RAGで難しいドキュメントはExcelかも、助けて!😢
はじめに
私は普段よりRAG検索精度向上に取り組んでいるエンジニアです。今はいわゆる通常のSaaSを活用した検索モデル(AzureAIサーチ等)は使用せずに、ossの検索モデルで検索精度向上をトライしています。
今までも様々な案件に取り組んできた結果、RAGの検索精度向上に大きくぶち当たっている課題があり、色々なコメントやアドバイスをいただき解決したいな〜笑(小声)と思っています。
ゴミからはゴミしか生まれない
RAGの検索精度向上には様々な手法がありZennでも多数まとまっています。
しかしながら、経験的にどんなに素晴らしいアルゴリズムやハイパワーなLLMを適用したとしても、その前に絶対やるべきことがあります。
それは、ゴミからはゴミしか生まれないと言われる通り、RAGでインデックス化する前に構造化して、美しいデータに整形しておくことが最も大事と感じています。いわゆる通常のMLプロジェクトと同様に、RAGの場合は検索モデルやLLMがうまく特徴量を高める形のデータでなければ、ゴミしか生まれないということです。極論全て美しいデータであれば、LLMの性能やEmbeddingの性能を多少落としたとしても検索精度が十分確保できるパターンも存在すると思います。
一般的に想像できる難しいドキュメント
私は今までパワーポイントが一番構造化が難しいドキュメントだと思っていました。例えば、👇のように絵の中に文字が含まれていたり、そもそも文章がほとんど含まれていないスライドなどです。

しかしながら、昨今マルチモーダルなLLMや画像のEmbeddingもOSSでかなり充実した結果、パワーポイントはほとんどのケースで、ある程度の検索精度を確保できるようになったと感じます。
# PEFT 手法のカテゴリー分類
この図は、パラメータ効率的ファインチューニング(PEFT: Parameter-Efficient Fine-Tuning)手法を大きく4つのアプローチに分け、代表的な手法をマッピングしたものです。
---
## 1. Adapters(アダプター系)
- **概要**
モデルの各層に“小さなボトルネック層”(Adapter モジュール)を挿入し、そこだけ学習する手法。
- **代表的手法**
- `Adapters` / `Parallel Adapters`
- `AdaMix` / `MAM Adapter` / `PHM Adapter` / `KronAᵇ₍res₎` / `S4` など
- **特徴**
- 元の重みは凍結しつつ、追加モジュールのみチューニング
- 複数タスク間での切り替えが容易
---
## 2. Soft Prompts(ソフトプロンプト系)
- **概要**
入力トークンの前後に「学習可能な埋め込みベクトル列」(ソフト・プロンプト)を付加し、モデル挙動を変える手法。
- **代表的手法**
- `Prefix-Tuning` / `Prompt-Tuning`
- `WARP` / `Spot` / `IPT` / `LeTS` / `(IA)³` など
- **特徴**
- モデル本体のパラメータには一切手を入れず、非常に軽量
---
> **※ Adapters(①)と Soft Prompts(②)は、いずれも“追加型(additive)”PEFT に分類されます。
---
## 3. Selective(選択的更新系)
- **概要**
既存パラメータの一部だけを選んで更新する手法。
- **代表的手法**
- `BitFit`(バイアス項のみ更新)
- `LN Tuning`(LayerNorm のみ更新)
- `Attention Tuning` / `Diff-Pruning` / `Fish-Mask` / `LT-SFT` / `FAR` など
- **特徴**
- 更新対象を絞ることで計算・保存コストを大幅に削減
---
## 4. Reparameterization-based(再パラメータ化系)
- **概要**
重み行列を低ランク分解や構造分解(クロネッカー分解など)で置き換え、その分解先のみを学習する手法。
- **代表的手法**
- `LoRA`(低ランク分解)
- `KronA`(クロネッカー分解)
- `Intrinsic-SAID` など
- **特徴**
- モデル重みを“再定義”し、最小限のパラメータで調整
---
## 複合手法(交点領域)
- **概要**
上記①〜④を組み合わせ、さらなる効率化や性能向上を図った手法群。
- **例**
- `Compacter`(Adapter+低ランク分解)
- `UniPELT` / `Sparse Adapter` / `Sparse LoRA` / `KronAᵇ₍res₎`
- `PHM Adapter` / `AdaMix` / `S4` など
---
> **出典**
> Lialin, Vladislav; Deshpande, Vijeta; Rumshisky, Anna.
> “Scaling down to scale up: A guide to parameter-efficient fine-tuning.” arXiv:2303.15647 (2023)
もちろん苦手なシーンもありますが、RAGで検索に引っ掛けるだけであれば十分ですし、フローチャートならより理解しやすいパターンが多い気がします。
では、なぜエクセルが難しいのか?
実はエクセルの難しかったポイント
あまりに綺麗じゃないのでナレッジにすべきではないと言えば、それまでなのですが、現場レベルだと👇のようなエクセルが思ったより沢山あります。
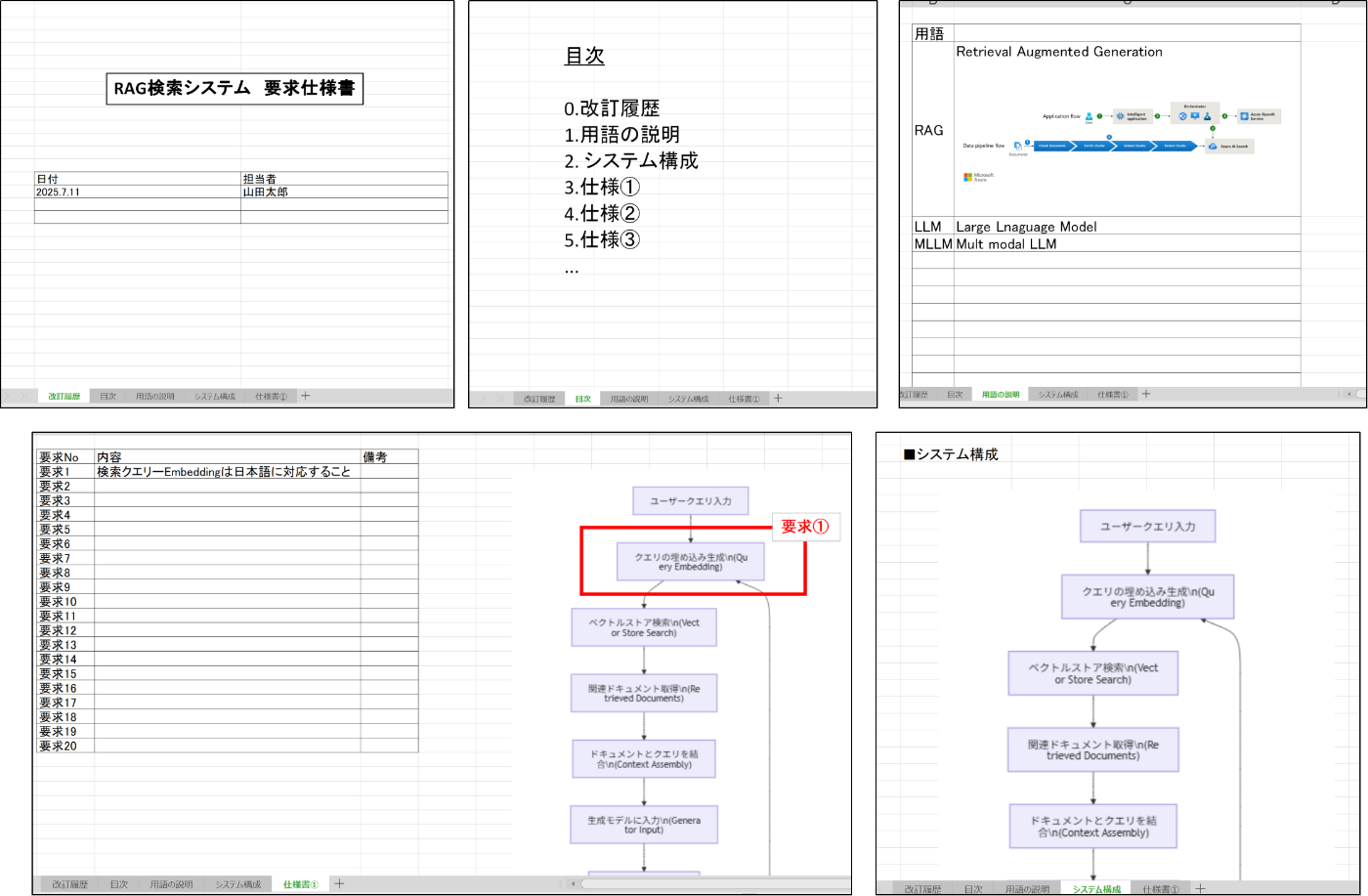
しかも、ナレッジにするべき重要な情報が入っていたり、仕様書だったりする時もあるのでこれを捨てるのは勿体無いと思っています。
- シートごとに縦横のサイズが違うパターンかつ、表に文字が書かれていない
- セルと図形のハイブリッドのパターン
- 図形の中に文字が書かれていたり、テキストボックスに書かれているパターン
👉経験的に上記パターンが非常に扱いずらいです。図形やテキストボックスの中の文字は、例えばpandasやopenpyxlで開いてしまうとなかったことにされてしまうんですよね。あくまでテーブルデータしか読めない。
この手のエクセルの対策
おそらく一番手っ取り早いのは、マルチモーダルLLMやAzureDocumentIntelligence等で画像を読み取り、テキストEmbedding化してしまう手法です。(※用途によってはもちろん画像Embedding化もありです)
openAIのマルチモーダルLLMの場合であれば、base64にエンコードして入力する必要がありますが、エクセルをいきなりbase64に変換はできないので、PDFに一度してbase64の画像エンコード化する、というやり方が一般的な流れだと思います。
一般的な手法ではうまくいかず...
PDF化する手法でよくある確実なやり方で、LibreOfficeを使った手法があります。
しかしながら、LibreOfficeでPDF化した時に図が切れてしまう。。
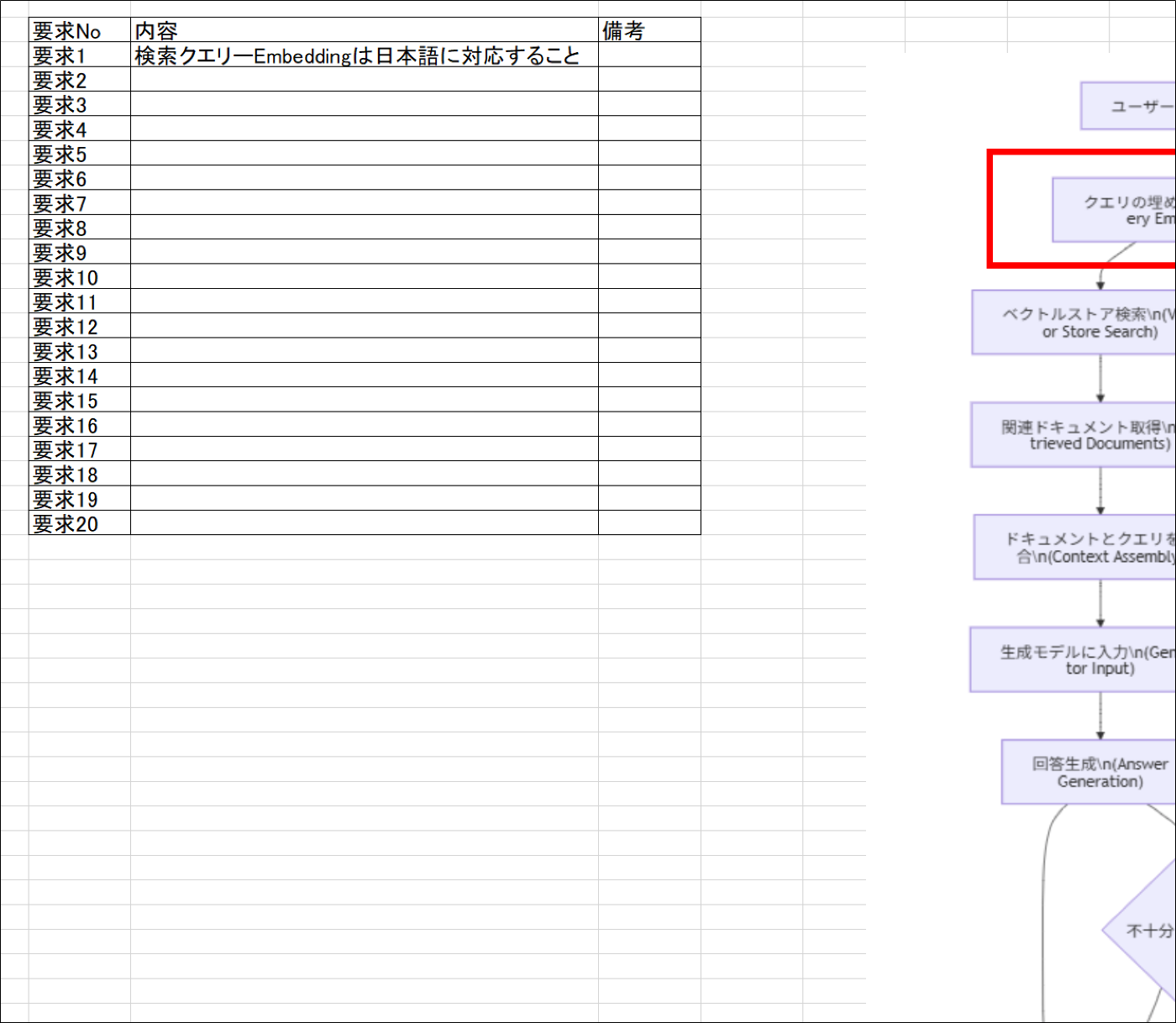
👆のように正しく区切りを捉えられずに切れてしまうことがあります
また、図が切れないようにしても、縦が長すぎるテキストボックスだと画像が小さくなりすぎて、解像度が悪化。マルチモーダルLLMの読み取り精度がガタ落ちになってしまいます。
どうすればいいんだ!
残念ながら。。実はまだ解決していません。
chatGPTに聞いたら、unoというライブラリでLibreOfficeをうまく制御できそう、ということは分かりましたが。。、うまく動作せず。どなたか良いソリューション知らないでしょうか。ぜひコメントください🙏 可能な限り、有料サービスを使わずに頑張りたいです(とワガママを一言。。)
Discussion
GoogleDriveやOneDriveのPDFエクスポート機能を使用すると、いい感じでPDFにできると思います。
お金はかかりますが...