AWSでの効率的なデータ処理を考える~AWS LambdaとSQSを活用した並列データパイプライン~
はじめに
以前の記事でAWS Lambdaを活用したETL処理を紹介しました。
今回もAWS Lambdaを活用したデータ処理に関する記事となります。
みなさんもご存じかと思いますが、データ処理においては大規模データセットを効率よく扱うことは非常に大きなポイントとなります。
今回採用するサービスであるAWS Lambdaで大規模データセットを扱う場合、メモリと処理時間の上限が大きな課題となることが多いです。
大規模データを取り込むだけでも大きな負荷がかかり、さらに処理を加えるとなるとこの制限に抵触する可能性が非常に高くなります。
今回は、この課題に対する対応として、AWS LambdaとSQSを活用し、大きなファイルをチャンクに分割して並列処理するデータパイプラインを構築する方法を紹介します。
今回のアーキテクチャ
今回のアーキテクチャは以下です。
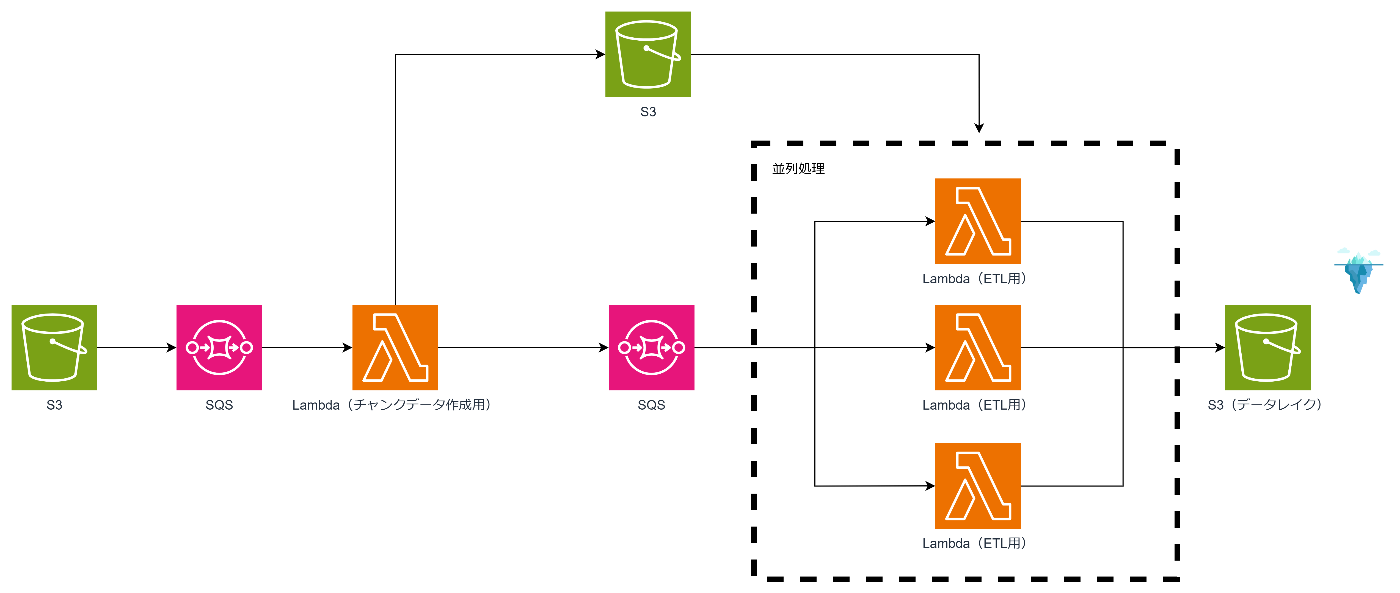
処理の流れは以下です。
- S3のファイルアップロードをトリガにSQSにイベント通知。
- SQSの通知を受けてファイル分割用のLambdaが起動。Lambdaで適切なファイルサイズに分割しS3に格保存。
- 保存後、分割された各ファイルの情報が別のSQSに送信されます。
- SQSの通知を受けた別のLambda関数が起動し、各ファイルに対してETL(抽出、変換、ロード)処理を実行し、最終的にデータレイク(Iceberg)に格納します。
Lambdaで使用する各種ライブラリは下記となります。
- DuckDB:データベースエンジンとして、メモリ内での高速なSQLクエリ処理を実現。
- PyArrow:Arrowフォーマットを使用し、高速なデータの変換・転送をサポート。
- PyIceberg:AWS Glue Catalogを活用して、Iceberg形式のテーブルにアクセス・操作。
このアーキテクチャのメリット
この方式には以下のメリットがあります。
-
並列実行によるスケーラビリティの向上
SQSを介することで、Lambdaで大規模ファイルを分割して並列処理が可能となります。
また、Lambda内での処理が重いほど並列処理が効果的になります。 -
Lambdaのメモリ制限と処理時間の制限を回避しつつ、大規模データを効率的に処理できる
チャンクに分けて処理することでメモリ制約と処理時間の制限に対応可能となります。
ここで以前紹介したDuckDBを活用することでより効率的な処理が可能となります。 -
リトライ処理の活用が可能
SQSを活用する大きなメリットとしてリトライ処理が使えるというものがあります。
特に今回のようなファイルをチャンクに分けて処理する場合、エラーの発生で一部のデータが欠損するということも考えられます。
そういった場合のためにもリトライ処理は非常に重要となります。
考慮が必要なポイント
-
並列処理とデータの順序保証
SQSではFIFOキューがありますが、並列処理後のLambdaでの処理があるため、テーブルへのデータ登録順序は保証されません。
この辺りはフロー処理が可能なStep Functions等の他のサービスを検討する必要があります。 -
エラーハンドリングとリトライ
本記事では触れませんが、SQSのデッドレターキュー(DLQ)を設定することをおすすめします。
DLQを活用することでより厳密なエラー対応が可能となります。
また、可視性タイムアウトを適切に設定することでデータが重複することを防ぐことができます。
テストデータ
今回はKaggleのNYC Yellow Taxi Trip Dataを使ってみます。
ちなみにこれはcsv形式となっているためparquet形式に変換する処理も追加します。
データ変換については下記の記事でまとめているので参考にどうぞ。
parquet形式に変換することでファイルサイズの圧縮と後続プロセスでの処理効率化を図ります。
Lambdaへの組み込み
前回のものを流用し、Lambdaへの組み込みはLambdaレイヤーを使いました。
下記のコマンドでレイヤー用のライブラリをダウンロードし、zipで固めていただければOKです。
mkdir python
pip install -t python --platform manylinux2014_x86_64 --only-binary=:all: pyiceberg[glue,duckdb]
オプションにglue,duckdbを付加することで同時にglue用の拡張と、DuckDB及びPyArrowがインストールされます。
ちなみにこのままだとLambdaレイヤーの250MBを超過してしまうため、boto3を削除しました。
素直にコンテナイメージ化したほうがいいのかなと思います。
サンプルコード
チャンクデータ作成用
import duckdb
import pyarrow.parquet as pq
import boto3
import json
import os
import pyarrow as pa
s3_client = boto3.client("s3")
sqs_client = boto3.client("sqs")
S3_BUCKET_NAME = "任意のバケット"
SQS_QUEUE_URL = "任意の送信用SQS"
def lambda_handler(event, context):
try:
print(f"event: {event}")
# SQSメッセージからS3イベント情報を取得
event_body = json.loads(event['Records'][0]['body'])
s3_bucket = event_body['Records'][0]['s3']['bucket']['name']
s3_object_key = event_body['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_object_key}"
print(f"Processing file: {s3_input_path}")
# 拡張子を除いたベースファイル名を作成
base_filename = s3_object_key.rsplit(".", 1)[0]
# DuckDBのインメモリーデータベースに接続
duckdb_connection = duckdb.connect(database=":memory:")
duckdb_connection.execute("SET home_directory='/tmp'") # Lambdaの一時ディレクトリに設定
# httpfs拡張モジュールのインストールとロード
duckdb_connection.execute("INSTALL httpfs;")
duckdb_connection.execute("LOAD httpfs;")
# CSVファイルを読み込む(read_csv_autoを使用)
query = f"SELECT * FROM read_csv_auto('{s3_input_path}')"
arrow_table = duckdb_connection.execute(query).fetch_arrow_table()
# 取得したテーブルのカラム名をすべて小文字に変換
new_column_names = [name.lower() for name in arrow_table.column_names]
arrow_table = arrow_table.rename_columns(new_column_names)
print(f"変換後のデータスキーマ: {arrow_table.schema}")
# チャンクサイズ取得(デフォルト: 100MB)
chunk_size_mb = int(os.environ.get("CHUNK_SIZE_MB", 100))
chunk_size_bytes = chunk_size_mb * 1024 * 1024
# 総データサイズと行数を取得
total_bytes = arrow_table.nbytes
total_rows = arrow_table.num_rows
# 1チャンクの行数を計算(最低1行以上)
chunk_rows = max(1, total_rows * chunk_size_bytes // total_bytes)
# 一定の行数ごとにチャンクを作成してS3に保存、SQSに通知
for i in range(0, total_rows, chunk_rows):
chunk = arrow_table.slice(i, chunk_rows)
output_file = f"/tmp/{base_filename}_part{i // chunk_rows}.parquet"
pq.write_table(chunk, output_file)
print(f"Saved chunk: {output_file}")
s3_chunk_key = f"chunks/{base_filename}_part{i // chunk_rows}.parquet"
s3_client.upload_file(output_file, S3_BUCKET_NAME, s3_chunk_key)
message_body = json.dumps({
"s3_bucket": S3_BUCKET_NAME,
"s3_object_key": s3_chunk_key
})
sqs_client.send_message(QueueUrl=SQS_QUEUE_URL, MessageBody=message_body)
print(f"Chunk saved to S3 and message sent to SQS: {s3_chunk_key}")
except Exception as e:
print(f"Error processing file: {e}")
ETL用
import duckdb
import pyarrow as pa
import boto3
import json
import time
from pyiceberg.catalog.glue import GlueCatalog # GlueCatalogを使ってIcebergテーブルにアクセス
def lambda_handler(event, context):
try:
# 1. SQSメッセージの受信
message_body = json.loads(event['Records'][0]['body']) # 1つのメッセージを処理
s3_bucket = message_body['s3_bucket']
s3_object_key = message_body['s3_object_key']
s3_input_path = f"s3://{s3_bucket}/{s3_object_key}"
print(f"Processing file from SQS message: {s3_input_path}")
# 2. DuckDB接続とホームディレクトリ設定
duckdb_connection = duckdb.connect(database=':memory:')
duckdb_connection.execute("SET home_directory='/tmp'") # Lambdaの一時ディレクトリに設定
# httpfs 拡張モジュールのインストールとロード
duckdb_connection.execute("INSTALL httpfs;")
duckdb_connection.execute("LOAD httpfs;")
# 3. S3からDuckDBでデータをロード
# ここで何かしらのフィルタリングやクレンジングを実施する。
query = f"""
SELECT * FROM read_parquet('{s3_input_path}')
"""
# SQLを実行して結果をPyArrow Table形式で取得
result_arrow_table = duckdb_connection.execute(query).fetch_arrow_table()
print(f"取得したデータ数: {result_arrow_table.num_rows}")
print(f"データスキーマ: {result_arrow_table.schema}")
# 4. Glue Catalogの設定(Icebergテーブルにアクセス)
catalog = GlueCatalog(region_name="ap-northeast-1", database="任意のスキーマ", name="my_catalog")
# 5. Icebergテーブルにデータを追加(リトライ処理付き)
retry_append(catalog, "任意のスキーマ", "任意のテーブル", result_arrow_table)
except Exception as e:
print(f"エラーが発生しました: {e}")
# 競合が発生した場合は最新スナップショットを取得し直す
def retry_append(catalog, namespace, table_name, result_arrow_table, retries=5):
delay = 5 # 初回の待機時間(秒)
for attempt in range(retries):
try:
# 最新のIcebergテーブルをロード
iceberg_table = catalog.load_table(f"{namespace}.{table_name}")
iceberg_table.refresh() # 明示的にテーブル情報を更新
current_snapshot = iceberg_table.current_snapshot()
snapshot_id = current_snapshot.snapshot_id if current_snapshot else "None"
print(f"Attempt {attempt + 1}: Using snapshot ID {snapshot_id}")
# データを追加
iceberg_table.append(result_arrow_table)
print("データがIcebergテーブルに追加されました。")
return
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if "Cannot commit" in str(e) or "branch main has changed" in str(e):
if attempt < retries - 1:
delay *= 2 # バックオフ間隔を指数関数的に増やす
print(f"Retrying in {delay} seconds with the latest snapshot...")
time.sleep(delay)
else:
print("Max retries reached. Failing the operation.")
raise
実行結果
実行前

実行後

今回の場合だと19ファイルに分割されます
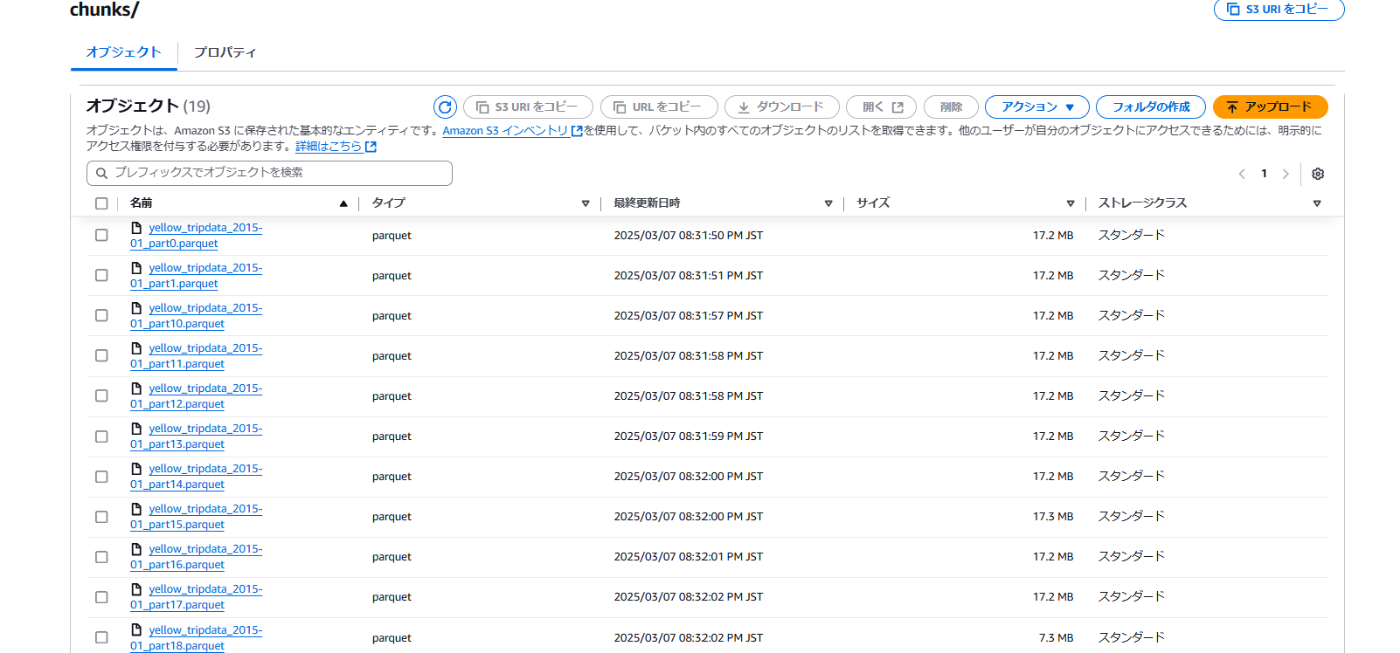
19回書き込み処理が実行

改善が必要なポイント
-
バックオフ間隔の調整:
Icebergテーブルのバージョン更新や競合によるエラー対応のための間隔をちょっと長めにしているのでここは要調整かなと。(リトライ回数の上限と時間は環境変数に持つのがいいかなと思います。)
実装としてはイマイチになってしまったこともありますが、そもそもリトライに関してはどうあるべきかしっかりと検討すべき事項だと思います。
今回のコードはあくまでもサンプルなので要件やIcebergの仕様を確認した上で、設計いただくのが良いかと思います。 -
チャンクサイズの制御:
CSVファイルをサイズごとに分けてparquet化していますが、parquetにした後でサイズごとに分割してもよかったかもしれない。
まとめ
今回はAWS LambdaとDuckDB、そしてSQSを活用した並列データパイプラインを構築しました。
AWSでETL処理を行う場合、通常はAWS GlueやEMRが候補に挙がりますがコスト面で適さない場合があります。
そこで採用されることの多いLambdaですが、前述したようなメモリと実行時間の制約があります。
今回紹介した組み合わせはそういったLambda特有の制約を回避しつつ、効率的かつコストパフォーマンスの高いアーキテクチャを構成することが可能となります。
ただし、厳密なフローやエラーハンドリングが必要な場合はStep FunctionsやGlueワークフローを活用したほうが良いと思います。
全ては適材適所なのでコストだけでLambdaを採用するのではなく、要件や制約等様々な要素を加味してサービス選定を行っていただければと思います。
今回の記事がLambdaでのデータパイプラインを構成する際に、参考になれば幸いです。
Discussion