注視推定モデル Gaze-LLE-DINOv3 を自作して CVPR2025 Highlight の SOTA 超え
はじめに
CyberAgent AI Lab Advent Calendar 2025 - Adventar 3日目の記事です。
Gaze-LLE-DINOv3 というモデルを自作しました。自作、と言っても、元論文・公式実装である Gaze-LLE(fkryan/gazelle)(CVPR2025 Highlight) をベースに、バックボーンを DINOv3 に置き換え、さらにONNX / TensorRT でのリアルタイム推論を前提にチューニングしただけです。
Zenn は動画を投稿できないため静止画のサンプルを共有しておきます。物体検出の DEIMv2 と注視推定の Gaze-LLE-DINOv3 を両方実行した合計処理時間が 10ms です。物体検出 + 骨格推定 + 属性推定 + 頭部向き推定 + トラッキング + 絶対距離測定 + 注視推定 の全処理時間を合算して 10ms。リアルタイム動画を見てみたい方は私のリポジトリの README をご覧ください。

チューニングしただけ、なのですが、元論文の実装よりめちゃくちゃ速く、軽量で、精度が高いです。下表の Gaze-LLE (ViT-B) および Gaze-LLE (Vit-L) は元論文 Gaze-LLE(fkryan/gazelle) で報告されている Head 部分のパラメーターに対して推論時に実際に必要となる backbone 部分のパラメーターを足しています。Atto-distillation 以下が私の自作モデルです。太文字にしてある行は エセSOTA達成 のアピールです。論文を書いていないので エセ と表現しました。ただ、backbone 含む全体のパラメーター数をGaze-LLE のおよそ 10分の1 にしたうえでさらに精度と速度を上回っています。論文化しないと存在自体に気づかれませんが、実用するうえではわりと意味があるチューニングをしたと考えいます。
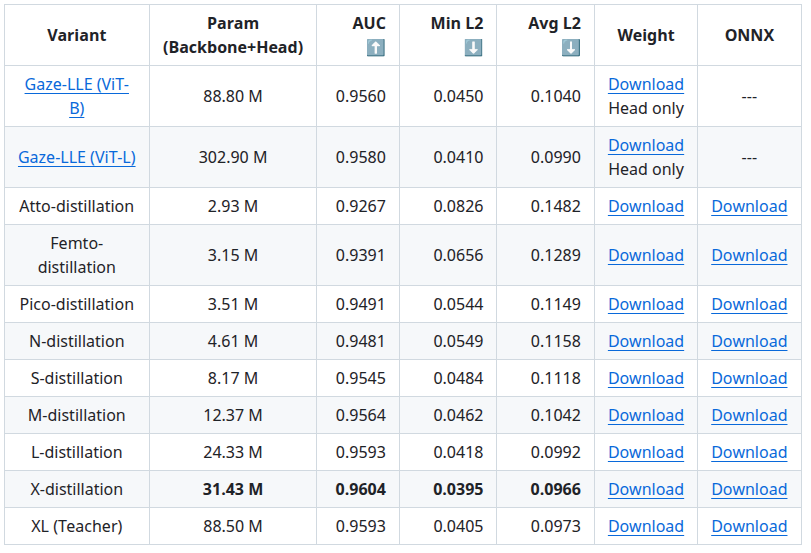
引用: https://github.com/PINTO0309/gazelle-dinov3?tab=readme-ov-file#benchmark-results-for-each-model
一番重たい X-distillation モデルを使用して10人同時に推定すると 9.21 ms/推論 でした。

軽量バージョンのうち最も軽いバリアント Atto-distillation は10人同時に推定しても 1.32 ms/推論 でした。これは backbone を含めたモデル全体の推論時間です。

1. Gaze-LLE
1.1 Gaze target estimation とは
Gaze-LLE 系のモデルが解くタスクは、「人が画角内のどのあたりを見ているか」を推定することです。
- 入力:
- シーン画像
- その中にいる人物の頭部バウンディングボックス
- 出力:
- 画像上の注視位置のヒートマップ(どこを見ているかの確率分布)
- さらに VideoAttentionTarget では、注視点が「画面内にあるか(in)」/「画面外か(out)」のスコアも出力(in/out head)
元論文の Gaze-LLE(fkryan/gazelle)は、DINOv2を「巨大な事前学習済み視覚エンコーダ」として凍結し、その上に軽量な視線デコーダだけを学習する Transformer ベースのアーキテクチャです。巨大な視覚基盤モデルを「そのまま利用」しつつ、追加で学習するパラメータを 1〜2 桁減らす、という思想が特徴です。論文上で引き合いに出されている過去のモデルとの比較表では学習可能パラメーターの視線デコーダ部分のパラメーターのみを取り上げて比較されていますので、そういう比較の仕方をすれば軽量なのは当然だと感じました。ちなみに、backbone よりデコーダのほうが遥かに重たく遅いです。

引用: https://arxiv.org/pdf/2412.09586
1.2 Gaze-LLE-DINOv3 の位置づけ
Gaze-LLE-DINOv3 は、この Gaze-LLE のアイデアを引き継ぎつつ:
- バックボーンを DINOv2 から DINOv3 に変更
- バックボーンをフリーズしない
- 小型モデルには PPHGNetV2 ベースの CNN(Atto / Femto / Pico / N) を採用
- GPU 上での実運用(ONNX + TensorRT)を強く意識
- GazeFollow / VideoAttentionTarget の両方で学習済みチェックポイントと ONNX を提供
実用志向の再実装 & 軽量化版 Gaze-LLE という思想で設計しました。論文を書いていないのでただのお遊びですが、Gaze-LLE の論文で課題として上げられている「バックボーンを含めた複数人同時の推論速度が遅い問題」はある程度クリアしています。
2. モデル設計時にこだわったこと
2.1 入力解像度:640×640 を前提にした設計
人検出の「地獄アノテーション」を大量にこなした結果として、頭部姿勢や視線を正しく推定するには最低でも VGA(640×480)以上が必要だと判断しました。
- 3 ピクセル程度しかないような目や耳まで含め、
1,034,735個の全身の各部位を自力アノテーション - DINOv3 ベースの DEIMv2 でベンチマークした結果、従来のよくある 224×224 や 448×448 ではコンテキストが足りない、という結論に達しました
公式論文実装を大幅に改造した Fork でベンチマークしています。

引用: https://github.com/PINTO0309/PINTO_model_zoo/tree/main/472_DEIMv2-Wholebody34#2-annotation
そのため Gaze-LLE-DINOv3 では、視線推定の入力解像度に 640×640 を選択しています。
2.2 Progressive Unfreezing(段階的アンフリーズ)
元の Gaze-LLE は「バックボーン完全凍結+ヘッドのみ学習」という方針ですが、Gaze-LLE-DINOv3 では、バックボーンの DINOv3/PPHGNetV2 も段階的に解凍して微調整(finetune)するパイプラインを採用しました。
-
--initial_freeze_epochs:最初は backbone を完全に凍結してヘッドだけ学習 -
--unfreeze_interval:数 epoch ごとに backbone のレイヤを順次アンフリーズ -
--finetune_layers 2:最後の数ブロックのみ finetune する設定
といったハイパーパラメータで制御しており、破滅的忘却や勾配爆発を防ぎつつ、タスク特化の最適化も行う、というバランスをとるようにしました。おそらく、元論文の Gaze-LLE(fkryan/gazelle)はbackbone を解凍した状態で学習した結果うまくいかなかったのではないか、と想像しています。実際、backbone のパラメータを学習初期から全て解凍した状態で学習を進めると 5 epoch から 8 epoch 前後で精度向上が頭打ちになり、さらに精度が逆行して低下し続けることを確認済みです。
ご参考までに、下図は DINOv3 backbone をファインチューニングしても安定的に最後まで精度が向上し続けていることが分かる X-Distillation の学習ログです。28 epoch でエセSOTAを達成しています。

2.3 損失関数:BCEWithLogitsLoss でクラス不均衡に対応
GazeFollow / VideoAttentionTarget は「画面のうち正解ピクセルはごく一部」で、正例と負例のクラス不均衡が非常に大きいタスクです。そのため、Gaze-LLE-DINOv3 では、シグモイド+BCELoss の代わりに BCEWithLogitsLoss を採用しました。これに合わせて、スクリプト側では --disable_sigmoid フラグで「モデルの出力をそのままロジットとして扱う」設計にしています。
こちらのカスタマイズも、backbone を解凍した状態の学習中盤で Loss が Nan になってしまう状況を観測したため問題に気づきました。
データセットは下記から引用しています。
2.4 Teacher–Student distillation 戦略
Gaze-LLE-DINOv3 では、大きな DINOv3 ViT-B16 モデルを teacher にして、より軽量な CNN / ViT の student モデル(Atto〜X)を蒸留する構成です。
典型的には:
-
Teacher:
gazelle_dinov3_vitb16(XL) -
Student:
- CNN 系:
gazelle_hgnetv2_atto / femto / pico / n - ViT 系:
gazelle_dinov3_vit_tiny / tinyplus / vits16 / vits16plus
- CNN 系:
スクリプト中の引数:
-
--distill_teacher: Teacher のモデル名 -
--distill_weight: distillation loss の比率(0.3) -
--distill_temp_end: distillation の温度スケジュール(終値 4.0)
VideoAttentionTarget 学習では、さらに:
-
--init_ckpt: GazeFollow で事前学習した student を初期値としてロードする
ことで、GazeFollow → VAT の逐次転移学習 + distillation の組み合わせにしています。
3. モデルバリエーションとベンチマーク
GazeFollow / VideoAttentionTarget に対するパラメータ数は大まかに以下のとおりです。
3.1 バリアント一覧
-
CNN 系(PPHGNetV2 ベース)
- Atto / Femto / Pico / N
- パラメータ数: 約 3M 〜 5M
- Atto / Femto / Pico / N
-
ViT 系(DINOv3 ベース)
- S(Tiny) / M(Tiny+) / L(ViT-S) / X(ViT-S+) / XL(ViT-B)
- パラメータ数: 約 8M 〜 88M
- S(Tiny) / M(Tiny+) / L(ViT-S) / X(ViT-S+) / XL(ViT-B)
パラメータ数と速度のバランスをできるだけ重視しています。
3.2 精度とコストのトレードオフ
GazeFollow:
- 教師(XL; ViT-B16)は AUC ≈ 0.96 前後
- X / L / M などの Distill モデルも、ほぼ同等か、むしろわずかに上回る AUCを出しつつパラメータを大幅削減
- CNN 系の Atto / Femto / Pico / N でも、AUC ≈ 0.93 〜 0.95 程度と、「軽量なのにかなり実用的な精度」をキープ

VideoAttentionTarget:
- XL teacher に近い AUC / Avg L2 / In/out AP を、より小さいモデルがかなりのレベルまで食い下がっています。
- 比較対象の元論文モデルとのパラメーター量の差が大きすぎて少し混乱します

3.3 評価指標の定義
精度の指標は下記のとおりです。
-
AUC
- 正解位置を含む画素を「正例」、それ以外を「負例」とみなした ROC 曲線の面積
- 1.0 に近いほど、「正解付近」が高スコアになっている
-
Min L2
- 予測ヒートマップ中、最大スコア点と正解視線位置の距離
- 小さいほど「最も自信のある点」が正解に近い
-
Avg L2
- ヒートマップを確率分布とみなした際の重心と正解視線位置の距離
- 分布全体として正解にどれだけ寄っているか
-
Inout AP
- 「画面内 / 画面外」の二値分類としての AP
- 1.0 に近いほど、in/out の識別が安定している
4. リポジトリ構成の概要
リポジトリのリソースは以下のような構成になっています。
| ディレクトリ/ファイル | 役割(推測・READMEから) |
|---|---|
gazelle/ |
モデル本体(バックボーン・デコーダ・ヘッド)、ONNX用forward等 |
data/ |
データセット配置用フォルダ |
data_prep/ |
GazeFollow/VAT向け前処理スクリプト |
scripts/ |
学習・評価スクリプト一式(train_gazefollow.py/train_vat.py/evalなど) |
benchmark/ |
TensorRT/ONNXの速度ベンチマーク関連 |
ckpts/ |
学習済みの.pt/事前学習バックボーンを配置するフォルダ |
demo_deimv2_onnx_wholebody34_with_edges.py |
DEIMv2+Gaze-LLE-DINOv3を使ったONNX推論デモ |
export_onnx.py |
PyTorch→ONNX変換スクリプト |
hubconf.py |
PyTorchHub用のエントリ(torch.hub.load向け) |
pyproject.toml |
uv用のPythonパッケージ設定 |
5. セットアップ手順(インストール〜データ準備)
5.1 環境構築
パッケージ管理に uv を利用していますのでとてもシンプルです。
- リポジトリを取得
-
uvをインストール -
uv syncで依存関係を解決 & 仮想環境作成 - 仮想環境を有効化
git clone https://github.com/PINTO0309/gazelle-dinov3.git
cd gazelle-dinov3
# uv をインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
# 依存関係をインストール(.venv が生成される)
uv sync
# 仮想環境を有効化
source .venv/bin/activate
5.2 データセットの準備
利用するデータセットは元の Gaze-LLE と同じ:
- GazeFollow
- VideoAttentionTarget
手順概要:
- GazeFollow / VAT をそれぞれダウンロード
README では attention-target-detection リポジトリの README を参照するようになっています。 -
data/フォルダの下に展開(data/gazefollow_extendedやdata/videoattentiontargetなど) - 前処理スクリプトを実行
uv run python data_prep/preprocess_gazefollow.py \
--data_path ./data/gazefollow_extended
uv run python data_prep/preprocess_vat.py \
--data_path ./data/videoattentiontarget
これにより、各 split ごとの JSON アノテーションなど、学習用のフォーマットに整形されます。
5.3 事前学習バックボーンのダウンロード
ckpts/ に以下のようなファイルを配置します。
-
Distill-DINOv3(DEIMv2 から拝借)
vitt_distill.ptvittplus_distill.pt
-
PPHGNetV2(D-FINE 由来)
PPHGNetV2_B0_stage1.pth
-
DINOv3 公式事前学習
dinov3_vits16_pretrain_lvd1689m-08c60483.pthdinov3_vits16plus_pretrain_lvd1689m-4057cbaa.pthdinov3_vitb16_pretrain_lvd1689m-73cec8be.pth
いずれも README にダウンロード URL を記載していますので、一度ダウンロードして ckpts/ に置けば、学習スクリプトが自動で読み込む設計です。
6. 学習パイプライン(GazeFollow / VAT)
6.1 GazeFollow 学習の流れ
scripts/train_gazefollow.py を使って、各バリアント(Atto / Femto / Pico / N / S / M / L / X / XL)を学習します。
代表的な引数:
-
--data_path:前処理済み GazeFollow データへのパス -
--model_name:どのアーキテクチャを使うか(例:gazelle_hgnetv2_atto) -
--exp_name:ログ・チェックポイント保存用の実験名 -
--max_epochs:トレーニング epoch 数(40〜60 あたり) -
--batch_size:64 or 128 -
--lr:学習率(1e-3) -
--n_workers:DataLoader のワーカ数(50〜60) -
--use_amp:自動混合精度(AMP)を有効化 -
--finetune/--finetune_layers:バックボーン微調整を有効化し、末尾何層かを更新 -
--initial_freeze_epochs/--unfreeze_interval:Progressive Unfreezing の設定 -
--distill_teacher/--distill_weight/--distill_temp_end:distillation 設定
CNN 系(Atto〜N)は、teacher が gazelle_dinov3_vits16plus、ViT 系(S〜X)は teacher = gazelle_dinov3_vitb16 という構成になっています。
6.2 VideoAttentionTarget 学習の流れ
VAT 用には scripts/train_vat.py を使用します。
大きな違いは:
- すべての student モデルが
--init_ckptで
「GazeFollow で事前学習済みのモデル」からスタートする - 2 つの learning rate:
-
--lr_non_inout:ヒートマップ側 -
--lr_inout:in/out 頭部の分類ヘッド側
-
-
--frame_sample_every 6:VAT の動画フレームから「6 フレームおき」にサンプルして学習 -
--inout_loss_lambda:in/out loss の重み(通常 1.0) -
--disable_progressive_unfreeze:VAT では progressive unfreezing を無効にしている設定も多い
teacher は gazelle_dinov3_vitb16_inout(in/out 付きの巨大モデル)を使うパターンが多く、VideoAttentionTarget の in/out タスクに合わせた distillation が行われます。
7. 評価(Validation)とベンチマーク
7.1 Validation スクリプト
学習済みモデルの精度確認には、以下のような eval スクリプトを使います:
-
GazeFollow
uv run python scripts/eval_gazefollow.py \ --data_path data/gazefollow_extended \ --model_name gazelle_dinov3_vit_tiny \ --ckpt_path ckpts/gazelle_dinov3_vit_tiny.pt \ --batch_size 64 -
VideoAttentionTarget
uv run python scripts/eval_vat.py \ --data_path data/videoattentiontarget \ --model_name gazelle_dinov3_vit_tiny_inout \ --ckpt_path ckpts/gazelle_dinov3_vit_tiny_inout.pt \ --batch_size 64
7.2 RTX3070 + TensorRT での速度
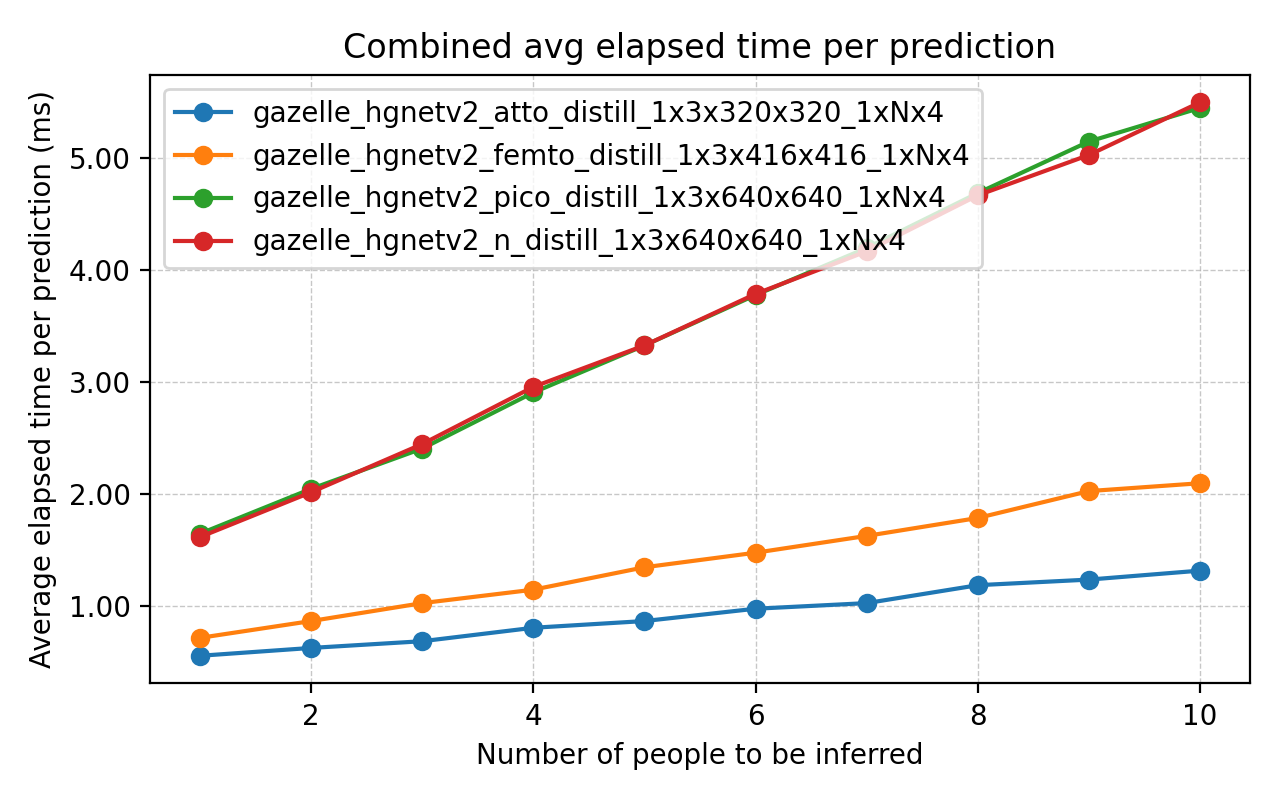
RTX3070 + TensorRT で 1000 回推論した平均レイテンシのベンチマークを行いました。
- S / M / L / X の ViT 系
- N / Pico / Femto / Atto の CNN 系
それぞれ「バックボーン+ヘッドを統合したモデル全体」の推論時間を可視化しています。小型モデルは数 ms~十数 ms レベルで動作しており、リアルタイム用途に十分な速度が出る設計になっていることが確認できました。X軸は同時に推定する人数です。

8. ONNX モデルと推論パイプライン
8.1 使用する ONNX モデル
-
DEIMv2(人検出+ WholeBody34 キーポイント)
- 超軽量 CNN による人検出専用モデルの ONNX
- GitHub Releases から直接
.onnxをダウンロード可能
-
Gaze-LLE-DINOv3(視線推定)
- 本リポジトリで学習した Gaze-LLE-DINOv3 の ONNX
- GitHub Releases から各種バリアントを入手
8.2 ONNX モデルの入出力仕様
入力
-
image_bgr:float32[1, 3, H, W]- BGR 画像(OpenCV の標準)
- サイズは 640×640 or 416×416 or 320×320
- モデル内部で:
- BGR → RGB チャンネル入れ替え
- 0–255 → 0–1 へスケーリング
- DINOv2 / DINOv3 バックボーン用の mean/std 正規化
-
bboxes_x1y1x2y2:float32[1, heads, 4]- 各 head(人物)ごとの
[x1, y1, x2, y2] - 0〜1 に正規化された座標
- 各 head(人物)ごとの
出力
-
heatmap:float32[heads, Hh, Wh]- 32×32 / 48×48 / 64×64 のヒートマップ
- 画像サイズにリサイズして、視線ヒートマップとして描画可能
-
inout:float32[heads]- 0.0〜1.0 の値で、「画面内を見ている」確率
8.3 ヒートマップの可視化
ONNX デモスクリプト内の overlay_gaze_heatmaps 関数を作ってヒートマップ化しました。出力のヒートマップを最大値で集約し(複数人物の場合)、元画像にカラーマップでオーバーレイする処理にしています。
処理の流れ:
-
heatmapsをnp.max(axis=0)で 2D に集約 - 0〜1 にクリップ
- 元画像サイズにリサイズ(
cv2.resize) - 0–255 にスケーリング →
cv2.applyColorMap(JET) -
cv2.addWeightedで元画像とブレンド
これにより、「どの領域が注視されているか」が直感的に分かる可視化が可能です。デモコード上では大した実装をしていません。

8.4 デモスクリプトの利用
リアルタイムデモには demo_deimv2_onnx_wholebody34_with_edges.py を使用します。
-h を叩くと、以下のようなオプションが出てきます(要約):
-
-m / --model:DEIMv2 の人検出 ONNX パス -
--gazelle_model:Gaze-LLE-DINOv3 の ONNX パス -
-v / --video:動画ファイルパス or カメラ ID -
-i / --images_dir:静止画フォルダパス -
-ep / --execution_provider:cpu / cuda / tensorrt -
-it / --inference_type:fp16 / int8(量子化) - 各種しきい値(object / attribute / keypoint)
- 描画モード切替(骨格描画、性別/年齢モードなど)
-
--gazelle_heatmap_alpha:ヒートマップの合成アルファ値
これらを指定することで、人検出 → head bbox 正規化 → 視線ヒートマップ生成 → オーバーレイ描画 まで一通り試せます。
9. 学習済み重み・PyTorch/ONNX の入手場所
9.1 weights アーカイブ
GitHub の releases ページで、バリアント別の PyTorch 重みをアップロードしています。
- GazeFollow weights
variant weight Atto gazelle_hgnetv2_atto_distill.pt Femto gazelle_hgnetv2_femto_distill.pt Pico gazelle_hgnetv2_pico_distill.pt N gazelle_hgnetv2_n_distill.pt S gazelle_dinov3_vit_tiny.pt M gazelle_dinov3_vit_tinyplus.pt L gazelle_dinov3_vits16.pt X gazelle_dinov3_vits16plus.pt XL gazelle_dinov3_vitb16.pt - VideoAttentionTarget weights
variant weight Atto gazelle_hgnetv2_atto_inout_distill.pt Femto gazelle_hgnetv2_femto_inout_distill.pt Pico gazelle_hgnetv2_pico_inout_distill.pt N gazelle_hgnetv2_n_inout_distill.pt S gazelle_dinov3_vit_tiny_inout.pt M gazelle_dinov3_vit_tinyplus_inout.pt L gazelle_dinov3_vits16_inout.pt X gazelle_dinov3_vits16plus_inout.pt XL gazelle_dinov3_vitb16_inout.pt
ファイルをダウンロードして ckpts/ に配置すれば、そのまま eval / ONNX 変換に利用可能です。
9.2 GitHub Releases の ONNX
GitHub Releases に Gaze-LLE-DINOv3 の ONNX もアップロードしています。
- DEIMv2 (人検出用 ONNX)
- Gaze-LLE-DINOv3 (視線推定用 ONNX)
両方揃えれば、demo スクリプトだけで GPU 上でリアルタイム推論が可能です。
まとめ
- Gaze-LLE-DINOv3 は、Gaze-LLE のアイデアを DINOv3 / PPHGNetV2 で再構成し、実運用しやすい軽量モデル群+ONNX/TensorRT デモとして仕上げています。
- RTX3070 クラスの GPU であれば、複数人の視線ヒートマップをリアルタイムで重ねて表示するようなユースケースにも十分対応できる設計にできました。
Discussion