2024年末と2025年の最初からAIエージェントについての議論が盛り上がっていますね。
これまでPharmaXでもYOJOというプロダクトで実現してきたAigentic Workflow(記事執筆当時はフローエンジニアリングと読んでましたが、エージェントがバズワード化したとことで、Aigentic Workflowの方がしっくりきそうだと感じてます)について、いくつかノウハウをシェアして来ました。
PharmaXではいち早くAigentic Workflowに取り組み、実際のビジネス成果を出しており、色々な所でも発表もさせていただいております。
今巻き起こっているAIエージェントについての議論には多少違和感があるので、今時点での自分の意見をまとめてみたいと思います。
今回の記事は、下記のみやっちさん(@miyatti)の記事にかなり触発されて、自分自身の考えを自分の言葉で書くことにしました。
特に私が言いたいことは、完全自律判断のAIエージェントこそが素晴らしいものであるかのように言われている現状にはかなり違和感があるということです。
先に本記事で言いたいことの要点を3つにまとめると、
- ワークフローを定義するAgentic Workflow型のAIアプリケーションをAIエージェントと呼ぶべきかどうかというAIエージェント定義論争は個人的にはどちらでもいい(今後の世の中の流れに迎合する気満々です)
- 現時点の技術では、複雑な業務を安定的にこなすには、ワークフローを定義するのが現実解ではないか
- ユーザーから見て「ほぼ放っておいても結果を出してくれる」「勝手にタスクを実行してくれる」ことで実際に価値がでているのであれば、裏側がどう作られていようともいいのではないか
ということです。
簡単にXなどで盛り上がっている議論と個人的な意見をまとめていきたいと思います。
Agentic Workflowとは何か
Agentic Workflowとは、あるタスクを1つのLLMですべて解かせるのではなく、そのタスクを細分化して、LLMやアプリケーションの実装を組み合わせてどう解いていくかをデザインすることを指します。
私の理解では、タスクの分岐によっては、LLMに解かせるのを諦めて人が解くパターンが含まれるたとしてもAgentic Workflowと呼びます。

例えば、カウンセリングAIを作ろうとしているとしたら、普段はLLMエージェントが対応しつつ、自殺願望を仄めかすような発言をした場合には、人間が対応するモードに切り替わるというようなイメージです。
このようにシステム、LLMの組み合わせ全体デザインし、目的とする処理系を作り上げることをAgentic Workflowと呼ぶと理解しています。
PharmaXでは、Agentic Workflowという言葉が注目される前から、実質的にAgentic Workflowを行っていました。
実装は、基本的にはLangGraphで行っています。
2024年は、DifyやBedrock Studioのようなほぼノーコードなツールや、PromptFlowのようなローコードツールも人気を博し、一気にAgentic Workflowを実現しやすくなりました。
YOJOでのメッセージ作成機能でのAgentic Workflowの例
具体例をあげた方が分かりやすいと思うので、PharmaXのYOJOというプロダクトのメッセージ作成機能におけるAgentic Workflowの概要をご説明します。
PharmaXのYOJOというサービスは、LINEで薬剤師に相談をして医薬品を購入できるというtoCサービスです。
今回例として取り上げるLLM機能は、ユーザーに対して返信するメッセージを自動送信、もしくは薬剤師にサジェストします。
下記が薬剤師メンバーが使うチャット画面です。
必要があれば、サジェストされた内容を薬剤師が確認し修正してから送信することもあります。
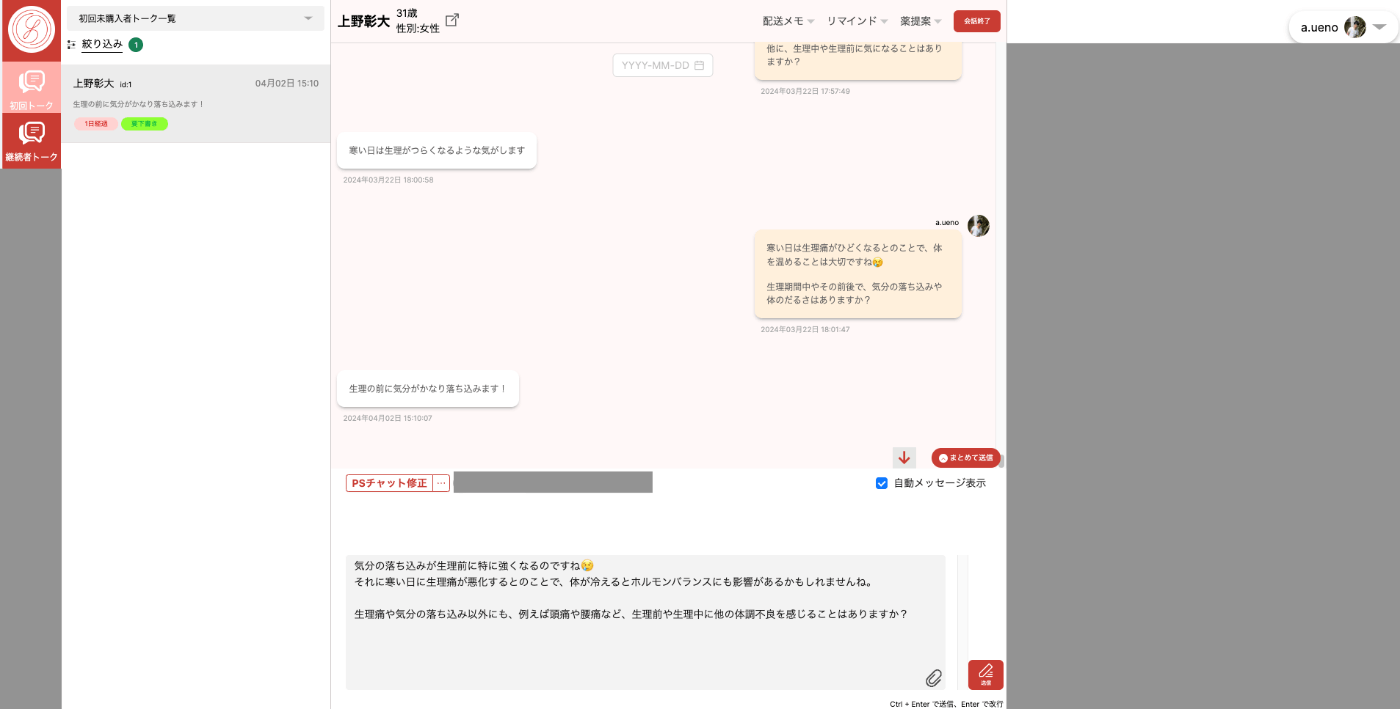
薬剤師が患者さんの状態を確認しつつ、チャットするための管理画面
YOJOのメッセージ作成機能は、
- ルールベースでLLM処理可能かを判定
- LLMで会話を分類しLLM処理可能かを判定
- LLMで次のフェーズに移るべきかどうかを判定
- LLMでメッセージを作成
- LLMで作成されたメッセージを評価(LLM-as-a-Judge)し、一定の水準を下回ったら再生成して、クリアしたもののみをサジェストする
という順番で動きます。
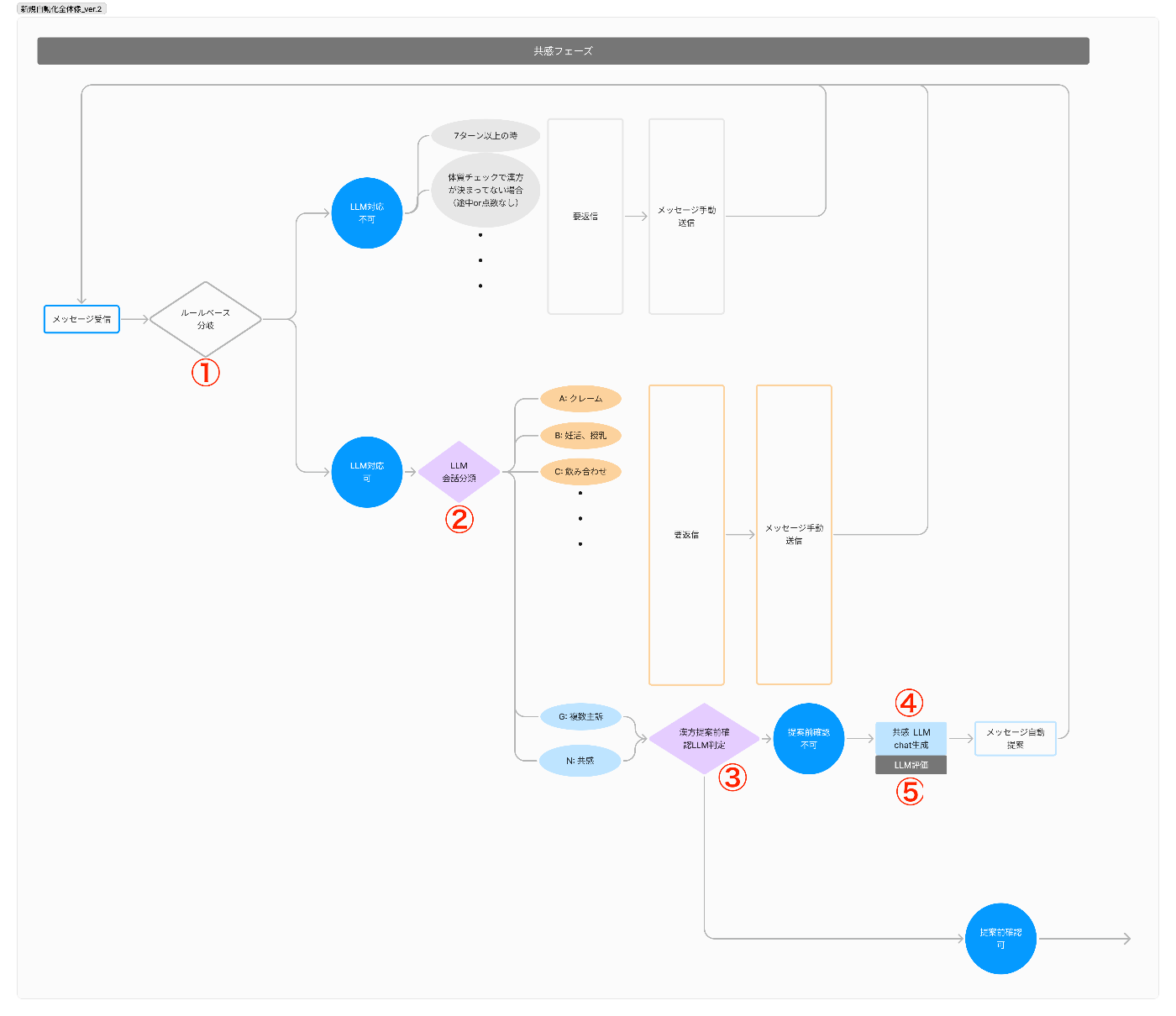
メッセージが作成されるまでの一連の処理イメージ
ただメッセージを生成させるだけで、かなり複雑な手順を踏んでいるのがお分かりいただけるかと思います。
会話分類の結果によっては、LLMでのメッセージ生成を諦めて、最初から薬剤師が対応するパターンもあります。
これは、安全性を鑑みてということでもありますが、(リソース不足や優先順位の問題で)精度高く出力するプロンプトをまだ作れていないだけという場合もあります。
今回は、詳細を省きますが、YOJOでは、フェーズという考え方で患者対応の段階を捉えていて、フェーズごとに動く処理のパターンやプロンプトを切替えています。
そのため、今このタイミングでフェーズを切り替えるかべきか?というのを判断するLLMエージェントも動いています。
このように目的とする処理を完了するまでに、ルールベースやエージェントの出力結果によってその後の処理を切替えたり、呼び出すプロンプトが変わったするのがAgentic Workflowです。
YOJOでAgentic Workflowで実現しているその他の業務
YOJOで自動化or半自動化を実現している業務をまとめると以下のとおりです。

例えば、ユーザーに合った漢方の選択までLLMが判断してしまいます(最終的には薬剤師がチェックします)。
裏では、各業務にそれなりに複雑なAgentic Workflowが定義されていますが、ユーザーや薬剤師から見れば、そのようなことを意識することはなく、いろんなことを勝手にやってくれます。
このようにユーザーや薬剤師から見て、さまざまな業務を自動化している私たちのシステムをエージェントと呼ぶのなら、ワークフロー型AIエージェントと呼べるのかもしれません。
やり方は任せるから結果出してくれればいいよ」
→自律型AIエージェント「うちはマニュアル通りに仕事して欲しいから、ちゃんと守ってね」
→ワークフロー型AIエージェント
この方の定義なら、YOJOはワークフロー型AIエージェントと呼べそうですね。
一方で、「ワークフローを定義しているものはエージェントとは呼べない」という意見もあるようです。
個人的には、普段はこのような定義の議論には踏み込まないようにしているのですが、私自身も混乱してきたので、自分のためにも少し整理してみたいと思います。
定義としてAgentic WorkflowをAIエージェントと呼ぶべきかの議論について
Agentic WorkflowでデザインされたシステムをAIエージェントと呼ぶべきではないという立場の方の主張は、
自律的とは「自分がとるべき行動を自分で決める」ということだから、ワークフローを人間が決めている時点でエージェントとは呼ばないのでは?ということのようです。
冒頭でも述べましたが、この定義論争に関して私は、「正直どちらでもよく今後の議論の流れに迎合しよう」というスタンスです(笑)
実際、この方のおっしゃっている「面倒なことが自動でできるようになったというだけでは、エージェントとは呼ばないのでは?」という視点は十分に理解できます。
AIエージェントの違和感について書きます。20年前の感覚だからずれてるかもだけど参考まで。
エージェントは「自律的に動くプログラム」と習った。自律的とは「自分がとるべき行動を自分で決める」という意味。
だからOpenAIのSwarmが、実行する関数を先に実装してしまうことが違和感だった。それじゃあエージェントじゃなくてただのプログラムと変わらないじゃん?って。
私の方で作らせてもらったゾルトラークウェブではYAML形式の作業指示書(スケジューラ)を入れた。プログラムの中身を書かずに柔軟に動きを変えることはできるけど、あくまでも書かれたことしかやらない。だからゾルトラークウェブは「デジタルコンテンツ生産ライン」であってエージェントではない。
ではLLMを使ったエージェントとは何か。「パターンにない行動はAIが自分でコードを書いて実行する」だと思ってた。ClaudeのComputer Useとか、リクエストからマウスとキーボードを動かすプログラムを裏で書いて動かすものだと思ってたが、どうなんだろう。
そして昨今のAIエージェントと謳っているものが「面倒なことが自動でできるようになりました」というサービスで、自分の習ったエージェントと違う。
AIエージェントの定義における論点は、どの視点で「自律的」か?という軸で整理できそう
上記で引用したツイートを拝見しても、どうやらAIエージェントの定義において論点となっているのは、「どの程度の自律性をもって行動を決定できるか」ということな気がしますよね。
ただ、この自律的という言葉は、見る人の立場や視点によって意味が変わってしまうややこしい言葉です。大きく分けて、ユーザー目線で見るか、開発者目線で見るかによって意見が変わってしまっているように感じます。
それぞれの目線から見た自律性についてまとめてみましょう。
ユーザー目線
ユーザーがタスクを指示したあとは「ほぼ放っておいても結果を出してくれる」と感じるなら、ユーザーからは“自律的に動いている”と見えているといってもいいかもしれません。
たとえ開発者が裏でワークフローを定義していようが、ユーザーが都度コマンドや選択を指示しなくても動いてくれるのであれば、「エージェントっぽい」と認識するでしょう。
“ユーザーが逐一介入しなくても完結している”ならエージェントと呼んでいい、
つまり、ユーザー視点を重視して、「ある程度レールに乗せられたプログラム」でも、少なくともユーザーにとっては“自律的”に映るならエージェントと呼んでしまおう、
という考え方です。この考え方は一理あるような気がします。
開発者目線
一方、開発者目線では、「このフローどおりに進みなさい」「選択肢が複数ある場合はそのうちのどれかを選びなさい」と指示を与えているのであれば、エージェントというよりは「定義済みワークフローをこなすプログラム」と捉えたくなる気持ちも分かります。
逆に、開発者が「目的はこれだけど、過程で必要なコードや処理をAI自身が生成して実行できる」ようにしているなら、よりエージェントらしい“自律性”があるとみなせます。
開発者の視点からみれば、“(開発者も含め)誰も行動手順を制御していないほど自由に動ける”のがエージェントだから、「内部的にかなりの自由度を持ち、必要ならプログラムも書き足して外部ツールを連携して…といった振る舞いができる」レベルのものをエージェントと呼ぶべき、という考え方もそれはそれで分からなくはありません。
このようなレベルのエージェントを本記事では、「完全自律型エージェント」と呼ぶこととしましょう。
function-callingやtoolsを定義する場合でも、取れる選択肢を指示しているわけだから、完全自律型エージェントとは呼ばなさそうです。
上記で引用したPostの方は、こちらの開発者目線での疑問を投げかけられているような気がしますね。
自律性にも段階・グラデーションがあることにも注意
ここまでは、議論をわかりやすくするため、完全自律型とワークフロー型を対立させて書いてきましたが、実際には自律性にも段階・グラデーションがあります。
-
完全に定義済みワークフロー型
- 開発者がタスクや処理手順をほぼすべて書いており、AIはそれを順番に実行するだけ。
- たとえばレシピを細かく手順どおりにこなすロボットのように、外部から見ると“自動化”ではあるが、実質は「あらかじめ定義されたシナリオを再生しているだけ」。
-
選択肢をAIに委ねるワークフロー型(Agentic Workflow)
- 全体の流れや大枠は決まっているが、各ステップでどのツールを使うか、何を生成するかなど具体的な行動はLLMなどが選べる余地がある。
- “中程度”の自律性で、ユーザーからは「途中経過に口を出さなくても勝手に仕事を進めてくれる」ように見える一方、開発者としては大枠が決まっているので暴走はしにくい。
-
目標だけを与えて手段はAIが自由に考える型(完全自律型)
- どんなコードを書いて実行するか、どの外部APIやサービスを呼び出すかも、ほぼAIの判断に委ねる。
- 「新たなタスク分解を生成→必要なツールを使って実行→結果を受けて次の手を考える」というループを完全自律で回す。
このように考えると、2と3の中間レベル=ハイブリッド型というのものも十分にあり得ます。
冒頭の記事でみやっちさんもおっしゃってますが、
ある程度の段取りやフェーズを決めておきつつ、途中で動的に追加情報や別のツールを活用して意思決定する っていうハイブリッドなやり方は、普通にあり得ますよね。
というようなイメージです。

ワークフローで分岐させたここから先は、“エージェント的な柔軟さ”も混ざっているとか、
基本的には、ワークフローを構築するけれども、自律的に判断できる余地も残しておくという設計も不可能ではなさそうです。
完全な対立構造ではなく、“グラデーション”もあり得るということを意識しておくとよいかもしれません。
定義に関する議論のまとめ
それぞれの目線とグラデーションででAIエージェントと呼べるかをまとめると以下のようになります。
| 完全自律型 | ハイブリッド型 | ワークフロー型 | |
|---|---|---|---|
| ユーザー目線 | ◯ | ◯ | ◯ |
| 開発者目線 | ◯ | ✕ | ✕ |
このようにAIエージェントの自律性についての議論は、
ユーザー目線と開発者目線のどちらから主張がなされているのかを区別し、
グラデーションもあり得ることを念頭に置いておくと、
混乱を避けることができそうです。
本記事では、AIエージェントの定義に関する議論に決着をつけたいという意図はありません。ある程度整理することができたので、個人的には満足です。
ここまで定義に関する議論をまとめてきましたが、本記事で私が主張したいことはあくまでここからが本題です。
私の主張は、
- Agentic Workflowのようにワークフローを組む必要があるなら迷わず組むべきではないか
- ユーザーから見て自動で十分に複雑なタスクを自動化してくれる便利な存在であれば、裏側で大枠のフローを人間が定義していようがいまいがどちらでもよいのではないか
ということであり、定義はそこまで興味がありません。
つまり、
「何でも自律判断の完全自律型AIエージェントこそが至高」
→ これは分からない。ユーザーに価値が出ていれば、どう作られていようとも良いじゃないの。
「何でも自律判断の完全自律型AIエージェントが2025年の始めから爆発的に流行する」
→ これもかなり怪しいと思う。まだその次元までは到達しておらず、なんだかんだで人による指示やワークフローの定義があった方が簡単かつ安全なケースは多い。1年後のことは知らん。
「何でも自律判断できなければAIエージェントとは呼べない(完全自律型のみをAIエージェントと呼ぶ)」
→ これは定義の話をしているだけで、どっちの方が優れているとも言っていないので分かる。主張が論理的に理解ができるというだけではなく、気持ちも分かる。
という感じでしょうか。
定義の話はここまでにして、ここからはもう少し踏み込んで私の違和感を整理してみたいと思います。
現実的に完全自律的にこなせる業務は少ないはず(その上、無理して完全自律で行う必要もない)
言いたいことは、現実的に完全自律型エージェントでこなせる業務などそこまで多くはないのではないかということです。
実際の業務で私たちがエージェントを使う場合には、「ルール(ガードレール)」や「制約条件」を与えたくなりませんか?
会社としては、「このツール群を使って欲しい」「この業務ではこの選択肢しかない」「社内のドキュメントのルールはこんな感じだ」「ユーザーへの対応では、✕✕よりも〇〇を優先する」というようなルールがあるはずです。
あるいは、「この業務のあとに、この業務を必ず行って」や「この業務は途中経過を〇〇に報告して」というルールもあるかもしれません。
もう少し分かりやすくするため、場合分けして考えてみましょう。
各LLMにルールやガードレールを定義できる場合
例えば、YOJOでは、(最終的には薬剤師がチェックするものの、)LLMが顧客に合った漢方を選択すると述べました。
この時、
- 性別、年齢、身長、体重などの基本情報
- 体質に関する質問への回答
- ユーザーの好みの剤形(顆粒か錠剤かなど)
- アレルギー
- 現在他に飲んでいる薬との飲み合わせ
などの情報をもとにLLMがユーザーにオススメできそうな漢方を選択します。
ただし、どんな漢方でも自由に選んでいいというわけではありません。私たちが在庫として抱えている漢方の中から選択する必要があります。
このような場合、イメージで言えば、その漢方の選択肢をプロンプトに与えて、「この中から最適なものを選んでください。」とするのが自然ではないでしょうか。(実際には、その他にもたくさんの指示を与えています。)

確かに、YOJOのアプリケーションのデータベースや、在庫管理システムにアクセスすれば、どのような漢方の選択肢があるのかをLLMが知ることは可能です。
ですが、そのようなことを毎度行うぐらいなら、最初からプロンプトに選択肢を与えてやればいいのです。
毎回自律的に環境から情報を読み取って判断するのは、処理にも時間がかかりますし、安定性の面でも不安があります。
ワークフローを定義できる場合
また、YOJOでは、ユーザーに最適な漢方を選択し、その漢方をユーザーにオススメするメッセージを送ります。(※処方行為ではありません。)
この時、ユーザーからのメッセージ受信をトリガーとして、次のような判断が行われています。話がややこしくなるので、薬剤師のチェック工程を省いて記載します。
- (ユーザーからのメッセージを受信する)
- ①ユーザーの体質や好みについて十分な情報が出揃ったことを判断し、次のフローをトリガーする
- ②LLMがそれまでの情報からユーザーに合った漢方を選択し、DBに入れる
- この際には、それまでの会話やユーザーの入力からさまざまな情報を総合して判断する
- ③LLMがユーザーに合った漢方を提案するためのメッセージを作成する
- ④メッセージを評価して、一定の水準を下回った場合には再度作成する
- (ユーザーにメッセージを送信する)
つまり、「あなたのような体質の方には、〇〇という漢方がオススメできます」というメッセージが送られるまでの間に複数の判断が行われます。
このように人間の思考過程をトレースしてワークフローを定義できる場合、わざわざ毎回自律的に考えさせる意味があるのでしょうか。
このとき、①〜③のプロンプトを分けて、LangGraphなどでグラフ構造を作るかどうかは本質的には関係がありません。
1つのプロンプトで実行する場合も①〜③のような順番で考えるように指示する場合は、実質ワークフローを組んでいるのと同じです。
また、基本的には、③メッセージ作成プロンプトと④評価者プロンプト(LLM-as-a-Judge)は分けるべきとされています。
このメッセージ作成と評価だけの工程だけ取り出しても十分にワークフローということもできます。
プログラミングやスライド作成のように成果物が明確で、思考過程のパターンも万国共通なものはわざわざワークフローを組む必要もなく、選択肢を与えずとも行動計画から実際の行動までLLMが考えられるのかもしれません。
ですが、多くの業務では、ワークフローを開発者がきちんと組んでおく方が安定的に正しい判断を取ってくれる可能性が高く、わざわざ完全自律型で業務をさせて不安定になるリスクを冒す必要はないのでは、という気がします。
安定性が高まる以外にワークフローを構築することのメリット
これまで述べてきた業務の安定性が高まる以外のワークフローを組むことの明確なメリットについても触れておきましょう。
それは、人間の思考過程や業務フローと同じようにLLMのワークフローを組む方が、途中経過を確認しやすいということです。
例えば、業務遂行が途中でうまく行かずに止まってしまった場合でも、人間が理解しやすいワークフローで仕事をしてくれていれば、デバッグもしやすく、途中から人間が仕事を引きづけるかもしれません。

また、最終的なアウトプットが私たちの期待とズレていたときでも、ワークフローを理解できれば、どこまでは期待通りで、どこから先でアウトプットがズレてしまったのかを評価しやすくなります。
一方、結果さえ出してくれれば手順は問わないという発想だと、業務の手順が人間に分かりやすい形式になっていない可能性があります。
完全自律型のAIエージェントに、人間の想定とかけ離れた方法で作業をされると、失敗したときに途中から引き継ぐのも難しく、アウトプットが微妙だったときも原因を特定するのが難しくなります。そうした状態に陥ると、手戻りや修正にかかる時間とコストが大きく膨らむリスクがあります。
さらに、どのような意図や思考過程でそのアウトプットに至ったのかを第三者に説明することが難しくなるため、組織内で共有しづらくなってしまうかもしれません。
既存のワークフローを踏襲しすぎない方がいいこともある
ただし、既存のワークフローが理想とはかけ離れている場合には、ワークフローそのものを再定義をした方がいいでしょう。
人間がやっていても無駄な作業をAIエージェントにさせ続ける必要はありません。
これ(※筆者注:ステップの削除、ワークフローの設計の見直し)やらないとマジでスケーリングで開発工数過多で死ぬか途中でAgentがキャパオーバー起こして精度的に機能しなくなるので、いい機会なのでスリム化は常に意識した方がいい。そのまま人間の業務フローをトレースしない方がいい。
まさにこのご意見には賛成で、削れる業務は削った方がいいですし、効率的になるならワークフローの再設計は必要です。
ただ、これは、「ワークフローを組むな」という話では当然なく、”クソなワークフロー”をそのまま踏襲するのはやめましょうというだけのことです。
複雑な業務を完全自律型エージェントで実現するには何が必要か
ここまで、複雑な業務はAI化するには、ワークフローを組んだ方がいいというスタンスを取ってきましたが、どうしても完全自律型で実現したい場合には、どうすればいいのかということも考えてみたいと思います。
ここからは少し妄想(よく言えば未来予想)も混じりますが、話半分に聞いていただければと思います。
完全自律型で複雑な業務を実現するには、フィードバックと記憶の仕組みが必要だと考えています。(技術的にどういうアーキテクチャが必要かは最後の付録に記載しました。)
要は、完全自律型のエージェントに対してオンボーディングとOJTをできればいいのです。
しかし、実際にエージェントを運用しようとすると、複雑な業務ではインプットとアウトプットのパターンが膨大になります。
(データ形式で与えても、口頭で説明してもいいのですが、)「こういう場合には、こういうアウトプットが理想だ」というありとあらゆるパターンを教えるのは一苦労です。
すべてエージェントが“自律的に”学んでくれることが理想だとしても、データ量や検証の手間を考えると、実用的な精度とスピードで仕上げるのは簡単ではないでしょう。
そうなると、人間側はどうしても仕事の手順や考え方のフレームワークを指示したくなります。
なぜなら、そうした方が効率的だからです。
人間を教育する際も同じで、最終的なアウトプットに対してのみフィードバックするわけではなく、課題をどう整理してどうアプローチするかといった“仕事のやり方”を教えるはずです。
一度教えてしまえば、同じような業務ではより良いアウトプットにたどり着けるようになるからです。
そして、そのためには、途中の実行結果や、途中のプロセスに対してもAIエージェントにフィードバックをかけられるような仕組みが必要です。
結局のところ、完全自律を謳うエージェントであっても、人間によるステップごとの教育プロセスが必要になるわけです。
こうしたフィードバック工程を積み重ねるうちにエージェントが“自分”で「こういう時にはこの行動を取るべき」と学んでいく流れを考えると、それは本質的に“ワークフローの学習”といっても差し支えないものかもしれません。
開発者が事前にワークフローを定義していなくても、エージェントが経験を通じて「最適な手順」を暗黙的に身に付けるのであれば、それはもはや“エージェント版ワークフロー”といえるでしょう。
要するに、いくら完全自律型を目指すとしても、複雑なプロセスをオンボーディングするためには途中経過へのフィードバックや“仕事のやり方”の指導が必要になります。結果として、内部的には“自動生成されたワークフロー”や“学習された手順”が構築されていくのであって、「完全自律だけどフローを一切持たない」という状態に到達するのは、現実的ではないように思います。
つまり、「もはや人間と違わないような汎用的なエージェントができてしまえば、開発者のカスタマイズなしにあらゆる業務を学習できるようになるが、ワークフローが不要かといえばそういう話ではない」ということでしょうか。
そんな汎用AIエージェントが爆誕するまでは、複雑な業務に対しては、大人しく開発者がワークフローを定義するのが妥当だと考えています。
AIエージェントに関する個人的意見のまとめ
ここまで色々考えてきましたが、要は私が最も言いたいことを一文で言うなら、
「ユーザーに価値が出ていれば、裏側の仕組みはどうでもよくて、最も価値が出るように作れば良くない?」ということです。
ワークフローが必要だと思えば、悩まずワークフローを組めばいいのでは?ということに尽きます。
そして、実際のところ、今時点の技術で複雑な業務を自動化しようと思えば、ワークフローを組む方が安全かつ早いことも多いよねということです。
完全自律型がどうとか、いつ来るかとか言う前にユーザーに価値を出しましょう。
最後に
今回は、AIエージェントに関する現時点での私の意見をまとめました。
2024年末からなんとなくモヤモヤしていたことを言語化してみたのですが、いかがだったでしょうか。
反論やディスカッションはウェルカムです。
登壇があったので、急遽プレゼン形式にもしてみました。
もし直接議論してみたいという方がいらっしゃれば、是非DMでご連絡いただければ幸いです。
付録:完全自律型エージェントを実現するための技術的仕組みについて
私の記事をo1 pro modeに読み込ませて、完全自律型エージェントを実現するためにはどのような仕組みが必要かをディスカッションしました。
付録として、その内容をシェアしたいと思います。
完全自律型エージェントが複雑な業務をこなすには、以下のような技術的・構造的な工夫が必要になるでしょう。
-
状態管理とメモリ構造の整備
完全自律型エージェントが各タスクの途中経過や結果を自分で保持し、必要に応じて参照できる「内部メモリ(短期・長期)」が必須です。たとえば、ユーザーとの対話ログや行動履歴だけでなく、中間的な計算結果や判断の根拠などを細かく保存できる仕組みが必要になります。- 短期メモリ: 直近の会話や作業ステップの履歴。これはセッションごとに使い捨てになるかもしれませんが、都度最適な判断をするためのコンテキストとして重要です。
- 長期メモリ: 複数回のやり取りや長期的な学習結果を蓄積し、後から再利用できるストレージ。たとえば、これまで解決したケースや教訓を事後的にまとめ、次のタスクで活かすためのDBスキーマを設計しておく、などが考えられます。
- イベントソーシング的アプローチ: エージェントが行った一連のアクションや判断を時系列で記録しておくことで、どのタイミングで何を参照したかが可視化しやすくなり、失敗時のトレースや再学習に役立ちます。
-
フィードバックを可能にする観測ポイント・インタフェース
複雑なタスクを自律的にこなすには、“どのステップで何が行われたのか”をエージェント自身や人間が把握し、逐次フィードバックを与えられるようにする“観測ポイント”が必要になります。- プロセスの可視化・インスペクション: エージェントが動いている最中や完了時に、その判断過程や使った知識リソースを可視化できるダッシュボード的機能。LLMがどのようなプロンプトを受け取り、何を生成し、どの関数や外部APIを叩いたのかをトレースできると、エラーや判断ミスが起きた箇所を特定しやすくなります。
- インタラクティブな修正・介入: 完全自律とはいえ、複雑なプロセスでは途中で人間が口を挟まないといけない場面が出てきます。その際に、どのステップの何を修正するかを指示できるUIやAPIインタフェースを設計しておくことで、エージェントの自律性と人間の管理可能性を両立できます。
-
外部ツールやAPIとの連携と安全性
完全自律型エージェントが複雑な業務をこなすためには、実際の業務システムや外部ツールと結合し、必要なデータや機能にアクセスしていく必要があります。そのために必要な仕組みとしては、- 権限管理・ロールベースのアクセス制御: エージェントが勝手にあらゆるシステムのAPIを叩けると危険です。必要最小限の権限で動かしつつ、安全に外部システムと連携できる仕組みが求められます。
- サンドボックス環境や実行制御: エージェントが自由にコードを書いてツールを実行するアーキテクチャを考えるなら、誤操作やセキュリティリスクを最小化するために、サンドボックス環境で実行を隔離する技術や厳格なエラーハンドリングが不可欠です。
- 監査ログの蓄積: いつ、どのエージェントが、どのAPIを呼び出したのか――といった情報を記録・監査できる設計を行っておかないと、トラブルシュートや不正検知が難しくなります。
-
動的なワークフロー生成や学習プロセスの取り込み
完全自律を目指すのであれば、事前にワークフローを人間が定義しなくても、エージェントが過去の成功事例や失敗事例を学習して“手順”を生成・更新していく仕掛けが必要になります。- ワークフロー自動生成モジュール: 経験から学んだパターンをエージェントが自己組織化的にフローとして表現する。これは高度なメタ学習の領域かもしれませんが、少なくとも手順を抽象的に保存して再利用するための内部構造が必要になります。
- 反省や振り返り(Reflection): タスク達成後に結果とプロセスを照合し、「うまくいった理由・失敗した理由」を分析する機能があると、自律的にワークフローを最適化していくことが可能になります。これを実現するには、ログや履歴データをまとめて学習し直す仕組みや、対話的に改善案を導き出せるようなフレームワークが望まれます。
総じて、完全自律型エージェントを実用化するためには、“その時々の判断と振る舞い”をリアルタイムあるいは段階的に捉え、必要に応じて人間が介入できる観測インタフェースと、安全で拡張性のある実行環境がカギになるといえそうです。こうした技術基盤が揃って初めて、“エージェント版のワークフロー”をエージェント自身が学習し、実行し、改善していく未来が見えてくるのではないでしょうか。
言っていることは確かにしっくり来ますね。

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion