📖
EmbeddingGemma-300mでテキスト分類(ロジスティック回帰)
初めに
GoogleからEmbeddingGemma-300mが出ましたので、試してみました。
Gemma 3 270Mのファインチューニングして、accuracy = 95%でましたが、埋込モデルではどうなるでしょうか?
livedoor ニュースコーパスのテキスト分類を試してみます。
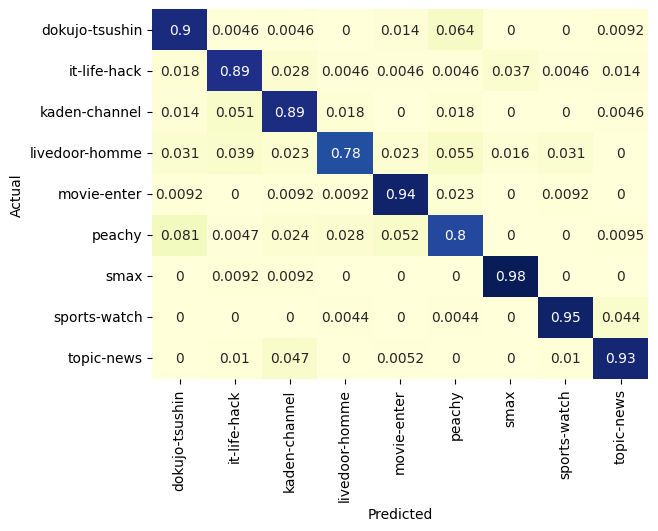
accuracy = 89.6%でした。
Gemma 3 270Mのファインチューニングよりは悪い結果となりました。
データ準備
livedoor ニュースコーパスを取得
%%capture
!wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
!tar xvf ldcc-20140209.tar.gz
ジャンル別に読み込む
import os
import glob
livedoor_news = {}
for folder in glob.glob("text/*"):
if os.path.isdir(folder):
texts = []
for txt in glob.glob(os.path.join(folder, "*.txt")):
text = []
with open(txt, "r") as f:
lines = f.readlines()
texts.append('\n'.join([line.strip() for line in lines[3:]]))
label = os.path.basename(folder)
livedoor_news[label] = texts
訓練データセットとテストデータセットを作成
from datasets import Dataset, concatenate_datasets
train_dataset = None
val_dataset = None
for label, texts in livedoor_news.items():
data = []
for text in texts:
data.append({"text": text, "label": label})
dataset = Dataset.from_list(data)
tmp_train = dataset.train_test_split(test_size=0.25, shuffle=True, seed=0)
if train_dataset is None:
train_dataset = tmp_train["train"]
val_dataset = tmp_train["test"]
else:
train_dataset = concatenate_datasets([train_dataset, tmp_train["train"]])
val_dataset = concatenate_datasets([val_dataset, tmp_train["test"]])
埋め込みモデル作成
from transformers import AutoTokenizer, AutoModel
import torch
model_name = "google/embeddinggemma-300m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
ベクトル化
classes = list(livedoor_news.keys())
def get_embedding(example):
inputs = tokenizer(example["text"], padding=True, truncation=True, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1).cpu().numpy()
return {
"embeddings": embeddings[0],
"labels": classes.index(example["label"]),
}
dataset = train_dataset.map(get_embedding).shuffle(seed=0)
val_dataset = val_dataset.map(get_embedding)
学習
from sklearn.linear_model import LogisticRegression
X = list(dataset["embeddings"])
labels = list(dataset["labels"])
clf = LogisticRegression(max_iter=1000)
clf.fit(X, labels)
推論
import numpy as np
preds = clf.predict(list(val_dataset["embeddings"]))
labels = list(val_dataset["labels"])
preds = np.array([classes[x] for x in preds])
labels = np.array([classes[x] for x in labels])
集計
import seaborn as sn
import pandas as pd
import matplotlib.pyplot as plt
figure, ax1 = plt.subplots()
SVM_confusion_df = pd.crosstab(labels, preds, rownames=['Actual'], colnames=['Predicted'], normalize='index')
sn.heatmap(SVM_confusion_df, annot=True, cmap="YlGnBu", ax=ax1, cbar=False)
from sklearn.metrics import classification_report
report = classification_report(y_pred=preds, y_true=labels, target_names=classes, output_dict=True)
pd.DataFrame(report).T

Discussion