はじめに
こんにちは。PharmaXでエンジニアをしている諸岡(@hakoten)です。
この記事では、LangGraphのデータ永続化機能であるCheckpointerとStoreについて解説します。
2024年の現時点で、LLMによる複雑なエージェントを構築するには、各LLM実行における横断的なデータ保存の仕組みが不可欠です。
LangGraphのCheckpointerとStoreを活用することで、LLMの実行状態を効率的に保存・復元したり、複数の会話セッションにまたがるデータ管理が可能となります。
環境
この記事執筆時点では、以下のバージョンで実施しています。
LangChain周りは非常に開発速度が早いため、現在の最新バージョンを合わせてご確認ください
- python: 3.12.4
- langchain: 0.3.1
- langchain-openai: 0.2.1
- langgraph-checkpoint-postgres: 1.0.9
- langgraph: 0.2.39
LangGraphによるデータ永続化の仕組み(Checkpointer, Store)
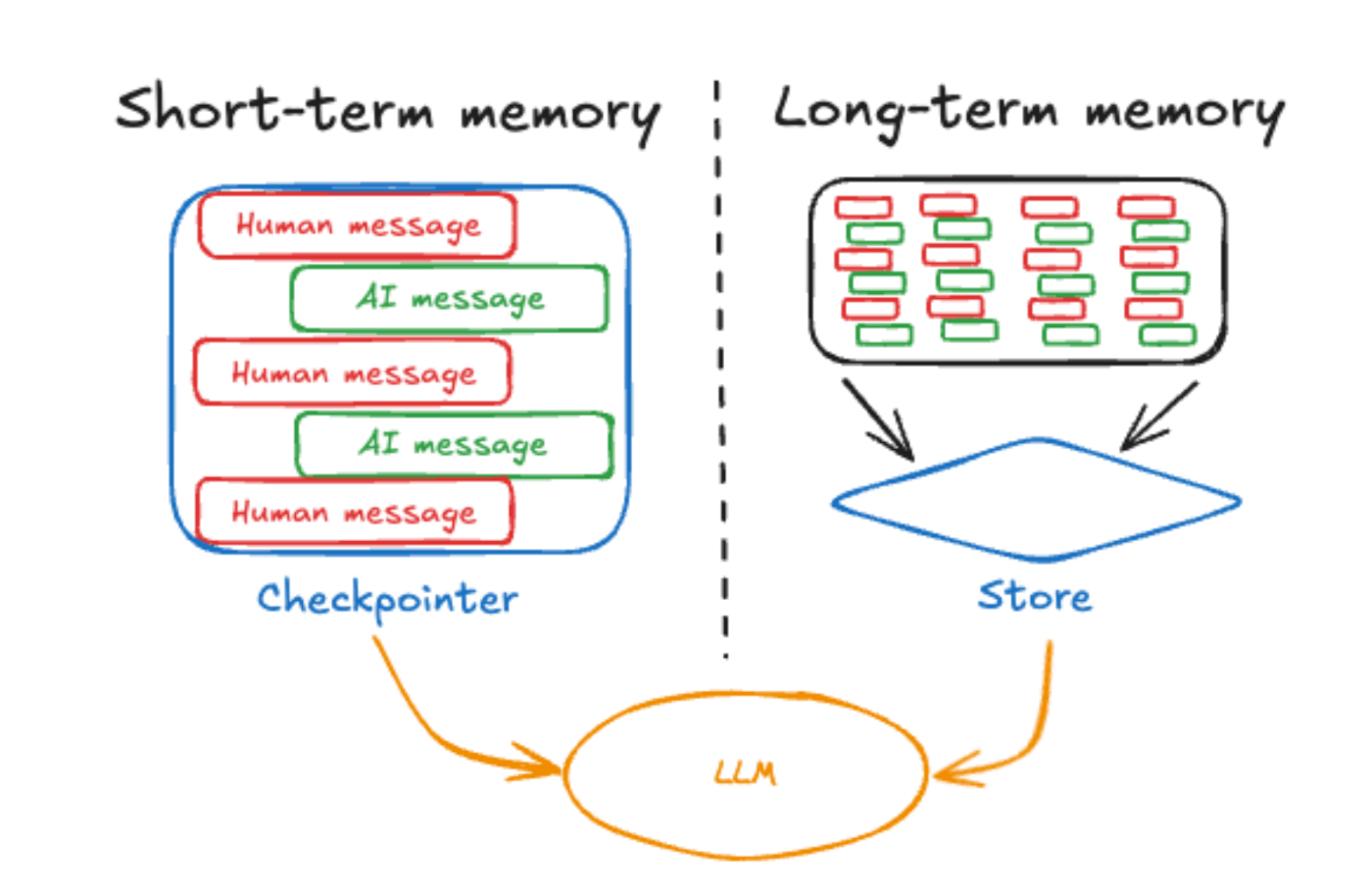
LangGraphでは、データの永続化の仕組みとしてCheckpointerとStoreという2つの機能を提供しています。まずはそれぞれの概要を説明します。
Checkpointerの概要
https://langchain-ai.github.io/langgraph/concepts/persistence/#persistence
Checkpointerは、特定のグラフの状態をスナップショットとして保存し、必要に応じてその状態を復元する機能です。これにより、グラフを以前の状態へ戻したり、パラメタを変更して再開することができます。Checkpointerは、1つの会話(スレッド)単位で管理され、thread_id というユニークIDを使って状態を管理します。
状態を保存・復元するだけではなく、Checkpointerを設定している会話(スレッド)中はその内容は各LLM実行に引き継がれています。同じスレッド内では前のLLM実行の内容を記憶した状態で、次のLLMの実行を行うことが可能です。
Storeの概要

https://langchain-ai.github.io/langgraph/concepts/persistence/#memory-store
Storeは、LangGraph v0.2.32で導入された新機能で、スレッド間を跨いでデータを保存する仕組みです。Checkpointerが特定のスレッド内の状態を保存するのに対し、Storeは複数のスレッドを横断した永続化が可能です。
CheckpointerとStoreの役割
Checkpointerは、「特定のグラフの状態を保存し、復元する」ことを目的としています。データベースの復元に使用されるチェックポイントと似たような役割に近いです。
一方のStoreは、「アプリケーションやユーザーのデータを保存し、必要なタイミングでアクセスする」ことを目的としています。
LangChainの文脈では、Checkpointerを「短期記憶」、Storeを「長期記憶」と表現しています。1回の会話の中で必要な情報を保持するのが短期記憶であり、複数の会話にわたって保持する必要がある情報が長期記憶という整理です。
公式ドキュメントでは、さらに詳しい説明が記載されていますので、あわせてご覧ください。
Checkpointer
ここでは、Checkpointerの基本的な使い方や仕組みについて説明します。
基本的な使い方
Checkpointerの基本的な実装例は次のとおりです。
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
model = ChatOpenAI(model='gpt-4o')
def call_model(state: MessagesState):
response = model.invoke(state['messages'])
return {'messages': response}
builder = StateGraph(MessagesState)
builder.add_node('call_model', call_model)
builder.add_edge(START, 'call_model')
graph = builder.compile()
# checkpointerをコンパイル時に指定する
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
# thread_idを指定する
config = {'configurable': {'thread_id': '1'}}
graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '最も人口の多い国は?',
}
]
},
config,
)
# チェックポイントを取得する
checkpoint = memory.get(config)
print(checkpoint)
Checkpointerを有効にするには、LangGraphのGraphコンパイル時に BaseCheckpointSaver
を継承したインスタンスを checkpointerパラメタに指定します。
...
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
...
また、Checkpointerは、1回の会話(スレッド)のスナップショットを管理するため、実行時にthread_id を指定する必要があります。
...
config = {'configurable': {'thread_id': '1'}}
graph.invoke(..., config)
...
Checkpointerインスタンスの getメソッドを使用することで、スレッドのチェックポイントデータ(Dict)を取得可能です。
...
config = {'configurable': {'thread_id': '1'}}
...
checkpoint = memory.get(config)
print(checkpoint)
get メソッドで取得できるチェックポイントのデータは次のとおりです。
保存されているチェックポイントのデータ
{
"v": 1,
"ts": "2024-10-23T22:33:32.210107+00:00",
"id": "1ef918ed-5525-6616-8001-6b42672d0b6a",
"channel_values": {
"messages": [
{
"content": "最も人口の多い国は?",
"additional_kwargs": {},
"response_metadata": {},
"id": "2331a402-dc05-4f49-a33d-2067e6fce2a4"
},
{
"content": "最も人口の多い国は中国です。ただし、インドも非常に人口が多く、近年その差は縮まってきています。最新の正確な人口統計を確認するには、国連などの信頼性のある情報源を参照してください。",
"additional_kwargs": {
"refusal": null
},
"response_metadata": {
"token_usage": {
"completion_tokens": 63,
"prompt_tokens": 16,
"total_tokens": 79,
"completion_tokens_details": {
"reasoning_tokens": 0
},
"prompt_tokens_details": {
"cached_tokens": 0
}
},
"model_name": "gpt-4o-2024-08-06",
"system_fingerprint": "fp_a7d06e42a7",
"finish_reason": "stop",
"logprobs": null
},
"id": "run-5a91b793-0ce6-406b-a2f1-df7a589e8254-0",
"usage_metadata": {
"input_tokens": 16,
"output_tokens": 63,
"total_tokens": 79
}
}
],
"call_model": "call_model"
},
"channel_versions": {
"__start__": "00000000000000000000000000000002.0.39325310677145675",
"messages": "00000000000000000000000000000003.0.7382122689936367",
"start:call_model": "00000000000000000000000000000003.0.4101423175271871",
"call_model": "00000000000000000000000000000003.0.9472718495434523"
},
"versions_seen": {
"__input__": {},
"__start__": {
"__start__": "00000000000000000000000000000001.0.927114866214825"
},
"call_model": {
"start:call_model": "00000000000000000000000000000002.0.939184747327784"
}
},
"pending_sends": []
}
CheckpointerによるLLMの実行状態の保持
Checkpointerは、指定された thread_idの単位で、LLMの実行状態を保持しています。次の例のように同じ thread_id を指定することで、前回の会話内容を引き継いだ状態でLLMを実行することができます。
config = {'configurable': {'thread_id': '1'}}
...
answer1 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': 'こんにちは。私の名前は山田太郎です。',
}
]
},
config,
)
print(answer1['messages'][-1].content)
print('--------------------------------')
answer2 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '私の名前はなんですか?',
}
]
},
config,
)
print(answer2['messages'][-1].content)
...
(実行結果)
こんにちは、山田太郎さん。今日はどのようにお手伝いできますか?
--------------------------------
あなたの名前は山田太郎さんです。
チェックポイントの復元
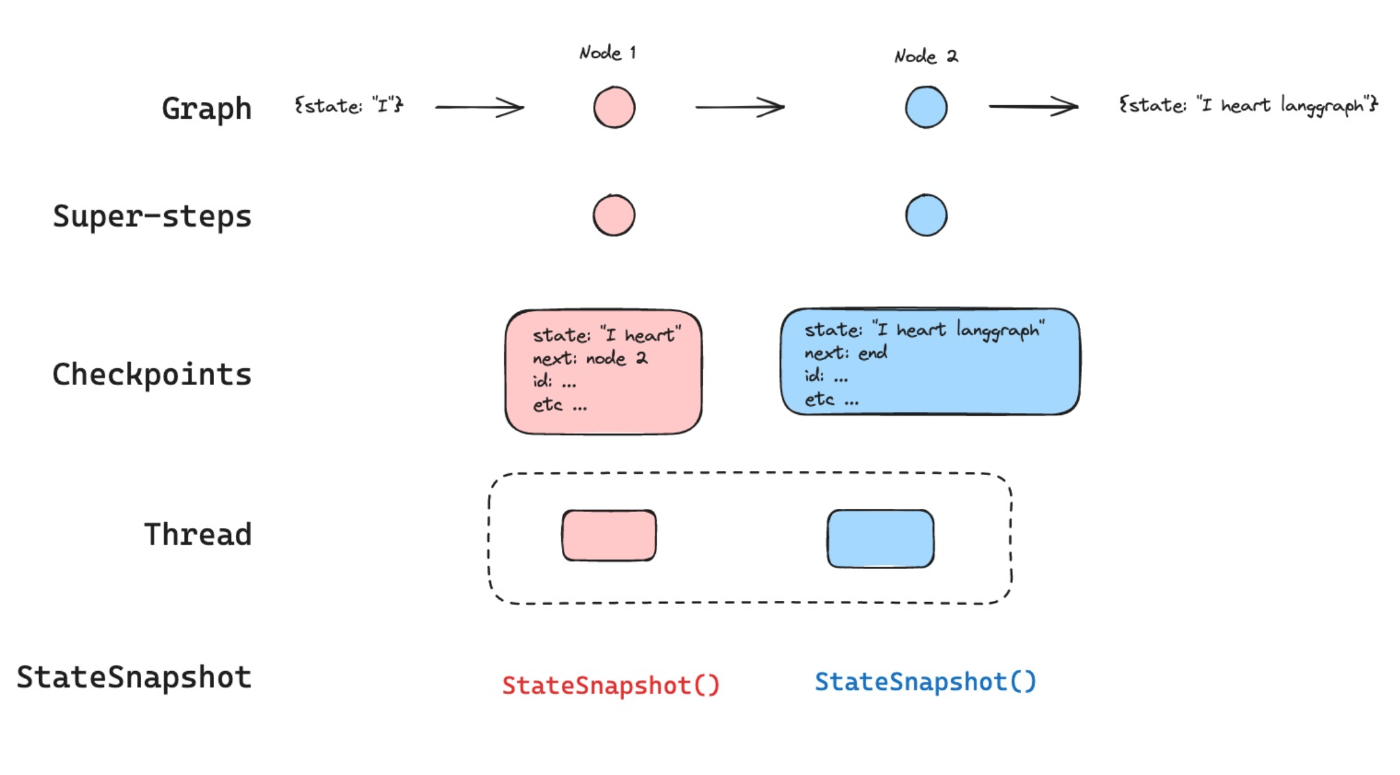
Checkpointerでは、特定の時点のスナップショットに基づいて過去の状態に戻ることができます。復元する際には、スナップショットごとに割り当てられる checkpoint_id と、会話セッションを特定するための thread_id が必要です。
これら2つの情報をconfigとしてグラフの実行時に渡すことで、特定のグラフ状態を復元できます。
LangGraphの各ステップの checkpoint_id の取得
復元したいステップの checkpoint_id を取得するには、get_state_history メソッドを使用します。
...
all_states = []
for state in graph.get_state_history(config):
all_states.append(state)
...
get_state_history を使用すると、StateSnapshot インスタンスを取得できます。この StateSnapshot には、checkpoint_id や thread_id など、各ステップに関する情報が含まれています。
(StateSnapshotに含まれるconfig)
...
"config": {
"configurable": {
"thread_id": "1",
"checkpoint_ns": "",
"checkpoint_id": "1ef92557-7860-6218-8000-51977d4fce1e"
}
}
...
StateSnapshot全体のサンプル
{
"values": {
"messages": [
{
"content": "こんにちは。私の名前は山田太郎です。",
"additional_kwargs": {},
"response_metadata": {},
"id": "038a3ea3-2630-4694-a868-22de5a5a634c"
}
]
},
"next": ["call_model"],
"config": {
"configurable": {
"thread_id": "1",
"checkpoint_ns": "",
"checkpoint_id": "1ef92557-7860-6218-8000-51977d4fce1e"
}
},
"metadata": {
"source": "loop",
"writes": null,
"step": 0,
"parents": {}
},
"created_at": "2024-10-24T22:15:24.692111+00:00",
"parent_config": {
"configurable": {
"thread_id": "1",
"checkpoint_ns": "",
"checkpoint_id": "1ef92557-7854-68be-bfff-d83335fd340c"
}
},
"tasks": [
{
"id": "043bd1e6-23a5-e0d7-9f3f-7ba9ceab58ea",
"name": "call_model",
"path": ["__pregel_pull", "call_model"],
"error": null,
"interrupts": [],
"state": null,
"result": {
"messages": {
"content": "こんにちは、山田太郎さん。お会いできて嬉しいです。今日はどのようなことをお手伝いできますか?",
"additional_kwargs": {
"refusal": null
},
"response_metadata": {
"token_usage": {
"completion_tokens": 31,
"prompt_tokens": 19,
"total_tokens": 50,
"completion_tokens_details": {
"reasoning_tokens": 0
},
"prompt_tokens_details": {
"cached_tokens": 0
}
},
"model_name": "gpt-4o-2024-08-06",
"system_fingerprint": "fp_90354628f2",
"finish_reason": "stop",
"logprobs": null
},
"id": "run-1fda52ef-344d-4c32-aca0-a527908ac231-0",
"usage_metadata": {
"input_tokens": 19,
"output_tokens": 31,
"total_tokens": 50
}
}
}
}
]
}
状態の復元と上書きの例
特定のステップを復元するして、別の内容に上書きしてみます。
まず、1回目のLLM実行では、「次に与える2つの数字に対して、計算してください [1,2]」というプロンプトを与えます。次に、2回目のLLM実行では、「与えられた数字の合計は?」と質問します。
その後、2回目の状態を復元し、プロンプトを「与えられた数字を掛け算してください」に上書きして、同じグラフを実行します。
answer1 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '次に与える2つの数字に対して、計算してください [1,2]',
}
]
},
config,
)
answer2_1 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '与えられた数字の合計は?',
}
]
},
config,
)
print('復元前の回答: ', answer2_1['messages'][-1].content)
# 各ステップのチェックポイントを取得
all_states = []
for state in graph.get_state_history(config):
all_states.append(state)
answer2_2 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '与えられた数字を掛け算してください',
}
]
},
# 2回目のLLM実行のスナップショットを指定する
all_states[3].config,
)
print('--------------------------------')
print('復元後の回答: ', answer2_2['messages'][-1].content)
全てのコード
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import START, MessagesState, StateGraph
model = ChatOpenAI(model='gpt-4o')
def call_model(state: MessagesState):
response = model.invoke(state['messages'])
return {'messages': response}
builder = StateGraph(MessagesState)
builder.add_node('call_model', call_model)
builder.add_edge(START, 'call_model')
graph = builder.compile()
# checkpointerをコンパイル時に指定する
memory = MemorySaver()
# thread_idを指定する
config = {'configurable': {'thread_id': '1'}}
graph = builder.compile(checkpointer=memory)
answer1 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '次に与える2つの数字に対して、計算してください [2,3]',
}
]
},
config,
)
answer2_1 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '与えられた数字の合計は?',
}
]
},
config,
)
print('復元前の回答: ', answer2_1['messages'][-1].content)
# 各ステップのチェックポイントを取得
all_states = []
for state in graph.get_state_history(config):
all_states.append(state)
answer2_2 = graph.invoke(
{
'messages': [
{
'role': 'user',
'content': '与えられた数字を掛け算してください',
}
]
},
all_states[3].config,
)
print('--------------------------------')
print('復元後の回答: ', answer2_2['messages'][-1].content)
実行結果は以下の通りです。
復元前の回答: 与えられた数字 2 と 3 の合計は、2 + 3 = 5 です。
--------------------------------
復元後の回答: 与えられた数字 2 と 3 の掛け算は次の通りです。
2 × 3 = 6
このようにCheckpointerを使うと、1回目のLLMの結果を保持したまま特定のポイントまで戻り、異なるパラメータで再度LLMを実行することが可能です。
なお、LangGraphのマネージドホスティングサービスであるLangGraph Cloudでは、Checkpointerはデフォルトで有効になっています。また、付属のIDEであるLangGraph Studioでは、チェックポイントを利用して特定のステップで状態を分岐させるなど、GUI上でのデバッグも行えます。
詳しく知りたい方は、ぜひ以下の記事をご覧ください。
不揮発領域への保存
サンプルコードで使用している MemorySaver は、デバッグ用のインメモリCheckPointerです。本番環境での運用は、データを不揮発領域に保存する必要があります。
不揮発に保存するための選択肢として次のようなライブラリをLangChainが用意しています。
- langgraph-checkpoint-postgres:PostgreSQLをバックエンドに利用するライブラリ
- langgraph-checkpoint-sqlite:SQLiteをバックエンドに利用するライブラリ
これらのライブラリを使用する場合は、別途インストールが必要です。
独自のCheckPointerを実装する
ここでは、独自のCheckPointerを実装する方法を説明します。
CheckPointerに指定されるクラス(XXXSaver)は、ベースクラスである「BaseCheckpointSaver」を継承し、特定のインターフェースに従って実装されています。
以下がその一部です。
| メソッド | 説明 |
|---|---|
.put |
チェックポイントの設定とメタデータを保存します。 |
.put_writes |
チェックポイントに関連付けられた中間的な書き込み(保留中の書き込み)を保存します。 |
.get_tuple |
指定された設定(thread_idとcheckpoint_id)を使ってチェックポイントのタプルを取得します。これは、graph.get_state()でStateSnapshotを構築するために使用されます。 |
.list |
指定された設定およびフィルタ基準に一致するチェックポイントのリストを取得します。これは、graph.get_state_history()で状態の履歴を表示するために使用されます。 |
これらのインターフェースに従ってクラスを実装することで、独自の領域にデータを保存し、復元することが可能になります。
もう一つの重要なコンポーネントとして、CheckPointerのデータ保存形式を指定する「Serializer」があります。デフォルトでは、「JsonPlusSerializer」が使用されており、データはJSON形式に変換されます。JSON以外の形式に変更したい場合は、独自のSerializerを実装することで保存形式を切り替えることが可能です。
具体的なデータの読み書きの実装については、MemorySaverの実装を参照するのが最もわかりやすいので、こちらを参考にすることをお勧めします。
Store
次に、Storeの基本的な使い方について説明します。Storeはまだ新しい機能ということもあるのか、現時点ではかなりシンプルな機能となっています。
基本的な使い方
Storeを利用するには、グラフのコンパイル時に store パラメータにStoreのインスタンスを指定します。
CheckPointerの MemorySaver と同様に、テスト用のクラスとして、メモリ上にデータを保存する InMemoryStore が用意されています。
...
in_memory_store = InMemoryStore()
# グラフをコンパイルする際にstoreを指定
graph = builder.compile(store=in_memory_store)
...
データの保存
グラフのコンパイル時に store を指定すると、LangGraphのNode内で store というキーワード引数を通じてStoreのインスタンスを利用できます。
データを保存するには、BaseStoreのインスタンスに対して put メソッドを使用します。
# LangGraphのNode
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
# storeのnamespaceをタプルで作成
user_id = config['configurable']['user_id']
namespace = ('memories', user_id)
# ユニークなIDをmemoryのidとして指定する
memory_id = str(uuid.uuid4())
# 保存するデータ
data = {'data': memory}
# namespaceにユーザーの情報を保存する
store.put(namespace, memory_id, data)
...
データの取得
データを取得する際は、作成した namespace に対して search メソッドを使用します。このメソッドは、同じ namespace に保存されているデータの一覧を返します。
特定の1つのデータを取得したい場合は、保存時に指定したユニークな memory_id を指定して、get メソッドを使います。
# LangGraphのNode
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
# storeのnamespaceをタプルで作成
user_id = config['configurable']['user_id']
namespace = ('memories', user_id)
# searchメソッドを使うと、同じnamespaseに保存されているデータが全て取得できる
memories = store.search(namespace)
print('\n'.join([d.value['data'] for d in memories]))
# getメソッドを使うと、特定のmemory_idのデータを取得できる
print(store.get(namespace, <memory_id>))
namespace
データの保存や取得に使用される namespace はタプル形式で ('memories', <user_id>) のような連続したデータ構造になります。namespaceは、データをプレフィックスで検索することが可能です。
例えば、Storeに以下のようなnamespaceでデータが保存されているとします。
('user', 'data', 'profile')('user', 'data', 'settings')('user', 'activity')('system', 'info')
この場合、namespace を ('user', 'data') と指定すると、最初の2つのnamespaceが一致します。また、('user') と指定すれば、最初の3つのnamespaceが一致します。
独自のStoreの実装
CheckPointerと同様に、データを不揮発のStoreやインメモリ以外の保存領域に保存する場合は、InMemoryStore 以外のStoreを使用する必要があります。
現時点の公式のライブラリとしては Github上にはduckdbなどの実装がありますが、ライブラリとしてはまだ公開されていないようです。
独自で実装する場合は、BaseStore クラスを継承することで実現できます。Storeは非常にシンプルな構造で、実装に必要なメソッドは batch(または非同期用の abatch)のみです。
保存や検索の操作は、タプル形式のOperationが渡されるため、それぞれのインスタンスの種類を判定して処理を行います。具体的な実装例としては、InMemoryStoreの実装を参考にすると良いと思います。
InMemoryStoreのbatchメソッド
def batch(self, ops: Iterable[Op]) -> list[Result]:
results: list[Result] = []
for op in ops:
if isinstance(op, GetOp):
item = self._data[op.namespace].get(op.key)
results.append(item)
elif isinstance(op, SearchOp):
candidates = [
item
for namespace, items in self._data.items()
if (
namespace[: len(op.namespace_prefix)] == op.namespace_prefix
if len(namespace) >= len(op.namespace_prefix)
else False
)
for item in items.values()
]
if op.filter:
candidates = [
item
for item in candidates
if item.value.items() >= op.filter.items()
]
results.append(candidates[op.offset : op.offset + op.limit])
elif isinstance(op, PutOp):
if op.value is None:
self._data[op.namespace].pop(op.key, None)
elif op.key in self._data[op.namespace]:
self._data[op.namespace][op.key].value = op.value
self._data[op.namespace][op.key].updated_at = datetime.now(
timezone.utc
)
else:
self._data[op.namespace][op.key] = Item(
value=op.value,
key=op.key,
namespace=op.namespace,
created_at=datetime.now(timezone.utc),
updated_at=datetime.now(timezone.utc),
)
results.append(None)
elif isinstance(op, ListNamespacesOp):
results.append(self._handle_list_namespaces(op))
return results
公式ドキュメント
データの永続化については、公式にも多くの情報があるため、実装の際はこちらも参照ください。
おわりに
この記事では、LangGraphのデータ永続化機構であるCheckpointerとStoreについて、概要から基本的な実装方法など解説しました。
データの永続化は独自で実装することも可能ですが、これらの機能を活用することでLLMの会話状態やデータを効率的に管理できるようになります。特に複雑な会話を行うようなアプリケーションを開発する際は有効な機能だと思います。
この記事が、少しでも皆さんの参考になれば幸いです。公式ドキュメントも併せて参考にしていただき、ぜひ実際のプロジェクトで試してみてください。
PharmaXでは、AIやLLMに関連する技術の活用を積極的に進めています。もし、この記事が興味を引いた方や、LangGraphの活用に関心がある方は、ぜひ私のXアカウント(@hakoten)やコメントで気軽にお声がけください。PharmaXのエンジニアチームで一緒に働けることを楽しみにしています。
まずはカジュアルにお話できることを楽しみにしています!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion