AWSで構築するデータ基盤の基本とPower BI利用時の設計ポイント
はじめに
AWS Community Builderのぺんぎん(@jitepengin)です。
AWSでデータ基盤を構築する場合、S3をデータレイク、RedshiftをDWH(データマート)、QuickSightをBIとする構成は最もオーソドックスで、クラウドネイティブなアーキテクチャとしてよく採用されます。
今回はこの基本構成をベースに、どういった判断が必要なのかを解説しようと思います。
また、要件としてありがちな、BIをPower BIとしたいという場合にどのように構成すればいいのかについてもあわせて検討します。
基本的なアーキテクチャ(S3 × Redshift × QuickSight)
データ基盤のよくある構成は以下の通りです。
今回はAWSにロードされた以降をターゲットとしているので、ソース側からの連携については省略しています。
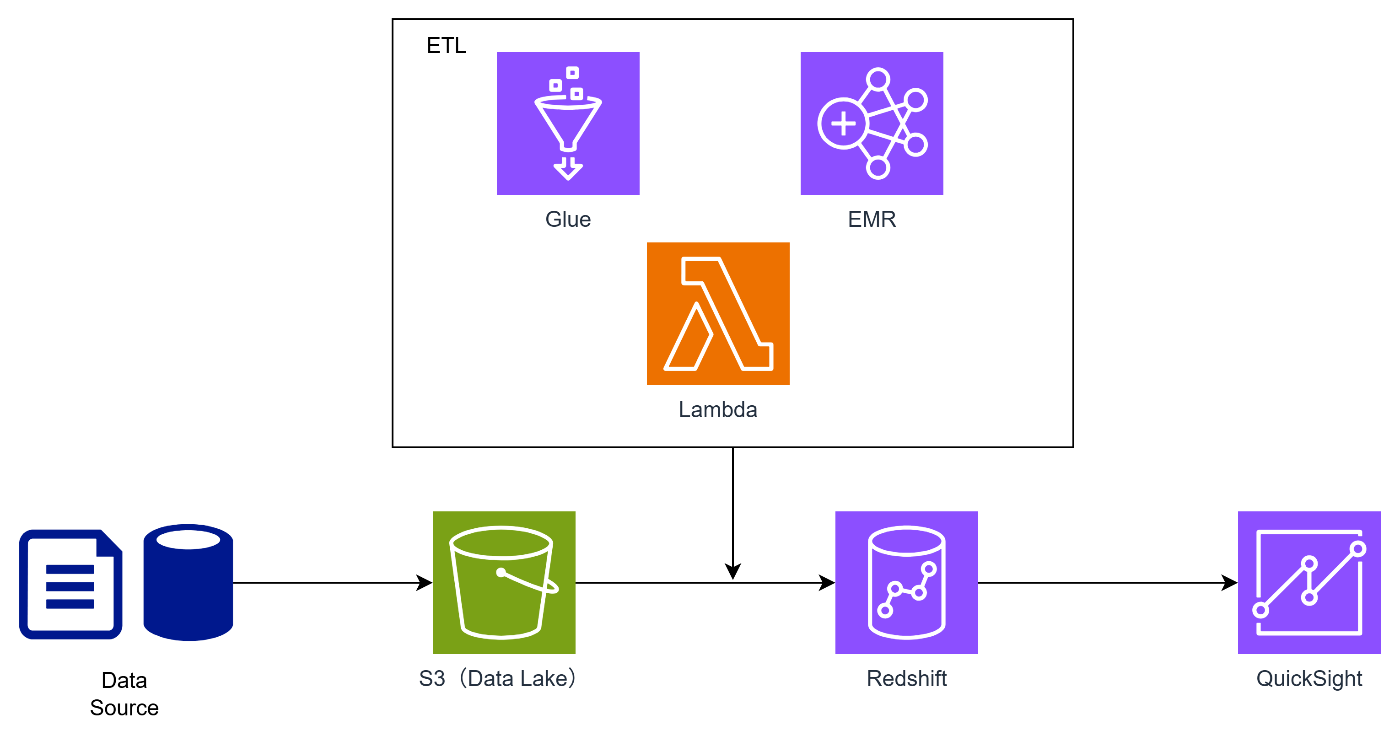
それぞれ簡単に解説します。
S3(データレイク)
データレイクにはS3を使うことが基本です。
ここは、様々な構成が考えられますが、メダリオンアーキテクチャを採用するのが良いと思います。

- 生データ(Raw)、整形済み(Processed)、分析用(Curated)などをレイヤー化して保存
- スキーマオンリードで柔軟性が高い
- Icebergなどのテーブル形式を採用すればACID性やスキーマ管理も強化可能
このあたりは下記の記事で紹介しているので参考にどうぞ。
Redshift(DWH/データマート)
RedshiftをDWHとして活用します。
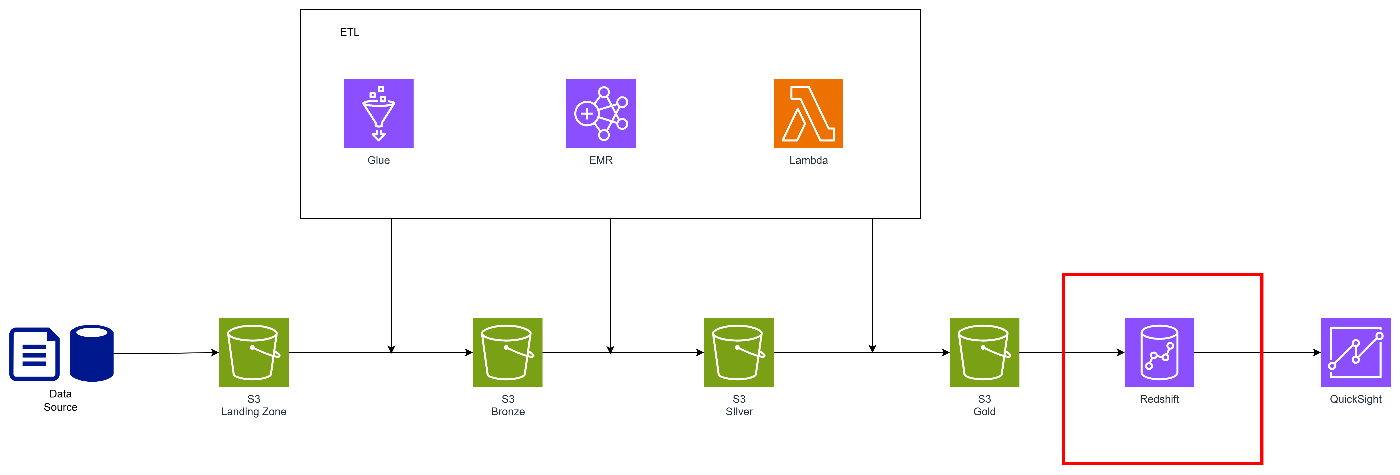
ここも様々な検討ポイントがあります。
- データレイクのゴールド層との住み分け
- RedshiftをProvisionedとServerlessのどちらにするか
- レイクのデータをRedshiftに取り込むか、外部テーブル扱いにするか
これ以外にも様々なポイントがあり、要件に応じた判断が必要となります。
データレイクのゴールド層との住み分け
一般的にメダリオンアーキテクチャのゴールド層はBIに最適化されたデータが格納されます。
お気づきの方もいると思いますが、DWHやデータマートとどう棲み分けるかがのポイントとなります。
-
DWH内にゴールド層を置くアプローチ

-
S3にゴールド層を置くアプローチ
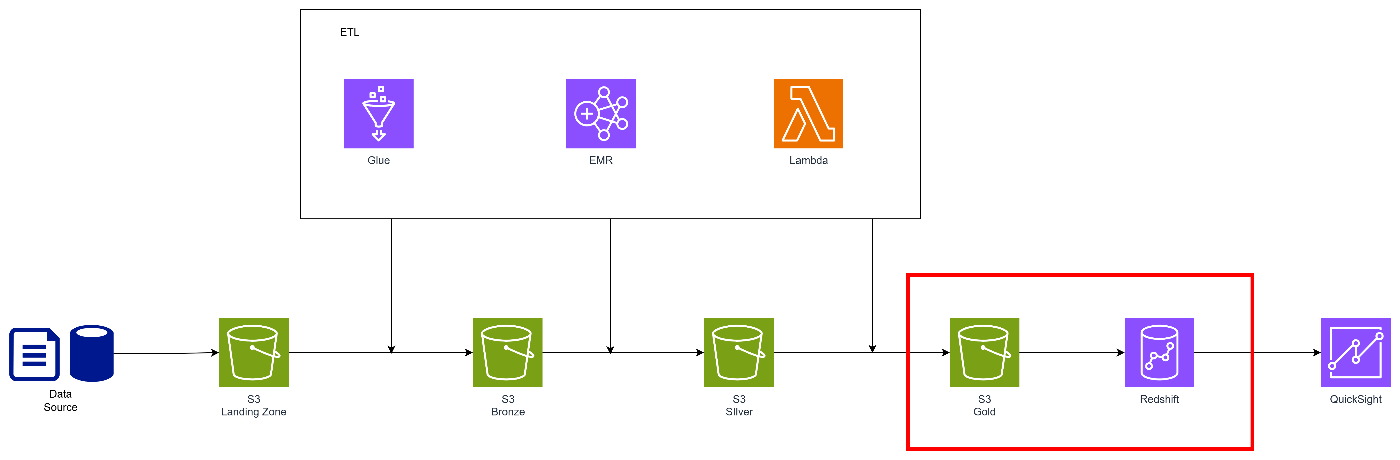
ここは、正解はなく、ゴールド層をデータレイク側に寄せずにDWH内で構成する方法もアプローチとしてはアリだと思います。
処理的にはS3側にゴールド層を置いてデータ整形・処理に寄せた方がDWH側の負荷を下げることができますが、DWH側とデータの2重持ちになり、ストレージコストがかさむことも考えられます。
※データの2重持ちに関しては回避方法があるので後で説明します。
結論としては、「要件や場合による」となりますので、仕様や制約などを考慮して判断いただくのが良いと思います。
ところでなぜRedshiftが必要になるのかですが、下記のようなことがあると思います。
- BIダッシュボードは秒単位のレスポンスが求められることが多い
こちらは単純に性能の高いRedshiftでクエリを実行したほうが有利という話です。 - KPI・集計テーブルはDWHにロードした方が安定する
こちらも性能に関わる部分にはなりますが、それ以外に可用性と言った観点でも優れています。 - ビジネスチームからの「横串要求」にはマートが必要
ゴールド層はあくまで「ドメインデータ」が中心ですが、BIは「事業横断の横串指標」が多いため、複数ドメインのデータを最終的にDWHでまとめるのが良いのかなと思います。
RedshiftをProvisionedとServerlessのどちらにするか

RedshiftにはProvisionedとServerlessの2種類があります。
どちらを採用するかによってコストや性能が変わってきます。
Serverless
- 小〜中規模環境ではコスト最適化しやすい
- ワークロードのブレが大きい場合に有利
- 運用がシンプル
Provisioned
- 大規模バッチ、重いSQLが大量にあるケース
- 予測可能なワークロードがある場合
こちらも結論としては、「要件や場合による」となりますので、仕様や制約などを考慮して判断いただくのが良いと思います。
基本はServerlessで検討して、要件に応じてProvisionedを検討する流れで良いと思います。
レイクのデータをRedshiftに取り込むか、外部テーブル扱いにするか
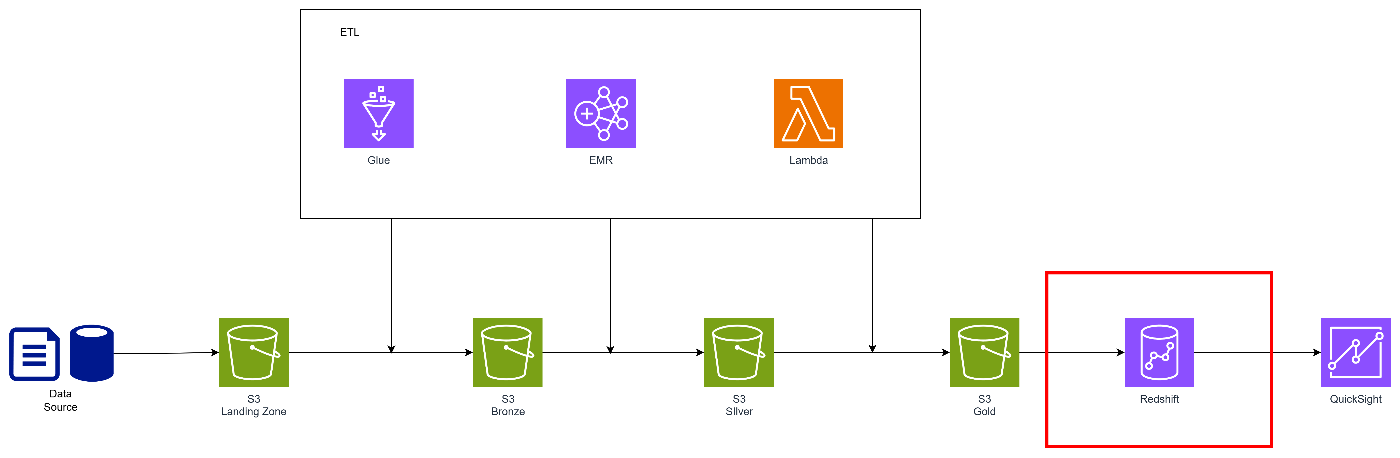
こちらは近年のレイクハウスの登場により、考慮が必要となる場面が増えてきました。
方式としては以下の2つがあります。
-
取込(COPY等)
データをRedshift内部にロードするので高速・安定したクエリ性能が実現可能
前述したようにデータレイク側の構成次第ではデータの2重持ちになる可能性がある -
外部テーブル(Spectrum)
ストレージの一元化が可能
大容量なデータを扱う場合、コストメリットが大きい。
こちらを活用することで、データ自体はレイク側のものをリードできます
つまりデータの2重持ちを回避可能です
こちらも結論としては、「要件や場合による」となりますので、仕様や制約などを考慮して判断いただくのが良いと思います。
主にコスト削減と性能のトレードオフで判断になると思います。
ETLサービスの選定(Glue/EMR/Lambda)

ETL選定ではGlue/EMR/Lambdaのいずれかを検討することが多いと思います。
- AWS Glue:フルマネージドなETLサービスでSpark/Pythonベースの柔軟なジョブ設計が可能
- AWS Lambda:軽量処理向きのサーバレス実行環境で小規模でリアルタイムなETLに強み
- Amazon EMR:Hadoop/Spark等をフルカスタマイズ可能なクラスタ型処理環境で大規模バッチ処理向き
こちらも結論としては、「要件や場合による」となりますので、仕様や制約などを考慮して判断いただくのが良いと思います。
ポイントはデータ量と実行時間になります。
詳細は下記にまとめているので参考にどうぞ
QuickSight
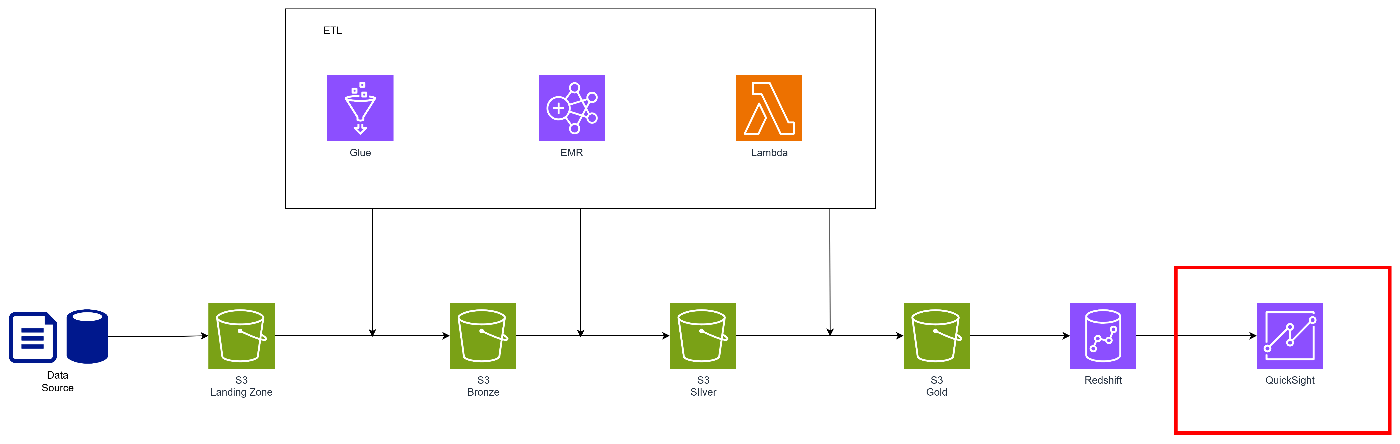
AWSでBIを構築する場合、セキュリティや権限等を加味するとQuickSightが第一候補となります。
ここで素直にQuickSightが利用できればそれで良いと思いますが、現実としては別のツールを使いたいという要件が出ることも多いです。
次のセクションからその中でもよく要望として挙がるにPower BIを使った構成について考えてみたいと思います。
BIにPower BIを活用する場合
エンタープライズ環境でデータ基盤を構築する場合、BIにPower BIを使いたいという要件が出ることが多いです。
その場合、どういった接続を行えばいいのかをまとめたいと思います。
Power BIを使う場合、次のような要件があがることが多いです。
- セキュリティ要件が厳しく、Redshiftをインターネット公開したくない
- Power BI サービス(クラウド)からAWS上のDWHに繋ぎたい
- オンプレミスとの接続ポリシーに制約がある
Power BIはAzureと相性が良いものの、AWSと接続する場合にはセキュリティや使用ツールを踏まえた構成を検討しないと、後で想定外な事態となることが多いです。
接続パターン
Redshiftをパブリックアクセス可能にする(非推奨)

最も単純ですが、セキュリティ上に大きな懸念があるためエンタープライズではほぼ採用することはありません。
-
メリット
- Power BI DesktopもPower BI Serviceも接続しやすい
-
デメリット
- セキュリティ上の懸念大
Power BI Desktopを活用するパターン
Power BI Desktopを使う場合、下記のようなパターンが考えられます。
こちらは基本的にセキュアな接続を前提にVPNかDirect Connectを使うのが良いと思います。
Direct Connectで接続
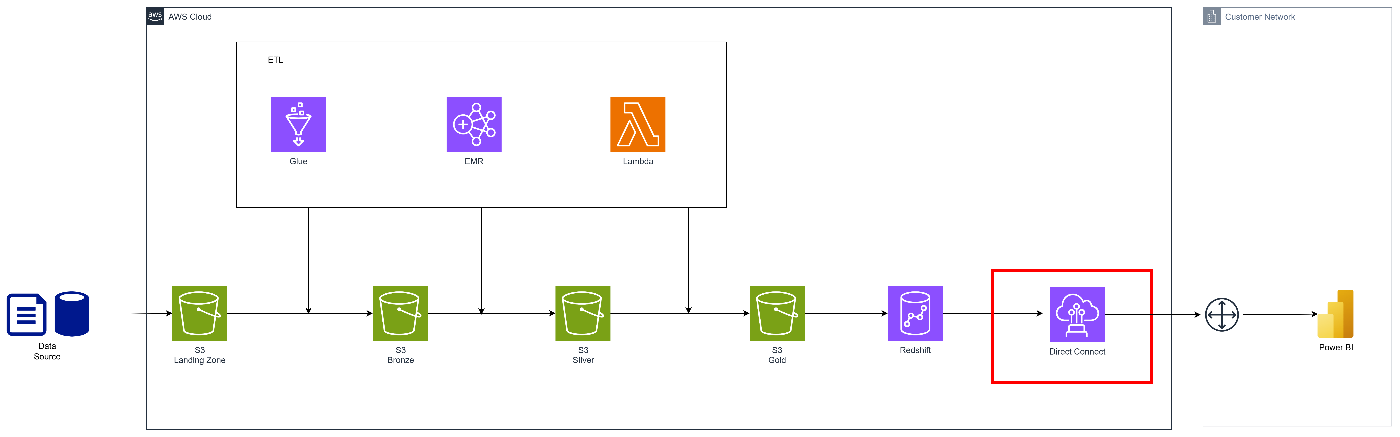
こちらはエンタープライズ環境で使われることの多いDirect Connectを使う方式です。
下記のような特徴があります。
- AWSとオンプレ環境を専用回線で接続する構成
- セキュリティ・帯域ともに最も安定
- 総じてコスト高
- 通信品質が必要な大規模構成で採用されることが多い
データ基盤案件はスモールスタートすることも多く、このためにDirect Connectを引くことは考えづらいと思います。
既存システムですでに使用されていたら、相乗りするようなイメージでOKです。
Site-to-Site VPNまたはClient VPNで接続

こちらもエンタープライズ環境で使われることの多いSite-to-Site VPNまたはClient VPNを使う方式です。
下記のような特徴があります。
- Power BI DesktopからVPN経由で接続する構成
- Direct Connectが設定されていない場合や様々な拠点から接続する場合によくある構成
これが一番よくある構成な気がします。
Direct Connectよりもハードルは高くなく、セキュアな接続が担保できるのがいい点ですね。
EC2内でPower BI Desktopを使う

こちらはあまり使う場面は少ないですが、AWS内にPower BI Desktopの実行環境を使用する方式です。
下記のような特徴があります。
- EC2にWindowsを立て、その中にPower BI Desktopをインストールし、その中で使用する構成
- 管理コストが増える
- AWS内からRedshiftに接続するためセキュリティ的にスムーズ
- 「逃げ道」として使うことが多い
Power BI Serviceを活用するパターン(オンプレミスデータゲートウェイ)

Power BI Serviceを使う場合、クラウド上からの実行となりますので、前述したようなDirect ConnectやVPNを使用することができません。
この場合、セキュアな接続を担保するにはオンプレミスデータゲートウェイを使用する必要があります。
お気づきの方も多いと思いますが、EC2を立てる必要があることから管理コストが増えること、そしてEC2が単一障害点となることが懸念となります。
- Redshiftをパブリックにしなくて良い
- Power BI Serviceの機能がすべて利用可能
- ゲートウェイの可用性(冗長構成)が必要
- 管理コストが増える
- DirectQueryの性能が課題になることがある
ちなみに、前述したように想定外のコストが発生してしまうのでわざわざEC2を建てるか?という議論になることが多いです。
これを一つの理由としてQuickSightに誘導するのもありだと思います。
とはいえ、あくまでもユーザに使ってもらえる仕組み、ユーザ目線で使いやすい仕組みを採用することを意識するのがいいと思います。
まとめ
本記事では、AWS の基本的なデータ基盤構成(S3 × Redshift × QuickSight)をベースに、Power BIを利用する場合に押さえるべき接続パターンを整理しました。
特にエンタープライズ環境では、セキュアな接続をどう担保するか、そしてコストや運用性はどうかといったことがポイントとなることが多いです。
また、Power BIの接続についてはDesktopとサービスを同時に使う場合も多いので、今回紹介したパターンを組み合わせることもあります。
いずれにせよ、今回紹介した内容以外にも、様々な要件や制約を加味した設計判断が必要となり、トレードオフを捉えることが求められます。
ベストプラクティスはある意味、「場合による」ということになりますので、様々なサービスの理解を深め、ビジネス要求と合致させること、つまりビジネスと技術の橋渡しを行うことが必要です。
最後に最も重要なのは、データ基盤はビジネス価値を向上させること、そしてそもそも使ってもらえる仕組みを作ることが重要となります。
技術ドリブンではなく、ビジネス価値ドリブンを意識することがすべての始まりだと考えています。
今回の記事が、データ基盤の構築を検討している方の参考になれば幸いです。
Discussion