pandas(値の抽出・代入)
初めに
この記事では、pandasのDataFrameやSeriesから特定の値を取り出す方法を説明します。
環境はGoogle Colaboratoryを使っています。
今回はkaggleのWine Reviewsのwinemag-data-130k-v2.csvというデータを用います。
まず、pandasをインポートしデータを読み込みます。(パスはダウンロードしたフォルダを指定して下さい。)また、pd.set_option('max_rows', 5)とすることで、表示する行数を最大で5行にすることができます。
import pandas as pd
reviews = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/datasets/wine_reviews/winemag-data-130k-v2.csv", index_col=0)
pd.set_option('max_rows', 5)
reviews
・出力

列の取り出し方
reviewsというDataFrameからcountryという列だけを取り出します。それには以下の二種類の方法があります。
reviews.country
reviews['country']
・出力

基本的にどちらの方法も同じように列を取り出すことができますが、例えばcountry nameといった列の名前に空白を含む列を取り出したい場合は、reviews.country nameとすることはできず、reviews['country name']のように[]を使う必要があります。
なお、reviewsからcountryという列の最初の行だけ取り出したい場合は以下のようにします。
reviews['country'][0]
・出力
'Italy'
ilocとloc
ilocやlocを用いて、DataFrameから特定の値を抜き出すこともできます。
iloc
ilocはindexを指定することで、特定の値を抽出できます。
例えば最初の行を抽出したい場合は、以下のコードを実行します。
reviews.iloc[0]
・出力

ilocとlocを使う際は、行を最初に、列を二番目に書きます。これは一般的なpythonにおける参照の仕方とは逆になっているため、注意が必要です。
最初の列を抽出したい場合は以下のコードを実行します。
reviews.iloc[:, 0]
・出力

いくつかの行や列をまとめて抽出したい場合は、:を用います。例えば、reviewsのcountry列を初めから3行分抽出したい場合は、以下のようにします。
reviews.iloc[:3, 0]
・出力

以下のようにリストを用いてインデックスを指定することもできます。
reviews.iloc[[0, 1, 2], 0]
また、インデックスの指定には負の値を用いることもできます。例えば、reviewsの最後から5行分を抽出したい場合は以下のようにします。
reviews.iloc[-5:]
・出力

loc
locは行や列の名前を指定することで、特定の値を抽出できます。
例えば一番初めの値を取り出したい場合は以下のようにします。
reviews.loc[0, 'country']
・出力
'Italy'
また、'price', 'taster_twitter_handle', 'points'という列を抽出したい場合は以下のようにします。
reviews.loc[:, ['price', 'taster_twitter_handle', 'points']]
・出力

ilocとlocの違い
ilocは範囲の最初の要素を含み、最後の要素を除外します。一方、locは範囲の最後の要素も含みます。
したがって以下のような違いを生じます。
reviews.iloc[:10, 0]
・出力

reviews.loc[:10, 'country']
・出力

条件に合う値を抽出する
データの中から条件に合う値だけを抽出することもできます。
例えば、以下のコードからワインがイタリア産かどうかがわかります。
reviews.country == 'Italy'
・出力

上記のコードを利用してreviewsの中からイタリア産のワインのみを抽出することができます。
reviews.loc[reviews.country == 'Italy']
・出力

次は、イタリア産かつ得点が95点以上のワインのみを抽出します。2つの条件を両方とも満たすものを抽出したい場合は、&を用います。
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 95)]
・出力

イタリア産または得点が95点以上のワインを抽出したい時は|を用います。
reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 95)]
・出力
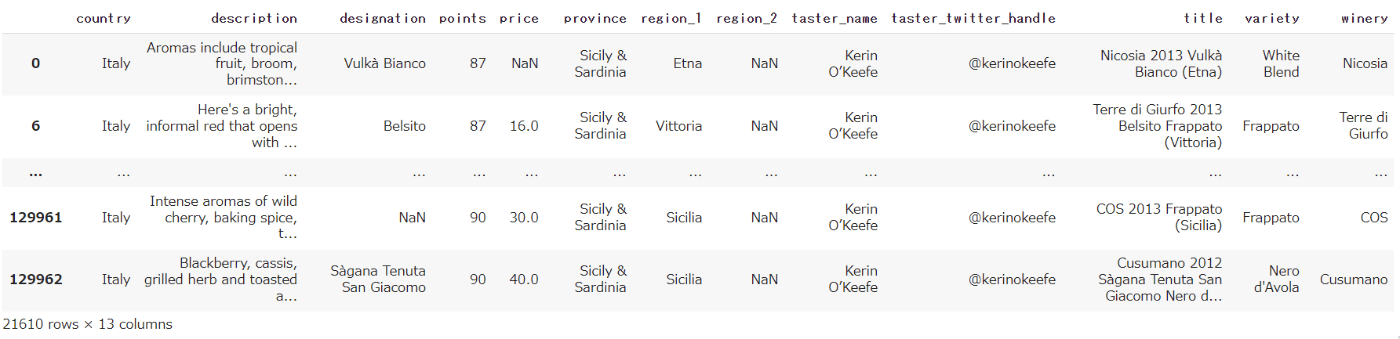
イタリア産またはアメリカ産のワインを抽出したい場合は、isinを用いることができます。
reviews.loc[reviews.country.isin(['Italy', 'US'])]
・出力

'designation'列に欠損値のないデータのみを抽出したいという場合はnotnullを用います。
reviews.loc[reviews.designation.notnull()]
・出力

データの代入
データを代入することもできます。上の出力を見ると、price列の最初のデータがNaNとなっていて欠損しています。そこでこのデータに0を代入してみます。
reviews.loc[0, 'price'] = 0
もう一度reviewsを確認すると、price列の最初のデータに0が代入されていることが分かります。
reviews
・出力

Discussion