AWSでの効率的なデータ処理を考える~データコンパクション~
はじめに
前回の記事AWSでの効率的なデータ処理を考える~AWS LambdaとSQSを活用した並列データパイプライン~で大きなファイルをLambdaでチャンク分割し、SQSで並列処理するパターンを紹介しました。
本記事ではこれとは逆に、IoTデバイスやアプリケーションログなど小さなイベントファイルが連続的に生成・アップロードされるユースケースを想定したCompactorパターンを検討します。
データレイクにおける小ファイル問題とは
データレイクを構築する際、IoTデバイスやアプリケーションログなど小さなファイルが大量に登録されるユースケースがあると思います。
こういった場合、稼働年数が長くなると以下のようなパフォーマンスに影響する問題が発生する場合があります。
- 小さなファイルがS3に大量に蓄積し、テーブルストレージやメタデータ管理に負荷がかかる
- 多数の小さなファイルをAthena/Glueでスキャンするとパフォーマンスが低下する
- Iceberg/Deltaの頻繁なスナップショット更新によるコスト・競合増加
ちなみに前の記事でバックオフ処理を実装しましたが、競合が多発して調整に苦労しました…(あの実装も課題が多いので見直しも必要かなと…)
Compactorパターンとは
Compactorパターンとはデータレイクに蓄積された多数の小さなファイルを定期的にマージ(結合・圧縮)して大きなファイルにまとめる処理パターンのことです。
小さなファイルをマージして大きなファイルとすることで、クエリパフォーマンス等の負荷を下げるためのアプローチとなります。
典型的な処理の流れ
-
スケジューリングまたはトリガー実行
定期的に(例:1時間ごと、1日ごと)または一定数の小さなファイルが溜まったときに実行。 -
小さなファイルの検出
S3またはIceberg/Deltaのマニフェストをスキャンし、小さなファイルを特定。 -
マージ処理(Compact)
AWS Glueなどを使ってファイルをまとめ、大きなParquetファイル等に再書き込み。 -
不要ファイルの削除
古い小さなファイルや不要なスナップショットを削除(ガーベジコレクション)。
Compactorパターン実装方法
Compact処理には実施するタイミングで大きく2つのパターンがあります。
データレイクに書き込む「前」にCompactするパターン(Pre-Compaction)

こちらは「前」で処理するパターンです。
ストリーミングやバッチ処理で発生する小さなファイルを一時ストレージやキューに保持し、一定のバッファが溜まったらCompactしてからレイクに書き込むパターンとなります。
つまり、「入口で整える」イメージです。
こちらのパターンは下記のメリデメがあります。
メリット
- 最初から最適化されたファイル構造でレイクに格納できます。
- レイク上のクエリ負荷・スナップショット競合が少なくなります。
- Iceberg/Deltaテーブルの管理がシンプルになります。
デメリット
- レイテンシが増える可能性があります。(バッファ時間が必要)
- リアルタイム性が損なわれる可能性があります。
- Compact前に処理が失敗するとデータロスリスクがあります。(リトライ設計が重要)
データレイクに書き込んだ書き込んだ「後」にCompactするパターン(Post-Compaction)
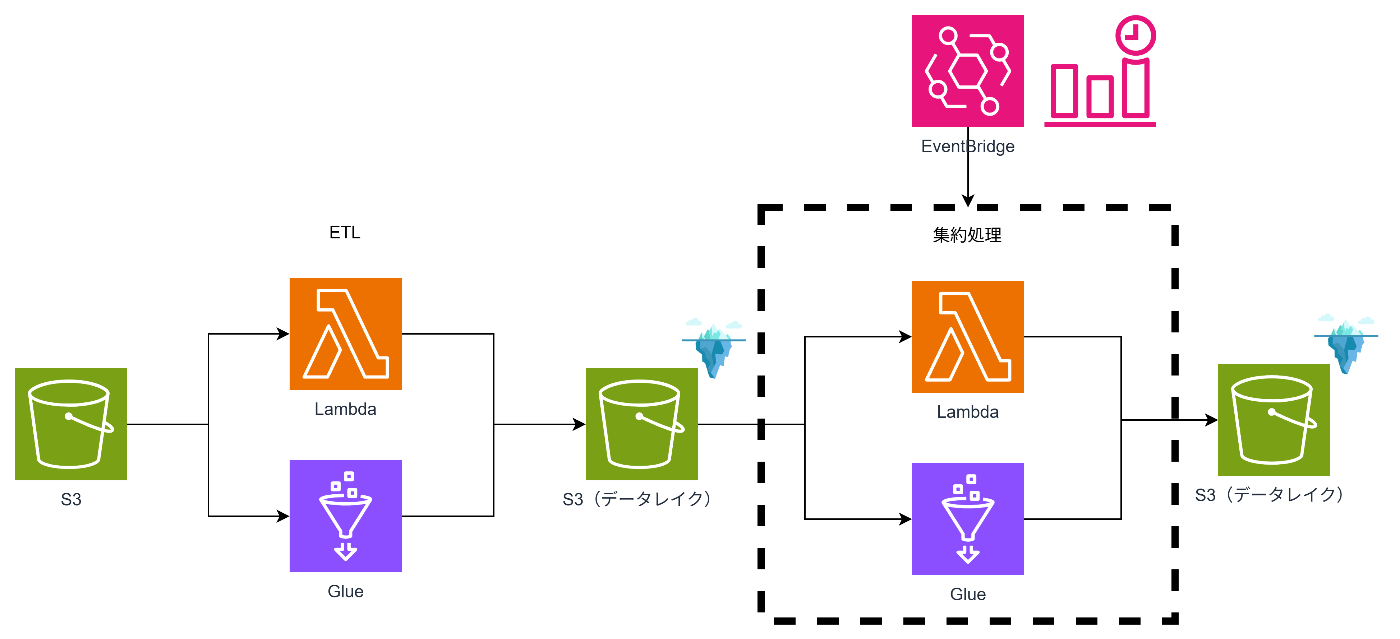
こちらは「後」で処理するパターンです。
ストリーミングやバッチ処理で発生する小さなファイルをそのままIceberg/Deltaに書き込み、後から別ジョブでCompactを定期実行するパターンとなります。
つまり、「出口で整える」イメージです。
こちらのパターンは下記のメリデメがあります。
メリット
- 書き込みのレイテンシが最小限となります。
- ストリーミングなどのリアルタイム処理と相性が良いです。
- 書き込み失敗リスクを減らせます。(小分けで書くので)
デメリット
- レイクに小さなファイルが一時的に増え、パフォーマンスが劣化する可能性があります。
- Iceberg/Deltaでスナップショットやトランザクションの競合リスクがあります。
データレイクに書き込む「前」にCompactするパターン(Pre-Compaction)を実装する
まずはPre-Compactionを実装します。
アーキテクチャ
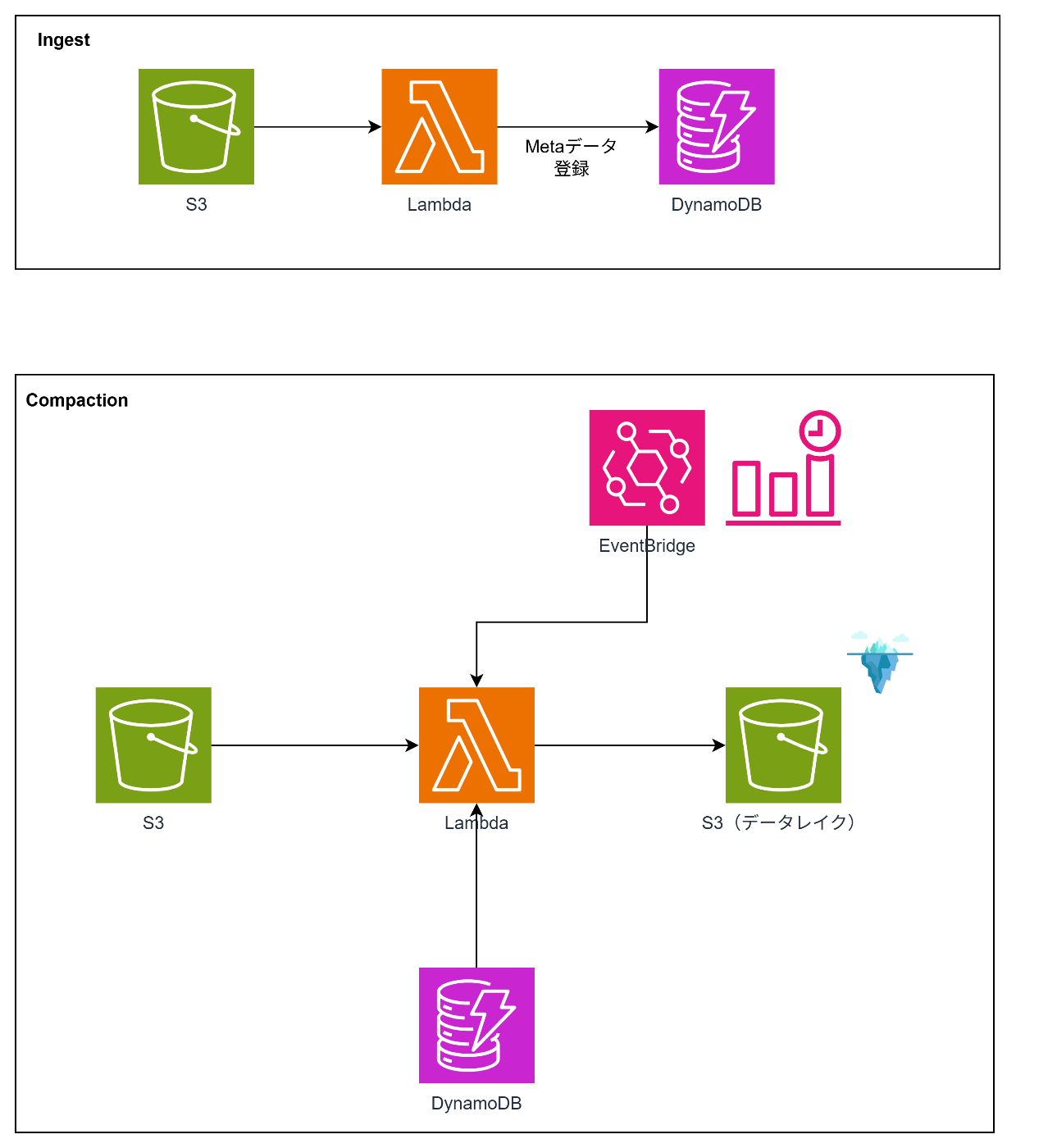
このパターンはIngestとCompactionの2つの処理から構成されます。
-
Ingest(ファイル登録)
- IoTデバイスやサービスから送信された小さなファイルをS3にアップロード
- LambdaでS3イベントをトリガーし、DynamoDBに各ファイルのURI・サイズなどをPENDINGステータスで登録
-
Compaction(圧縮・統合)
- 一定数または合計サイズがしきい値を超えたタイミングでCompactor Lambdaを起動
- 蓄積された小さなファイルをまとめてマージし、大きなParquetファイルに変換してS3/Icebergに書き出し
サンプルコード
- Ingest(ファイル登録)
import os
import json
import uuid
import boto3
from urllib.parse import unquote_plus
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(os.environ['CHUNK_TABLE'])
# S3 イベント受信 → メタデータ登録のみ
def lambda_handler(event, context):
for rec in event['Records']:
bucket = rec['s3']['bucket']['name']
key = unquote_plus(rec['s3']['object']['key'])
size = rec['s3']['object']['size']
uri = f's3://{bucket}/{key}'
table.put_item(
Item={
'ChunkId': str(uuid.uuid4()),
'Uri': uri,
'SizeBytes': size,
'Status': 'PENDING',
'Timestamp': int(context.aws_request_id[:8], 16)
}
)
return {'statusCode': 200, 'body': json.dumps({'message': 'Registered'})}
- Compaction(圧縮・統合)
import os
import boto3
import duckdb
import time
from datetime import datetime
from pyiceberg.catalog.glue import GlueCatalog
# 環境変数
TABLE_NAME = os.environ['CHUNK_TABLE']
TARGET_TOTAL_SIZE = int(os.environ.get('TARGET_TOTAL_SIZE', 100 * 1024 * 1024)) # 100MB デフォルト
ICEBERG_CATALOG_NAME = os.environ.get('ICEBERG_CATALOG_NAME', 'my_catalog')
ICEBERG_NAMESPACE = os.environ.get('ICEBERG_NAMESPACE', 'icebergdb')
ICEBERG_TABLE_NAME = os.environ.get('ICEBERG_TABLE_NAME', 'yellow_tripdata')
# AWS クライアント
dynamodb = boto3.resource('dynamodb')
s3 = boto3.client('s3')
def lambda_handler(event, context):
items = get_pending_items()
selected_items = []
accumulated_size = 0
for item in items:
item_size = item['SizeBytes']
if accumulated_size + item_size > TARGET_TOTAL_SIZE:
break
selected_items.append(item)
accumulated_size += item_size
if not selected_items:
return {'message': 'しきい値未満のため処理をスキップ', 'count': 0, 'size': 0}
uris = [item['Uri'] for item in selected_items]
print(f"マージ処理実行 {uris}")
arrow_table = merge_parquet_in_memory(uris)
print(f"arrow_table {arrow_table}")
append_to_iceberg(arrow_table)
mark_done([item['ChunkId'] for item in selected_items])
return {'message': 'Compaction 完了', 'merged_rows': arrow_table.num_rows}
def get_pending_items():
table = dynamodb.Table(TABLE_NAME)
resp = table.scan(
FilterExpression="#st = :pending",
ExpressionAttributeNames={'#st': 'Status'},
ExpressionAttributeValues={':pending': 'PENDING'}
)
return resp.get('Items', [])
def merge_parquet_in_memory(uris):
con = duckdb.connect(database=':memory:')
con.execute("SET home_directory='/tmp'")
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
# Parquet ファイルを読み込み、結合
df = con.read_parquet(uris, union_by_name=True).arrow()
return df
def append_to_iceberg(arrow_table, retries=5):
catalog = GlueCatalog(region_name="ap-northeast-1", name=ICEBERG_CATALOG_NAME)
delay = 10
for attempt in range(retries):
try:
table = catalog.load_table(f"{ICEBERG_NAMESPACE}.{ICEBERG_TABLE_NAME}")
table.refresh()
current_snapshot = table.current_snapshot()
snapshot_id = current_snapshot.snapshot_id if current_snapshot else "None"
print(f"Attempt {attempt + 1}: Using snapshot ID {snapshot_id}")
table.append(arrow_table)
print("データが Iceberg テーブルに追加されました。")
return
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if "Cannot commit" in str(e) or "branch main has changed" in str(e):
if attempt < retries - 1:
delay *= 2
print(f"{delay} 秒後にリトライします。")
time.sleep(delay)
else:
print("最大リトライ回数に達しました。処理を中断します。")
raise
else:
raise
def mark_done(ids):
table = dynamodb.Table(TABLE_NAME)
for cid in ids:
table.update_item(
Key={'ChunkId': cid},
UpdateExpression="SET #st = :c",
ExpressionAttributeNames={'#st': 'Status'},
ExpressionAttributeValues={':c': 'COMPACTED'}
)
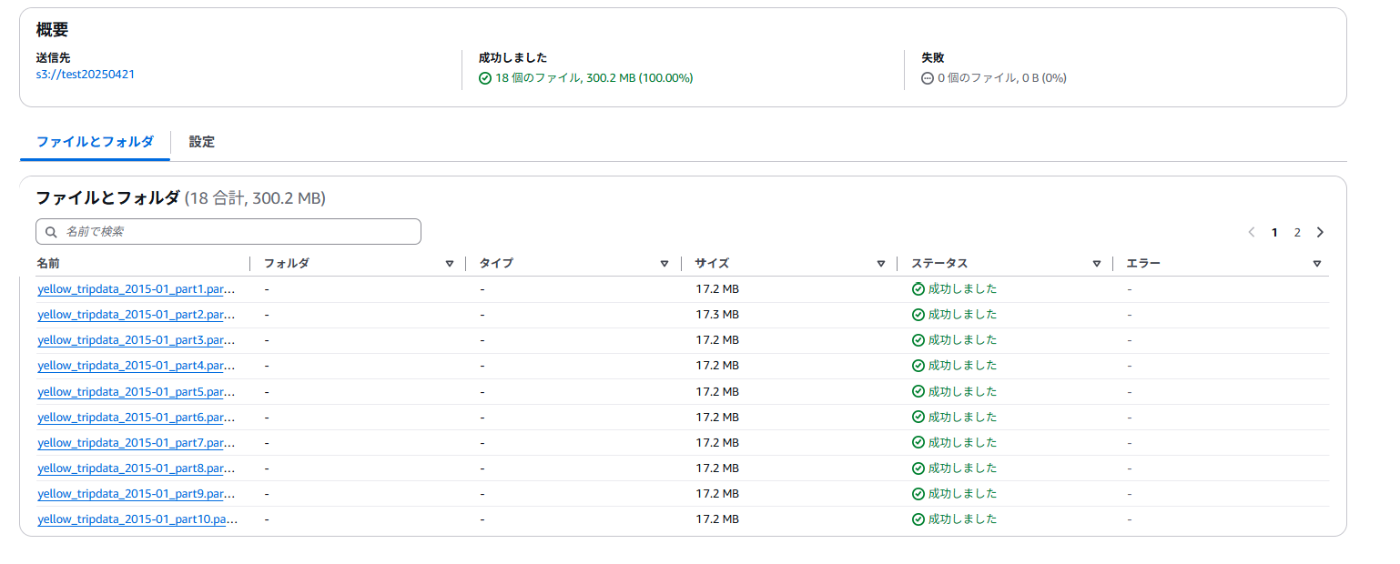
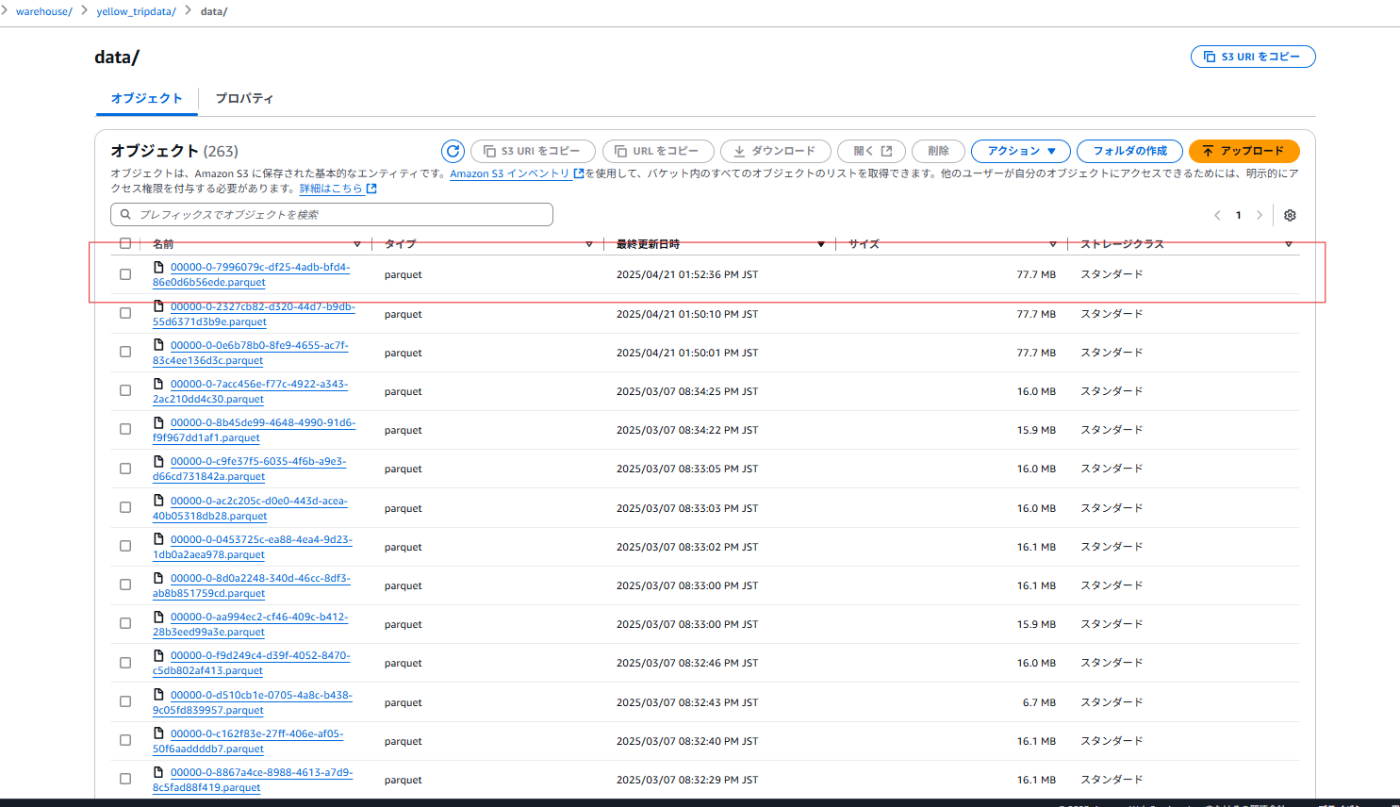
実行結果
アップロードファイル
登録済みデータ
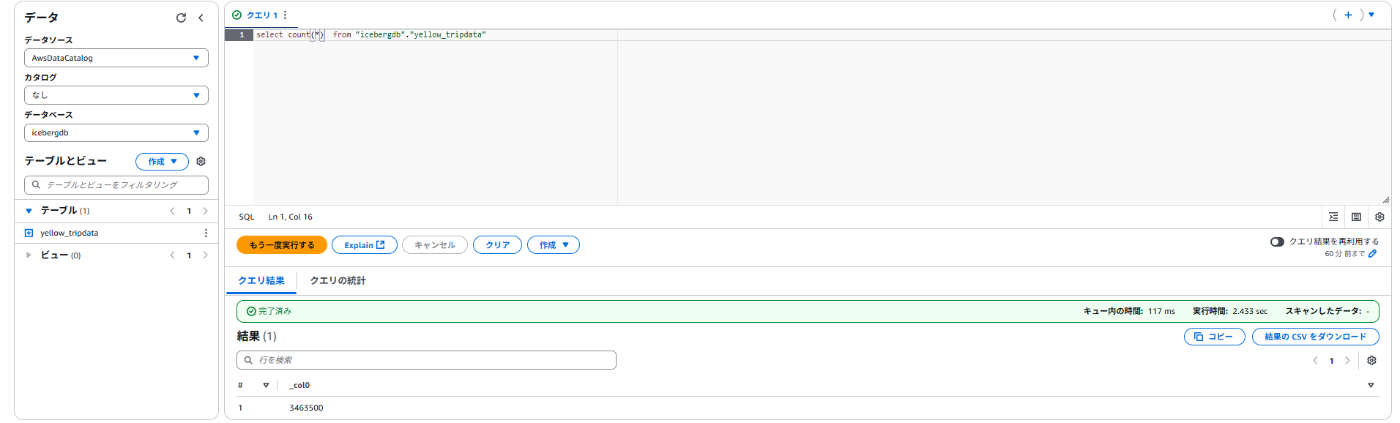
Iceberg上のファイル
検討が必要なポイント
-
バックオフ間隔の調整:
Icebergテーブルのバージョン更新や競合によるエラー対応のための間隔をちょっと長めにしているのでここは要調整かなと。(リトライ回数の上限と時間は環境変数に持つのがいいかなと思います。)
今回のコードはあくまでもサンプルなので要件やIcebergの仕様を確認した上で、設計いただくのが良いかと思います。 -
サイズの制御:
Icebergテーブルのファイルサイズは一般的には、128MB ~ 1GBの範囲が最適とされています。
サイズに関しても調整をしたうえで制御していただければと思います。 -
EventBridgeのトリガ間隔:
こちらもファイルのアップロードの間隔やファイルサイズに応じて調整が必要となります。
トリガ間隔が大きすぎるとリアルタイム性が損なわれてしまいますし、短すぎると空振りの頻度が大きくなる可能性があります。また、重複マージが行われる可能性もありますのでここはしっかりと見極めていただければと思います。
データレイクに書き込んだ「後」にCompactするパターン(Post-Compaction)を実装する
次にPost-Compactionを実装します。
こちらは非常にシンプルな構成です。
アーキテクチャ

ポイントは下記のAWSのガイドの通り、Athena経由でOPTIMIZEとVACUUMを実行するものとなります。
サンプルコード
import boto3
athena = boto3.client('athena', region_name='ap-northeast-1')
TEMP_OUTPUT = 's3://20250421testresult/'
def lambda_handler(event, context):
queries = [
"OPTIMIZE icebergdb.yellow_tripdata REWRITE DATA USING BIN_PACK",
"VACUUM icebergdb.yellow_tripdata"
]
for query in queries:
response = athena.start_query_execution(
QueryString=query,
QueryExecutionContext={'Database': 'icebergdb'},
ResultConfiguration={'OutputLocation': TEMP_OUTPUT}
)
print(f"Started Athena query: {response['QueryExecutionId']}")
実行結果
実行前


実行後
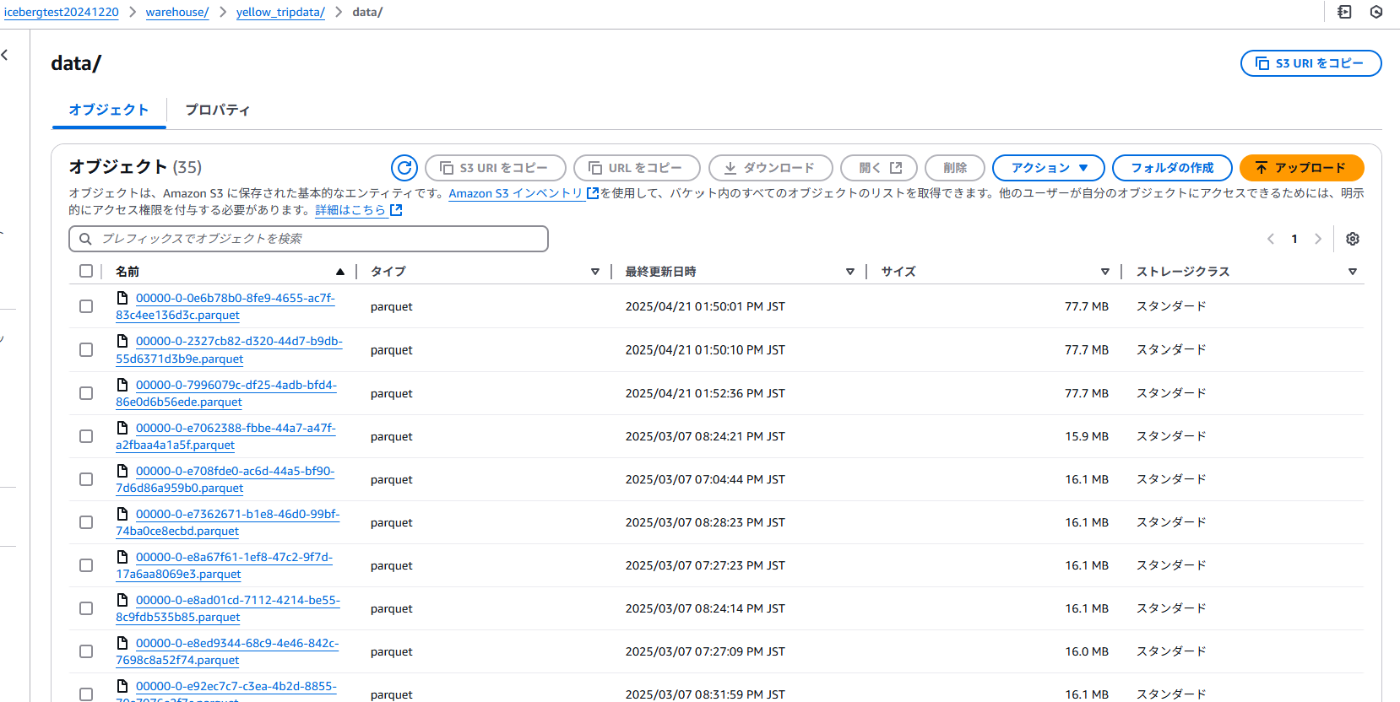

このように最適化されていることを確認しました。
検討が必要なポイント
-
EventBridgeのトリガ間隔:
このコンパクション処理は大規模なテーブルでは計算負荷が高くなることが考えられます。
テーブルのサイズや更新頻度にもよりますが、1日1回など頻度を抑えることが推奨されます。
また、データパイプラインの中に入れるのか、外に配置するのかも検討すべきポイントとなります。
データレイクに書き込んだ「後」にCompactするパターン(Post-Compaction)を実装する(AWS Glueの自動コンパクション)
前述のPost-CompactionではLambdaから処理を実行しました。
実はこのApache IcebergはAWS Glueデータカタログにて自動コンパクションが可能となります!
AWS GlueのTable Optimizerを使用すると、Apache Icebergテーブルのコンパクション、スナップショットの保持、孤立ファイルの削除などの最適化を自動化できます。
これにより、ストレージの効率化やクエリパフォーマンスの向上が期待できます!
とても便利な機能ですね。
自動でテーブルの状態を確認して実行されるようです。
自動コンパクションの設定

コンパクション、スナップショットの保持、孤立ファイルの削除のすべてにチェックを入れる
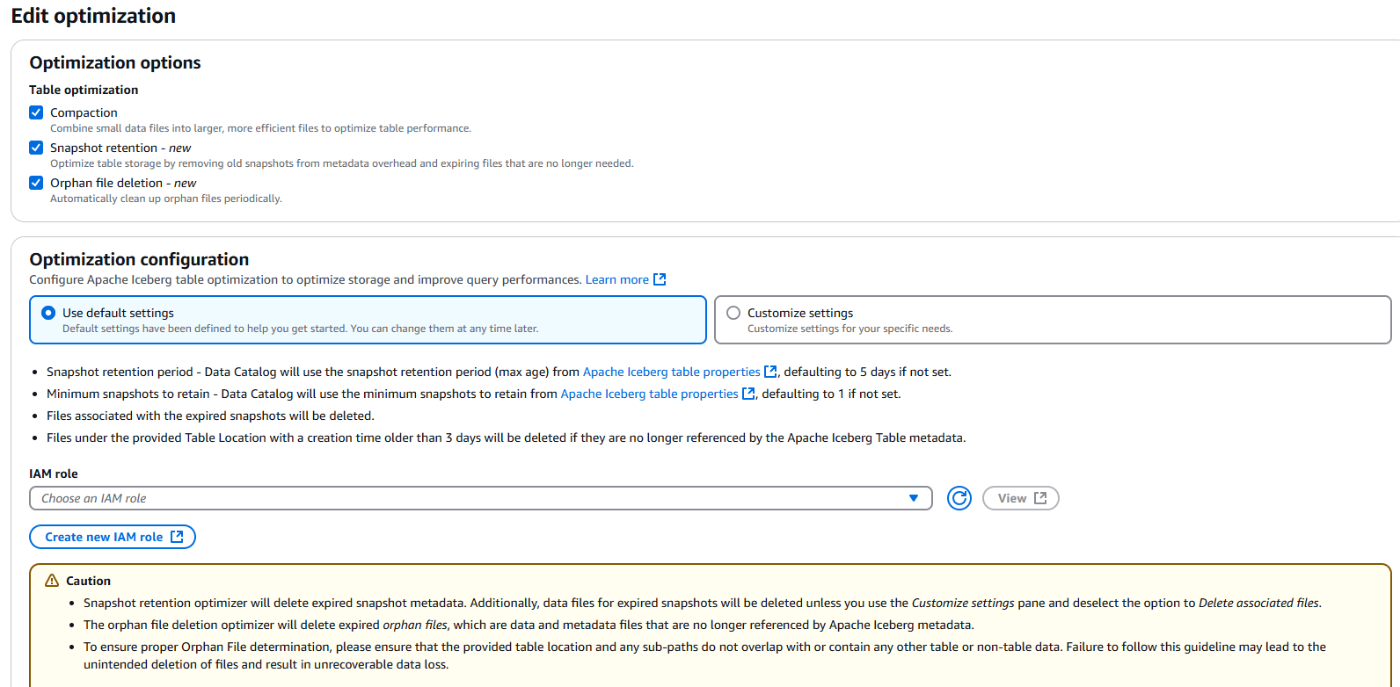
運用上の注意点
- DPU単位で課金されるため、テーブルの断片化やデータが多いとコストが増えます。
- 機能を使用可能なリージョンが限られているため注意が必要です。
それぞれのユースケース
本セクションでは、ユースケース別にそれぞれのアプローチが適切なシナリオを示し、メリット・デメリットを整理します。
Lambdaベースのコンパクション(Pre-Compaction)
ユースケース
- Delta Lakeなど、Glue自動コンパクションを使えない場合
- 高度なビジネス要件に応じたコンパクションロジックを実装したいとき
- Lambda/Step Functions など既存サーバーレス基盤を活用して柔軟に構成したい場合
メリット
-
柔軟なロジック実装:
ファイル選択基準やマージ手順を自由にカスタマイズ可能です。 -
マルチフォーマット対応:
Iceberg以外にもDelta Lakeなどに対応可能です。 -
コスト制御:
必要なときだけLambdaを起動し、DPU課金を回避可能です。
デメリット
-
実装・運用コストが高い
Lambda/DynamoDB/EventBridge等の構築・管理が必要となります。 -
モニタリング要素増加:
独自メトリクス設定や障害検知ロジックを実装・維持が必要となります。 -
スケーラビリティ検証:
大量データ時のパフォーマンスボトルネックに留意する必要があります。
Lambdaベースのコンパクション(Post-Compaction)
ユースケース
- Delta Lakeなど、Glue自動コンパクションを使えない場合
- 運用負荷を抑えつつ、定期的なファイル統合を自動化したいとき
メリット
-
実装工数が少ない:
LambdaからAthena経由でクエリを実行するだけなので実装が容易です。
デメリット
-
スケーラビリティ検証
大量データ時のパフォーマンスボトルネックに留意する必要があります。
AWS Glue 自動コンパクション(Post-Compaction)
ユースケース
- Apache IcebergテーブルをGlueカタログで一元管理している場合
- 運用負荷を抑えつつ、定期的なファイル統合を自動化したいとき
- カスタムロジック不要で標準機能に任せたい中~大規模データレイク
メリット
-
実装工数が少ない:
GlueコンソールやCLIから有効化するだけで利用可能です。 -
管理運用が簡易:
CloudWatchメトリクスやGlueコンソールで状況を把握できます。 -
ネイティブサポート:
コンパクション、スナップショットの保持、孤立ファイルの削除も対応可能です。
デメリット
-
Glue DPU課金:
1分単位でのDPU課金が発生し、頻度次第でコスト増となります。 -
制約がある:
こちらの自動処理はIcebergに限定されます。 -
トリガー柔軟性:
細かな条件判定や動的トリガーには別途設計が必要です。
まとめ
今回はデータレイクを運用する上で考慮が必要となるデータのコンパクションについて解説しました。
データレイクという形式上、様々なサイズのファイルが様々なタイミングで格納されます。
小さなファイルが大量にある状態だと、処理の効率が悪化してしまうことが懸念されます。
そこで、今回紹介したようなコンパクションを行うことで、効率的な処理が可能な状態を維持することが可能となります。
対応方法もいくつか種類がありますので、要件やシステムの現状に合わせて、構成を検討いただければと思います。
今回の記事が最適なアーキテクチャ設計の参考になれば幸いです。
Discussion