はじめに
プログデンスの圓佛です。2025年7月にAWS S3 Vectorsがリリースされました。
今回はS3 VectorsとBedrock Knowledge Basesを組み合わせ、RAGを構築してみます。
S3 Vectorsが利用可能なリージョン
AWS Regions, endpoints, and quotas for S3 Vectorsに現在、S3 Vectorsが利用可能なリージョンが記載されています。このページに記載されている表にリージョンの和名を追記したものを記載しておきます。
| リージョン名 | Region Name | Region | Endpoint | Protocol | Signature Version(s) Support |
|---|---|---|---|---|---|
| 米国東部 (バージニア北部) | US East (N. Virginia) | us-east-1 | s3vectors.us-east-1.api.aws | HTTPS | 4 |
| 米国東部 (オハイオ) | US East (Ohio) | us-east-2 | s3vectors.us-east-2.api.aws | HTTPS | 4 |
| 米国西部 (オレゴン) | US West (Oregon) | us-west-2 | s3vectors.us-west-2.api.aws | HTTPS | 4 |
| 欧州 (フランクフルト) リージョン | EU Central 1 (Frankfurt) | eu-central-1 | s3vectors.eu-central-1.api.aws | HTTPS | 4 |
| アジアパシフィック (シドニー) | Asia Pacific (Sydney) | ap-southeast-2 | s3vectors.ap-southeast-2.api.aws | HTTPS | 4 |
S3 Vectorsの料金プラン
S3 Vectorsの料金情報は日本語のAmazon S3 料金ページにはまだ記載が無い為、英語のAmazon S3 Pricingページを参照します。「Vectors」タブに料金情報が記載されています。

米国バージニア北部リージョンの料金を一覧表にしてみました。日本円は「1$=150円」で計算しています。
| 項目 | 単位 | 料金(米ドル) | 料金(日本円) |
|---|---|---|---|
| ストレージ保管 | 1GB/一ヶ月 | $0.06 | 9.00円 |
| PUTリクエスト | 1GB | $0.20 | 30.00円 |
| GETやLISTなど、PUT以外の全てのリクエスト | 1,000リクエスト | $0.055 | 8.25円 |
| クエリリクエスト | 1,000リクエスト | $0.0025 | 0.38円 |
| ベクトルデータ(最初の10万ベクターまで) | 1TB | $0.0040 | 0.60円 |
| ベクトルデータ(以降の10万ベクター) | 1TB | $0.0020 | 0.30円 |
1.AWS Bedrockで基盤モデルを有効化する
AWS Bedrock で基盤モデルを有効化するの手順に従って基盤モデルを有効化します。任意の基盤モデルで問題ありませんが、今回はClaude Sonnet 4を有効化しました。
2.S3に汎用バケットを作成する
Step.2-1
S3へアクセスし、汎用バケットを作成します。「バケット名」を入力したら、その他のオプションは全てデフォルトのまま「バケットを作成」をクリックします。

Step.2-2
汎用バケットが作成されました。

3.S3にベクトルバケットを作成する
Step.3-1
同じくS3から「ベクトルバケット」を選択し、画面右上の「ベクトルバケットを作成」をクリックします。

Step.3-2
「ベクトルバケット名」に任意の名前を設定し、「ベクトルバケットを作成」をクリックします。

Step.3-3
ベクトルバケットが作成されました。そのまま作成したベクトルバケットをクリックします。

Step.3-4
「ベクトルインデックスを作成」をクリックします。

Step.3-5
「ベクトルインデックス名」には任意の名前を入力します。もし同一ベクトルバケット内に複数のデータを同居させる場合は、各々でインデックス名をユニークにする必要があります。「ディメンション」にはベクトル内に格納するデータの次元数を指定します。今回は「1024」を入力しました。ディメンションを増やすとその分、多くのストレージを消費することになり、より多くのコストがかかる点に注意します。「距離メトリック」には「コサイン」を指定します。設定が完了したら「ベクトルインデックスを作成」をクリックします。

Step.3-6
ベクトルインデックスが作成されました。

4.Bedrockでナレッジベースを作成する
Bedrockへアクセスすると画面上部に以下のメッセージが表示されていました。
Introducing S3 Vectors as a vector store (currently in preview)
S3 vector buckets are optimized for durable and cost-effective storage of large long-term data sets while maintaining subsecond query performance. This feature is currently in preview and we don't recommend using it for production workloads.
Step.4-1
「ナレッジベース」から「作成」をクリックし、選択肢から「ベクトルストアを含むナレッジベース」をクリックします。

Step.4-2
「ナレッジベース名」には任意の名前を入力します。IAM許可は既存のサービスロールを利用しない限り、「新しいサービスロールを作成して使用」を選択します。「データソースを選択」からは「Amazon S3」を選択します。設定が完了したら「次へ」をクリックします。

Step.4-3
「データソース名」には任意の名前を入力します。「S3のURI」には前の手順で作成した汎用バケット名を入力します。「解析戦略」には「Amazon Bedrockデフォルトパーサー」を選択します。設定が完了したら「次へ」をクリックします。
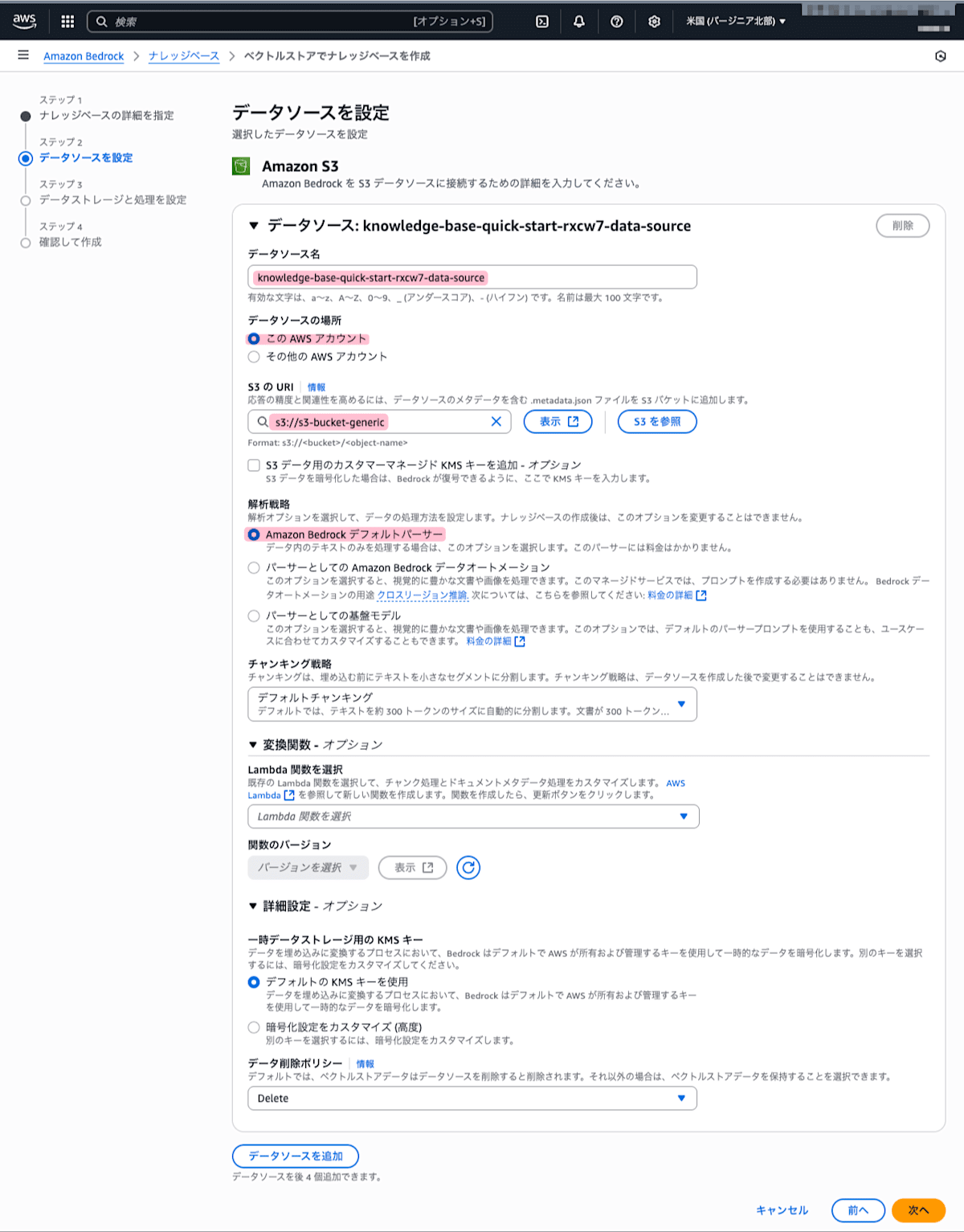
尚、「チャンキング戦略」には以下の選択肢があります。詳しくはナレッジベースでのコンテンツチャンキングの仕組みを参照してください。

Step.4-4
「埋め込みモデル」から「モデルを選択」をクリックします。

Step.4-5
ここでは「Amazon Titan Text Embeddings V2」を選択し「適用」をクリックします。詳しくはAmazon Titan Text Embeddings モデルを参照します。

Step.4-6
今回は新規のベクトルデータベースを作成する為、「ベクトルデータベース」の「ベクトルストアの作成方法」は「新しいベクトルストアをクリック作成」を選択します。「ベクトルストア」には「Amazon S3 Vectors」を選択します。設定が完了したら「次へ」をクリックします。

Step.4-7
ここまで設定した内容が一覧表示されます。問題が無いことを完了したら「ナレッジベースを作成」をクリックします。

Step.4-8
少し待つとナレッジベースが作成されました。

5.S3汎用バケットへデータをアップロードする
Step.5-1
S3汎用バケットへアップロードし、ナレッジベースの処理対象になるファイルを用意します。今回は以下のドキュメントをダウンロードしました。ダウンロードしたファイルは約85MBありました。

Step.5-2
ナレッジベースデータにサポートされているドキュメント形式と制限に記載されていますが、ナレッジベースにはファイルサイズに関して以下の制限があります。
各ファイルサイズは 50 MB のクォータを超えないようにしてください。
このままではナレッジベースで処理対象にされずに無視されてしまう為、以下のようにファイルを分割しました。ファイルの分割にはmacOS標準の「プレビュー」アプリケーションを利用しました。
分割前
| ファイル名 | ページ | 総ページ数 | ファイルサイズ(MB) |
|---|---|---|---|
| Cisco_TroubleshootingApplicationCentricInfrastructureSecondEdition.pdf | 1〜506 | 506 | 84.6 |
分割後
| ファイル名 | ページ | 総ページ数 | ファイルサイズ(MB) |
|---|---|---|---|
| Cisco_TroubleshootingApplicationCentricInfrastructureSecondEdition1.pdf | 1〜156 | 156 | 16.5 |
| Cisco_TroubleshootingApplicationCentricInfrastructureSecondEdition2.pdf | 157〜314 | 158 | 13.5 |
| Cisco_TroubleshootingApplicationCentricInfrastructureSecondEdition3.pdf | 315〜506 | 192 | 19.3 |
Step.5-3
分割したファイルをS3汎用バケットへアップロードします。

6.ナレッジベースでデータソースを同期する
Step.6-1
データソースとして指定したS3バケット上のファイルとナレッジベースを同期させます。Bedrockからナレッジベースを開き、今回作成したナレッジベースを選択して「同期」をクリックします。

Step.6-2
「ステータス」が「同期中」になります。同期が完了するまでしばらく待機します。

Step.6-3
「ステータス」が「利用可能」となり、同期が完了しました。

7.ナレッジベースをテストする
Step.7-1
「ナレッジベースをテスト」をクリックします。

Step.7-2
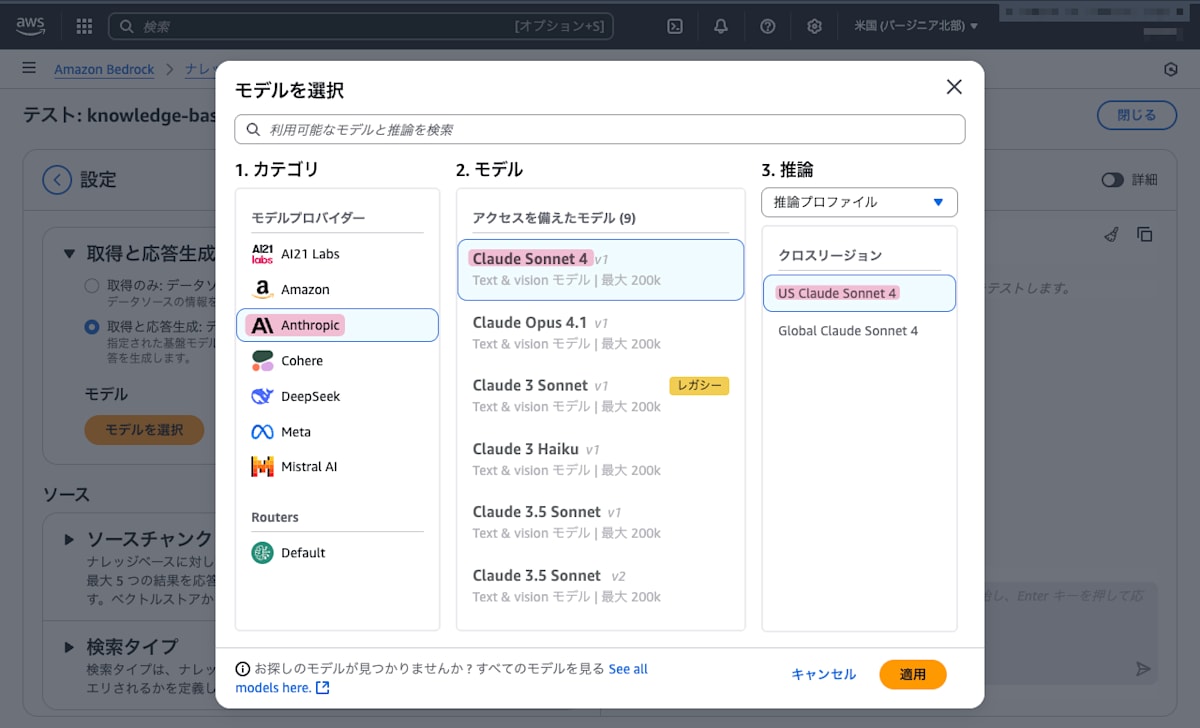
「モデルを選択」をクリックします。

Step.7-3
今回は「Anthropic」「Claude Sonnet 4」「US Claude Sonnet 4」を選択し、「適用」をクリックします。
Step.7-4
以下のプロンプトを入力してみます。
ACIでデバイスのディスカバリに失敗した場合、トラブルシューティングにはどのようなコマンドを実行するのが良いですか?
すると以下の回答が得られました。


株式会社プログデンス/BtoB向けのITソリューションを提供する企業です。 技術スタック: SASE / Prisma Access / Zscaler / Netskope / Cato Networks / Tanium / M365 / Cisco / Automation / Ansible