ArrayExpressからlftpコマンドで巨大なデータをダウンロードする
ArrayExpressのデポジットデータで巨大なファイルのダウンロードに躓いた対処を記録しておく。
デモデータ
130例の末梢血サンプルのシングルセル解析論文。2021年 Nature Medicine。
データはArrayExpressにdepositされていた。
ダウンロード可能なファイルを見ると、7.19GBのh5adファイルがあり論文の処理済みデータが落とせそう。

Download all filesをクリックすると、4通りのダウンロード方法を示してくれる。
データが巨大なのでもちろんブラウザからダウンロードは断念。(rdsファイル以外はブラウザからダウンロードできた。)
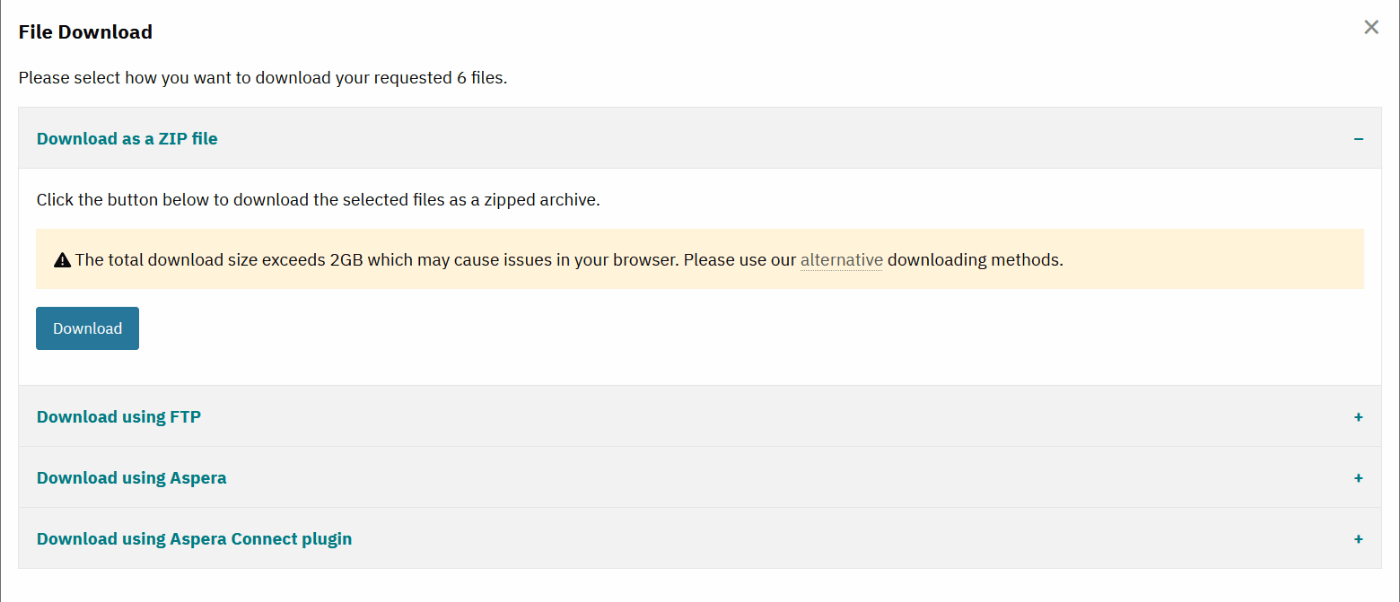
FTPダウンロードで、Unixを選択すると、ダウンロード工程を示してくれる。

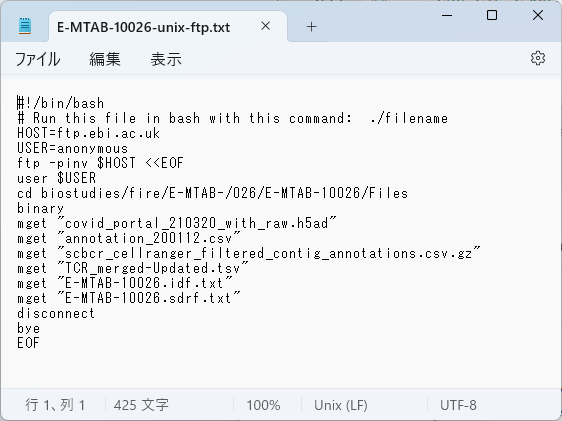
Downloadを押すと、ダウンロードスクリプトが落とせるので、これをWSLで実行すれば良いだけの状態である。とても親切。
(AsperaはIBMでアカウント作ったりがなんか嫌だったので、試していない。Aspera Connect Pluginは登録なしでいけるかも。Aspera Connectとウェブブラウザの拡張機能アドインを入れて、ウェブブラウザからダウンロード?)
いざダウンロードスクリプトを実行してみるも、途中で止まる。。。
cat ./E-MTAB-10026-unix-ftp.txt | sh
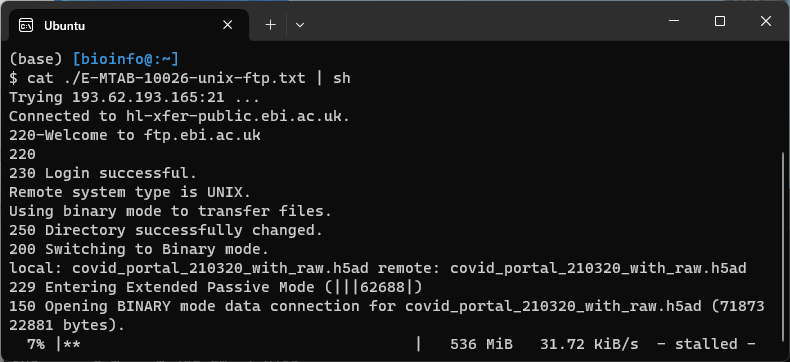
途中で接続で切れてるのか、タイムアウトしてるのかわからないが、もう一度スクリプトを流しても途中から再開できず。。。
ということでダウンロードスクリプトを見直す。mgetコマンドのところで止まっているようだ。
#!/bin/bash
# Run this file in bash with this command: ./filename
HOST=ftp.ebi.ac.uk
USER=anonymous
ftp -pinv $HOST <<EOF
user $USER
cd biostudies/fire/E-MTAB-/026/E-MTAB-10026/Files
binary
mget "covid_portal_210320_with_raw.h5ad"
mget "annotation_200112.csv"
mget "scbcr_cellranger_filtered_contig_annotations.csv.gz"
mget "TCR_merged-Updated.tsv"
mget "E-MTAB-10026.idf.txt"
mget "E-MTAB-10026.sdrf.txt"
disconnect
bye
EOF
chatGPTに改善策を聞いて、wget -cやlftpコマンドなどの改善案を教えてもらった。lftpコマンドでうまくいったので記録として残しておく。(その他は試していない。)
lftpが無ければインストールから。
sudo apt install lftp
以下をWSLで打ち込む。
HOST=ftp.ebi.ac.uk
USER=anonymous
REMOTE_DIR=biostudies/fire/E-MTAB-/026/E-MTAB-10026/Files
LOCAL_DIR=./ # ダウンロード先のディレクトリを指定
lftp -e "
open ftp://$HOST;
user $USER;
lcd $LOCAL_DIR;
cd $REMOTE_DIR;
mirror --continue --verbose --parallel=2 \
--include-glob covid_portal_210320_with_raw.h5ad \
--include-glob annotation_200112.csv \
--include-glob scbcr_cellranger_filtered_contig_annotations.csv.gz \
--include-glob TCR_merged-Updated.tsv \
--include-glob E-MTAB-10026.idf.txt \
--include-glob E-MTAB-10026.sdrf.txt;
bye;
"
Password:という行が表示され、パスワード要求された。
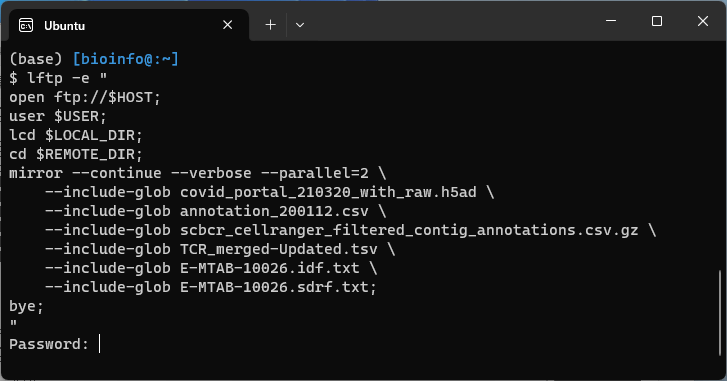
元のダウンロードスクリプトを見てもそれっぽいのは無いので、何も入れずにEnterを押すだけで進んだ。
無事ダウンロードが成功した。
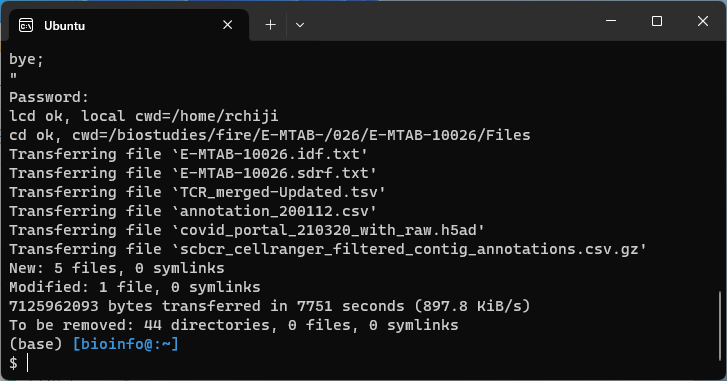
REMOTE_DIRの場所とmirror --include-globの指定ファイルを変えれば、他のアクセッション番号のものもいけそう。
Discussion