AWSで実現するメダリオンメッシュアーキテクチャ
はじめに
以前、メダリオンアーキテクチャとデータメッシュアーキテクチャについて紹介しました。
今回は両者のメリットを組み合わせた 「メダリオンメッシュアーキテクチャ」 を紹介したいと思います。
本記事は以前紹介した下記のアーキテクチャの解説を抜粋・再構成したものとなります。
各アーキテクチャの詳細についてはそれぞれの記事を参照いただければと思います。
メダリオンアーキテクチャ

メダリオンアーキテクチャとはデータを論理的に整理するためのデータアーキテクチャで、データのレイヤー(ブロンズ⇒シルバー⇒ゴールド)を遷移するごとにデータの構造と品質を洗練・向上させることを目的にしています。
データが順次処理されることからマルチホップアーキテクチャとも呼ばれています。
オリンピックのメダルのように銅⇒銀⇒金の順に品質や価値が向上していくようなイメージですね。
ゴールドレイヤーまで来るとビジネス価値により直結したものになります。
メダリオンアーキテクチャの3つの層の役割
前述したようにメダリオンアーキテクチャでは3つの層が存在し、それぞれのレイヤーでデータを品質に応じて階層化し保存します。
-
ブロンズ層:様々なデータソースから取り込んだデータそのもの(生のデータ)が保存されるレイヤーとなります。データとしてはノイズが含まれており、データの欠損がある場合があります。
ここで重要なのがデータの完全性を維持するということです。生のデータを加工せずに保存しておくことがなにより重要となります。
ちなみに完全性が維持されたデータになるので監査にも対応できるデータとなります。 - シルバー層:ブロンズ層に保存された生のデータに対してクレンジングやフィルタリングを行い、分析に対応できる形式で保存するレイヤーとなります。このレイヤーに格納するタイミングで後続処理で不要なフィールドの削除、データ欠損の補完や整合性チェックを行う必要があります。
- ゴールド層:BIや機械学習等で使用されるある特定の目的向けに加工されたデータが格納されたレイヤーとなります。つまり最終目的のためにデータの集計や結合、場合によっては追加でクレンジングが行われ、ビジネスに直結するデータとなります。
このようにブロンズ⇒シルバー⇒ゴールドと遷移する中でデータがより洗練され、ビジネス価値に直結したものとなります。
ちなみにデータエンジニアリングにおいてビジネスの価値を意識することは非常に大事です。
ビッグデータという言葉に踊らされ、ビジネスにつながらないようなデータを溜め込むことで、価値のあるデータが埋もれてしまい、貴重なデータを活かしきれていない企業も多いのではないでしょうか。
データメッシュとは
データメッシュとは、従来行われていたような中央集権型のデータ管理から、ドメイン単位でのデータ管理に分散させ、ドメインチームがデータプロダクトを所有し運用するアプローチとなります。
ドメイン駆動の考え方に基づいたデータ管理手法となります。

データメッシュは以下の4つの原則に基づいて構成されます。
-
ドメイン別オーナーシップとアーキテクチャ
データを生成するチームがそのデータの所有権を持ち、その責任を負うという原則です。
従来の集中型データ管理(データレイクやデータウェアハウス)とは異なり、データの生成や活用を行うドメインチームが自分たちのデータの管理と提供を担当します。 -
プロダクトとしてのデータ
データを単なる副産物やリソースではなく、「プロダクト」として設計、開発、提供するという原則です。
プロダクトとしてのデータは、利用者に価値を提供し、使いやすく、高品質であることが求められます。 -
セルフサービス型データ基盤
データの提供や活用をサポートするために、各ドメイン所属の開発者やデータ利用者が自律的に操作できるデータ基盤を提供するという原則です。
セルフサービス型の仕組みによって、ドメインチームがデータプロダクトを迅速かつ効率的に提供できるようになります。 -
横断的なガバナンス
分散型アプローチを維持しつつ、一貫性とコンプライアンスを確保するためのガバナンスを横断的に実施するという原則です。
これは、中央集権的なトップダウン型ガバナンスではなく、各ドメインが独立性を持ちながら共通のルールに従うモデルです。
データメッシュではデータの管理責任がドメイン側に移るため、データの品質管理やマネジメントをドメイン側で担保する必要があります。
ドメイン側にデータ品質が左右されてしまうため、横断的なガバナンスがなにより重要となります。
また、データの収集も各ドメインに責任があるため、データを収集するETL等のデータエンジニアリング全般も各ドメインで対応する必要があります。
メダリオンメッシュアーキテクチャ
ここからが本題です。
「メダリオンメッシュアーキテクチャ」はその名の通り、メダリオンアーキテクチャとデータメッシュを組み合わせたもので、メダリオンアーキテクチャの階層構造とデータメッシュの分散型管理の利点を活かし、各ドメインが独立してデータを管理しつつ、ドメイン内のデータ品質を向上させることが可能となるデータ管理手法となります。
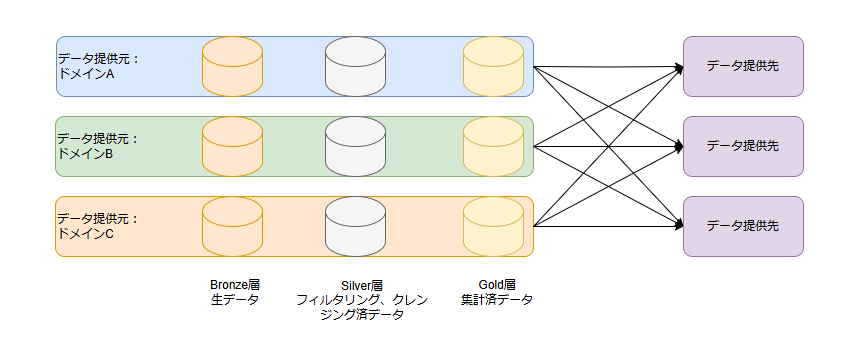
-
階層構造の分散化
メダリオンアーキテクチャのブロンズ、シルバー、ゴールド層を、各ドメインごとに独立して運用。これにより、ドメイン特化のデータ管理と全体のデータ品質向上を両立することができる。 -
分散型ガバナンス
データメッシュのフェデレーション型ガバナンスを活用して、ドメイン間のデータ共有ルールやメタデータ管理を統一することができる。 -
柔軟な拡張性
データのステージングや処理フローがドメインごとに構築されるため、スケーラブルかつ柔軟に変更可能となる。 -
セルフサービス型のパイプライン構築
ドメインチームが自律的にETLパイプラインを構築可能で、中央管理のボトルネックを排除することができる。
それぞれの強みを活かし、より強力にデータ管理を行うことができます。
この構成により大規模組織での高品質なデータの民主化が可能となります。
AWSで実現するデータメッシュアーキテクチャの例
こちらも以前紹介したようなメダリオンアーキテクチャとデータメッシュアーキテクチャを組み合わせたものとなります。
各ドメイン内の処理をメダリオンアーキテクチャで構成しデータの品質を担保。コンシューマ側からの参照をLake Formationで統制をとるデータメッシュの概念を使用したものとなります。
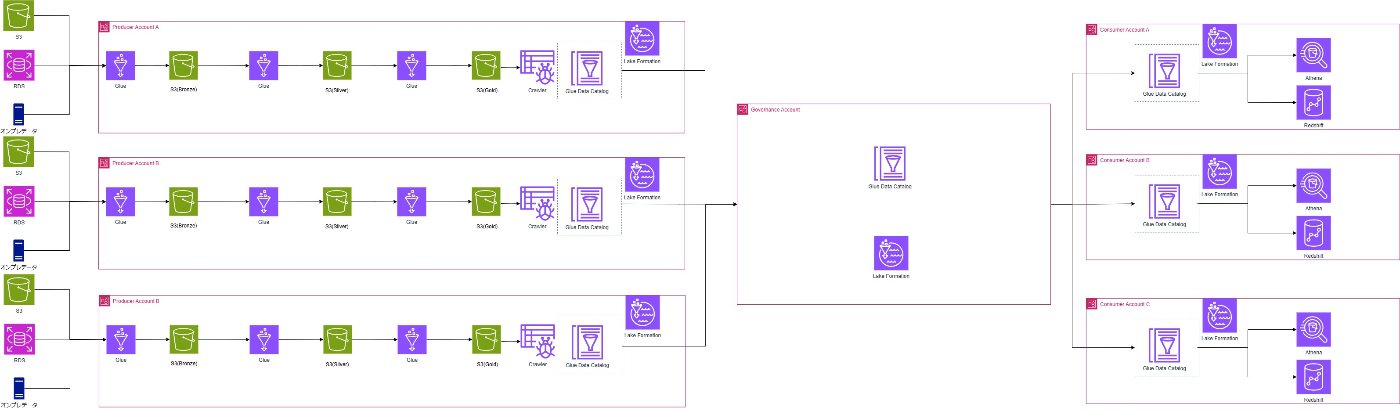
データプロデューサ
データプロデューサでは以下のサービスを活用します。
-
S3 / Glue
S3はデータレイクとして機能します。-
ブロンズ層
ブロンズ層では生データをそのまま保存します。GlueでETLジョブを構成することでS3やRDS等様々なデータソースからブロンズ層にデータを取り込むことができます。
クローラー機能で各データソースのデータを検出し、データカタログにメタデータを登録することで後続の処理で効率的にデータを扱うことが可能となります。 -
シルバー層
シルバー層ではブロンズ層の生データに対して、データのクレンジングやフィルタリングを行ったデータを保存します。
ここで力を発揮するのがGlueのSparkジョブです。大量のデータに対して欠損補完やノイズ除去、データ型の正規化等の処理を高速に実施できます。 -
ゴールド層
ゴールド層ではシルバー層で加工したデータを高度な分析や集計に向けてさらに加工したデータを保存します。
特定の目的向けのBIデータや機械学習モデル用の高度なデータセットを生成します。
ここでも大量のデータに対して結合や集計処理を行う必要があるためSparkの性能が発揮されるプロセスとなります。
-
-
Glue Crawler / Glue Data Catalog
S3に格納されたデータは、AWS Glue Crawlerを使用することでデータセットの検出が可能となります。検出したデータセットはAWS Data Catalogに登録され、テーブルとパーティションを追加し、その後スキーマの変更が検出可能となります。
この時、ゴールド層以外のブロンズ、シルバー層をクロール対象とすることで、生データやクレンジング済データにもアクセスすることが可能となります。 -
Lake Formation
Glue CrawlerをLake Formationと連携させます。これによりデータメッシュ全体でLake Formationを使用したデータアクセス認証を行うことが可能となります。
ガバナンスコントローラ
-
Glue Data Catalog
データプロデューサ側でクロールされた情報はガバナンスコントローラ内のGlue Data Catalogにデータカタログエンティティ (データベース、テーブル、列、属性) を作成します。
これにより、データコンシューマ間でカタログを検索することが可能となります。 -
Lake Formation
Lake Formationにてコンシューマ側のアクセス許可を設定します。アクセスが許可されたもののみコンシューマよりアクセスが可能となります。許可はタグベースのアクセス制御に基づいて行われます。
この機能により全体のガバナンスを統制します。
データコンシューマ
-
Glue Data Catalog
ガバナンスコントローラより許可されたDBとテーブルのリンクが設定されます。これによりコンシューマ側でのデータアクセスが可能となります。 -
Lake Formation
Lake Formationにて、コンシューマアカウントの各IAMユーザーとロールに権限を付与します。
付与されたアクセス権限に基づいてAthenaやRedShiftにデータをロードします。
これによりコンシューマ側での権限を制御することが可能となります。
まとめ
今回はメダリオンメッシュアーキテクチャの概念とAWSでの実現例を紹介しました。
メダリオンメッシュアーキテクチャはメダリオンアーキテクチャの階層構造とデータメッシュの分散型管理の利点を活かし、高品質とデータの独立性を担保したデータ管理手法となります。
以前の記事でも触れた通り、ドメイン駆動設計が反映された組織やシステムが前提とはなりますが、よりビジネスに直結したデータを管理することができる魅力的なアーキテクチャとなります。
今回紹介したようにデータアーキテクチャは様々なものを組み合わせたり、特定の要素を取り入れたり様々な構成が可能です。
データアーキテクトやデータエンジニアはアーキテクチャの形にとらわれず、より鮮度が高く、ビジネス価値の高いデータを提供できるように検討すべきだと思います。
これまで紹介した以外にもデータハブアーキテクチャ、イベント駆動アーキテクチャ、ライブデータスタック等様々なアーキテクチャ、概念が存在します。
データエンジニアリングについては発展が著しい分野となるので、新しい技術やアーキテクチャが日々発表されると思います。
何よりも大事な「ビジネス価値」を意識しつつ技術にアンテナを張っていきたいですね。
Discussion