初めての投稿ですがよろしくお願いします、ハンです。
私は福岡の株式会社Fusicの機械学習チームで勤めている者です。機械学習やAWS運用など、困っていることがありましたら気軽にお声かけてください。
この記事では、Lambda LabsのGPU Cloud Serviceを使ってみたレビュー・感想などを書いてみたいと思います。
要約
- Lambda Labs、お値段だけを考えると良い!
- モニタリングなど、提供するサービスが少ないので、自分なりの工夫が必要
- 使用可能なインスタンス・ストレージの制約があり、Persistanceストレージ連動ができなかったのはすごく残念
なぜLambda Labs?:お値段!
皆さんはクラウドサービスを利用する際、何を一番の選択基準にするのでしょうか?
使用したいGPUの種類や数・求められるセキュリティ・サポート機能など、さまざまな判断基準があると思いますが、以下のような条件を考え 私は 「コスパが良いLambda Labs」を使ってみました。
- なるべく多様な実験を行いたい(インスタンスをいっぱい立てる可能性)
- すでに公開されたデータセットを使用(セキュリティーはそこまで気にしなくて良い)
- 24GB以上のGPU RAMは必要
自分が参考にしたサイトはfullstackdeeplearningで、(2023年2月基準)色んなGPUインスタンス情報を目にすることができました。GPU RAM基準にソーティングして、他の条件を参考にしながら「LAMBDA:A10G(24GB)」を使うことにしました。(CPUsとかRAMとかも余計に良さそう)

実際に使ってみよう
Storage 生成
Lambda LabsではFilesystemsという名前のStorageを提供してます。インスタンス内のデータはインスタンスがTerminateされると削除されてしまうので、まずFilesystemを作る必要がありました。複雑な設定はなく、Lambda Labs Storage(Filesystems)で簡単に生成できます。これをインスタンス生成の時にAttachするだけ。
だと思っていましたが。。 現在提供できるFilesystemsは「Texas Regionのみ」になっていて、他のRegionのインスタンスを使う場合はストレージを活用するのが無理でした。。。
インスタンスに十分なSDDが付いてはいましたが、
- インスタンスの中止が出来ない。(Launch → Terminateのみ)
- ストレージはTexas Regionしかない。
- インスタンスがTexas Regionに必ずあるとは言えない。
という状況は少し残念な部分です。
ストレージに関しては、Wasabiなどを活用して、必要なデータが無くならないよう、別途の管理が必要そうですね。
インスタンス生成・アクセス
Lambda Labs インスタンスからインスタンスを生成し、Tutorialを参考にSSH Keyを登録・アクセスしてみました。インスタンス生成・アクセス以外の機能はそんなにないので、生成自体はかなり簡単です。
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.65.01 Driver Version: 515.65.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10 On | 00000000:06:00.0 Off | 0 |
| 0% 35C P8 22W / 150W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:18:20_PST_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
すでに作業中のコードがありましたので(docker-composeを含め)、Docker-compose / Git の作業だけを行いました。
スムーズに行けた訳ではないですが、私の場合は以下のような設定で十分でした。
$ sudo apt-get update -y
# docker-composeを最新のバージョンにインストール
$ sudo apt install jq -y
$ VERSION=$(curl --silent https://api.github.com/repos/docker/compose/releases/latest | jq .name -r)
$ DESTINATION=/usr/bin/docker-compose
$ sudo curl -L https://github.com/docker/compose/releases/download/${VERSION}/docker-compose-$(uname -s)-$(uname -m) -o $DESTINATION
$ sudo chmod 755 $DESTINATION
$ docker-compose -v
Docker Compose version v2.17.2
# Git repository clone
# docker-compose-gpu.ymlは事前作成
$ git clone ...
# Run Docker
$ sudo chmod 666 /var/run/docker.sock
$ docker-compose -f docker-compose-gpu.yml up -d
無駄なお金を使いたくない:学習が止まったらTerminate
Amazon CloudWatchのアラームは、インスタンスの状態をモニタリングし「Reboot・Stop・Terminateなどアクションを行う」便利な機能です。Lambda Labsにはこのような機能がなかったので、学習が止まった(終わった)のに無駄にインスタンスが動いている可能性も十分あると思いました。
せっかくコスパの良いGPU Cloudサービスを選んだのに、無駄な課金が発生したら心が痛むので、簡単な対策を取っておきました。
- GPU使用量を定期的にモニタリング
- モニタリング結果をSlackで通知
- GPU使用がないと思われる場合、APIでインスタンスをTerminate
Lambda labs API Key生成
Lambda labs APIは起動中のインスタンスリスト・インスタンスの起動や中止などが可能な機能を提供しています(DOCUMENTS)。多くの機能があるわけでは無いですが、Terminateさえ出来ればよかったので、API Keyを作成しました。(これも2〜3回クリックすることで出来ます。)
ChatGPTに聞いてみる
上記の機能の実装って色んな方法があると思いますが、自分が思い出したのはChatGPT。以下のようなPromptでコード完成できました!(超便利)
- nvidia-smiを使って現在インスタンスのGPU使用量を確認し、その結果をslackメッセージに転送するPythonコードを作成してください。
- gpu_usage == 0の場合は、次のコマンドを実行するコードを追加してください。
# Lambda LabsのAPIコマンド curl -u API-KEY: https://cloud.lambdalabs.com/api/v1/instance-operations/terminate -d @INSTANCE-IDS -H "Content-Type: application/json" | jq . - cronスケジューラにPython実行を登録する方法を教えてください。
ChatGPTで作成されたコード
以下のコードを1時間毎に実行するようcrontabを生成したら、ちゃんと
import subprocess
import psutil
import json
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
###################### INIT ######################
# Slack API token
SLACK_TOKEN = "YOUR_SLACK_TOKEN"
# Slack channel to send the message
SLACK_CHANNEL = "YOUR_SLACK_CHANNEL_ID"
# Lambda Labs API_KEY
LAMBDA_API_KEY = "YOUR_LAMBDALABS_API_KEY"
# Lambda Labs Instance ID
LAMBDA_INSTANCE_ID = "YOUR_LAMBDALABS_INSTANCE_ID"
# Get Slack client
client = WebClient(token=SLACK_TOKEN)
###################### GPU USAGE ######################
# 6秒間、平均GPU使用量を確認
# Initialize the list for storing GPU usage
gpu_usages = []
# Loop for getting GPU usage for 6 times with 1-sec interval
for i in range(6):
# Get GPU usage using nvidia-smi command
gpu_usage = subprocess.check_output(
["nvidia-smi", "--query-gpu=utilization.gpu", "--format=csv"]
).decode("utf-8")
# Extract GPU usage percentage from output
gpu_usage = gpu_usage.split("\n")[1]
# Append GPU usage to the list
gpu_usages.append(float(gpu_usage[:-1]))
# Sleep for 10 seconds before next check
time.sleep(1)
# Get the average of GPU usage
avg_gpu_usage = sum(gpu_usages) / len(gpu_usages)
###################### TERMINATE INSTANCE ######################
try:
# Send message(GPU Usage) to Slack channel
message = f"Instace ID: {LAMBDA_INSTANCE_ID}\nGPU Usage: {avg_gpu_usage}"
response = client.chat_postMessage(channel=SLACK_CHANNEL, text=message)
print("Message sent: ", message)
# For Terminating the current Lambda labs instance
if avg_gpu_usage == 0.0:
# Send message(Terminate Lambda Labs instance) to Slack channel
message = f"Terminating Lambda Labs instance {LAMBDA_INSTANCE_ID}"
response = client.chat_postMessage(channel=SLACK_CHANNEL, text=message)
print("Message sent: ", message)
# Convert dictionary to JSON string
_json = {"instance_ids": [f"{LAMBDA_INSTANCE_ID}"]}
_json_str = json.dumps(_json)
# Create Terminate Lambda Labs instance command
command = [
"curl",
"-u",
f"{LAMBDA_API_KEY}:",
"https://cloud.lambdalabs.com/api/v1/instance-operations/terminate",
"-d",
_json_str,
"-H",
"Content-Type: application/json",
]
# Terminate Lambda Labs instance
output = subprocess.check_output(command).decode("utf-8")
response = client.chat_postMessage(channel=SLACK_CHANNEL, text=output)
print("Message sent: ", output)
except SlackApiError as e:
print("Error sending message: {}".format(e))
動作確認
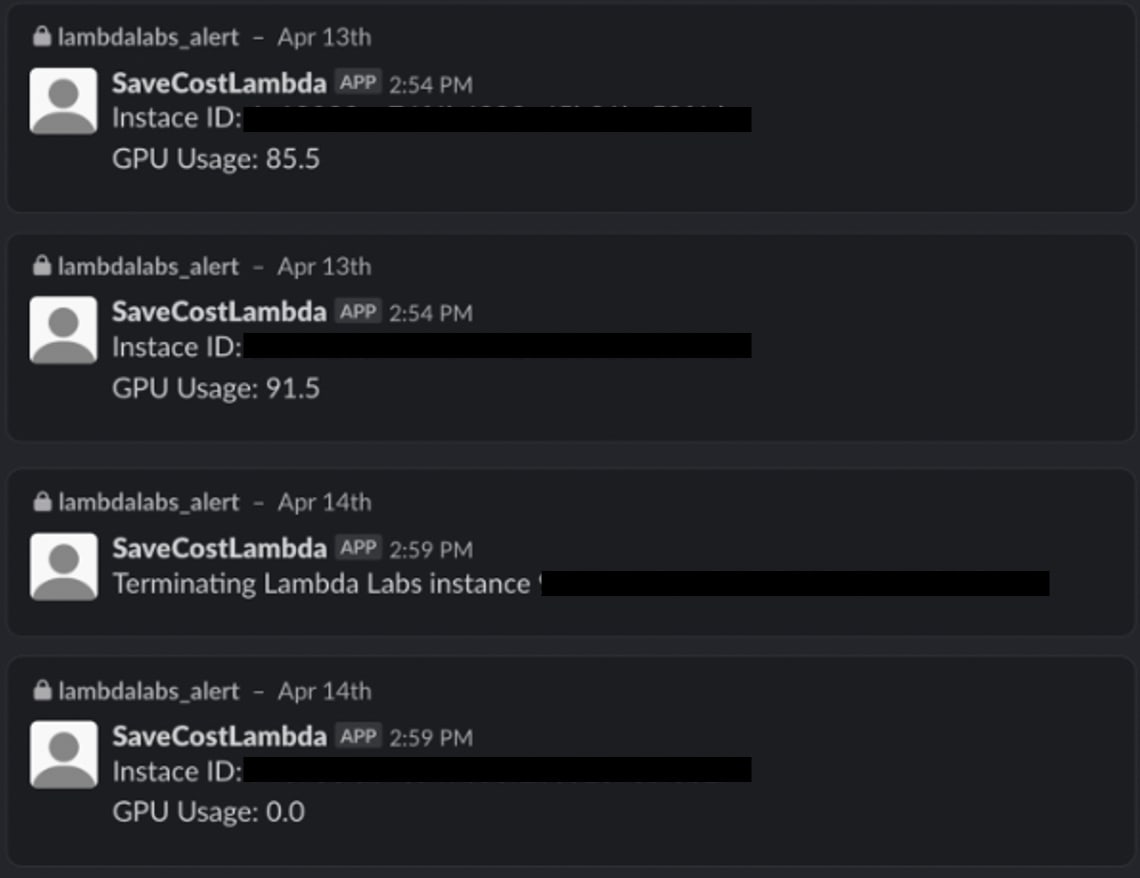
テストとしてコードの実行サイクルを1分に設定した後、動作を確認してみました。GPUが動いてないと、しっかりインスタンスをTerminateしてくれましたので、一応安心できますね。。
Slackで届いたメッセージ:テスト画面
感想
個人的にはGoogleColabやAWSしか使ったこと無いですが、非常に単純な仕組みで、安く、GPU Cloudが使えるなっと思いました。もちろんAWSに比べては色々工夫が必要でしたが、これもこれなりに勉強になる部分だと思います。
しばらくはこのサービスを使う予定なので、また他の発見があったら投稿しますので、よろしくお願いします。

Discussion