📖
Gemma 3 270Mのファインチューニング
初めに
GoogleからGemma 3 270Mが出ましたので、試してみました。
unsolothaiからファインチューニングのnotebookが公開されています。
これを参考にlivedoor ニュースコーパスのテキスト分類を試してみます。
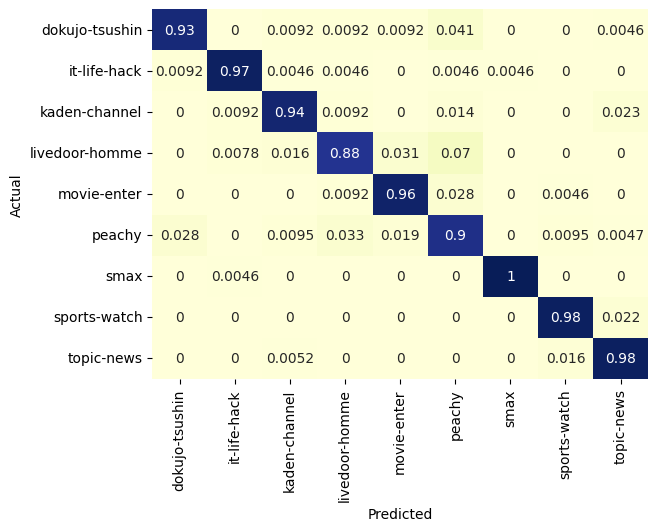
accuracy = 95%でよいですね!
インストール
%%capture
import os, re
if "COLAB_" not in "".join(os.environ.keys()):
!pip install unsloth
else:
# Do this only in Colab notebooks! Otherwise use pip install unsloth
import torch; v = re.match(r"[0-9\.]{3,}", str(torch.__version__)).group(0)
xformers = "xformers==" + ("0.0.32.post2" if v == "2.8.0" else "0.0.29.post3")
!pip install --no-deps bitsandbytes accelerate {xformers} peft trl triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf "datasets>=3.4.1,<4.0.0" "huggingface_hub>=0.34.0" hf_transfer
!pip install --no-deps unsloth
!pip install transformers==4.55.4
!pip install --no-deps trl==0.22.2
Unsloth
ベースモデル作成
from unsloth import FastModel
import torch
max_seq_length = 2048
model, tokenizer = FastModel.from_pretrained(
model_name = "unsloth/gemma-3-270m-it",
max_seq_length = max_seq_length, # Choose any for long context!
load_in_4bit = False, # 4 bit quantization to reduce memory
load_in_8bit = False, # [NEW!] A bit more accurate, uses 2x memory
full_finetuning = False, # [NEW!] We have full finetuning now!
# token = "hf_...", # use one if using gated models
)
LoRAアダプターを追加
model = FastModel.get_peft_model(
model,
r = 128, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 128,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
データ準備
トークナイザー作成
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "gemma3",
)
livedoor ニュースコーパスを取得
%%capture
!wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
!tar xvf ldcc-20140209.tar.gz
ジャンル別に読み込む
import os
import glob
livedoor_news = {}
for folder in glob.glob("text/*"):
if os.path.isdir(folder):
texts = []
for txt in glob.glob(os.path.join(folder, "*.txt")):
text = []
with open(txt, "r") as f:
lines = f.readlines()
texts.append('\n'.join([line.strip() for line in lines[3:]]))
label = os.path.basename(folder)
livedoor_news[label] = texts
訓練データセットとテストデータセットを作成
def convert_to_chatml(example):
return {
"conversations": [
{"role": "system", "content": example["task"]},
{"role": "user", "content": example["input"]},
{"role": "assistant", "content": example["expected_output"]}
]
}
from datasets import Dataset, concatenate_datasets
train_dataset = None
test_dataset = None
TASK = "次の文章のジャンルを分類してください。ジャンルは'peachy', 'sports-watch', 'movie-enter', 'smax', 'livedoor-homme', 'it-life-hack', 'topic-news', 'dokujo-tsushin', 'kaden-channel'から選択してください"
for label, texts in livedoor_news.items():
data = []
for text in texts:
data.append({"task": TASK,"input": text, "expected_output": label})
dataset = Dataset.from_list(data)
tmp_train = dataset.train_test_split(test_size=0.25, shuffle=True, seed=0)
if train_dataset is None:
train_dataset = tmp_train["train"]
test_dataset = tmp_train["test"]
else:
train_dataset = concatenate_datasets([train_dataset, tmp_train["train"]])
test_dataset = concatenate_datasets([test_dataset, tmp_train["test"]])
dataset = train_dataset.map(convert_to_chatml).shuffle(seed=0)
test_dataset = test_dataset.map(convert_to_chatml)
Gemma3向けのフォーマットに変換
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = [tokenizer.apply_chat_template(convo, tokenize = False, add_generation_prompt = False).removeprefix('<bos>') for convo in convos]
return { "text" : texts, }
dataset = dataset.map(formatting_prompts_func, batched = True)
test_dataset = test_dataset.map(formatting_prompts_func, batched = True)
学習
学習パラメーターを設定
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
eval_dataset = None, # Can set up evaluation!
args = SFTConfig(
dataset_text_field = "text",
per_device_train_batch_size = 8,
gradient_accumulation_steps = 1, # Use GA to mimic batch size!
warmup_steps = 5,
num_train_epochs = 1, # Set this for 1 full training run.
#max_steps = 100,
learning_rate = 5e-5, # Reduce to 2e-5 for long training runs
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir="outputs",
report_to = "none", # Use this for WandB etc
),
)
アシスタントの出力のみを訓練対象に設定
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<start_of_turn>user\n",
response_part = "<start_of_turn>model\n",
)
学習実施
trainer_stats = trainer.train()
保存&読込
モデル保存
model.save_pretrained("gemma-3") # Local saving
tokenizer.save_pretrained("gemma-3")
モデル読込
from unsloth import FastLanguageModel
max_seq_length = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/gemma-3-270m-it", # YOUR MODEL YOU USED FOR TRAINING
max_seq_length = max_seq_length,
load_in_4bit = False,
load_in_8bit = False,
)
model.load_adapter("gemma-3")
推論
from transformers import TextStreamer
def predict(example):
messages = [
{'role': 'system','content':example[0]['content']},
{"role" : 'user', 'content' : example[1]['content']}
]
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True, # Must add for generation
).removeprefix('<bos>')
res = model.generate(
**tokenizer(text, return_tensors = "pt").to("cuda"),
max_new_tokens = 125,
temperature = 0.01, top_p = 0.95, top_k = 64,
#streamer = TextStreamer(tokenizer, skip_prompt = True),
)
res = tokenizer.decode([tokenizer.pad_token_id if x == -100 else x for x in res[0]]).replace(tokenizer.pad_token, " ")
return res[res.rfind('model')+6:-13]
with open('predict.txt', 'w') as f:
for i, example in enumerate(test_dataset['conversations']):
t = example[2]['content']
p = predict(example)
f.write(f"{t},{p}\n")
集計
import seaborn as sn
import pandas as pd
import matplotlib.pyplot as plt
results = pd.read_csv('predict.txt', header=None)
figure, ax1 = plt.subplots()
SVM_confusion_df = pd.crosstab(results[0], results[1], rownames=['Actual'], colnames=['Predicted'], normalize='index')
sn.heatmap(SVM_confusion_df, annot=True, cmap="YlGnBu", ax=ax1, cbar=False)
from sklearn.metrics import classification_report
target_names = results[0].unique().tolist()
report = classification_report(y_pred=results[1], y_true=results[0], target_names=target_names, output_dict=True)
pd.DataFrame(report).T

Discussion