📖
決定木アルゴリズムをIris-datasetに対してPythonで実行した!
背景
今回では、大学での課題として、機械学習ライブラリを利用して、決定木アルゴリズムをIris-datasetに対して実行結果をレポートにすることになりました!
ライブラリ準備
library.py
import japanize_matplotlib #matplotlibで日本語を表示するためのライブラリ。
import matplotlib.pyplot as plt #データのグラフィック化(プロット)のために使用する
from sklearn.datasets import load_iris #irisデータを読み込むために使用する
from sklearn.tree import DecisionTreeClassifier #決定木モデル
from sklearn.model_selection import train_test_split #train用データ、test用データをわけるために使用する
from sklearn.metrics import classification_report, accuracy_score #訓練したものを評価するために使用する
from sklearn import tree #決定木モデルに関連する機能を使うために使用する
コード
では、ライブラリ準備のようにライブラリの宣言が終わった後に、次のようにコードを書きました。
tree.py
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
from sklearn import tree
import matplotlib.pyplot as plt
import japanize_matplotlib
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
class_report = classification_report(y_test, y_pred, target_names=iris.target_names)
plt.figure(figsize=(12,8))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names.tolist())
plt.title('irisデータをセットした決定木')
plt.savefig('tree.png')
plt.show()
-
iris = load_iris()
irisにデータセットを入れる。(この時に、irisのタイプはBunchs型になります。scikit-learnに含まれるデータセットはBunchs型です。) -
iris.data
Xにiris.dataを入れるが、iris.dataには【データ】が入っている。 -
iris.target
yにiris.targetを入れるが、iris.targetには【正解ラベル】が入っている。(【正解ラベル】とは、最終的に予測して導きたい値のことです。) -
train_test_split(X, y, test_size=0.3, random_state=42)
X_train,X_test,y_train,y_testにtrain_test_split(X, y, test_size=0.3, random_state=42) の戻り値を格納することになります。(この時のtest_size=0.3では、分割する時のテスト用データを決めることができます。なお、random_state=42では、普段分割する時にランダムに選択されますが、random_state=42をすることで、乱数を固定することができます。) -
DecisionTreeClassifier(random_state=42)
clfに決定木のモデルを指定します。 -
clf.fit(X_train, y_train)
X_train,y_trainを利用して、訓練をさせます。これによって、モデルがデータを学習することで、未知のデータに関して予測することができるようになります。 -
tree.plot_tree()
ここでは、決定木の可視化を行います。
まとめ
この記事を参考にしてコードを書くと、次のような結果を得ることができます。
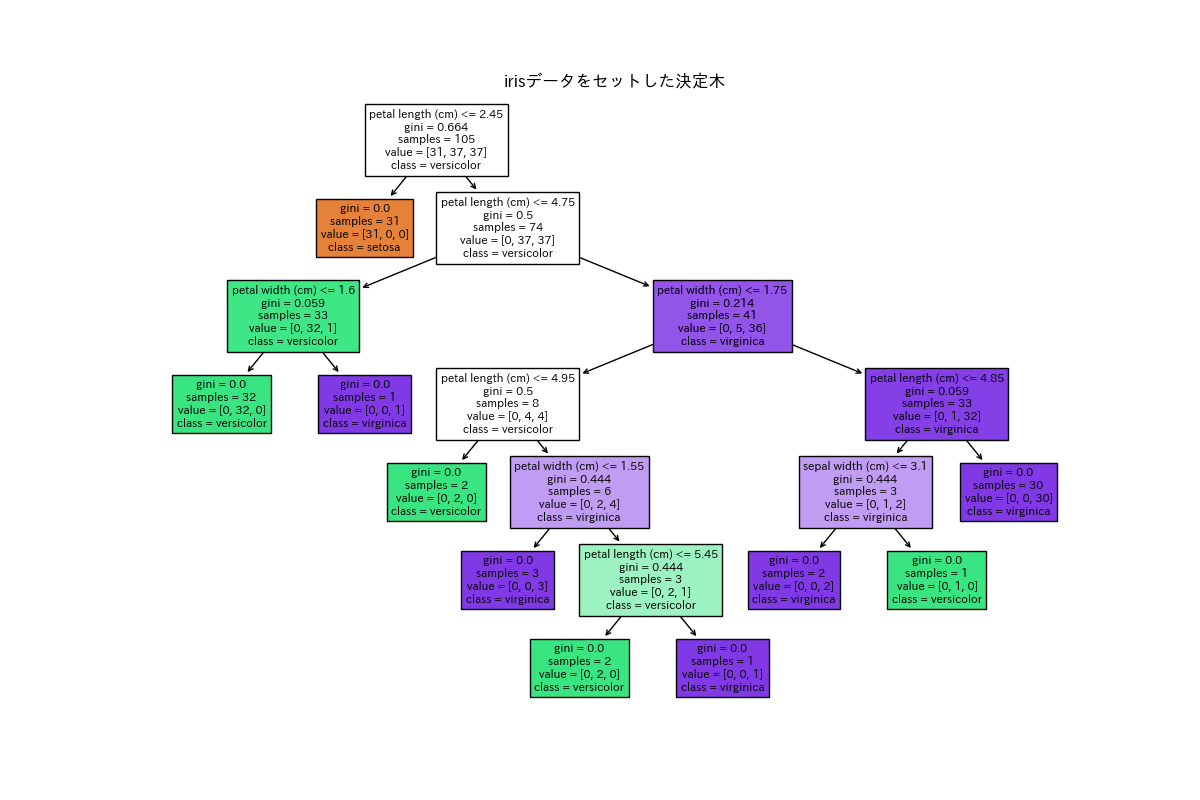 Irisデータをセットした決定木
Irisデータをセットした決定木
結果として、今回を通じて、決定木アルゴリズムをIris-datasetに対して実行結果をみることができました。役に立つ情報ではないと思いますが、間違っている情報などがあれば教えてもらうと嬉しいです!
Discussion