前回の記事では、社内データ基盤と連携する分析エージェントを開発したときの技術面について解説しました。
今回は、このエージェントのPoCを社内でどのように進めたのかをご紹介します。
背景
私たちREADYFORの社内には、dbtとBigQueryにより整備されたデータ基盤があり、日々多くの情報が蓄積されています。
データ基盤はRedashやLooker Studio等から幅広い社員が利用できるようになっていますが、SQLを書いたりディメンション・指標を組み合わせてダッシュボードを作ったりする社員は一部に限られました。
結果として、一部のメンバーにデータの集計依頼が集まってくることに。
そうなると、以下のような課題がありました。
- データが必要な機会が来てもすぐには手に入らないため、その場ではビジネスメンバーの経験をもとに判断するしかない
- 依頼する前提だと、いろんな条件で集計し直して探索的に分析していくのが難しい。どうしても定型的なレポート作成に終始するケースが多い
同様の課題を持つ組織は少なくないのではないかと思います。
なぜエージェントを開発したのか?
そんな中、LLM・MCP・AIエージェントといった新しい技術の普及があり、社内でも「AIによるデータ活用をやってみよう」という動きが生まれました。
AIエージェントを開発しなくても、
- Gemini in BigQueryで自然言語をもとにSQLを書かせる
- MCPのデータコネクターを開発してChatGPTやClaudeから利用する
といった方法も考えられましたが、どちらも最初の一歩を踏み出すために一定のハードルがあり、大きく社内の状況を変えるには至らないのではないかと想定しました。
「データ分析に詳しい社員が目の前にいて、あれこれ要望を伝えたらその場でデータを出してくれる」という体験を実現することが重要と考えました。
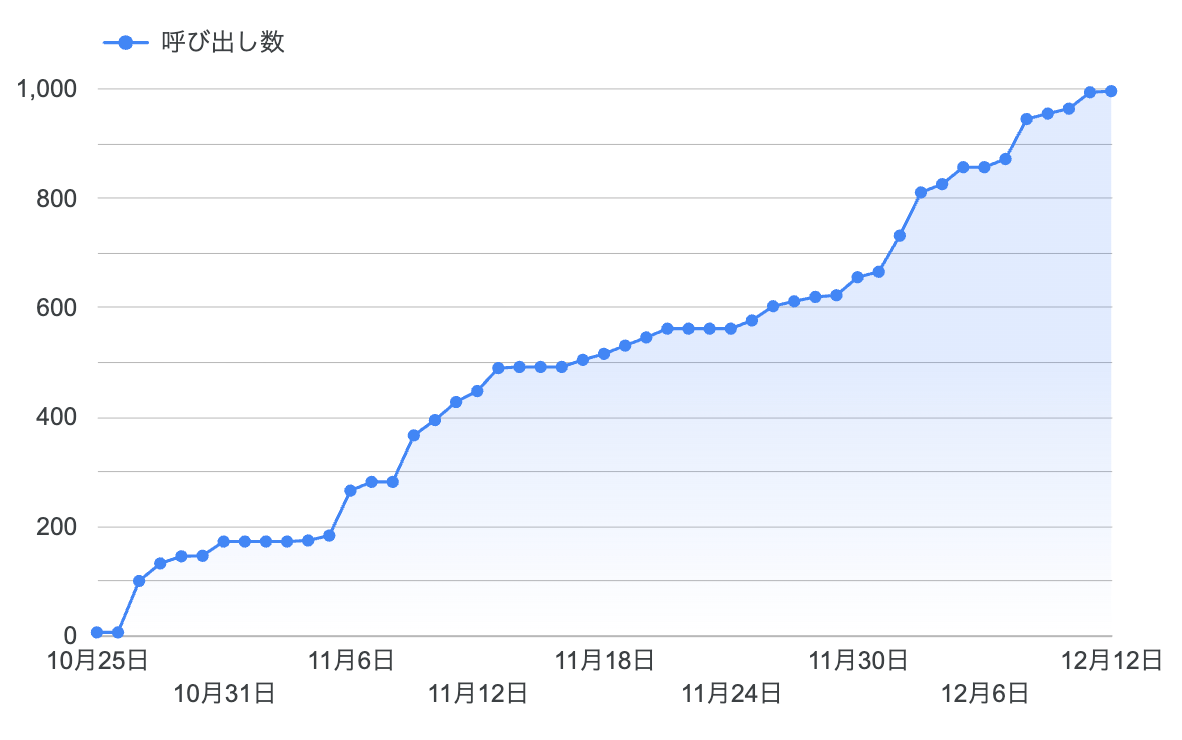
現在の利用状況(再掲)
回答の安定性・精度を改善しながら、段階的に社内でのアナウンスを進めています。
現在、週あたり10〜20人のアクティブユーザーがいて、AIに対する呼び出し回数は約1,000件まで達しています。
職種は営業・マーケティング・カスタマーサポート・カスタマーサクセスと幅広く、会話履歴の分析からは職種ごと職位ごとに様々な観点からデータと向き合っている様子が見られます。
特に、営業における事例探しには明確な実用性が見えていて、以下のような嬉しい声をもらいました。
事例AI、本当に重宝しております!!特に、地域と最終金額がすぐ出るのがありがたく・・
また、「〇〇に紹介するとしたら、どんな事例が良い?」みたいな質問にも答えてくれるので、めっちゃ勉強になる・・
アウトバウンドだとお電話して初めて情報を得ることができる中でご紹介する事例がある一定決まってしまっているという課題がありました。
お電話しながら、情報をいれてその場で事例をご紹介できるのはめちゃくちゃありがたかったです!
事例の有無であれば、ユーザー自身でハルシネーションかどうかの検証もしやすいので、AI活用の入口としてはうってつけかなと思います。
PoCの流れ
ここからは、こうした取り組みをどのように進めていったかを紹介していきます。
1. 対象ユーザーとユースケースの絞り込み
社内のあらゆる社員・ユースケースをカバーすることを初めから目指すのは、ことAIエージェントの開発においては悪手であると考えています。
確率的に振る舞うLLMを扱うのは不確実性が高く、少しずつ機能やプロンプトのチューニングが必要です。
まずは特定のユースケースに限定してでも、一過性のおもちゃではなく「業務に使える」水準を目指すことにしました。
ところで、社内ではEMのtoyocさんのおかげでプロダクト組織とビジネス組織の交流が進み、それがきっかけで私と同い年のビジネスメンバーとで「プロダクト自由研究の会」という週1の会が発足していました。
社内では「キュレーター」と呼ばれる役割を持つメンバーで、顧客である社会活動団体の資金調達(ファンドレイジング)の実行伴走を行っています。
数千万円、ときには億単位での目標金額を掲げてクラウドファンディングのプロジェクトを企画します。
そのための戦略策定と実行支援の役割を担うだけでなく、そういった案件を複数同時に抱えており、大型案件を成功に導く要であると同時に、社内では多忙で知られる仕事です。
- 多忙なキュレーターの業務を楽にすること
- ファンドレイジングのコンサルタントとして、日々さらなるサービス品質向上を求められていく中で、「データ」を武器にできるようにすること
を、エージェント開発の目標としました。
2. 初期プロトタイプの作成
次に、「そもそも社内データ分析をAIエージェントが上手くこなせるのか?」を検証するため、最速で初期プロトタイプを作成しました。
立ち上げにはGoogleのAgent Starter Packを利用しました。
READMEに従ってプロジェクトを作成し、 make playground を実行するだけで、ローカルでエージェントとのチャット画面が立ち上がります。
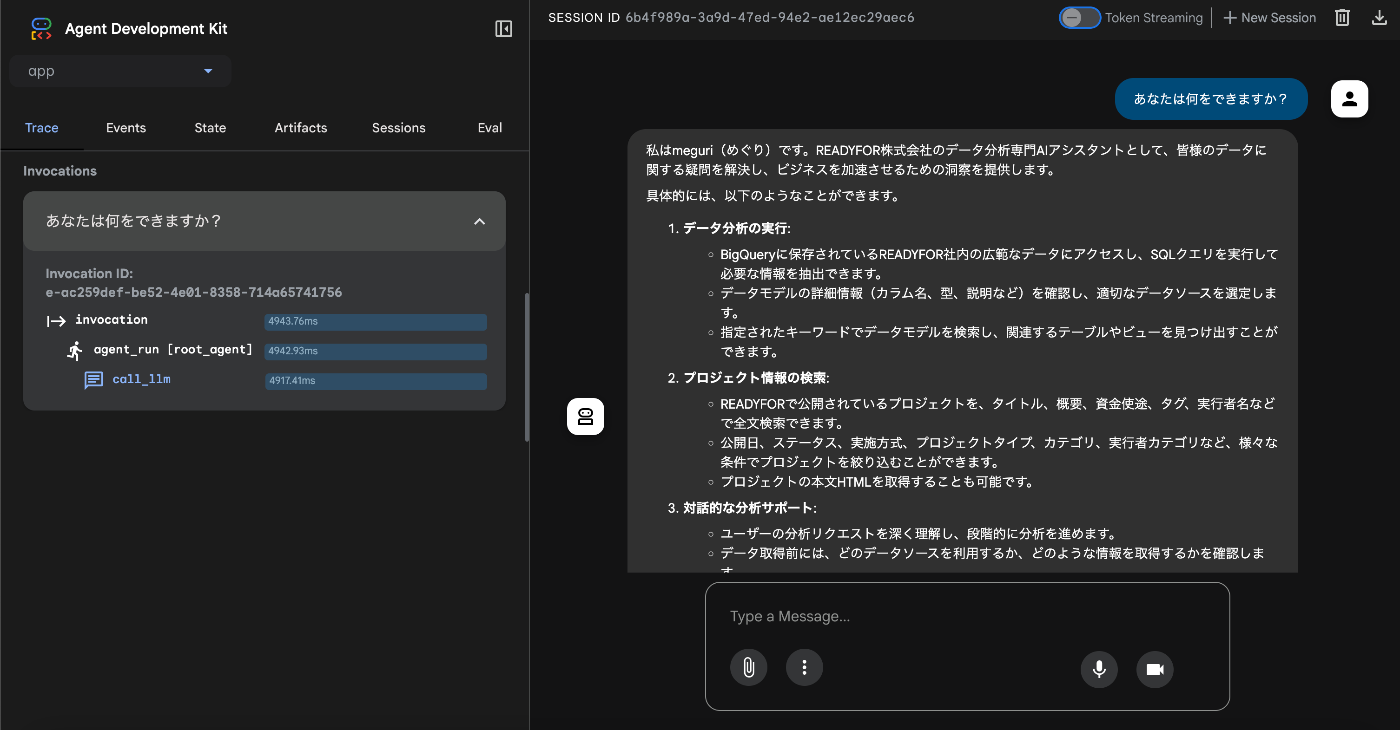
社内のデータ基盤についてエージェントが調べられるようにする必要がありましたが、既存のdbtの資産を活用しました。

Claude Codeで以下のツールを作らせてエージェントにセットし、システムプロンプトを調整しました。
- クエリ実行ツール(ローカルにあるGoogle Cloud機密情報をもとにデータ基盤にクエリを実行)
- データ探索ツール(dbtが生成してくれるデータカタログをもとに、必要なデータがどのテーブルにあるかを探索)
ものの数日で初期プロトタイプは完成しました。
これを先述した「プロダクト自由研究の会」に持ち込み、キュレーターの視点からフィードバックをもらいます。
まだ自分のローカルでしか動かないので、オフィスに持っていって目の前でデモを行いました。
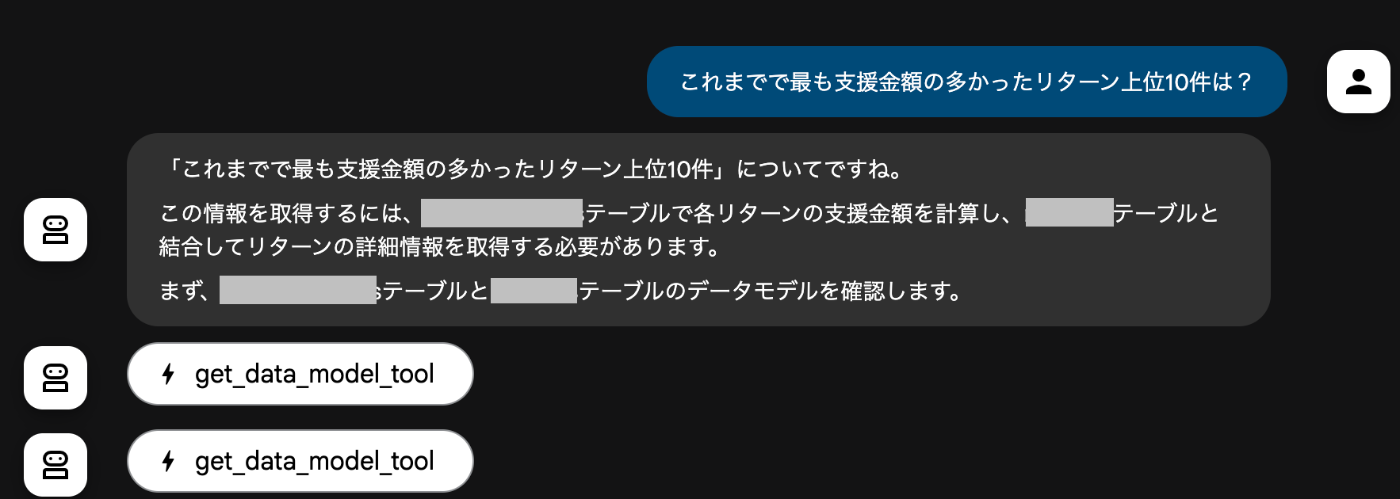
荒削りなところはあれど感触はよく、「欲しいデータをすぐに得られる体験」は何物にも変え難いようでした。
3. Webアプリケーション化
とはいえ、自分のローカルでしか動かないままでは、PoCは進められません。
これなら行けそうだという感触を得てから、Webアプリケーションとして社内に展開できる方法を模索しました。
結果的には、Agent Engine と Cloud Run で稼働させるアーキテクチャに落ち着きました。
詳しくは前回の記事をご参照ください。
社内ではGoogle Workspaceが使われているので、Google Cloud上ならGoogleアカウントによる認証をIdentity-Aware Proxyというサービスにより簡単に実現できます。
この工程には2-3週間ほど要したと思います(元々のプロダクトマネージャーとしての業務もあるので、実際には6-7営業日ほど)。
4. 段階的な利用者拡大
Next.jsのWebアプリケーションとして社内で使ってもらえる環境ができたので、いよいよ現実の業務で試してもらう段階です。
とはいえ最初の段階ではデータの精度には不安があるため、「AIの出してくる結果が妥当かどうかを批判的に判断できるレベルの知識と経験のあるメンバー」に利用を限定しました。
チャット画面にも注意書きを表示しています。

また、最初は Agent Engine や Agent Development Kit (ADK) の使い方について探り探り進めていたので、「突然エージェントが反応しなくなる」「分析結果が出る前に生成を中断してしまう」という事態が起こっていました。
こういった問題を一つずつ潰していって品質を十分なものに持っていくためにも、段階的に利用者を広げていくことは有効でした。
ただ、社内ではデータ分析エージェントへのニーズはキュレーター以外からも多く寄せられ、営業・広報・マーケティング・カスタマーサクセス・カスタマーサポートと、利用者の幅を徐々に広げていきました。
5. 利用状況の分析と改善
利用者が増えていくと、
- エージェントがどういった部署で何のために使われているのか
- どれくらいの人数や頻度で使われているのか
- どういった質問だと回答精度が悪いのか
などの状況を把握するのがあっという間に難しくなります。
早い段階で、利用状況の可視化・分析のための仕組みを作ることをおすすめします。
今のエージェントでは、Agent Starter Packで作られたコードを踏襲しながら、Cloud LoggingからBigQueryに利用ログを出力する方式を採用しました。
ユーザーがAIにメッセージを送るたびに、その内容をセッションIDなどと紐づけてログに出力しています。
また、👍/👎によるフィードバックボタンも配置し、これが押されたときのログも出力しています。
速度優先で、自前のデータベースを持たずにここまで運用しているので、気軽にBigQueryにログを出力できる方法があるのは非常に便利でした。
BigQueryに出してしまえば、それをスプレッドシートに連携したり、LookerStudioにダッシュボードを作成したりするのは容易です。
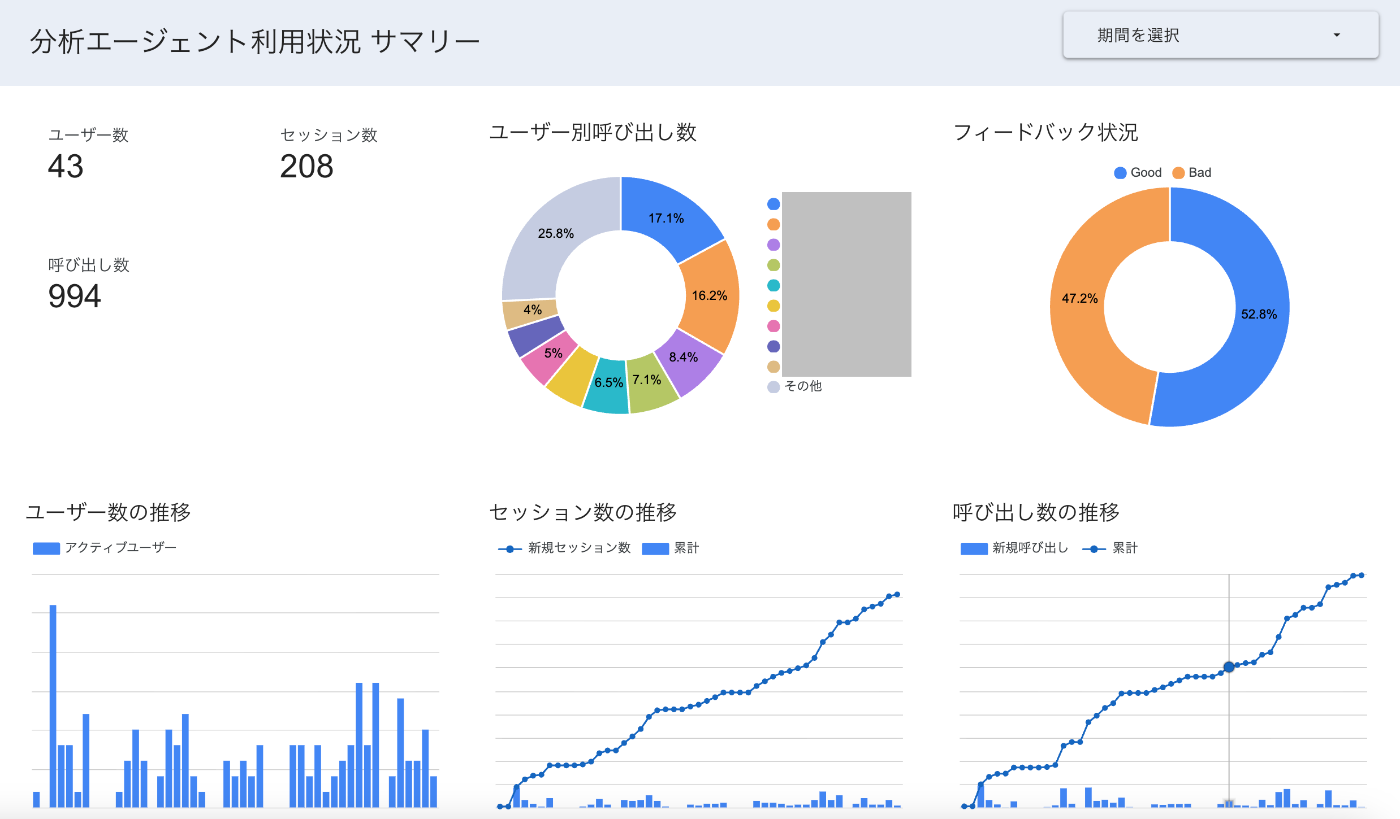
利用状況を定量指標で可視化するとともに、Good/Bad/その他ごとに各ユーザーがどんなことをエージェントに聞いているのかをウォッチしながら、改善の方向性を検討しています。


「みんなの想いを集め、社会を良くするお金の流れをつくる」READYFORのエンジニアブログです。技術情報を中心に様々なテーマで発信していきます。 ( Zenn: zenn.dev/p/readyfor_blog / Hatena: tech.readyfor.jp/ )
Discussion