Claude 3.7 Sonnet の調査
概要
Anthropicから,Claude 3.7 Sonnetがリリースされました.
Claude 3.7 Sonnetは,迅速な応答と拡張思考(段階的なreasoning)の両方を,単一のモデルで実行することができるハイブリッドreasoningモデルです.
APIで利用する場合,標準モード (迅速な応答)or 拡張思考モードを選択することが可能です.拡張思考モードを利用することで,解決策の計画やself-reflectionなどを行い,複雑なタスクを解くことが可能です.拡張思考モードでのthinking tokenはoutput tokenとして課金されます.その他の特徴は以下です.
- Claude 3.5 Sonnetよりも15倍以上多い出力長(一般提供として64K,ベータ版として最大128K)
- 拡張思考モードでのthinking token数は調整可能.(推論速度・コスト・パフォーマンスのトレードオフを検討可能)
- thinking tokenを増やすほど,論理的な問題の解決精度は高まる
- 画像入力も可能.
価格
Claude 3.5 Sonnetと同様で入力: 0.003/1K, 出力: 0.015/1K です.(出力トークンにreasoningトークンは含まれる)
利用可能なリージョン
利用可能なリージョンは以下のようです.本日時点(2025/02/25)では,Cross-region inferenceのみ対応しております.
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 米国西部 (オレゴン)
軽く利用してみた体感ですが,推論レイテンシが低下してそうです.(ただし実際は Claude3.5 Sonnet v2 とほぼ変わらなかった.)
※推論プロファイルID: us.anthropic.claude-3-7-sonnet-20250219-v1:0
Claude’s extended thinking
下記記事によると,visible thought process (拡張思考におけるthinking tokenの公開)には以下の課題があるため,研究プレビューの位置づけらしいです.
- 思考プロセスのキャラクター性(機械的・分析的に振る舞う)
- 忠実性(思考プロセスで表示した以外の結論を導く可能性がある)
- 安全性(モデルの学習中に「思考プロセスが公開されること」を学習した場合,特定の思考を意図的に隠す可能性がある等)
また,Claude 3.7 Sonnetにポケモン赤をプレイさせると,3人のジムリーダーと戦い,バッジを獲得することができたそうです.(Claude 3.0 Sonnetはマサラタウンの家から出られない笑)
References
AWS
- AWS Blog: https://aws.amazon.com/jp/blogs/aws/anthropics-claude-3-7-sonnet-the-first-hybrid-reasoning-model-is-now-available-in-amazon-bedrock/
- AWS Announcements: https://www.aboutamazon.com/news/aws/claude-3-7-sonnet-anthropic-amazon-bedrock
- AWS Doc: https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-anthropic-claude-37.html
- Whats news: https://aws.amazon.com/jp/about-aws/whats-new/2025/02/anthropics-claude-3-7-sonnet-amazon-bedrock/
- Price: https://aws.amazon.com/bedrock/pricing/?nc1=h_ls
Anthropic
- Anthropic Announcements: https://www.anthropic.com/news/claude-3-7-sonnet
- Claude’s extended thinking: https://www.anthropic.com/research/visible-extended-thinking
- Anthropic Building with extended thinking: https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking
- System Card: https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf
Blog
Building with extended thinking
下記ドキュメントを読んだメモ
- 内部思考プロセス中,安全上の懸念があるコンテンツが検出された場合,そのセクションは暗号化され,
redacted_thinkingブロックとして出力される.
Occasionally Claude’s internal reasoning will be flagged by our safety systems. When this occurs, we encrypt some or all of the thinking block and return it to you as a redacted_thinking block.
- 上記を再現したい場合,入力プロンプトに以下の特殊なテスト文字列を利用すると良い.
ANTHROPIC_MAGIC_STRING_TRIGGER_REDACTED_THINKING_46C9A13E193C177646C7398A98432ECCCE4C1253D5E2D82641AC0E52CC2876CB
If you need to test redacted thinking handling in your application, you can use this special test string as your prompt:
- 特殊な28または29トークンのシステムプロンプトが自動的に入力トークンとして含まれるらしい.
When extended thinking is enabled, a specialized 28 or 29 token system prompt is automatically included to support this feature.
-
大量のドキュメントをキャッシュさせたい場合,システムプロンプトに含めてキャッシュする方が有利.
-
thinking_budgetを変更してもキャッシュが無効化されないため
-
-
マルチターンの会話の場合,過去の思考ブロック+通常のコンテンツブロックを入力すると,API側で思考ブロックのみ除外して推論される.
- マルチターンの会話で思考を含む場合,トークン計数APIを使用して正確なトークン数を取得することを推奨.
- 通常の推論の場合は思考ブロックを意図的にAPIの入力に含めなくても良いが,tool useの場合は含める必要があるので,基本的にAPIに全て含めることを推奨.
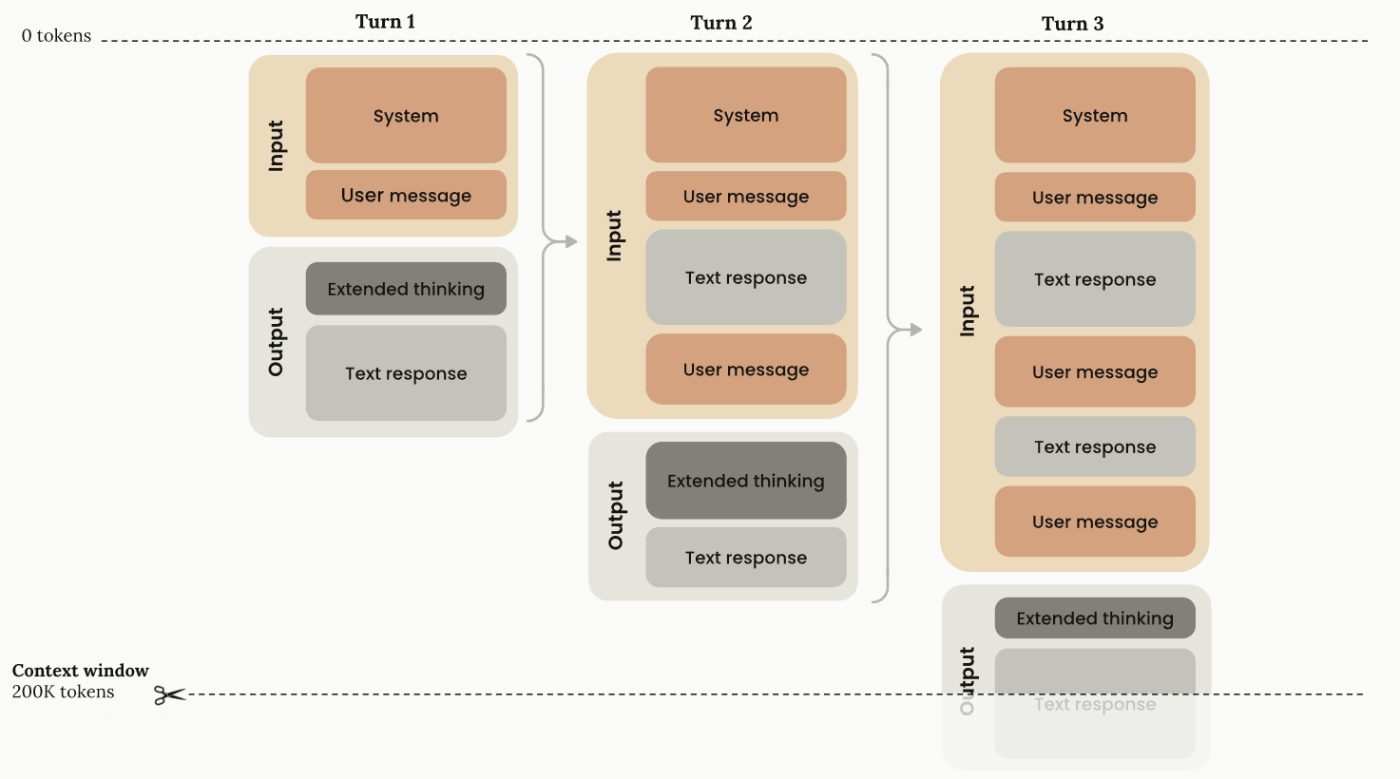
図はドキュメントから引用
以下がわかりやすい.(入力中のthinking tokenはカウントされない)
context window =
(current input tokens - previous thinking tokens) +
(thinking tokens + redacted thinking tokens + text output tokens)
- 以下を厳守しなければ,検証エラーが発生するようになった.
- 以前までは,以下が守られてない場合,API側でmax_tokensを調整してくれてたらしい.
プロンプトトークン + max_tokens ≤ context_window
- tool use で extend thinkingを利用する場合,
- 最初の tool use ブロック生成には思考ブロックは含まれるが,tool result を受け取った後は思考は含まれない.
- 直前の思考ブロックはAPIのリクエストに含める必要がある.Claudeが思考途中でツールを呼び出し,ツール結果を受け取った後にその思考を続けるという仕様のため.(入力トークンとしてはカウントされない)
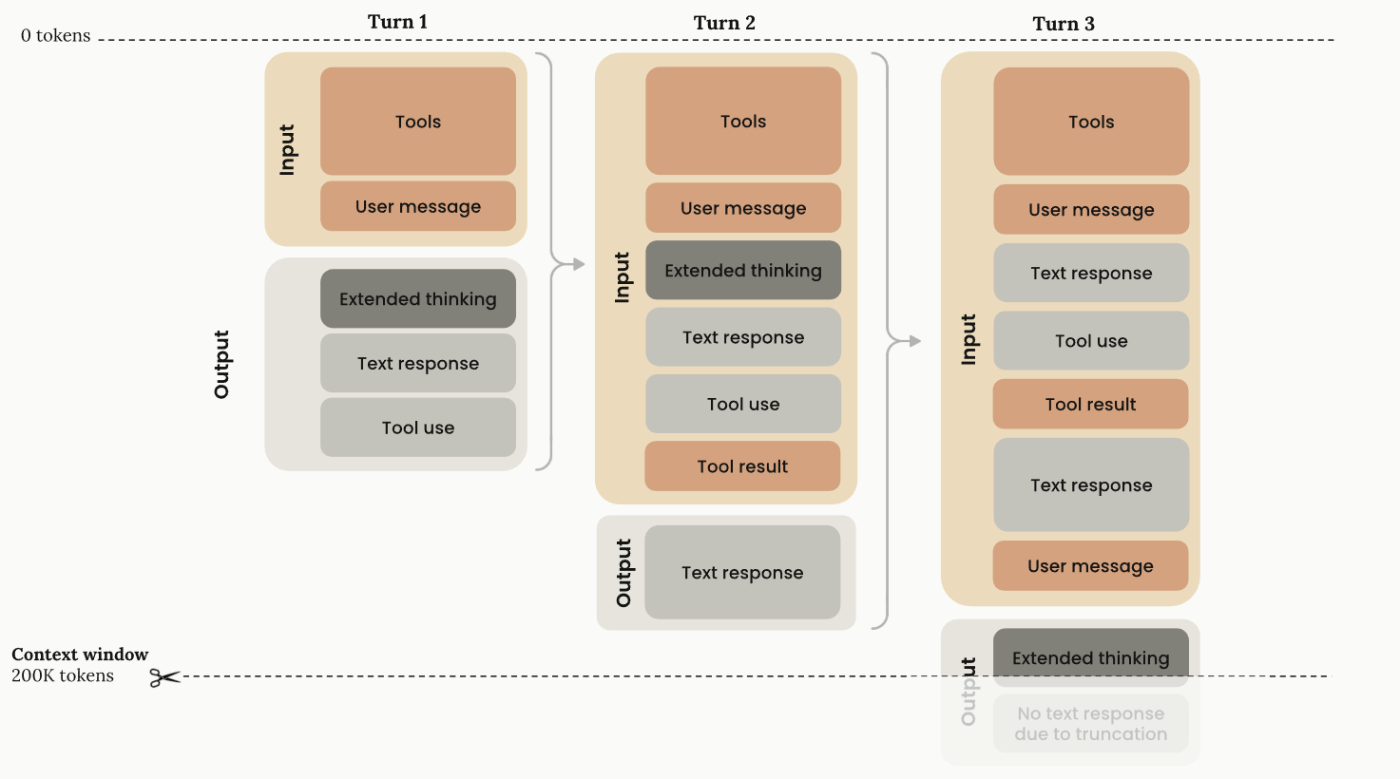
- Claudeの思考能力を最大化したい場合は、拡張思考プロンプトのヒントを確認すること
Extended thinking tips
- 拡張思考は英語で最も効果的に機能する.
- 拡張思考は英語で行い,最終的な任意の言語で出力させると良いらしい.
- 拡張思考では,タスクについて深く考えるという高レベルの指示でしばしばより良いパフォーマンスを発揮する.
- ステップバイステップの指示は(基本)不要.
- ただし,要件などは詳細かつ具体的に記述すると良い.
- 作業を完了させる前に,self-reflectionさせ,回答の一貫性とエラー処理を向上させることも可能.
ユーザー
数値の階乗を計算する関数を書いてください。
完了する前に、次のテストケースであなたの解決策を検証してください:
- n=0
- n=1
- n=5
- n=10
そして見つかった問題を修正してください。