はじめに
こんにちは。PharmaXでエンジニアをしている諸岡(@hakoten)です。
今回は、LangGraphの クラウドホスティング環境であるLangGraph Cloudについて紹介します。
LangGraph Cloudは現在ベータ版ですが、すでに多くの機能が利用可能です。弊社では、既にLangSmithを運用していることもあり、LangGraph Cloudの採用を視野に基本的な機能を試してみました。今回はその内容をシェアしたいと思います。
LangGraph Cloudに興味がある方の参考になれば幸いです。
LangGraph Cloudとは
LangGraphは、LangChainのツール群の一つで、LLMエージェントのステップをグラフ化し、状態管理を行うためのツールです。
そのLangGraphで作成したエージェントをクラウド環境で動作させるために、マネージドホスティング環境を提供するサービスが「LangGraph Cloud」です。
LangGraph自体の基本的な使い方をまずは知りたい方は、次の記事もぜひ御覧ください。
LangGraph Cloudの特徴
水平スケーリング
LangGraph Cloudの大きなメリットの一つは、フルマネージドな環境であり、水平スケーリングが可能である点です。これにより、需要に応じて自動的にシステムを拡張することができます。
LangSmithとの連携
LangGraph Cloudで実行されるグラフは、LangSmithによって自動的にトレースされ、実行ログが管理されます。(LangGraph Cloudを利用するためには、LangSmithのアカウントが必須です。)
LangGraph Studio 上での開発
LangGraph Cloudと密接に連携しているのが、統合開発環境であるLangGraph Studioです。

LangGraph Studioを使うと、LangGraph Cloudにデプロイされるエージェントの各ノードをデバッグしたり、Human-in-the-loop(エージェント処理の途中で人間の応答が必要な場面)のテストなどを簡単に行うことができます。
API、SDK、CLIツールなどの連携
LangGraph Cloudでは、API、SDK、およびCLIツールが提供されており、これらを使って外部からグラフを実行したり、ローカルサーバーを立ち上げて開発を進めたりすることができます。
LangGraph Cloudで実行するためのプロジェクト設定
ここでは、LangGraph Cloud上でエージェントを動作させるための設定について説明します。
LangGraph Cloudでエージェントを実行するためには、まずlanggraph.jsonという設定ファイルを作成する必要があります。
最小で動作する環境として、公式のサンプルプロジェクトが提供されているため、作業するときには一度このプロジェクトを参考にするのがよいと思います。
サンプルのプロジェクト: langgraph-example-pyproject
langgraph-example-pyprojectに含まれる langgraph.json の内容は次のようになっています。
{
"dependencies": ["./my_agent"],
"graphs": {
"agent": "./my_agent/agent.py:graph"
},
"env": ".env"
}
graphs フィールドには、コンパイルされたグラフのインスタンス(CompiledStateGraphインスタンス)を指定します
上記の例では、./my_agent/agent.py:graph という指定により、agent.py 内の graph という変数を実行するグラフとして認識しています。
実際のコードは以下の通りです。agent.pyではコンパイルされたグラフが graph 変数に格納されています。
...
workflow.add_edge("action", "agent")
# Finally, we compile it!
# This compiles it into a LangChain Runnable,
# meaning you can use it as you would any other runnable
graph = workflow.compile()
agent.py
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, END
from my_agent.utils.nodes import call_model, should_continue, tool_node
from my_agent.utils.state import AgentState
# Define the config
class GraphConfig(TypedDict):
model_name: Literal["anthropic", "openai"]
# Define a new graph
workflow = StateGraph(AgentState, config_schema=GraphConfig)
# Define the two nodes we will cycle between
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
# First, we define the start node. We use `agent`.
# This means these are the edges taken after the `agent` node is called.
"agent",
# Next, we pass in the function that will determine which node is called next.
should_continue,
# Finally we pass in a mapping.
# The keys are strings, and the values are other nodes.
# END is a special node marking that the graph should finish.
# What will happen is we will call `should_continue`, and then the output of that
# will be matched against the keys in this mapping.
# Based on which one it matches, that node will then be called.
{
# If `tools`, then we call the tool node.
"continue": "action",
# Otherwise we finish.
"end": END,
},
)
# We now add a normal edge from `tools` to `agent`.
# This means that after `tools` is called, `agent` node is called next.
workflow.add_edge("action", "agent")
# Finally, we compile it!
# This compiles it into a LangChain Runnable,
# meaning you can use it as you would any other runnable
graph = workflow.compile()
langgraph.jsonで指定できる、主な設定項目は以下の通りです。
| キー | 説明 |
|---|---|
| dependencies | 依存管理の設定。プロジェクトディレクトリ内の pyproject.toml、setup.py、requirements.txt の場所を指定します。※1 |
| graphs | グラフ(CompiledStateGraphインスタンス)の変数または関数を指定します。 |
| env | .envファイルへのパスを指定します。または環境変数を直接定義することもできます。 |
| python_version | Pythonのバージョンを指定します。3.11または3.12が使用可能で、デフォルトは3.11です。 |
| dockerfile_lines | カスタムDockerイメージを作成するためのコマンドを指定します。 ※2 |
※1 依存関係を直接パッケージで指定することも可能です。
※2 詳しくは How to customize Dockerfile を参照ください。
LangGraph Studio
LangGraph Cloud用のプロジェクトのグラフを可視化・デバッグするには、統合開発環境である「LangGraph Studio」が使用できます。ここでは、LangGraph Studioの基本的な使い方を紹介します。
環境
この記事の執筆時点では、以下のバージョンで実施しています。
LangGraph Studioは他のLangChainツールと同様に開発が非常に速いため、使用する際は最新バージョンの挙動も確認してください。
- langgraph-studio: 0.0.21
セットアップ
インストール
LangGraph StudioはGitHubページからダウンロードできます。
また、LangGraph Studioは内部でDockerを利用するため、Docker DesktopまたはOrbstackなどのDocker環境が必要です。
LangSmith ログイン

LangGraph Studioを使用するには、最初にLangSmithのアカウントでログインする必要があります。
プロジェクトディレクトリの選択

ログイン後、プロジェクトディレクトリを選択する画面が表示されます。
動作確認には、一度公式のlanggraph-example-pyprojectを使用することをお勧めします。このプロジェクトをローカルにダウンロードし、プロジェクトのトップディレクトリを選択することで、実行環境がセットアップされます。
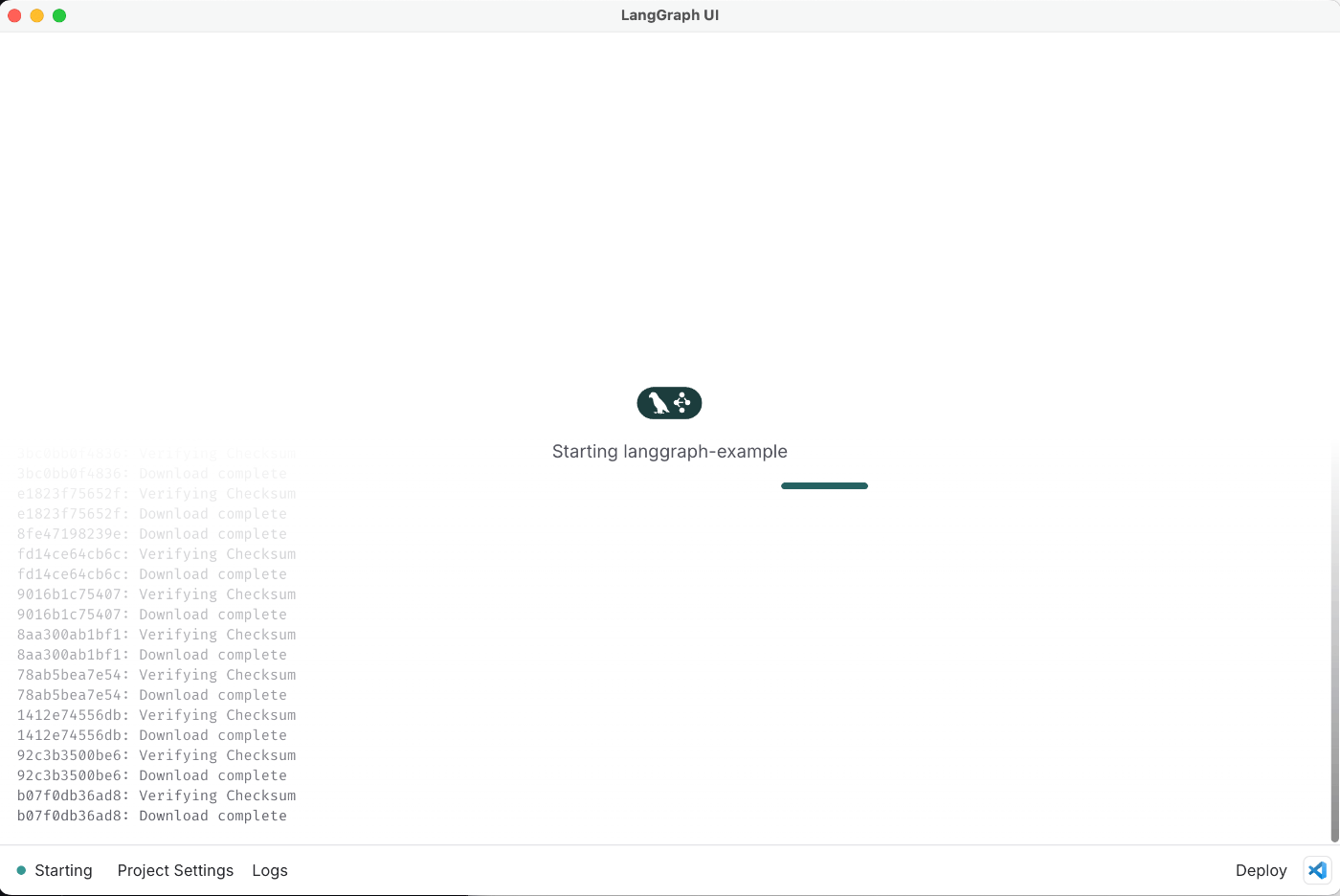
Docker Desktopを起動した状態で、ディレクトリを選択するとLangGraph Studioの実行環境が開始されます。
※ フォルダを選択する際にDockerコンテナが起動されるため、Docker Desktopが起動している必要があります。

正しく起動すると、上記のような画面が表示されます。
LangGraph Studioでできること
ここでは、langgraph-example-pyproject を動かして、LangGraph Studioでできることを紹介します。
このサンプルプロジェクトは、RAG(Retrieval-Augmented Generation)の検索エンジンであるtavilyを利用し、Web上で質問を検索し、LLMが回答を生成するというエージェントのチュートリアル的な構成になっています。
グラフの実行
LangGraph Studioでは、作成したグラフをGUI上で簡単に実行して試すことができます。画面左下の「Input」欄にグラフの実行パラメータを入力し、Submitボタンを押すことでグラフを実行できます。

また、画面左下の Configurable セクションから、OpenAIまたはAnthropicのどちらのLLMを使用するかを選択することが可能です。

各ステップの実行結果は、画面右側のThread領域に表示されます。

グラフを途中で中断する
LangGraph Studioを使うと実行中のグラフを途中で中断することができます。
例えば、LLMの実行結果の後に、tavilyのaction toolが動作する直前で確認したい場合、以下のようにInterruptを設定します。

この設定により、実行時に指定したステップで処理が中断されます。

Continueボタンが表示され処理が中断される
さらに、中断中にインプットを編集し、内容を変更することも可能です。変更後に「Fork」ボタンを押すと、別の実行を複製し、新しい条件で次のステップを実行できます。

別の内容で処理をForkする
LangSmith上で実行ログを確認する
LangGraph Studioで実行したグラフのログは、LangSmithに自動的に記録され、コンソール上でログを確認することができます。

LangSmithボタンを押下するとLangSmithのブラウザページが起動する
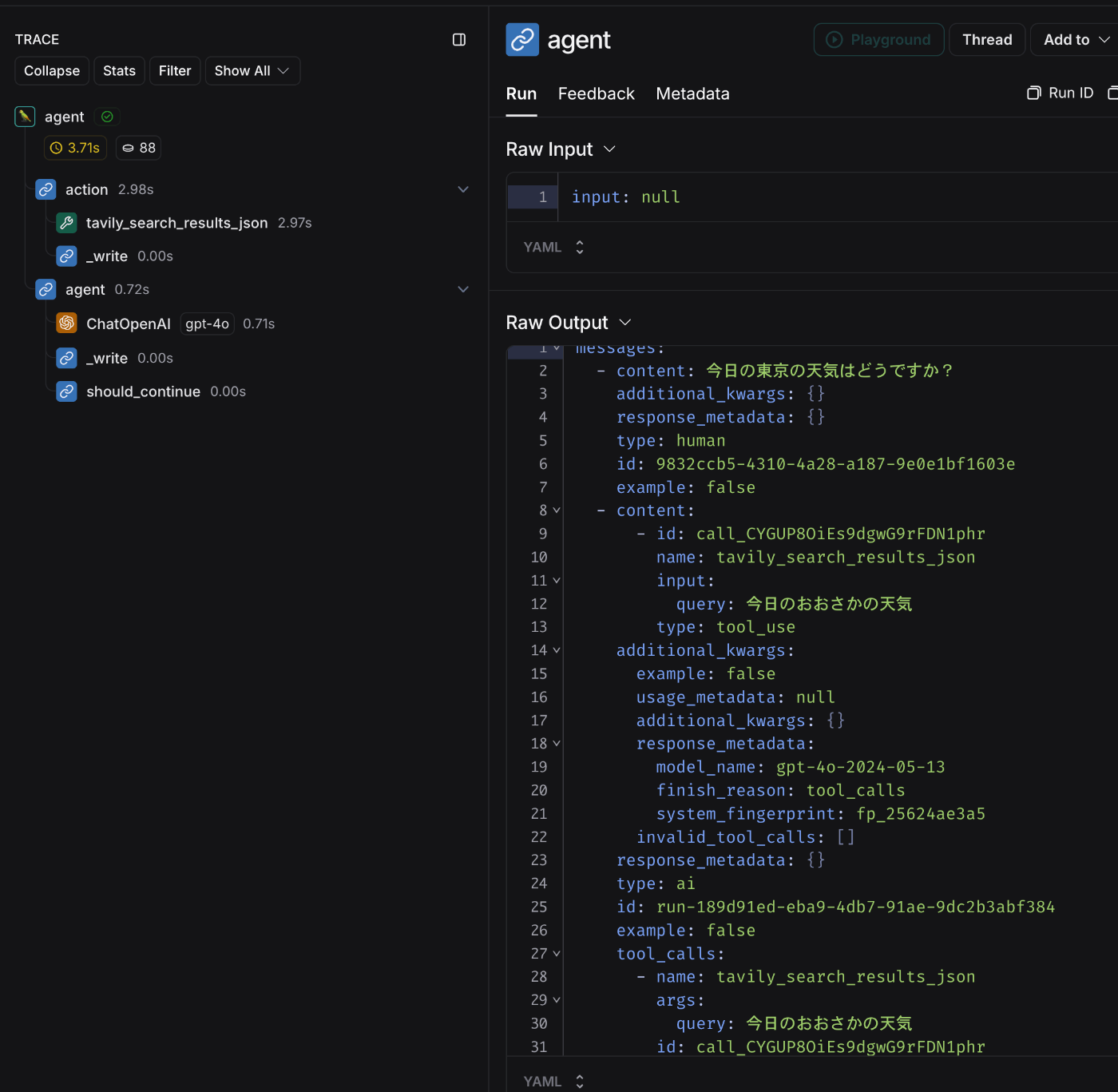
LangSmith上にRunが記録されている
API Keysを確認すると、LangGraph Studioにログインした際に、LangSmithのAPIキーが自動的に発行されていることがわかります。

LangSmith上に記録されるプロジェクト名は、何も設定しないと default になります。これは通常のLangSmithと同じ仕様で、LANGCHAIN_PROJECT 環境変数を設定することで、記録先のプロジェクトを変更することが可能です。
Threadの切り替え
LangSmithには「Thread」機能があり、一連のLLMの実行をまとめて管理することができます。
LangGraph Studio上でも、実行したThreadを切り替えて過去の実行を確認したり、同じ条件で再実行することが可能です。

過去のThreadを切り替えることができる
ローカルサーバー(LangGraph API Server)を立ち上げる
LangGraph Studioを使用せずに、ローカル環境でLangGraph Cloudのプロジェクトを動かす場合、「LangGraph API Server」を立ち上げることができます。
ここでは、ローカルでのサーバ起動について、紹介します。
CLIツールのインストール
ローカルサーバーを起動するには、まずLangGraph CLIツールをインストールする必要があります。
pip install langgraph-cli
サーバーの起動
CLIツールが正常にインストールされたら、langgraph up コマンドを実行してサーバーを起動します。
langgraph up
この際、LangSmithのAPIキーが必要です。.envファイルに LANGSMITH_API_KEY を設定してください。
サーバーが起動すると、次のようなメッセージが表示されます。
% langgraph up
Starting LangGraph API server...
For local dev, requires env var LANGSMITH_API_KEY with access to LangGraph Cloud closed beta.
For production use, requires a license key in env var LANGGRAPH_CLOUD_LICENSE_KEY.
Ready!
- API: http://localhost:8123
- Docs: http://localhost:8123/docs
- Debugger: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:8123
LangGraph SDKから グラフを実行する
ローカルで立ち上げたグラフ実行環境に対して、グラフを実行するには、LangGraph SDKのstreamコマンドを使用します。
次のサンプルコードでは、langgraph-example-pyproject をSDK経由で実行しています。
import asyncio
from langgraph_sdk import get_client
async def main() -> None:
client = get_client()
assistant_id = "agent"
thread = await client.threads.create()
print(thread)
input = {"messages": [{"role": "user", "content": "世界で一番人口が多い都市はどこですか?"}]}
async for chunk in client.runs.stream(
thread["thread_id"],
assistant_id,
input=input,
stream_mode="updates",
config={
"configurable": { "model_name": "openai" }
}
):
print(f"Receiving new event of type: {chunk.event}...")
print(chunk.data)
print("\n\n")
if __name__ == '__main__':
asyncio.run(main())
実行結果は次のようになります。
{'thread_id': 'ddb5a21d-9655-45d3-9ded-b41c8e3af4ed', 'created_at': '2024-09-15T07:30:22.344017+00:00', 'updated_at': '2024-09-15T07:30:22.344017+00:00', 'metadata': {}, 'status': 'idle', 'config': {}, 'values': None}
Receiving new event of type: metadata...
{'run_id': '1ef73345-e02e-6790-8f16-dab7902b005e'}
Receiving new event of type: updates...
{'agent': {'messages': [{'content': '', 'additional_kwargs': {'tool_calls': [{'index': 0, 'id': 'call_CPf8sCbZi34AdtwJWDs5KyAR', 'function': {'arguments': '{"query":"世界で一番人口 が多い都市 2023"}', 'name': 'tavily_search_results_json'}, 'type': 'function'}]}, 'response_metadata': {'finish_reason': 'tool_calls', 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_992d1ea92d'}, 'type': 'ai', 'name': None, 'id': 'run-d36132b4-b666-4466-8256-7720c1c95972', 'example': False, 'tool_calls': [{'name': 'tavily_search_results_json', 'args': {'query': '世界で一番人口が多い都市 2023'}, 'id': 'call_CPf8sCbZi34AdtwJWDs5KyAR', 'type': 'tool_call'}], 'invalid_tool_calls': [], 'usage_metadata': None}]}}
Receiving new event of type: updates...
{'action': {'messages': [{'content': '[{"url": "https://statja.com/world/EN_URB_LCTY/", "content": "最大都市圏人口の世界ランキング1960〜2023年【国別順位】 1960〜2023年の最大都市圏人口について、各国の世界ランキングを表形式にして、国別順位をまとめました。 2023年の1位は日本で37,194,105人、2位はインドで32,941,309人、3位は中華人民共和国で29,210,808人でした。"}]', 'additional_kwargs': {}, 'response_metadata': {}, 'type': 'tool', 'name': 'tavily_search_results_json', 'id': '8dae25b2-32de-4811-92e2-76e4aa394dec', 'tool_call_id': 'call_CPf8sCbZi34AdtwJWDs5KyAR', 'artifact': {'query': '世界で一番人口が多い都市 2023', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'title': '最大都市圏人口の世界ランキ ング1960〜2023年【国別順位】 | 統計リアル', 'url': 'https://statja.com/world/EN_URB_LCTY/', 'content': '最大都市圏人口の世界ランキング1960〜2023年【国別順位】 1960〜2023年の最大都市圏人口について、各国の世界ランキングを表形式にして、国別順位をまとめました。 2023年の1位は日本で37,194,105人、2位はインドで32,941,309人、3位は中華人民共和国で29,210,808人でした。', 'score': 0.9974983, 'raw_content': None}], 'response_time': 1.92}, 'status': 'success'}]}}
Receiving new event of type: updates...
{'agent': {'messages': [{'content': '2023年のデータによると、世界で一番人口が多い都市は日本の都市で、人口は37,194,105人です。', 'additional_kwargs': {}, 'response_metadata': {'finish_reason': 'stop', 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_25624ae3a5'}, 'type': 'ai', 'name': None, 'id': 'run-e948c343-3b02-4d6d-97de-32f03d00fb7d', 'example': False, 'tool_calls': [], 'invalid_tool_calls': [], 'usage_metadata': None}]}}
LangGraph Cloudのデプロイ設定
最後に、LangGraph Cloudを本番環境にデプロイする方法について紹介します。
LangGraph Cloudのデプロイは、LangSmithのコンソールから行います。右上にある「New Deployment」ボタンをクリックして、新しいデプロイを作成します。

現在のところ、デプロイするコードはGitHubと連携しており、アプリケーション名やデプロイするブランチを指定してSubmitすることでデプロイが可能です。

詳細については、公式ドキュメントを参照してください。
デプロイされたグラフを実行する
デプロイされた本番環境のグラフを実行する方法は、ローカルサーバーでの実行方法とほとんど同じです。
違いとしては、SDKのクライアント取得時に、get_client関数の引数にデプロイされたURLを設定する必要がある点です。
async def main() -> None:
client = get_client(url=<DEPLOYMENT_URL>)
・・・

LangSmithコンソールのAPI URL
上記のLangSmithのDeploymentコンソールに表示されている「API URL」を、このDEPLOYMENT_URLに設定してください。
本番環境で実行されたログは、LangSmithのコンソールから確認することができます。

感想
ひと通りLangGraph Cloudを試してみた感想としては、以下の通りです。
LangGraph Studioを使うことで、グラフを常に可視化しながらローカルで開発できる点は、特に複雑なグラフを扱うアプリケーションにおいて非常に有効だと感じました。また、複雑なグラフを使用するほどスケーラビリティの予測が難しくなるため、クラウド上でリソースを管理できることには大きなメリットがありそうです。
一方で、まだベータ版ということもあり、デプロイ数やリクエスト数に制限があるようなので、通常の規模のアプリケーションでは問題ないと思いますが、高負荷トラフィックを処理するようなアプリケーションでは慎重な検討が必要かもしれません。
弊社のLangGraphアプリケーションについては、LangGraph Studioでの起動を試みましたが、起動時のエラーが解決できていないため、まだ実際には試せていません。このあたりの実装コスト次第では、安定版がリリースされた際に移行を検討する可能性がありますが、現時点では、Google Cloud上でLangGraphを運用する方法に特に大きな問題はないため、今すぐ移行する予定はないかと思います。
おわりに
以上、LangGraph Cloudの基本的な使い方の紹介でした。
LangGraph StudioとLangSmithとの連携によって、デバッグやリソース管理がシンプルになるため今後の安定化を期待しています!
PharmaXでは、AIやLLM関連の開発に興味を持つエンジニアを募集しています。さまざまなバックグラウンドを持つ方を歓迎していますので、ぜひ気軽にお声がけください。
興味がある方は、私のXアカウント(@hakoten)や記事のコメントから、ぜひカジュアルにお話ししましょう!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion