生成 AI を検索体験に組み込みたい──そう考えたとき、RAGをゼロから実装するのは意外と骨が折れます。
埋め込みモデルの選定や大量ドキュメントのベクトル化バッチ、スケーリングするベクトル DB の運用、生成モデルへ渡すコンテキストの最適化など、工程が多岐にわたり運用負荷も高くなるためです。
Google Cloud が提供する Vertex AI Search を使えば、データの取り込みからインデックス生成、質問応答までをフルマネージドで任せられるため、開発者はフロントエンド設計やドメイン知識の整理に集中できます。
この記事では実際に触ってみて感じた便利さを軸に Vertex AI Search について語っていきます。
Vertex AI Search とは?
Vertex AI Search は、Google Cloud が提供する構造化/非構造化データを横断して検索・要約・質問応答を行うフルマネージド型サービスです。
アカウントあたり月 10,000 クエリまでの無料トライアルが用意されているので、小規模な PoC であれば費用ゼロから試せるのも魅力です。
RAG を自前で実装する時と比べた時のメリット
RAGにはよく、PostgreSQL + pgvector を使ったベクトル検索の実装が紹介されます。
pgvector + PostgreSQL でベクトル検索を構築できても、ドキュメントが 10 万件とかを超えてくるとストレージ肥大化の問題があります。
また、定期的に元データを更新する場合、ベクトル化のバッチ処理やインデックスの再構築も必要です。
特に独自で実装する場合、toB向けのマルチテナントで実装する場合のデータ隔離やセキュリティの確保も難しいです。
Vertex AI Search ならこうした面倒を Google に丸投げできるため、開発者はアプリケーションのロジックに集中できます。
管理画面で検索結果をプレビュー
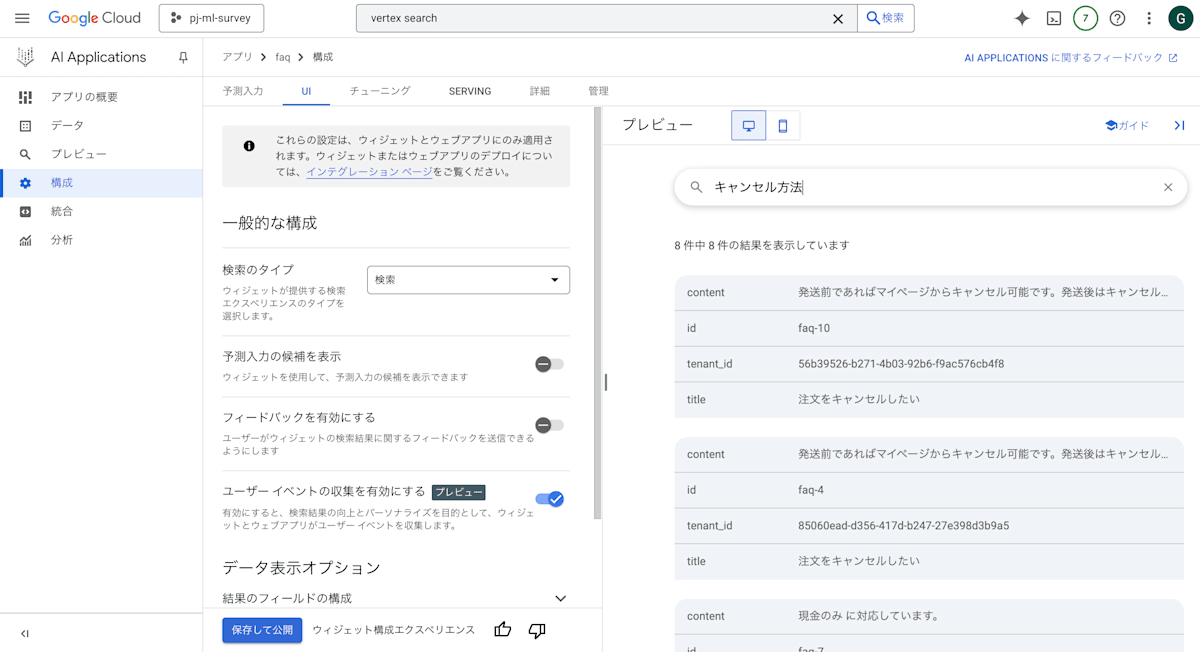
Vertex AI Searchで個人的に便利だなと感じたのは、Google Cloud上で検索結果をプレビューできる点です。
UIを使えば、実際に検索したい内容を検索にかけて、結果をその場でプレビューできます。これにより、検索エンジンのチューニングが容易になり、開発者は試行錯誤を繰り返しながら最適な検索体験を構築できます。
例えばこの画像では、「キャンセル方法」というキーワードで検索して関連するドキュメントを取得し、どのような回答が得られるかを確認しています。
さらに、検索ではなく「回答付き検索」を選ぶことで、ただ検索結果を取得するだけでなく、質問に対する回答も同時に得ることができます。
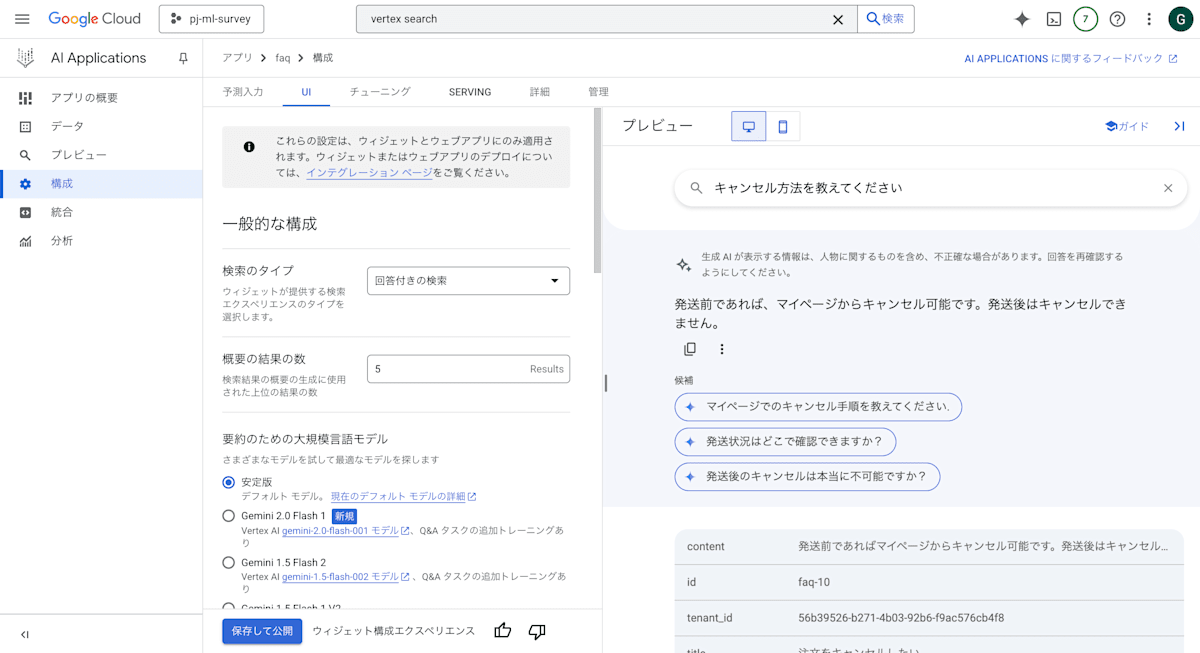
ちなみにこの検索UIはウィジェットとして直接アプリに組み込むことも可能です。
簡単なチャットボットだったらこれだけでもいいかもしれませんね!
もちろん、このウィジェットを使わずに、独自のフロントエンドを実装して検索体験をカスタマイズすることもできます。
テナント分離でエンタープライズでも安心
Vertex AI Search は工夫して実装することでプロジェクト単位でマルチテナント構成を組めます。
顧客ごとに独立したアプリケーションを立てられるため、データの隔離とセキュリティを確保しつつ、各テナントに対して個別の検索エンジンを提供できます。
図のようにテナントごとにData Storeを作成し、アプリケーションごとに異なるData Storeを紐づけることで、データの隔離とセキュリティを確保できます。
Cloud Storage / Google Drive からのデータ取り込み
Vertex AI Search は Web クローリングのほか、Cloud Storage・BigQuery・Firestore・Google Drive など複数ソースのコネクタを提供しています。コンソール操作に加え、API/SDK から Data Store を作成することもできます!


弊社では、Cloud SQL のデータを JSONL 形式にエクスポートし Cloud Storage に配置。各テナント用 Data Store に一括インポートしたのち、それぞれテナントごとのアプリケーションに紐づけています!
以下のコードスニペットでは、Node.js を使って Data Store の作成からデータのインポート、検索エンジンのデプロイまでを行う方法になります!
Node.js で Data Store を作成する
import { DataStoreServiceClient } from '@google-cloud/discoveryengine';
import { google } from '@google-cloud/discoveryengine/build/protos/protos';
// 設定値
const PROJECT_ID = 'project-id'; // Google Cloud プロジェクト ID
const LOCATION = 'global';
const DATA_STORE_ID = 'my-data-store'; // Data Store の ID
/**
* Data Store を新規作成
*/
async function createDataStore(
projectId: string,
location: string,
dataStoreId: string,
): Promise<string> {
const client = new DataStoreServiceClient(
location !== 'global' ? { apiEndpoint: `${location}-discoveryengine.googleapis.com` } : undefined,
);
const parent = client.collectionPath(projectId, location, 'default_collection');
const dataStore: google.cloud.discoveryengine.v1.IDataStore = {
displayName: dataStoreId,
industryVertical: google.cloud.discoveryengine.v1.IndustryVertical.GENERIC,
solutionTypes: [google.cloud.discoveryengine.v1.SolutionType.SOLUTION_TYPE_SEARCH],
contentConfig: google.cloud.discoveryengine.v1.DataStore.ContentConfig.NO_CONTENT,
};
const request: google.cloud.discoveryengine.v1.ICreateDataStoreRequest = {
parent,
dataStoreId,
dataStore,
};
const [operation] = await client.createDataStore(request);
await operation.promise();
return operation.name || '';
}
Data Store にデータをインポートする
import { DocumentServiceClient } from '@google-cloud/discoveryengine';
import { google } from '@google-cloud/discoveryengine/build/protos/protos';
// 設定値
const PROJECT_ID = "project-id"; // Google Cloud プロジェクト ID
const LOCATION = "global"; // Values: "global"
const DATA_STORE_ID = "my-data-store"; // Data Store の ID
// Examples:
// - Unstructured documents
// - `gs://bucket/directory/file.pdf`
// - `gs://bucket/directory/*.pdf`
// - Unstructured documents with JSONL Metadata
// - `gs://bucket/directory/file.json`
// - Unstructured documents with CSV Metadata
// - `gs://bucket/directory/file.csv`
const GCS_URI = "gs://example-bucket/directory/file.json"; // インポートする GCS ファイルの URI
/**
* データストアにドキュメントをインポートする関数
* @param projectId - Google Cloud プロジェクトID
* @param location - データストアの場所
* @param dataStoreId - データストアのID
* @param gcsUri - インポートするGCSファイルのURI
* @returns インポートオペレーションの名前
*/
async function importDataStore(
projectId: string,
location: string,
dataStoreId: string,
gcsUri: string,
): Promise<string> {
// For more information, refer to:
// https://cloud.google.com/generative-ai-app-builder/docs/locations#specify_a_multi-region_for_your_data_store
const clientOptions = location !== "global"
? { apiEndpoint: `${location}-discoveryengine.googleapis.com` }
: undefined;
// クライアントを作成
const client = new DocumentServiceClient(clientOptions);
// 検索エンジンブランチの完全なリソース名
// e.g. projects/{project}/locations/{location}/dataStores/{data_store_id}/branches/{branch}
const parent = `projects/${projectId}/locations/${location}/dataStores/${dataStoreId}/branches/default_branch`;
const request: google.cloud.discoveryengine.v1.IImportDocumentsRequest = {
parent: parent,
gcsSource: {
// 複数のURIがサポートされています
inputUris: [gcsUri],
// オプション:
// - `content` - 非構造化ドキュメント(PDF、HTML、DOC、TXT、PPTX)
// - `custom` - カスタムJSONLメタデータを持つ非構造化ドキュメント
// - `document` - discoveryengine.Document形式の構造化ドキュメント
// - `csv` - CSVメタデータを持つ非構造化ドキュメント
dataSchema: "custom", // カスタムJSONLメタデータを使用
},
// オプション: `FULL`(完全上書き), `INCREMENTAL`(増分更新)
reconciliationMode: google.cloud.discoveryengine.v1.ImportDocumentsRequest.ReconciliationMode.INCREMENTAL,
autoGenerateIds: true,
};
// リクエストを実行
const [operation] = await client.importDocuments(request);
console.log(`Waiting for operation to complete: ${operation.name}`);
const [response] = await operation.promise();
// オペレーション完了後、オペレーションメタデータから情報を取得
const metadata = operation.metadata;
// レスポンスを処理
console.log('Response:', response);
console.log('Metadata:', metadata);
return operation.name || '';
}
Node.js で検索エンジンをデプロイする
import { EngineServiceClient } from '@google-cloud/discoveryengine';
import { google } from '@google-cloud/discoveryengine/build/protos/protos';
// 設定値
const PROJECT_ID = 'project-id'; // Google Cloud プロジェクト ID
const LOCATION = 'global';
const DATA_STORE_ID = 'my-data-store'; // Data Store の ID
const ENGINE_ID = 'my-search-engine'; // 検索エンジンの ID
const DATA_STORE_IDS = ['my-data-store']; // 紐付ける Data Store の ID
async function createSearchEngine(
projectId: string,
location: string,
engineId: string,
dataStoreIds: string[],
): Promise<string> {
const client = new EngineServiceClient(
location !== 'global' ? { apiEndpoint: `${location}-discoveryengine.googleapis.com` } : undefined,
);
const parent = client.collectionPath(projectId, location, 'default_collection');
const engine: google.cloud.discoveryengine.v1.IEngine = {
displayName: engineId,
industryVertical: google.cloud.discoveryengine.v1.IndustryVertical.GENERIC,
solutionType: google.cloud.discoveryengine.v1.SolutionType.SOLUTION_TYPE_SEARCH,
searchEngineConfig: {
searchTier: google.cloud.discoveryengine.v1.SearchTier.SEARCH_TIER_ENTERPRISE,
searchAddOns: [google.cloud.discoveryengine.v1.SearchAddOn.SEARCH_ADD_ON_LLM],
},
dataStoreIds,
};
const request: google.cloud.discoveryengine.v1.ICreateEngineRequest = {
parent,
engine,
engineId,
};
const [operation] = await client.createEngine(request);
console.log(`Waiting for operation: ${operation.name}`);
await operation.promise();
return operation.name || '';
}
Vertex AI Search のインデックス料金について
Vertex AI Search の嬉しいポイントとして「インデックス作成自体にはお金がかからない」ことがあります。
つまり、どれだけインデックスを作っても、その作業自体で課金されることはありません。
実際に費用が発生するのは、インデックスに保存されているデータ量(ストレージ使用量)が毎月10GBを超えた場合だけです。10GBまでは無料枠として使えるので、かなり余裕があります。小〜中規模のプロジェクトなら、ストレージ料金を気にせず始められるのは大きな魅力です。
また、インデックスの作成やデータの更新操作も無料。課金対象になるのは「検索クエリ数」と「インデックスストレージの超過分」だけなので、コスト管理もしやすいです。
まとめ
このように、Vertex AI Search を使うことで検索体験を向上させつつ運用コストを削減できます!
特に、使い方を工夫することでマルチテナント環境でのデータ隔離やセキュリティを確保しつつ、高度な検索機能を簡単に実装できる点が大きな魅力ですね!

Discussion