機械学習(簡単なモデル作成)
初めに
この記事では簡単な機械学習のモデルを作ってみます。モデルとは入力データに対して出力データを導き出す仕組みのことです。(後ほどもう少し説明します。)
環境はgoogle colabotoryを使っています。
今回はkaggleのMelbourne Housing Snapshotのmelb_data.csvというデータを用います。
まずpandasをインポートします。pd.set_optionにより、表示する行数を最大で5行、列数を12行にしています。(このコードは実行しなくても構いません。)次にデータを読み込みます。(パスはダウンロードしたフォルダを指定して下さい。)さらにデータの先頭5行を表示します。
import pandas as pd
pd.set_option('max_rows', 5)
pd.set_option('max_columns', 12)
melb_data = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/datasets/melb_data.csv')
melb_data.head()
・出力
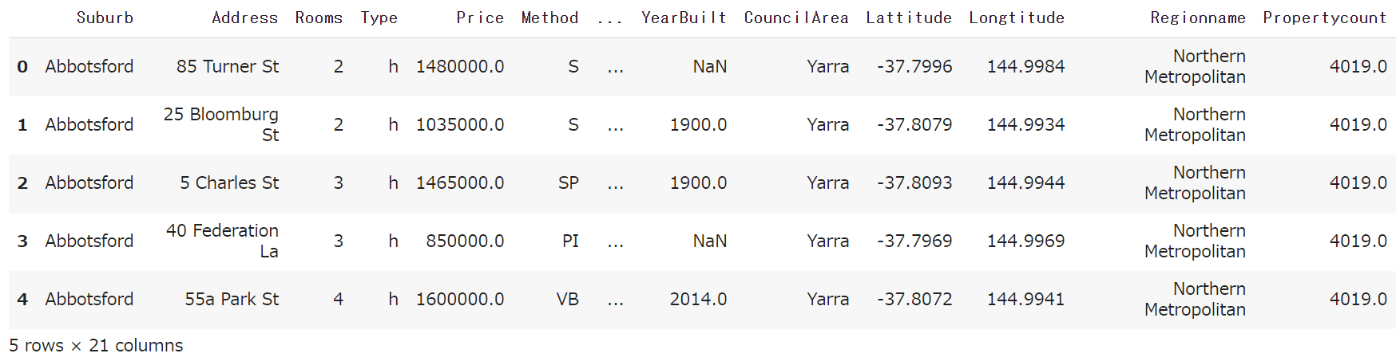
列の名前を全て表示することができていないので、以下のコードで確認します。
melb_data.columns
・出力

欠損値について
データにはしばしば欠損が存在します。例えば、'YearBuilt'列の最初のデータはNaNとなっていて、これはデータが欠損していることを表しています。モデルの多くは欠損を含むデータを扱えないので、何らかの処理が必要となります。この記事では欠損値の処理について触れないため、欠損を含むデータは行単位で削除しようと思います。
まず、このデータには欠損値が含まれているのかを確認したいと思います。
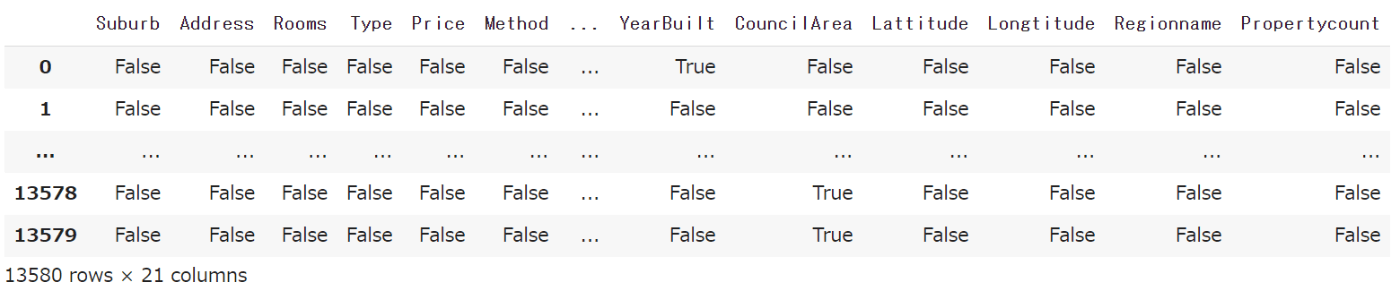
以下のコードにより、各要素が欠損値である場合はTrue、欠損値でない場合はFalseと表示されます。例えば、'YearBuilt'列の最初のデータは欠損値(NaN)であるため、Trueと表示されます。
melb_data.isnull()
・出力
より具体的に欠損値が何個あるのか知りたい場合は以下のコードを実行します。
melb_data.isnull().values.sum()
・出力
13256
以上よりこのデータは欠損値を13256個含んでいることが確かめられました。ここでは、欠損値を含む行を全て削除したいと思います。欠損値を行もしくは列ごと削除したい場合は、pd.DataFrame.dropnaを用います。引数のaxisを0にすると行ごとに、1にすると列ごとに削除します。
melb_data = melb_data.dropna(axis=0)
では欠損値がなくなったことを確認しましょう。
melb_data.isnull().values.sum()
・出力
0
目的変数と説明変数について
データの中から目的変数を選択します。目的変数とは予測したい変数のことで、モデルの出力にあたります。ここでは'Price'を選択します。DataFrameから列を取り出す方法はこちらの記事で説明しています。
y = melb_data['Price']
次に、説明変数を選択します。説明変数とは目的変数の原因となる変数のことで、モデルの入力に使われるデータのことです。予測したい変数'Price'以外を説明変数とします。この際、先ほど紹介したpd.DataFrame.dropnaを用いて全体のデータmelb_dataから'Price'列を取り除きます。
X = melb_data.drop(['Price'], axis=1)
量的変数と質的変数
さて、ここで説明変数Xの中身を見てみます。
X.head()
・出力
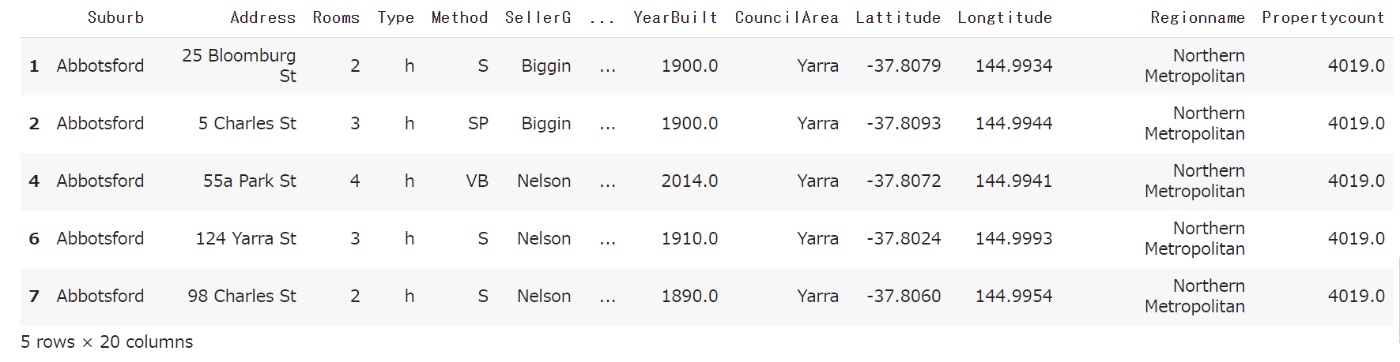
例えば、'Rooms'列を見ると、2,3といった数字となっています。このように数値で表されるデータを量的変数といい、このようなデータはモデルの入力として用いることができます。一方、'SellerG'列を見ると、'Biggin','Nelson'といったカテゴリとなっています。これらのデータは数値となっておらず、そのままモデルの入力に用いることはできないため、何らかの処理が必要となります。この記事では質的変数の変換について触れないため、量的変数のみ用いようと思います。DataFrameからある特定の型のみを抽出したい場合は、pd.DataFrame.select_dtypesを用います。引数includeを['number']にすると数値データのみ抽出できます。
X = X.select_dtypes(include=['number'])
モデルの作成
最後に説明変数('Price'以外)から目的変数('Price')を導くようなモデルを作成したいと思います。モデルの作成にはscikit-learnというライブラリを用います。コードを書く際はsklearnと書きます。sklearnには様々な機械学習アルゴリズムがありますが、ここではsklearn.tree.DecisionTreeRegressorを用います。まずは、sklearn.tree.DecisionTreeRegressorをインポートします。
from sklearn.tree import DecisionTreeRegressor
次にモデルの定義を行います。引数がたくさんありますが、ここではrandom_stateのみ指定します。(random_stateに任意の整数を固定することで結果を固定することができます。)
model = DecisionTreeRegressor(random_state=0)
次にモデルの学習を行います。これにより、説明変数と目的変数の関係性を学習することができます。
model.fit(X, y)
・出力
DecisionTreeRegressor(random_state=0)
最後にこのモデルを使って予測をしたいと思います。入力データとしてはXの先頭5行にします。
model.predict(X.head())
・出力
array([1035000., 1465000., 1600000., 1876000., 1636000.])
終わりに
「モデルの作成」という項目において、モデルを学習し、そのモデルを用いて予測するということを行いました。ここでは、モデルの学習の際はXとyというデータを用いており、予測の際はXのデータの一部を用いています。つまり、モデルの学習と予測で同じデータを用いていますが、普通はモデルの学習で用いていない未知のデータに対して予測を行います。
Discussion