LambdaLabsで節約しながら機械学習
機械学習を始めようと思った時に、サンプルを試す程度ならGoogle Colabでも出来ます。しかし、一定時間操作がないとセッションが切れたり、ブラウザを開きっぱなしにする必要があったり、時間のかかる学習をさせようと思うと使い勝手が悪い面があります。
とはいえ、GPUマシンを購入する余裕はないといった時に考えるのがクラウド運用だと思います。
LambdaLabsはGPUインスタンスを比較的安価に提供しているサービスです。
本稿では、Ansibleを使ってLambdaLabsのインスタンスを節約しながら運用する方法をご紹介します。
例として、RVCというAIボイスチェンジャーを構築してみます。RVC自体の使い方は割愛します。
事前準備
Ansible Collectionのインストール
インスタンス費用を節約するには、学習が完了したらインスタンスは停止する必要があります。繰り返し環境構築する必要があるため、Ansibleで自動化しました。
自分が作ったCollectionをGitHubで公開しているので、今回はこちらを使いながら説明します。カスタマイズしたい方はForkして適所変更して使ってください。
requirements.yml に次のように追記してください。
collections:
- name: https://github.com/rikuson/lambda-cloud-infra.git
type: git
version: 1.1.0
次のコマンドでインストールします。
ansible-galaxy install -r requirements.yml
SSH接続時にyes/noの入力を求められてしまうので、 ansible.cfg を編集して無効化します。
[defaults]
host_key_checking = False
SSHキーの追加
インスタンスにアクセスするためのSSHの公開鍵を登録します。名前は「Macbook Air」としました。

FirewallのSSHポート解放
Ansibleで環境構築するにはSSHで接続する必要があるため、22番ポートを解放します。ご自身の環境に合わせてIP制限をかけてください。

APIキーの生成
LambdaLabsはインスタンスを操作するためのWEB APIを提供しています。APIキーを生成しましょう。生成したキーは後で使うので控えておいてください。
Filesystemの作成
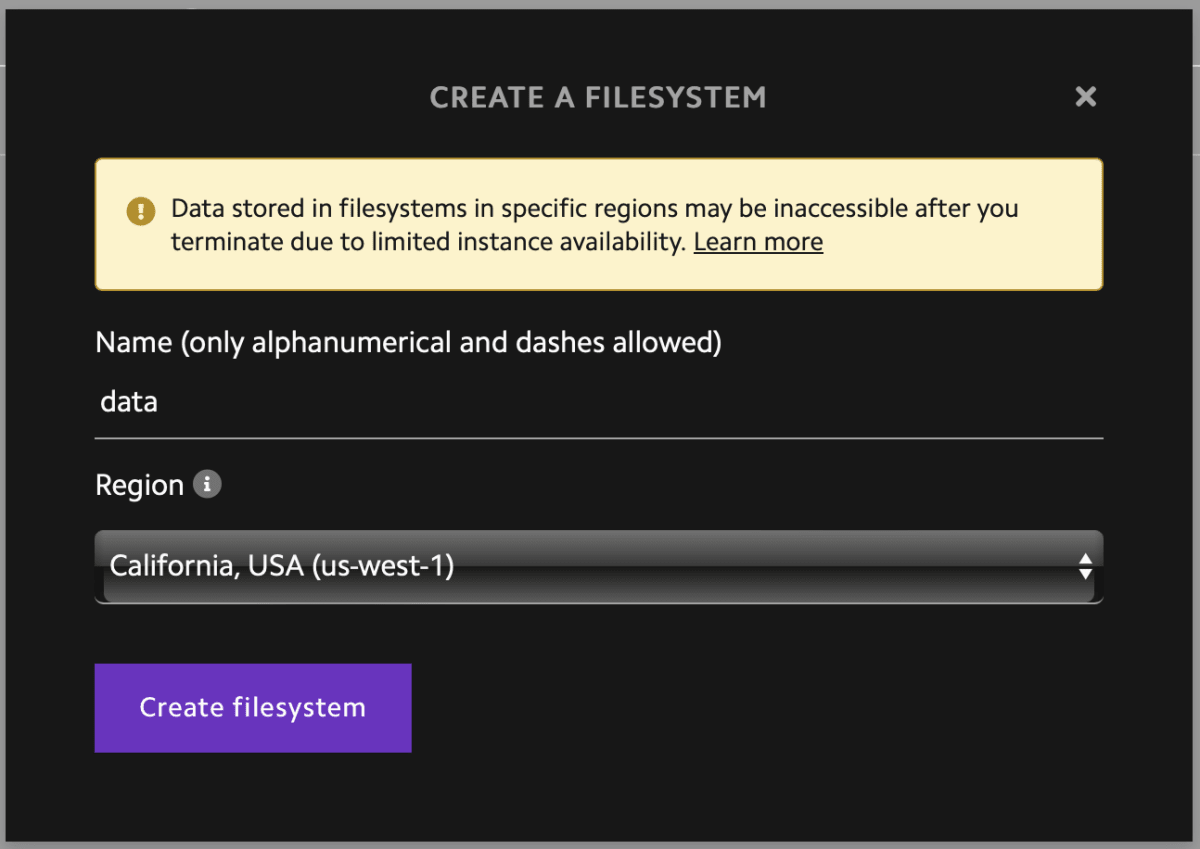
インスタンスを停止するとファイルも一緒に消えてしまいます。後から取り出せるように、出力ファイルをストレージに保存しておく必要があります。
Lambda CloudではFilesystemという機能でストレージを作成することができます。今回は data という名前で作成しました。
インスタンスの起動
生成したAPIキーやFilesystemの値を次のように変数にセットし、roleを呼び出してください。
- hosts: localhost
roles:
- role: rikuson.lambda_cloud_infra.gpu_instance
vars:
api_key: XXXXXXXXX
instance_type: gpu_1x_a10
region_name: us-west-1
ssh_key_name: Macbook Air
file_system_name: data
host_groups: gpu_instance
中身は次のようになっています。
まず、APIを呼び出してインスタンスを起動します。
インスタンスがアクティブになるまで30秒ごとにリトライしています。
最後にDyanamic Inventoryにhostを追加しています。
実行ごとにインスタンスが作成されてしまい、冪等になっていない点は要改善です。
インスタンスの停止設定
学習が完了したらインスタンスを自動停止させます。自動停止が働かなかった際も強制的に停止できるように max_running_time という変数を設定できるようにしました。APIキーや出力ファイルのパスを次のように変数にセットし、roleを呼び出してください。
output_file はインスタンス停止のトリガーとなるため、学習過程で作成される一時ファイルなどがマッチしないようにパターンを設定してください。
- hosts: gpu_instance
roles:
- role: rikuson.lambda_cloud_infra.terminator
vars:
api_key: XXXXXXXXX
file_system_mount_point: /home/ubuntu/data
output_file: /home/ubuntu/rvc/weights/*.pth
max_running_time: 24 hours
中身は次のようになっています。
毎分crontabで監視し、出力ファイルが見つかったらサーバーを停止させます。
atコマンドでインスタンスの最大起動時間を設定しています。
terminateコマンドはシェルスクリプトで次のように定義しています。
APIを呼び出してインスタンス一覧を取得し、グローバルIPを使って自身の INSTANCE_ID を取得します。取得した INSTANCE_ID を用いて、サーバー停止用のAPIを呼び出して停止させています。
サーバーを停止させる前に出力ファイルをFilessystemに保存しています。このとき、誤って上書きしないように cp コマンドにbオプションをつけています。
ちなみに、ググると、出力ファイルではなくGPUの使用量をトリガーにして自動停止させている方もいました。
RVCのインストール
RVCと依存パッケージをインストールし、モデルをダウンロードします。ディープラーニング用のインスタンスなのでpytorchやffmpegは初めから入っています。playbookに直書きすると取り回しづらいので、roleにしておきましょう。 roles/rvc/tasks/main.yml というファイルを次のように作成してください。
---
- name: Install dependencies
pip:
name: "{{ item }}"
loop:
- torchaudio
- name: Install RVC
git:
repo: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
dest: $HOME/rvc
- name: Install requirements
pip:
requirements: $HOME/rvc/requirements.txt
- name: Download models
command: python /home/ubuntu/rvc/tools/download_models.py
次のコマンドを実行すると、GradioのWEBサーバーが起動することが分かります。Gradioは機械学習モデルのWEBアプリを簡易的に構築するためのPythonライブラリです。機械学習系のツールはGradioを使ってUIを提供していることが多いです。
cd /home/ubuntu/rvc
python infer-web.py
Gradioをデーモン化
supervisorをインストールし、設定ファイルを作成します。
- hosts: gpu_instance
roles:
# (中略)
- role: rikuson.lambda_cloud_infra.daemon
vars:
name: rvc
command: python infer-web.py
directory: /home/ubuntu/rvc
中身は次のようになっています。
設定ファイルは次のようになっています。
学習の進捗状況はoutput.logやerror.logを見て確認します。
WEB UIにアクセス
リモートサーバー上で起動したWEB UIにアクセスするにはいくつかのやり方が存在します。
ngrokやgradio.liveを使って外部公開する方法もありますが、時間制限があったり無料だとIPアドレス制限機能が使えなかったり難があります。かといって、ドメインを設定したり、SSL証明書を入れるのは面倒です。
今回は個人利用なので、より手軽にSSHポートフォワーディングを利用することにしました。
次のコマンドを実行して、ブラウザで http://localhost:7865 にアクセスしてみましょう。 ${SERVER_HOST} にはサーバーのIPアドレスを入れてください。
ssh -L 7865:127.0.0.1:7865 ubuntu@${SERVER_HOST} -N
学習を開始したら、WEB UIを閉じて ssh コマンドを終了してOKです。
出力ファイルをダウンロード
学習が完了したら出力ファイルがFilesystemに保存され、インスタンスが停止しているはずです。LamdaLabsのWEB UIからFilesystemの中身にアクセスすることはできないため、出力ファイルをダウンロードするためにはインスタンスを再度起動する必要があります。
インスタンスを起動したら、 rsync でダウンロードします。
rsync -v --ignore-existing ubuntu@${SERVER_HOST}:data ~/Downloads/
ダウンロードが完了したらインスタンスを停止することをお忘れなく!
おわりに
ここまでの手順をPlaybookにまとめると次の通りです。
---
- hosts: localhost
roles:
- role: rikuson.lambda_cloud_infra.gpu_instance
vars:
api_key: XXXXXXXXX
instance_type: gpu_1x_a10
region_name: us-west-1
ssh_key_name: Macbook Air
file_system_name: data
host_groups: gpu_instance
- hosts: gpu_instance
roles:
- role: rikuson.lambda_cloud_infra.terminator
vars:
api_key: XXXXXXXXX
file_system_mount_point: /home/ubuntu/data
output_file: /home/ubuntu/rvc/assets/weights/*.pth
max_running_time: 24 hours
- role: rvc
- role: rikuson.lambda_cloud_infra.daemon
vars:
name: rvc
command: python infer-web.py
directory: /home/ubuntu/rvc
正直、RVCなら自動停止設定をするほど学習に時間はかかりませんでした。
学習に時間のかかるツールなら、もっと役に立つと思います。
参考になれば幸いです。
Discussion