毒チョコゲーム (Chomp) が先手必勝であることを Lean で証明する
こちらは、証明支援系 Advent Calendar 2025 17日目の記事です。
毒チョコゲーム Chomp は先手必勝
毒チョコゲームとして知られる Chomp ゲームには、「プレーヤーが最善手を指した場合に先手必勝であることは証明されているが、具体的な必勝手を求めるのは難しい」という面白い特徴があります。
YouTube チャンネル「えびまラボ」の動画「毒チョコゲームの必勝法〖ゆっくり解説〗」では、この先手必勝性の証明について戦略盗用 (strategy stealing) という論法で分かりやすく解説されています。
この記事では、定理証明支援系 Lean 4 で Chomp ゲームを形式化し、ゲームが先手必勝であることを証明します。
Chomp(毒チョコゲーム)のおさらい
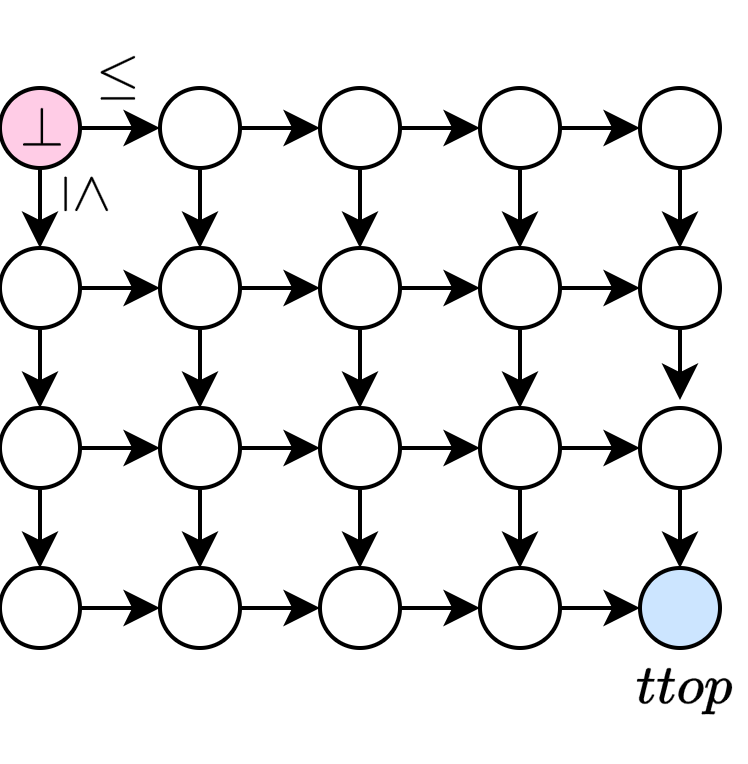
まずは普通の Chomp のルールをざっくり振り返ります。板チョコ(以降、盤面と呼びます)のイメージを示します。

Chomp ゲームの盤面
- 一番左上のピースが「毒チョコ」です
- プレイヤーは交互に、好きなピースを 1 つ選び、そのピースより右下にあるすべてのピースをまとめて食べます(例えば、図中
p - 最後に毒チョコを食べさせられたプレイヤーが負けとなります
半順序集合版 Chomp へ一般化
板チョコのような長方形の形のままでも、Chomp ゲームの形式化はできますが、ピースに 2 次元座標を入れたりと若干面倒な手順が入ってくるので、問題を少し一般化した、半順序集合版 Chomp を考えます。(動画の2:41)
板チョコの各ピースの集まりに、例えば下図のような半順序 (

- 毒ピース = 最小元
\bot - 手番でできる操作 = あるピース
p p \le q q - ゲームの盤面 = 有限半順序集合 (finite poset) の下に閉じた部分集合
最後の「ゲームの盤面」について、少し説明を加えます。ゲームが進行中の盤面は板チョコの右下部分が階段状に切り取られた形となります。

このような盤面の形状は、半順序
Lean による Chomp の形式化と先手必勝の証明
それでは、Lean 4 で半順序集合版の Chomp を形式化し、ある条件を満たす初期盤面においては、先手必勝であることを証明していきます。
証明の全体は以下のリンク先に掲載しています。
なお、本記事での証明では、Lean バージョン 4.22.0 より導入された grind タクティクを使用します。grind は強力な証明自動化タクティクで、証明に必要な定理を登録していくことも簡単できます。grind タクティクについてはこちらのページが詳しいです。
準備
この証明では、Lean の数学ライブラリ Mathlib を用います。特に、ピースの集合が有限の半順序集合となるので、Finset (有限集合) や PartialOrder (半順序集合) などに関する定義や定理が示されたライブラリをインポートしておきます。
import Mathlib.Data.Finset.Basic
import Mathlib.Data.Finset.Card
import Mathlib.Order.Basic
ピースを表す型変数 α を変数として用意しておきます。
variable {α : Type} -- 各ピースの型:最小元(毒ピース)を持つ半順序集合
[PartialOrder α] [OrderBot α] [DecidableEq α] [DecidableLE α]
ピースの集合が、最小元 (毒ピース) を持つ半順序集合となることを反映して、型α には、型クラス PartialOrder と OrderBot のクラスインスタンスとしています。また、型クラス DecidableEq と DecidableLE のクラスインスタンスであることも要求しています。これらは、ゲームの手を進める際に、盤面のピースを条件に従って取り除いたりするために必要となります。(端的に言うと Finset.filter を使うためです)
盤面 Board の定義
ゲームの盤面の型 Board α を定義します。この Board α は、盤面に残っているピースの(有限)集合 pieces と、それが満たすべき 2 つの条件
-
hasBot:\bot piecesに含まれている -
downClosed:piecesは\le
の証明から構成される構造体として定義します。
structure Board (α : Type) -- α は各ピースを表す型
[PartialOrder α] [OrderBot α] [DecidableEq α] [DecidableLE α]
where
pieces : Finset α -- 残っているピースの(有限)集合
hasBot : ⊥ ∈ pieces -- 毒ピースが含まれる
downClosed : -- 残っているピースの集合は下に閉
∀ p q, p ∈ pieces → q ≤ p → q ∈ pieces
ピースの有限集合は pieces は Finset α 型の値として定義しています。 なお、Finset をインポートしているので、
後のために、盤面のサイズをピースの個数で定義し、Board α を SizeOf クラスのインスタンスとしておきます。Finset.card を用いて、pieces の要素の個数を取得しています。
/-- 盤面のサイズを定義 (残っているピースの個数) -/
instance Board.SizeOf: SizeOf (Board α) where
sizeOf b := b.pieces.card
毒ピース terminal αは、Board α 型の項として次のように定義できます。
/-- 毒ピースのみの最終盤面 -/
@[simp, grind]
def Board.terminal (α : Type)
[PartialOrder α] [OrderBot α] [DecidableEq α] [DecidableLE α]
: Board α where
pieces := {⊥} -- ⊥だけを含む集合
hasBot := by grind
downClosed := by
intro p q hqp
simp_all
pieces は
hasBot には、pieces に grind を grind? に置き換えると裏で使われている定理がわかります。ここではFinset.mem_singleton が使われていました。
downClosed には
与えられた盤面 isTerminal b も用意しておきます。
/-- 最終盤面であることを表す述語 -/
def Board.isTerminal (b : Board α) : Prop :=
b = terminal α
合法手 legalMove の定義
プレーヤーが盤面 some に包んで) 返す関数 move b p を定義します。盤面にないピースや none を返す) するよう、Option (Board α) 型の項を返す関数として定義します。
/-- 盤面 b から、ピース p を選んで取った盤面 b' を返す -/
@[simp, grind]
def Board.move (b : Board α) (p : α) : Option (Board α) :=
if h : p ∈ b.pieces ∧ p ≠ ⊥ then -- 合法手の場合 some b' を返す
--
let pieces := { q ∈ b.pieces | ¬ p ≤ q } -- p 以上のピースを取り除く
let hasBot : ⊥ ∈ pieces := by
simp [pieces]
cases b with grind
let downClosed : ∀ p q, p ∈ pieces → q ≤ p → q ∈ pieces := by
cases b with grind
--
some <| .mk pieces hasBot downClosed -- some b'
else -- 合法手でない場合 none を返す
none
プレーヤーが盤面に含まれるピース some b' を返します。この新しい盤面 pieces は、内包記法を使って { q ∈ b.pieces | ¬ p ≤ q } と定義しています。hasBot と downClosed は grind タクティクを使うと簡単に証明できます。
次に定義する legalMove b b' は、盤面 move 一手で移ることができる) という述語です。
/-- 盤面 b から b' への合法手がある -/
@[simp, grind]
def Board.legalMove (b b' : Board α) : Prop :=
∃ p, b.move p = some b'
ここで、「合法手を一手進めると盤面のサイズが必ず小さくなる」ことを証明しておきます。一手進めると少なくとも 1 ピースは食べるので、直感的には明らかですね。この定理 move_size_lt は、次に定義する盤面が勝ち盤面であるという述語 winning を再帰的に定義する際に必要となります。
/-- 一手進めると盤面のサイズが小さくなる
NOTE : winning の定義が整礎再帰であることを示す際に使う -/
@[simp, grind →]
theorem Board.move_size_lt {b b' : Board α} (h : legalMove b b') :
sizeOf b' < sizeOf b := by
simp_all
obtain ⟨p, hp⟩ := h
obtain ⟨hv, heq⟩ := hp
apply Finset.card_lt_card
simp_all [← heq, Finset.filter_ssubset]
use p
constructor
· grind
· rfl
勝ち盤面の定義
Chomp では、先手も後手も同じ盤面が与えられた時に取れる手の選択肢は全く同じものとなります。したがって、盤面に対して (先手後手に依存せず、その盤面を与えられたプレーヤーが) 必勝となるかどうかが決まります。
では、盤面 winning b の定義を考えてみましょう。
盤面 winning b は次のように定義できそうです。
/-- 盤面 b が勝ち盤面である -/
def Board.winning (b : Board α) : Prop :=
∃ (b' : Board α), legalMove b b' ∧ ¬ b'.winning
decreasing_by sorry
盤面 legalMove b b' で行ける盤面 ¬ winning b' であるというふうに、再帰的に定義しています。
しかし、この定義はうまくいきませんでした。というのも、この winning のように再帰的な関数の定義では、再帰呼び出しの引数が小さくなっていること (整礎再帰であること) の証明が必要となるのですが、その証明を与えることができないためです。
上記の decreasing_by の部分で sizeOf b' < sizeOf b を証明する必要があるのですが、この定義では、legalMove b b' を証明の条件として得ることができず、sizeOf b' < sizeOf b を証明することができません。
次のように条件 legalMove b b' を存在量化の形で表現することで、winning をうまく定義することができます。
/-- 盤面 b が勝ち盤面である -/
@[simp, grind]
def Board.winning (b : Board α) : Prop :=
∃ (b' : Board α) (_ : legalMove b b'), ¬ b'.winning
decreasing_by grind
この定義では、decreasing_by において legalMove b b' を仮定に取ることが可能となり、先に示した定理 move_size_lt を使うことで、sizeOf b' < sizeOf b を証明することができます。実際の証明は grind タクティクで通ります。
ちなみに、この定義による winning b と ∃ (b' : Board α), legalMove b b' ∧ ¬ b'.winning が等価であることは簡単に証明することができます。
与えられた盤面 losing b を winning b の否定として定義しておきます。
/-- 盤面 b が負け盤面である -/
@[simp, grind]
def Board.losing (b : Board α) : Prop :=
¬ b.winning
さて、毒ピース (terminal α は負け盤面であるはずです。この事実は次のように証明できます。
/-- 最終盤面は負け盤面 -/
theorem Board.terminal_losing :
terminal α |>.losing := by
grind
初期盤面の特徴 (真の最大元を持つ盤面)
2次元長方形の初期盤面での Chomp では、
一般の半順序構造での Chomp においても、最小元 (
盤面 hasTop b を定義しておきます。
/-- 真の最大元(最小元と異なる最大元)が存在する -/
def Board.hasTtop (b : Board α) : Prop :=
∃ ttop ∈ b.pieces, (∀ a ∈ b.pieces, a ≤ ttop) ∧ ttop ≠ ⊥
初期盤面 hasTop b が成り立つとき、先手必勝となります。先手必勝の証明では、先手が真の最大限のみを選んで取ることが可能であるということが一つのポイントとなります。
補題の証明 (先手キャンセル補題)
真の最大限を持つ初期盤面に絡んだ補題を証明しておきます。
真の最大元
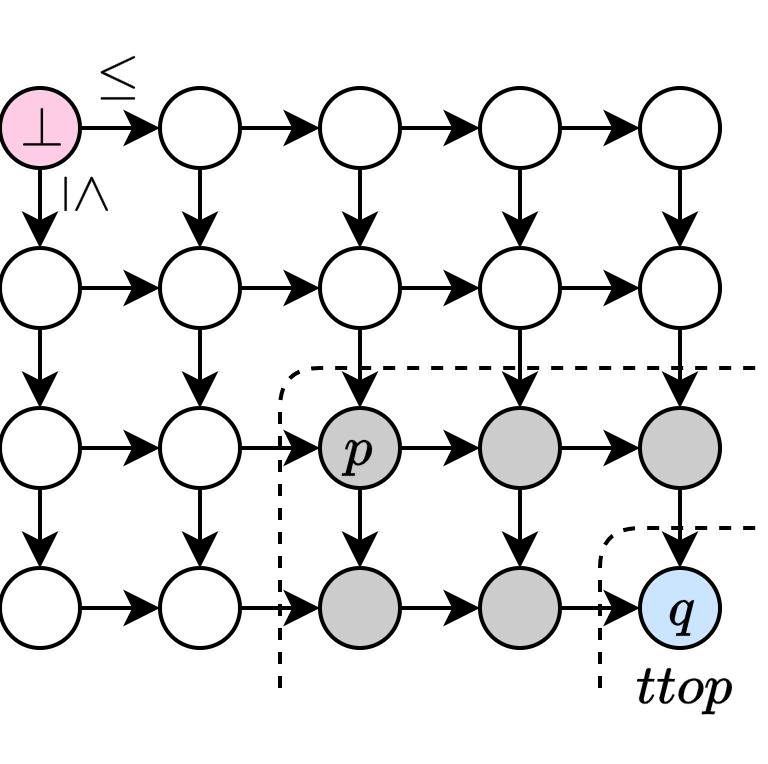
このことを少し一般化した形で証明しておきます。次の定理 move_move_of_le は、
/-- p ≤ q のとき、q を取ってから p を取る手順は、
はじめから p を取る手順と同じ盤面を与える (一手目はキャンセルできる) -/
@[simp, grind →]
theorem Board.move_move_of_le {b b₁ b₂ : Board α} {p q : α}
(hpq : p ≤ q) (h₁ : b.move q = some b₁) (h₂ : b₁.move p = some b₂) :
b.move p = some b₂ := by
simp_all
obtain ⟨q', hq'⟩ := h₁
obtain ⟨p', hp'⟩ := h₂
apply Exists.intro
· congr
grind
· grind
メイン定理「真の最大元を持つ盤面は勝ち盤面」の証明 (戦略盗用論法)
それでは、Chomp が先手必勝であるという定理を証明します。盤面
まず、先手が
-
b_1 b_0 -
b_1 p p p move_move_of_leで保障されます)
この先手が後手の手を盗用するという戦略盗用論法により、具体的な必勝手を具体的には示さないものの必勝手が存在すること自体は示すことができます。
Lean による証明は次のようになります。
theorem Board.winning_of_hasTtop {b₀ : Board α} (h : b₀.hasTtop) :
b₀.winning := by
obtain ⟨ttop, h₀⟩ := h -- 先手は ttop を取って move
have h_move_ttop : ∃ b₁, b₀.move ttop = some b₁ := by
simp_all
obtain ⟨b₁, hb₁⟩ := h_move_ttop -- 後手は b₀ から ttop を取った盤面 b₁ を受け取る
by_cases h₁ : b₁.losing -- b₁ が負け盤面かどうかで場合分け(排中律)
. grind -- b₁ が負け盤面の場合: そもそも b₀ は勝ち盤面
. grind -- b₁ が勝ち盤面の場合: 後手の手を先手が真似ればよい
by_cases タクティクで
おまけ
勝ち盤面と負け盤面を相互再帰的に定義する
上記では、盤面 losing b を、勝ち盤面であることの否定 ¬ winning b として定義しました。しかし、盤面が勝ち盤面であることもしくは負け盤面であるということは、次のように考えるのがより自然かもしれません。
- 与えられた盤面が勝ち盤面であるとは、うまく一手を取ると相手に負け盤面を押し付けることができる。
- 与えられた盤面が負け盤面であるとは、どんな一手を取っても相手に勝ち盤面を与えてしまう。
この考えに基づいて、述語 winning と losing は次のように相互再帰的に定義することができます。
mutual -- winning とlosing を相互再帰で定義
/-- 盤面 b が勝ち盤面である b.winning
うまい一手を取ると相手に負け盤面を与えられる -/
@[grind]
def Board.winning (b : Board α) : Prop :=
∃ (b' : Board α) (_ : legalMove b b'), b'.losing
decreasing_by grind
/-- 盤面 b が負け盤面である
どんな一手をとっても相手に勝ち盤面を与えてしまう -/
@[grind]
def Board.losing (b : Board α) : Prop :=
∀ (b' : Board α), legalMove b b' → b'.winning
decreasing_by grind
end
このような相互再帰による定義をした場合においても、(ある意味当然ですが) losing b と ¬ winning b は論理的には同値となります。証明は若干長くなりますが以下の通りです。
/-- losing は winning の否定と同値 -/
@[simp, grind =]
theorem Board.losing_iff_not_winning (b : Board α) :
b.losing ↔ ¬ b.winning := by
apply Iff.intro <;> intro h
· rw [winning]
push_neg
intro b' hbb'
have ih : b'.losing ↔ ¬ b'.winning := by -- 数学的帰納法
have hlt : sizeOf b' < sizeOf b := by grind
exact losing_iff_not_winning b' -- 自身を再帰で呼ぶ (hlt で整礎性を示す)
grind
· rw [losing]
intro b' hbb'
have ih : b'.losing ↔ ¬ b'.winning := by -- 数学的帰納法
have hlt : sizeOf b' < sizeOf b := by grind
exact losing_iff_not_winning b' -- 自身を再帰で呼ぶ (hlt で整礎性を示す)
grind
盤面のサイズに対する数学的帰納法に対応した証明なのですが、証明の中で自分自身を再帰的に呼び出せるのは、プログラムによる証明ならではだなあという感じがして、個人的にはとても好みです。
相互再帰による定義での証明の完全版はこちらです。
終わりに
本記事では Chomp ゲームが先手必勝であることを戦略盗用論法に基づいた証明を Lean で行いました。Lean の事始めで自然数を作ったりその性質を証明したりしてみた、その次ぐらいに取り組んでみるのにちょうどよいレベルと規模感の課題なのかなと思います。
以下、今回 Chomp の証明に取り組んでみての雑感です。
- 証明自体よりも、証明に向けたデータ構造の定義や命題の形式化のほうが大変:
証明にあたって必要なデータ構造の整備、例えば、盤面Boardや一手進めるmove、合法手LegalMoveなどどのような概念が必要かの検討や、それらをどう定義し形式化するかといったところに、証明自体よりもずっと時間も手間もかかりました。
証明対象となる命題を形式化することも難しかったです。Lean は証明が正しいかどうかは示してくれますが、形式化した命題が本当に証明したいことを意味しているかどうかは示してくれません。 - LLM は証明の細部はいまいちだが、証明の指針は示してくれる(場合もある):
今回の証明の全体的な構成や、データ構造の整備は ChatGPT や Gemini などの LLM と何度もやり取りをして詰めていきました。やり取りをとおして Lean での証明を書いていくうちに、自身の理解が次第に深まっていくのがいちばんの収穫です。
現時点においては、これらの LLM から得られた証明自体には少なからず誤りがあって、正しい証明を得るにはいろいろと試行錯誤が必要でした。また指定したにも関わらず grind タクティクを使ってくれることはなかったです (grind タクティクに対する理解はあるようですが)。今回の証明部分は結局ほぼ自身で書き直しました。
この辺りの状況は日進月歩で、数年後もしくは数か月後にはだいぶ変わってきてるのかなとも思います。 - grind タクティクつよい。:
今回の証明ではひたすら grind と simp_all をたたき続けました。Mathlib で証明されている定理なども適宜使って証明してくれるようですので、すでに Mathlib でより強い定理が証明されていてそれが使われていたらどうしようと若干不安になりました(これは grind だけでなく Mathlib 使った証明全体に言えることですが)。定理を証明すること自体には問題はないですが、理解のための証明となると少し考える必要がありそうです。
また、将来 grind タクティクの実装が変わったときに、今回通った証明が通らなくなることもあり得そうです。grind タクティクのしくみをきちんと理解し、堅牢な証明を構築する必要があるかと思われます。
Discussion