Go の基本
ポインタと構造体
- ポインタ
- 変数の値を保持するメモリアドレス。変数への参照。
- 変数のポインタを取得することを referencing、変数のポインタから値を取得することを dereferencing(または indirecting)という
- referencing:
&v - dereferencing:
*p
- referencing:
- 構造体
- 構造体はフィールドの集まり。異なる型の値を保持できる型。
structキーワードを使って宣言する。 - フィールドへのアクセス
- フィールドのへのアクセスは
.演算子を使う。 - 構造体のポインタからフィールドへアクセスしたい場合、ポインタの dereferencing を利用して
(*p).Fieldとすることでフィールドへアクセスできる。ただし Go では、syntax sugar としてポインタの dereferencing をしなくてもp.Fieldとすることでフィールドへアクセスできる仕様になっている。
- フィールドのへのアクセスは
- 構造体はフィールドの集まり。異なる型の値を保持できる型。
補足として、Go のメソッドと変数レシーバ、ポインタレシーバの関係にも、このような syntax sugar が定義されている。
構造体とポインタの挙動の確認
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
// 構造体の宣言
v := Vertex{1, 2} // T: Vertex
p := &v // T: *Vertex
fmt.Println(v)
fmt.Println(p)
// referencing / dereferencing
p.X = 1e9 // syntax sugar of (*p).X
fmt.Println(v)
(*p).X = 500
fmt.Println(v)
(&(*p)).X = 1000
fmt.Println(v)
(*(&(*p))).X = 1500
fmt.Println(v)
}
- 出力
{1 2}
&{1 2}
{1000000000 2}
{500 2}
{1000 2}
{1500 2}
defer / panic / recover
- references
defer / panic / recover の挙動確認
package main
import "fmt"
func main() {
f()
fmt.Println("Returned normally from f.")
}
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered in f", r)
}
}()
fmt.Println("Calling g.")
g(0)
fmt.Println("Returned normally from g.")
}
func g(i int) {
if i > 3 {
fmt.Println("Panicking!")
panic(fmt.Sprintf("%v", i))
}
defer fmt.Println("Defer in g", i)
fmt.Println("Printing in g", i)
g(i + 1)
}
- 出力
Calling g.
Printing in g 0
Printing in g 1
Printing in g 2
Printing in g 3
Panicking!
Defer in g 3
Defer in g 2
Defer in g 1
Defer in g 0
Recovered in f 4
Returned normally from f.
スライス
- references
-
Go Blog: Go Slices: usage and internals
- スライスの基本的な挙動が書いてある
-
Go Blog: Go Slices: usage and internals
range
for ループに利用する range は、スライスや、マップをひとつずつ反復処理するために使う。
基本
スライスを range で繰り返す場合、range は反復毎に 2 つの変数を返す。1 つ目の変数は要素のインデックス、2 つ目はインデックスの場所の要素のコピーである。
package main
import "fmt"
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
出力
2**0 = 1
2**1 = 2
2**2 = 4
2**3 = 8
2**4 = 16
2**5 = 32
2**6 = 64
2**7 = 128
インデックスや要素の省略
インデックスや値は、 _ (アンダーバー)へ代入することで捨てることができる。
for i, _ := range pow
for _, value := range pow
もしインデックスだけが必要なのであれば、2 つ目の値を省略することもできる。
for i := range pow
例
package main
import "fmt"
func main() {
pow := make([]int, 10)
for i := range pow {
pow[i] = 1 << uint(i) // == 2**i
}
for _, value := range pow {
fmt.Printf("%d\n", value)
}
}
早すぎる最適化はしてはいけないが、明らかにスライスやマップの要素のコピーコストがかかると分かる場合は、上記の for i range pow ように要素のコピーを避け、インデックスを用いてスライスの要素を参照すれば良い。
A Tour of Go:スライスの練習
問題文
Pic 関数を実装してみましょう。 このプログラムを実行すると、生成した画像が下に表示されるはずです。 この関数は、長さ
dyの slice に、各要素が 8 bit の unsigned int 型で長さdxの slice を割り当てたものを返すように実装する必要があります。 画像は、整数値をグレースケール(実際はブルースケール)として解釈したものです。生成する画像は、好きに選んでください。例えば、面白い関数に、 (x+y)/2 、 x*y 、 x^y などがあります。
ヒント:( [][]uint8 に、各 []uint8 を割り当てるためにループを使用する必要があります)
ヒント:( uint8(intValue) を型の変換のために使います)
実装
- Go Playground で実行
- ポイント
- Go では関数は第一級オブジェクトである。つまり、変数の値、関数の引数、関数の戻り値として扱うことができる(参考:Function values | A Tour of Go)。
package main
import (
"golang.org/x/tour/pic"
)
type calcFunc func(int, int) uint8
type Pic func(int, int) [][]uint8
// 特定の計算方法を関数として渡して pic.Show() に渡す Pic 関数を生成する
func generatePicFunc(f calcFunc) Pic {
return func(dx, dy int) [][]uint8 {
var s [][]uint8 = make([][]uint8, dy)
for i := 0; i < dy; i++ {
var xs []uint8 = make([]uint8, dx)
for j := 0; j < dx; j++ {
xs[j] = f(i, j)
}
s[i] = xs
}
return s
}
}
func main() {
calcFuncs := []calcFunc{
func (x, y int) uint8 { return uint8(x+y) },
func (x, y int) uint8 { return uint8((x+y)/2) },
func (x, y int) uint8 { return uint8(x*y) },
func (x, y int) uint8 { return uint8(x^y) },
}
// pic.Show(generatePicFunc(calcFuncs[0]))
// pic.Show(generatePicFunc(calcFuncs[1]))
// pic.Show(generatePicFunc(calcFuncs[2]))
pic.Show(generatePicFunc(calcFuncs[3]))
/*
// ↓ のコードだと画像が表示されない。
// 一つの画像を表示する実装じゃないとダメみたい。
// これは 多分 pic の仕様の問題。
for _, f := range calcFuncs {
pic.Show(generatePicFunc(f))
}
*/
}
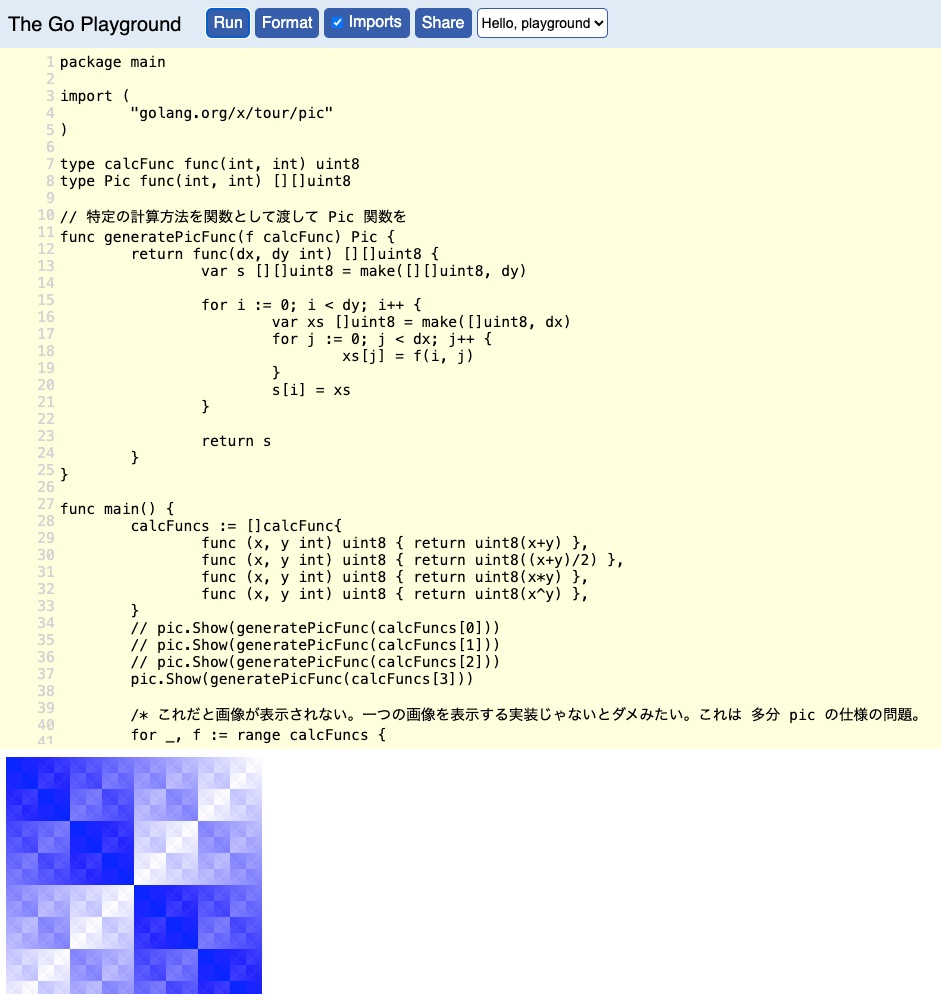
上記コードを実行すると、以下のような画像がコンソールに表示される。
マップの仕様
v, ok := m["key"] のように、存在しないキーに対してアクセスを行った場合 v にはゼロ値が入るが、これによってマップ自体に m["key"] の要素が作成されることはない(ゼロ値で初期化されるというわけではない)。つまり、存在しないキーに対して何度アクセスしてもゼロ値が返ってくるだけ。m["key"] = xxx のように明示的に値を代入して初めてキーが作成される。
キーがないときはゼロ値。明示的に代入すると map にそのキー(と値)が作られ、次回アクセスのときは「キーがあるから ok には true を返す。
package main
import "fmt"
func main() {
m := make(map[string]int)
m["Answer"] = 42
fmt.Println("The value:", m["Answer"])
m["Answer"] = 48
fmt.Println("The value:", m["Answer"])
delete(m, "Answer")
fmt.Println("The value:", m["Answer"]) // 存在しないキーに対してアクセス
v, ok := m["Answer"]
fmt.Println("The value:", v, "Present?", ok) // 存在しないキーに対してアクセス
v, ok = m["Answer"]
fmt.Println("The value:", v, "Present?", ok) // 存在しないキーに対してアクセス。出力は変わらない。
}
A Tour of Go:Function closures
クロージャとは?
- クロージャ closure
- 環境を持つ関数。実行時の環境を保持する関数。
Go の関数とクロージャ
Goの関数は クロージャ(closure)である。
クロージャは、それ自身の外部から変数を参照する関数値である。クロージャは、関数生成時に関数外部に存在する変数へアクセスしてその値を変えることができ、その意味では、関数は変数へ "バインド"(bind)されている(実行時の環境へ束縛されている)と言える。
例えば、以下の adder 関数はクロージャを返している。adder 関数によって作られた各クロージャ pos、neg は、各々が sum という変数が存在する環境へバインドされる。関数ごとに環境が作られている。
クロージャが作られる度に環境が作られるため、クロージャが異なれば環境が異なり、互いの環境への影響を及ぼすことはない(環境を共有するような書き方できる?なんかハマりどころがありそうだけどおかしくなりそうだけどぱっと思いつかない)。以下の例では、クロージャ pos、neg がそれぞれ参照する変数 sum は異なるものであり、pos 内で sum を更新しようがその更新は別の環境である neg の sum には影響しない。
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
pos, neg := adder(), adder()
for i := 0; i < 10; i++ {
fmt.Println(
pos(i),
neg(-2*i),
)
}
}
出力
0 0
1 -2
3 -6
6 -12
10 -20
15 -30
21 -42
28 -56
36 -72
45 -90
練習:フィボナッチ数列を返す関数をクロージャで実装する
以下に実装した関数 fibonacci は「フィボナッチ数列の要素を戻り値とするクロージャ」を返す関数である。f() でクロージャが実行される際の処理の流れは以下のようになっている。
- (
f := fibonacci()でクロージャの初期化(環境の初期化)) -
ret := v0で現在のフィボナッチ数列の要素をコピー -
v0, v1 = v1, v0 + v1で環境の変数(フィボナッチ数列の要素)を更新する -
retを返す - (次回実行時は更新された
v0、v1によって次のフィボナッチ数列の要素が返される)
package main
import "fmt"
func fibonacci() func() int {
v0, v1 := 0, 1
return func() int {
ret := v0
v0, v1 = v1, v0 + v1
return ret
}
}
func main() {
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Printf("f%d: %d\n", i, f())
}
}
メソッド、レシーバ
メソッド、レシーバ
- メソッド
- 型に対して紐付ける関数
- 多言語におけるクラスとそのインスタンスに紐づくメソッドと同じようなもの
- メソッドは同じパッケージに存在する型に対して定義できる(パッケージスコープ)
- レシーバ
- メソッドは一般の関数と異なり、レシーバという特別な引数を取る。レシーバはメソッド自身が紐づけられた型のオブジェクトである。
- 多言語におけるクラスの
selfやthisみたいなもの
- ポインタレシーバ(Pointer receivers | A Tour of Go)
- ポインタとして定義したレシーバ
- ポインタレシーバを持つメソッドは、レシーバが指す変数を変更できる。実際のソフトウェアではレシーバ自身を更新することが多いため、変数レシーバよりもポインタレシーバの方が一般的。対して、変数レシーバでは、元の変数のコピーを操作する。これは関数の引数としての振るまいと同じ。
メソッドとポインタレシーバ
メソッドがポインタレシーバである場合、呼び出し時に、変数、または、ポインタのいずれかのレシーバとして取ることができる。つまり、ポインタでなくとも、特定の型の変数(v T)からポインタレシーバを受け取るメソッド(func (v *T) Method(...) {...})を直接呼ぶことが出来る。これは Go の v.T を (&v).T として解釈する syntax sugar である。
以下の例では、v.Scale(5) という式における v は変数であり、ポインタではないが、メソッドでポインタレシーバが自動的に呼びだされる。Scale メソッドがポインタレシーバを受け取る場合、Goは利便性のため、 v.Scale(5) のステートメントを (&v).Scale(5) として解釈する。
type Vertex struct {
X, Y int
}
func (v *Vertex) Scale(f int) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
v := Vertex{3, 5}
// 以下のどっちも実行できる
(&v).Scale(10)
v.Scale(10) // (&v).Scale(10) の syntax sugar
}
例
package main
import (
"fmt"
)
type Vertex struct {
X, Y float64
}
func (v Vertex) _Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
func main() {
var v Vertex = Vertex{3.0, 5.0}
fmt.Println(v)
// ポインタレシーバを呼び出す
p := &v
p.Scale(10) // OK
fmt.Println(v)
// ポインタレシーバは変数から直接呼ぶことができる
v.Scale(10) // OK, "(&v).Scale(10)" の syntax sugar
fmt.Println(v)
// 変数レシーバを呼び出す
v._Scale(10)
fmt.Println(v) // v は変数レシーバなので v のフィールドは変わらない
}
出力
{3 5}
{30 50}
{300 500}
{300 500}
メソッドと変数レシーバ
逆もしかり。
上の例とは反対に、メソッドが変数レシーバを受け取る場合、呼び出し時に、変数、または、ポインタのいずれかのレシーバとして取ることができる。つまり、特定の型のポインタ型変数(v *T)から変数レシーバを受け取るメソッド(func (v T) Method(...) {...})を直接呼ぶことが出来る。これは Go の v.T を (*v).T として解釈する syntax sugar である。
例
package main
import (
"fmt"
"math"
)
type Vertex struct {
X, Y float64
}
func (v Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func AbsFunc(v Vertex) float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
v := Vertex{3, 4}
fmt.Println(v.Abs())
fmt.Println(AbsFunc(v))
p := &Vertex{4, 3}
fmt.Println(p.Abs())
fmt.Println(AbsFunc(*p))
}
ポインタレシーバと変数レシーバの挙動まとめ
- 型
Tのポインタレシーバfunc (v *T) myFunc(...) {...}を変数v Tから呼べる-
v.Tが(&v).Tとして解釈される
-
- 型
Tの変数レシーバfunc (v *T) myFunc(...) {...}を変数v *Tから呼べる-
v.Tが(*v).Tとして解釈される
-
ポインタレシーバが使う理由
- メソッドがレシーバが指す先の変数を変更するため
- メソッドの呼び出し時に変数のコピーを避けるため
- 例えば、レシーバが大きな構造体である場合に有効で、コピーのコストを下げることができる
一般的には、変数レシーバ、または、ポインタレシーバのどちらかで全てのメソッドを統一して定義する方が良く、混在させるべきではない。
インタフェース Interfaces
- [Interfaces | A Tour of Go]
- Interface types | GoSpec
インタフェースとは?
- interface
- メソッドの集合を定義する型。interface に定義されたメソッドの集合を保持する変数の値は interface 型の変数へ代入することができる。特定の interface に定義されたメソッドの集合を保持する変数の値は「インタフェースを実装している(implement the interface)」と言われる。
- 特定の( interface でない)型に対して、あるインタフェースで定義されたメソッドの集合を定義していき、その型で変数を宣言した時、その変数の値はインタフェースを実装している。Go では、インタフェースを実装することを明示的に宣言する必要はない(Java のように
implementsキーワードは必要ない)。暗黙のインタフェースは、インタフェースの定義をその実装から切り離す。インタフェースの実装は、事前の取り決めなしにパッケージに現れることがある。
Inteface を実装する
Vertex は、Abs というメソッドを持たないためコンパイルエラーになる。これは Abs メソッドが Vertex ではなく *Vertex の定義であり、Vertex が Abser インタフェースを実装していないということになるため、エラーになる。
package main
import (
"fmt"
"math"
)
type Abser interface {
Abs() float64
}
// 変数レシーバを持つメソッドを持つ型を定義
type MyFloat float64
func (f MyFloat) Abs() float64 {
if f < 0 {
return float64(-f)
}
return float64(f)
}
// ポインタレシーバを持つメソッドを持つ型を定義
type Vertex struct {
X, Y float64
}
func (v *Vertex) Abs() float64 {
return math.Sqrt(v.X*v.X + v.Y*v.Y)
}
func main() {
var a Abser
f := MyFloat(-math.Sqrt2)
v := Vertex{3, 4}
a = f // a MyFloat implements Abser
a = &v // a *Vertex implements Abser
// In the following line, v is a Vertex (not *Vertex)
// and does NOT implement Abser.
a = v
fmt.Println(a.Abs())
}
以下の例はコンパイルが通る。*T 型の変数の値はメソッド M() を実装しているためインタフェース I 型の実装として扱われる。T 型の変数にはメソッド M() は実装されていないので、インタフェース I 型の実装として扱われない。そのため、main 関数のコメントアウトしてあるコードはコンパイルエラーになる。
package main
import (
"fmt"
"math"
)
type I interface {
M()
}
type T struct {
S string
}
func (t *T) M() {
fmt.Println(t.S)
}
type F float64
func (f F) M() {
fmt.Println(f)
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
func main() {
var i I
// コンパイルエラー
// i = T{"World"} // T 型の変数は M を実装していない
// describe(i)
// i.M()
i = &T{"Hello"} // *T 型の変数は M を実装している
describe(i)
i.M()
i = F(math.Pi)
describe(i)
i.M()
}
インタフェースの値 Interface value
上記で示したように、インタフェース型の変数には、インタフェースで定義されたメソッドの集合を実装している値なら代入することができる。このとき、代入された値は「インタフェースの値」という。
インタフェースの値は、下記のような「値と具体的な型のタプル」のように考えることができる:
(value, type)
インターフェースの値は、特定の基底になる具体的な型の値を保持する。この基底になる型は underlying type という。インターフェースの値のメソッドを呼び出すと、その基底型の同じ名前のメソッドが実行される。
package main
import (
"fmt"
"math"
)
type I interface {
M()
}
type T struct {
S string
}
func (t *T) M() {
fmt.Println(t.S)
}
type F float64
func (f F) M() {
fmt.Println(f)
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
func main() {
var i I
// i = T{"World"}
// describe(i)
// i.M()
i = &T{"Hello"}
describe(i)
i.M()
i = F(math.Pi)
describe(i)
i.M()
}
出力
(&{Hello}, *main.T)
Hello
(3.141592653589793, main.F)
3.141592653589793
インタフェースの値のゼロ値は nil
ここまで示してきたように、インタフェースは「値と型のタプル」のようなものとして考えることができる。以下の例において、インタフェース I を初期化せずに出力すると、その値と型はどちらも nil として出力される。
package main
import "fmt"
type I interface {
Method()
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
func main() {
var i I
describe(i)
}
出力
(<nil>, <nil>)
ここで注意したいのは、上記の変数 i は I 型の変数であるにも関わらず、fmt.Printf("%T", i) で出力したときの型は nil として表示される。これにより、インタフェース型の変数は、特定の基底となる具体的な型の値を保持しなければ値の型は nil として扱われることが分かる。インタフェースを実装する具体的な型の値で初期化、またはインタフェースを実装する具体的な型の値を代入しなければ nil のままである。
インタフェースを実装した特定の型の値を代入すると、その値と型が出力されるようになる。下記のコードにおいて、MyStruct 型の変数 myStruct の値はインタフェース I を実装している。
package main
import "fmt"
type I interface {
Method()
}
type MyStruct struct {}
func (v *MyStruct) Method() {
fmt.Printf("(%v, %T)\n", v, v)
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
func main() {
var i I
describe(i)
var myStruct *MyStruct
i = myStruct
describe(myStruct)
describe(i)
}
出力
(<nil>, <nil>)
(<nil>, *main.MyStruct)
(<nil>, *main.MyStruct)
インタフェース型の変数は nil であるか否か
インタフェース型の変数は、特定の型の値で初期化、または代入しない場合、その変数の値は nil となる。初期化、代入されると変数の値は nil でなくなる。ただし、具体的な値として nil を保持するインターフェイスの値それ自体は非 nil であることに注意する。インターフェース型の「変数の値」と「変数が保持する値」は異なる。
package main
import "fmt"
type I interface {
Method()
}
type MyStruct struct {}
func (v *MyStruct) Method() {
fmt.Printf("(%v, %T)\n", v, v)
}
func describe(i I) {
fmt.Printf("(%v, %T)\n", i, i)
}
func main() {
var i I
if (i == nil) {
fmt.Printf("i is nil.\n")
}
describe(i)
var myStruct *MyStruct
i = myStruct
if (myStruct == nil) {
fmt.Printf("myStruct is nil.\n")
}
if (i != nil) {
fmt.Printf("i is NOT nil.\n")
}
describe(myStruct)
describe(i)
}
空 interface
- 空のインタフェース
interface{}- 任意の型の値を保持できる。全ての型は、少なくともゼロ個のメソッドを実装している。
- 空のインタフェースは、道の値を扱うコードで使用される。多言語の
Anyと同じ。
型アサーション Type assertions
構造体をマップのキーとして使う
- 結論
- Go ではプリミティブ型だけでなく、構造体、ポインタなどもマップのキーとして使用できる
- 構造体の各フィールド値の同一性によってマップから値を取り出したいときは、構造体ポインタでなく構造体の値をキーとして使用するべき
- 理由
- 構造体をキーとした場合、
map[key]としたときに構造体の各フィールドの値を比較してキーの同一性が検証されるが、構造体ポインタをキーとした場合、構造体の各フィールドの値ではなく、ポインタの値(ポインタの指すアドレスの値)がキーの同一性の検証に使われてしまう。
- 構造体をキーとした場合、
参考
- [Golang]mapのkeyのちょっとした話