【初心者】ネコでも分かる「簡単な分類AI」の作り方【Python】
今回は、Python を使って簡単な人工知能(AI)を作ってみます。
初心者向けに超分かりやすく解説します。
なお、この記事の内容は YouTube で動画にもしています。併せて見ていただくと嬉しいです。
みなさんの理解が一歩でも進めば嬉しいです。
Created by NekoAllergy
6 つのステップに分けて解説します
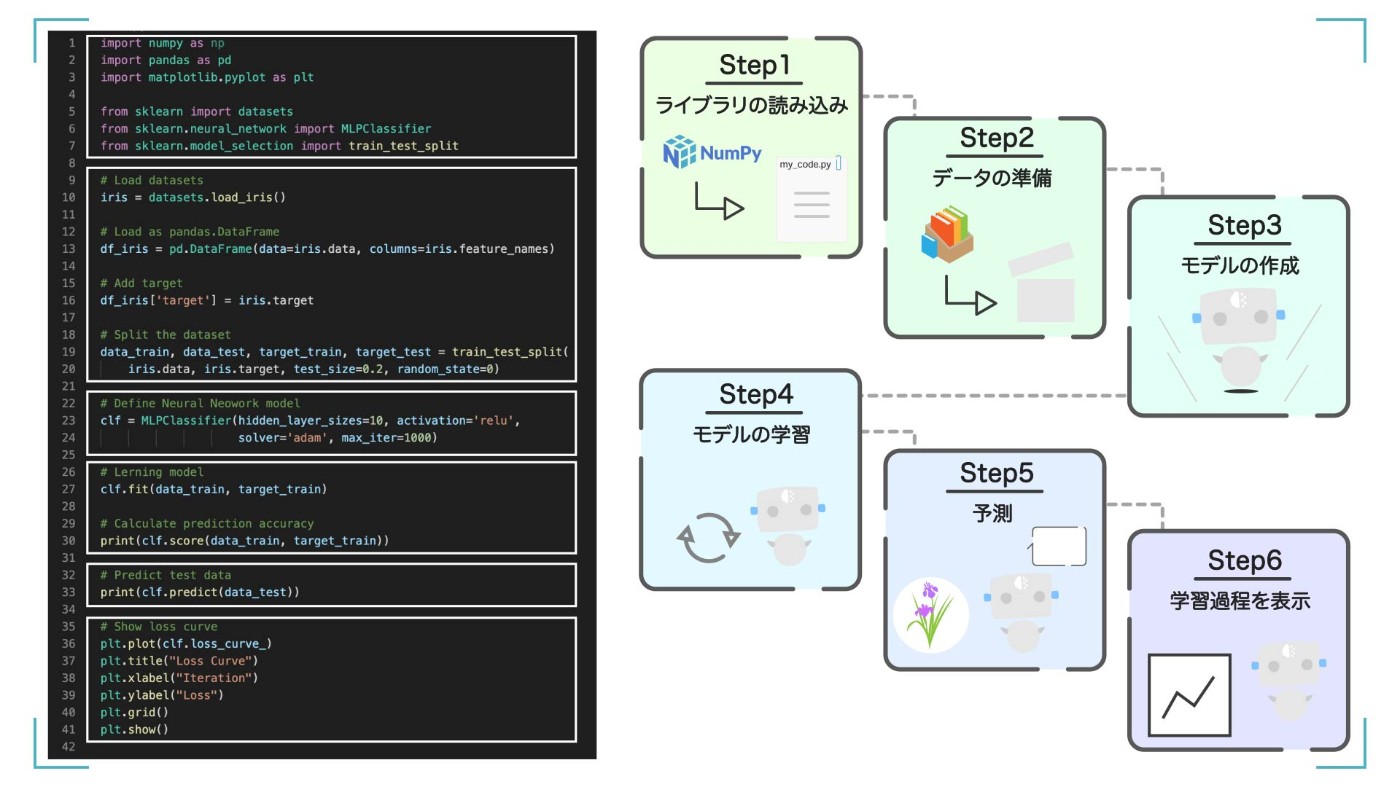
この記事の全体像
Step1
まずは、必要なライブラリを読み込みます。
Step2
次に、学習に使うサンプルデータを読み込んで、形をいい感じに整えます。
Step3
そして、Neural Network のモデルを作成します。
Step4
作ったモデルにデータを渡して、学習をさせます。
Step5
学習が完了したら、そのモデルが正しく予測できるかを確認します。
Step6
最後に学習過程を表示してみます。
わからない単語があっても大丈夫です。1 つ 1 つは難しいことはしていません。それぞれ順を追って解説します。
プログラムの全体像
後で解説するので読み飛ばしても構いません。
ソースコード全文
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
# Load datasets
iris = datasets.load_iris()
# Load as pandas.DataFrame
df_iris = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Add target
df_iris['target'] = iris.target
# Split the dataset
data_train, data_test, target_train, target_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=0)
# Define Neural Neowork model
clf = MLPClassifier(hidden_layer_sizes=10, activation='relu',
solver='adam', max_iter=1000)
# Lerning model
clf.fit(data_train, target_train)
# Calculate prediction accuracy
print(clf.score(data_train, target_train))
# Predict test data
print(clf.predict(data_test))
# Show loss curve
plt.plot(clf.loss_curve_)
plt.title("Loss Curve")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.grid()
plt.show()
Step1: ライブラリの読み込み
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
今回は上記の 6 つのライブラリを使います。
ライブラリとは?
ライブラリとは、賢い人が作ったプログラムをすぐに使えるようにした便利ツールです。今回のプログラムで必要になるライブラリ 6 つを読み込みましょう。
ライブラリを使うと簡単にプログラムが書ける!
-
Numpy
たくさんの数値(配列)を扱うのに便利なライブラリです。 -
Pandas
データを表として扱います。データの変換などがやりやすくなります。 -
Matplotlib
データや結果を図にして可視化するために使います。 -
Sklearn.datasets
このライブラリから、今回学習に使うサンプルのデータをとってきます。 -
Sklearn.neural_network.MLPClassifier
今回使う【ニューラルネットワーク】というアルゴリズムです。 -
Sklearn.model_selection.train_test_split
【訓練データ】と【テストデータ】を簡単に分けることができるライブラリです。
これら 6 つのライブラリを読み込むことで、AI を簡単に作ることができます。ライブラリに、機械学習のプログラム作成を助けてもらいましょう。
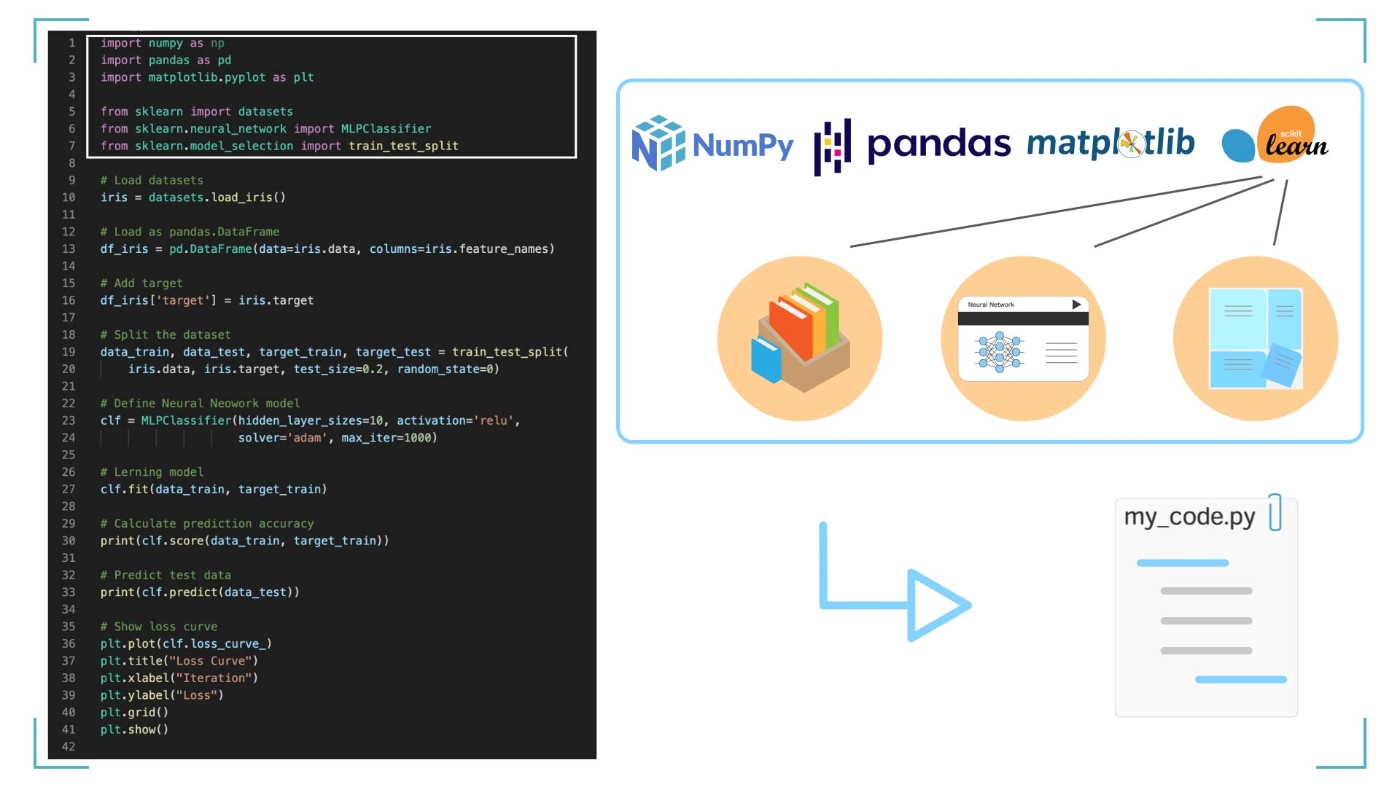
6 つのライブラリを import して使えるようにする

STEP1 のまとめ
Step2: データの準備
# Load datasets
iris = datasets.load_iris()
まずは、今回学習するデータを用意します。今回は、Sklearn というライブラリに含まれているサンプルの 【iris】(アイリス)というデータセット を使います。datasets の load_iris 関数を使って iris データセットを読み込み、それを iris という変数に入れます。
iris データセットには、アヤメというのお花の情報が入っています。このデータセットにはアヤメの 3 つの品種について、【花びらの長さ】など実際に計測した情報がたくさん含まれています。
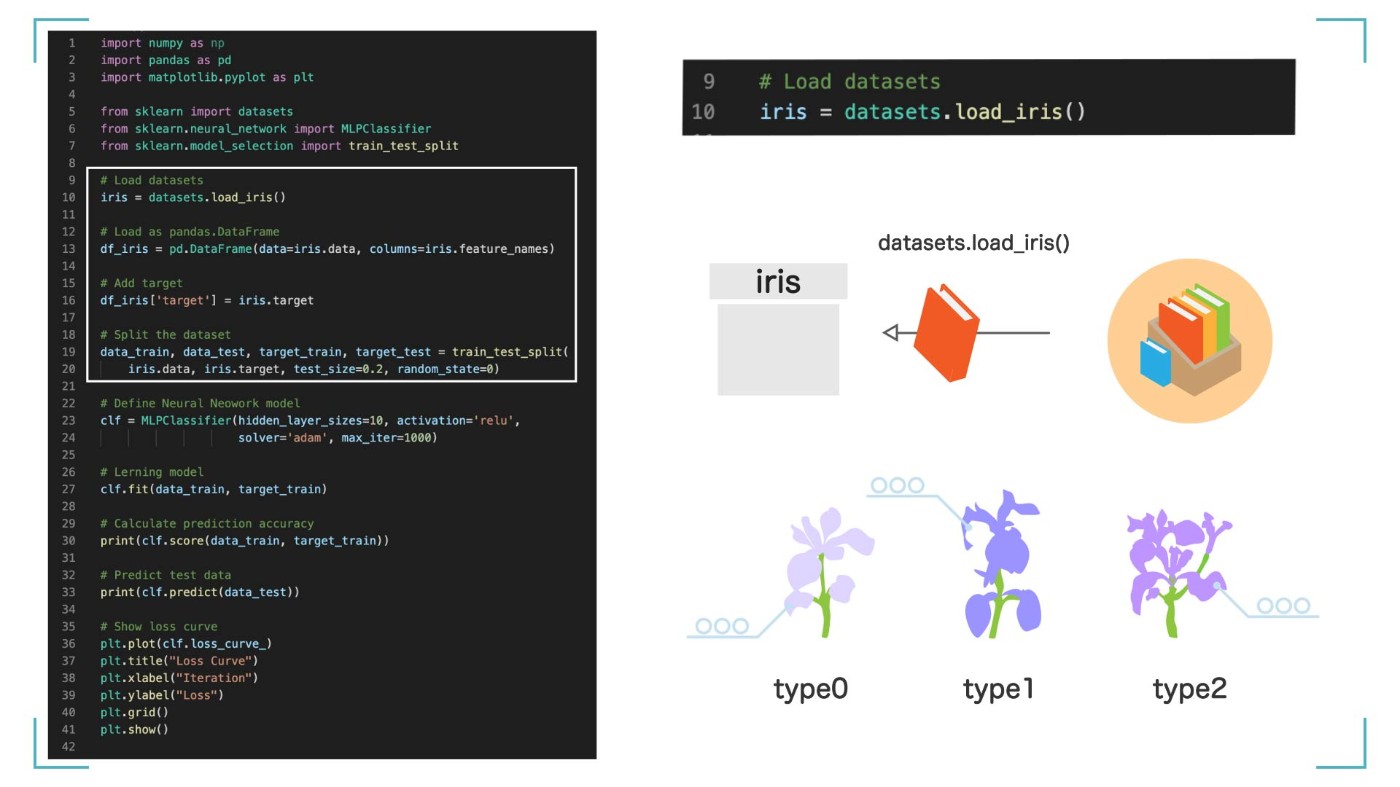
iris データセットには花の情報が入っている
この 3 種類の花を正しく分類することが、今回の機械学習プログラムのゴールになります。 Python を使って AI(モデル)を作り、この花の種類が正しく分類できるように頑張りましょう!
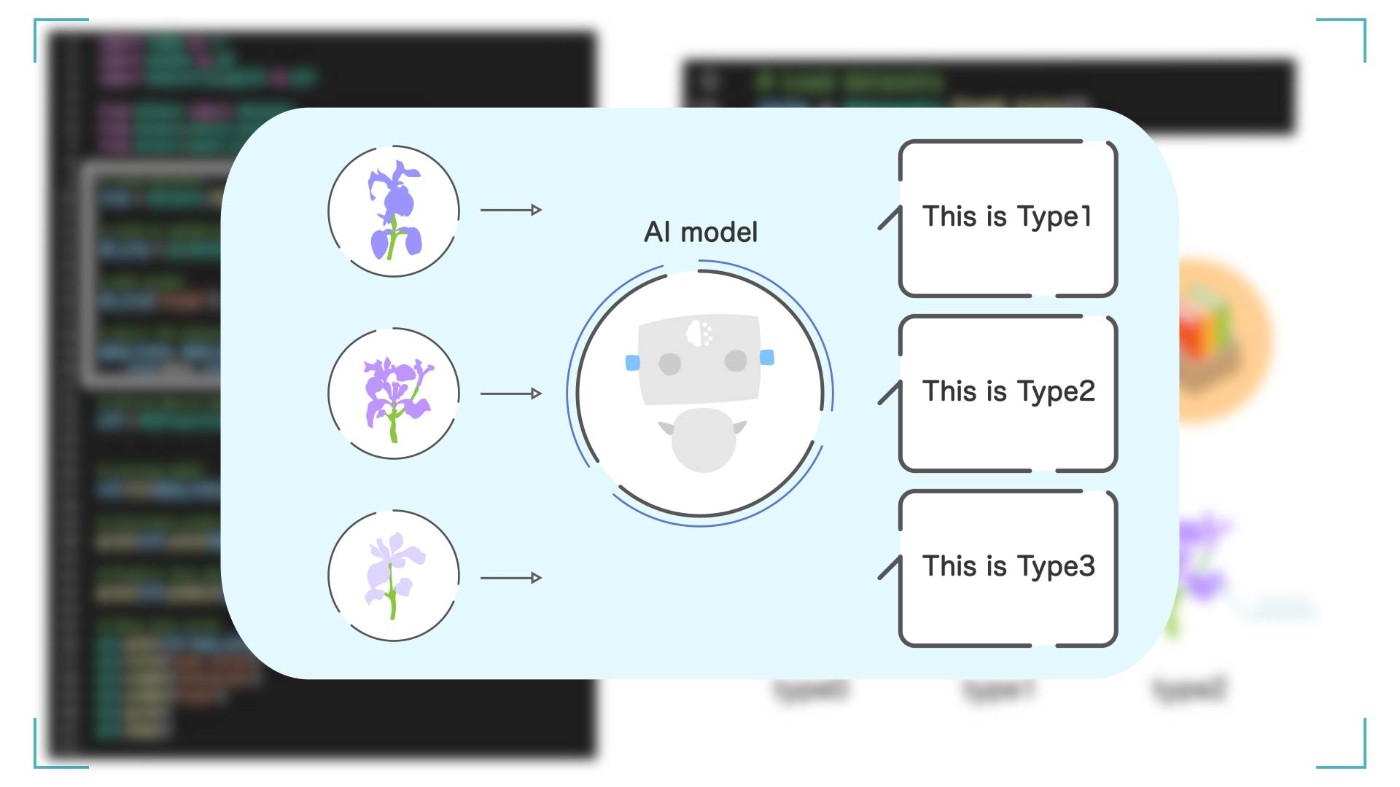
今回の目標は iris の種類を分類する AI を完成させること
ちょっと脱線
プログラムには書いていませんが、この iris データセットを調べて、もう少し詳しくなりましょう。まず、この変数 iris がどんなデータかを確認してみましょう。type()関数を使って、iris の型を確認できます。
print(type(iris))
<class 'sklearn.utils.Bunch'>
結果のように、scikit-learn に含まれているデータセットは全て Bunchs 型という型になっています。
Bunchs 型って?
詳しい説明は省きますが、Bunchs 型とは、Python で使える普通のリスト型や辞書型よりも便利 な使い方ができる型です。
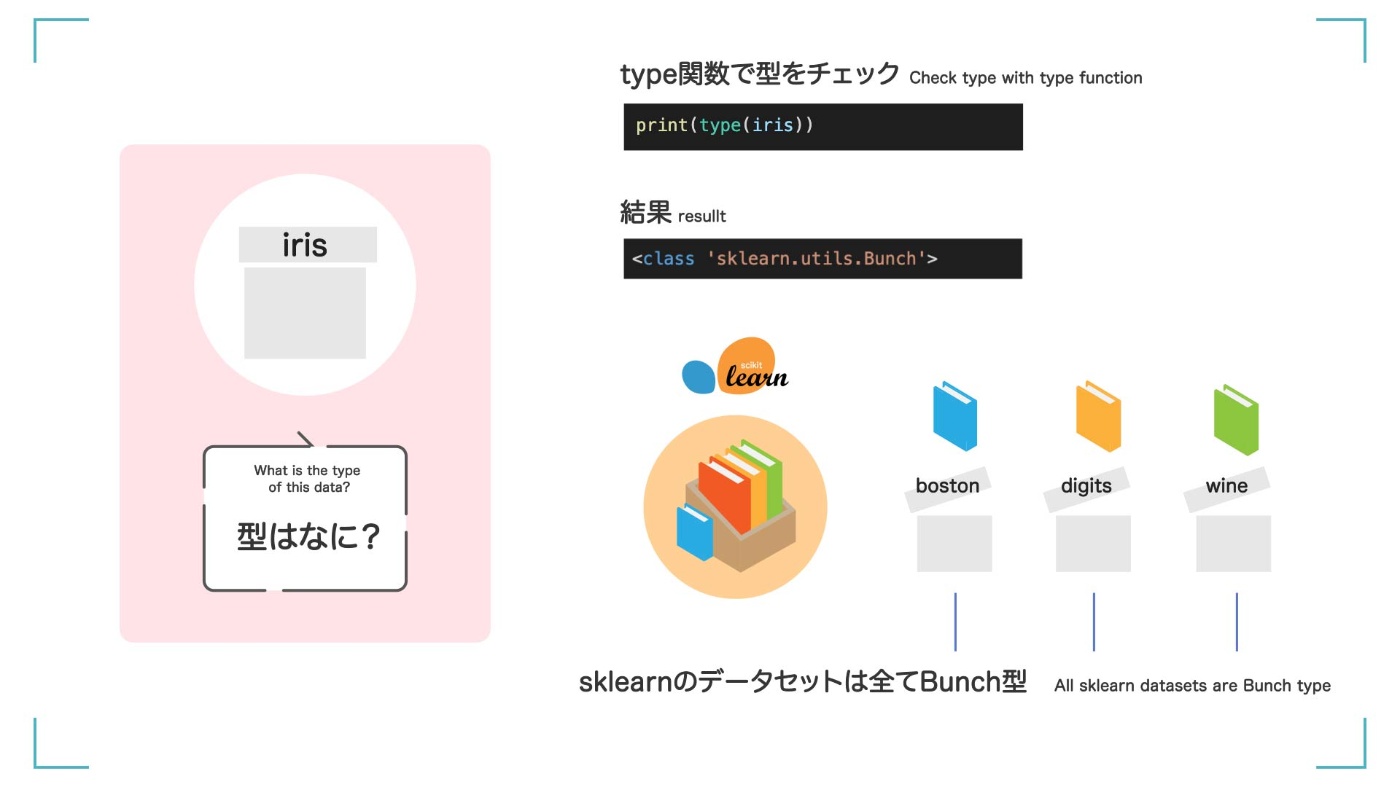
Bunchs 型は便利な型
次に、keys()関数を使って、iris で使える【キー】の一覧を確認します。
print(iris.keys())
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename']という 6 つが使えることがわかりました。
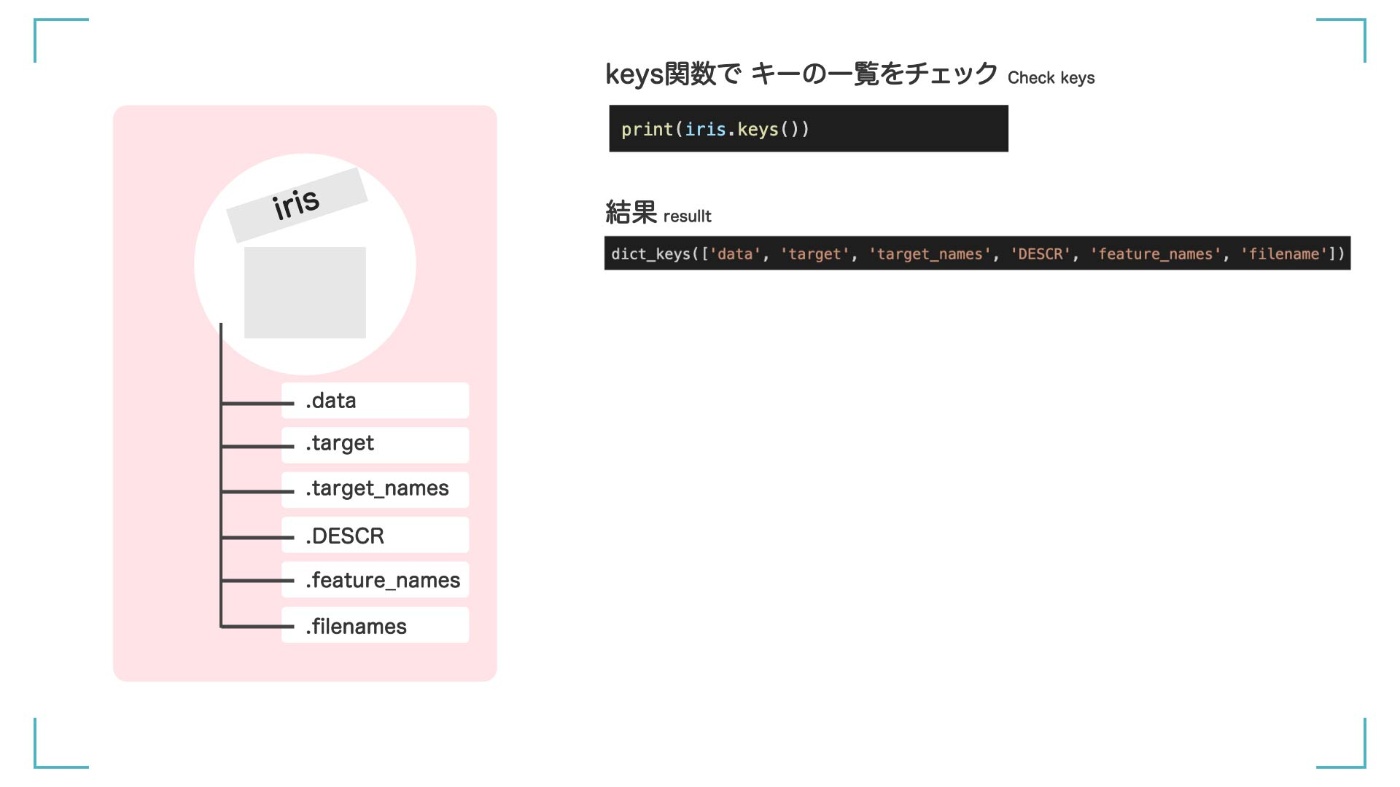
iris データは 6 つのキーが使える
こんな感じで使います
これらのキーは、iris.data のように、iris の後に「.」ドットをつけることで呼び出すことができます。
iris.data
iris.target
iris.DESCR
iris.feature_names
iris.target_names
iris.filename
ひとつずつ見ていきましょう。
iris.data って?
iris.data には【データ】が入っています。中に何が入っているのか確認してみましょう。
print(iris.data)
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
,
,
,
(150行続く)
,
,
,
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2]])
中身はこんな感じです。たくさんの数字が並んでいます。
図解

iris.data の中身は数値が並んでいる
さてまずは、type()関数を使って、iris.data の型を確認します。
print(type(iris.data))
<class 'numpy.ndarray'>
結果は<class 'numpy.ndarray'>なので、numpy の中の ndarray 型ということが分かりました。つまり、numpy のいろいろな便利な関数を使うことができます。
shape()関数を使うと、データが全部で何個あるのか、どんな形をしているのかを確認できます。
print(iris.data.shape)
(150, 4)
(150, 4)は、(行, 列)を表しているので、150 行、4 列と分かります。4 つの特徴(数値)をもったデータが 150 個並んでいるようです。
図解
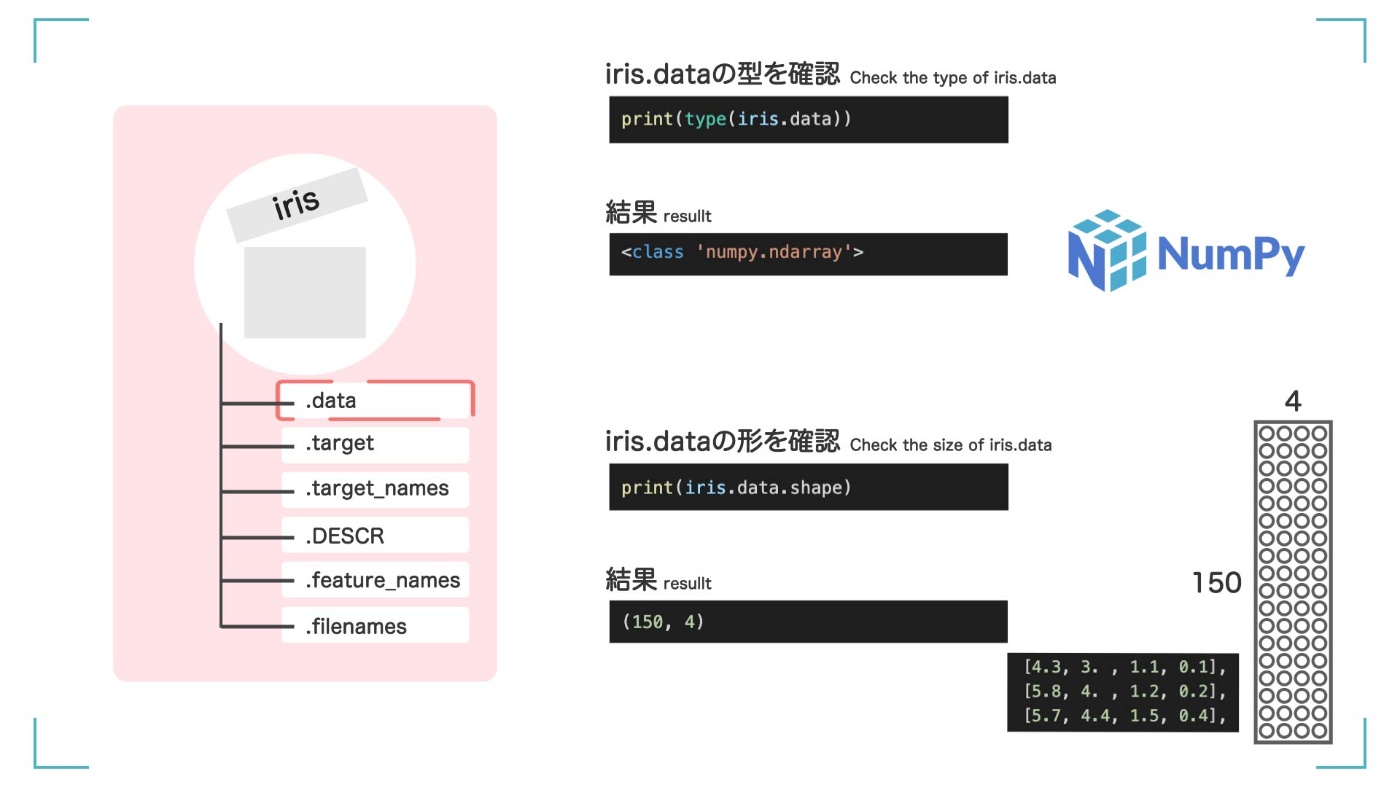
iris.data の型と形がわかった
iris.target って?
同様に、iris.target についても見ていきましょう。iris.target には【正解ラベル】が入っています。正解ラベルとは、最終的に予測して導き出したい値です。今回は AI(機械学習)を使って、この target の値を予測することがゴールとなります。
中身を見てみましょう。
print(iris.target)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
中身はこんな感じです。たくさんの 0 と 1 と 2 が並んでいます。iris.target に入っている正解ラベル 0, 1, 2 は、【3 つのどの品種のアヤメなのか】を数値として表しています。
先ほどの iris.data を学習して、最終的には、0 の品種なのか、1 の品種なのか、2 の品種なのかを予測して分類します。
図解

1 つずつに 0 か 1 か 2 のラベルがついている。これが正解ラベルとなる。
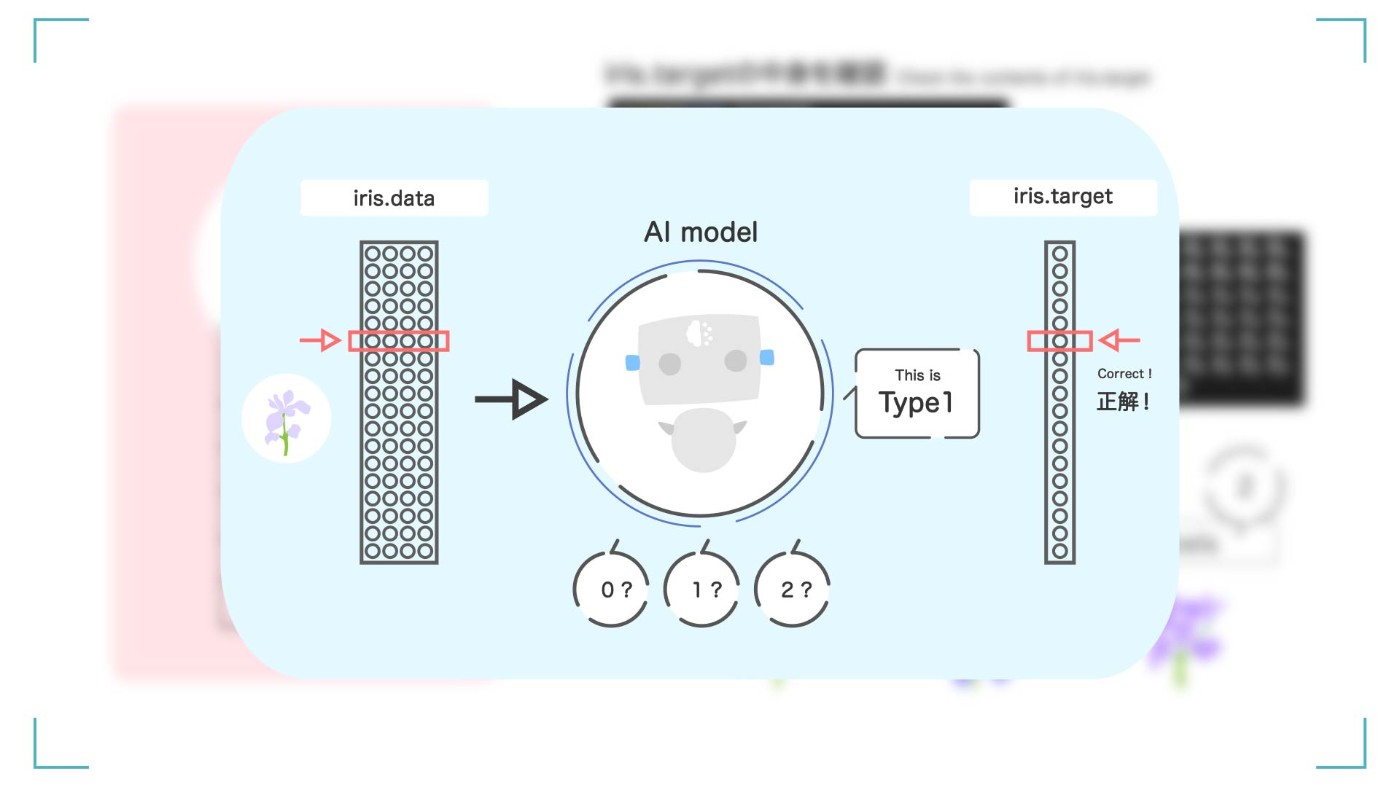
最終的に作りたい AI は、この iris.target の値を正確に言い当てる AI
さて、type()関数を使って、iris.target の型を確認してみましょう。
print(type(iris.data))
<class 'numpy.ndarray'>
こちらもさっきと同じで<class 'numpy.ndarray'>と分かりました。
shape()関数を使ってデータの形を確認すると、150 行、1 列と分かります。
print(iris.target.shape)
(150, )
図解

iris.target の型と形がわかった
なんとなくデータのイメージが掴めてきたでしょうか?
iris.feature_names って?
iris.feature_names には、さっきの【4 つの特徴とはどんな情報か】が書かれています。
iris.feature_names の中に何が入っているかを確認してみましょう。
print(iris.feature_names)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']らしいです。
つまり、先ほどの iris.data の数値には、花びらの長さ、花びらの幅、がく片の長さ、がく片の幅という 4 つの特徴が入っているようです。
図解
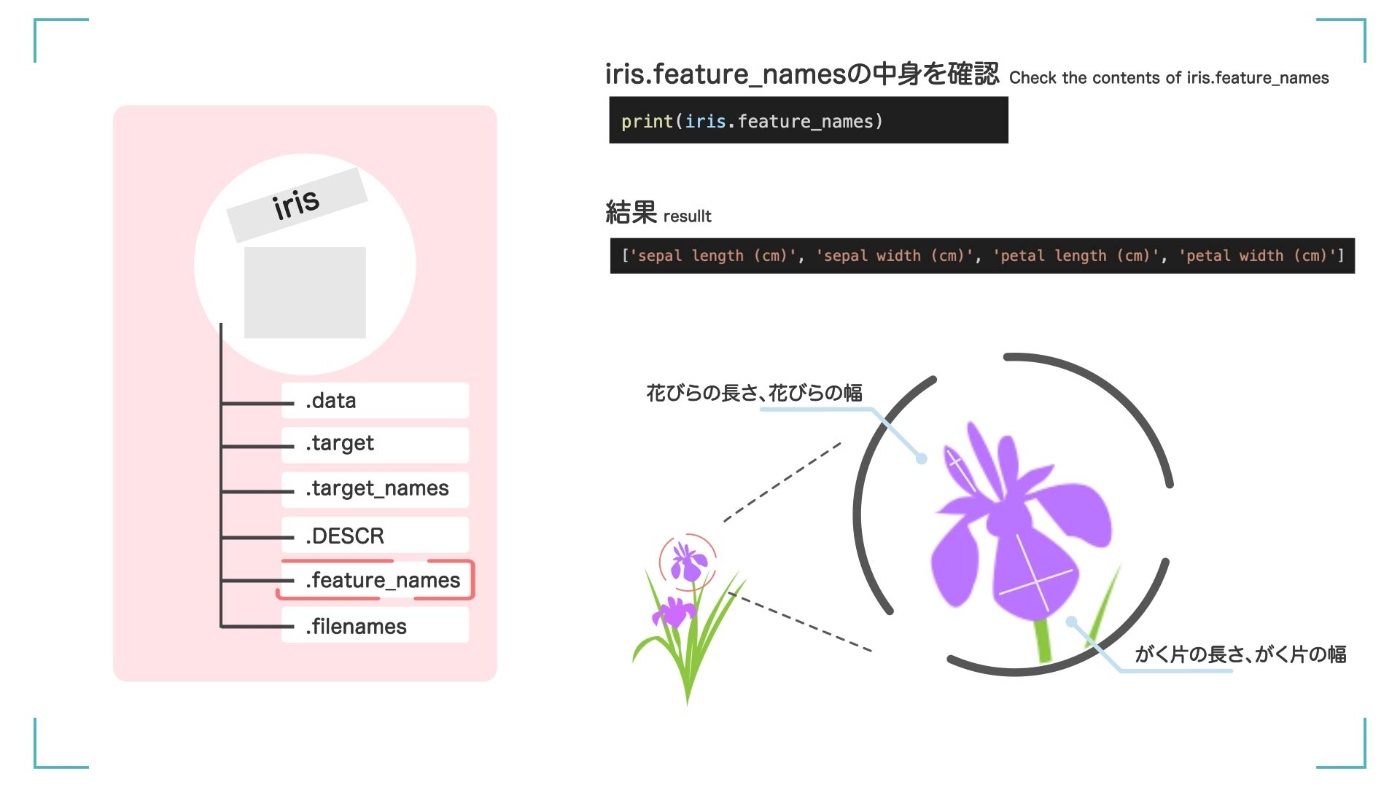
iris.data に書いてあった数値の正体
iris.target_names って?
iris.target_names には、【正解ラベルの情報】が入っています。
print(iris.target_names)
['setosa' 'versicolor' 'virginica']
結果から、さっきの data.target の 0, 1, 2 は、'setosa' 'versicolor' 'virginica'という名前の品種に対応しているということがわかります。
図解
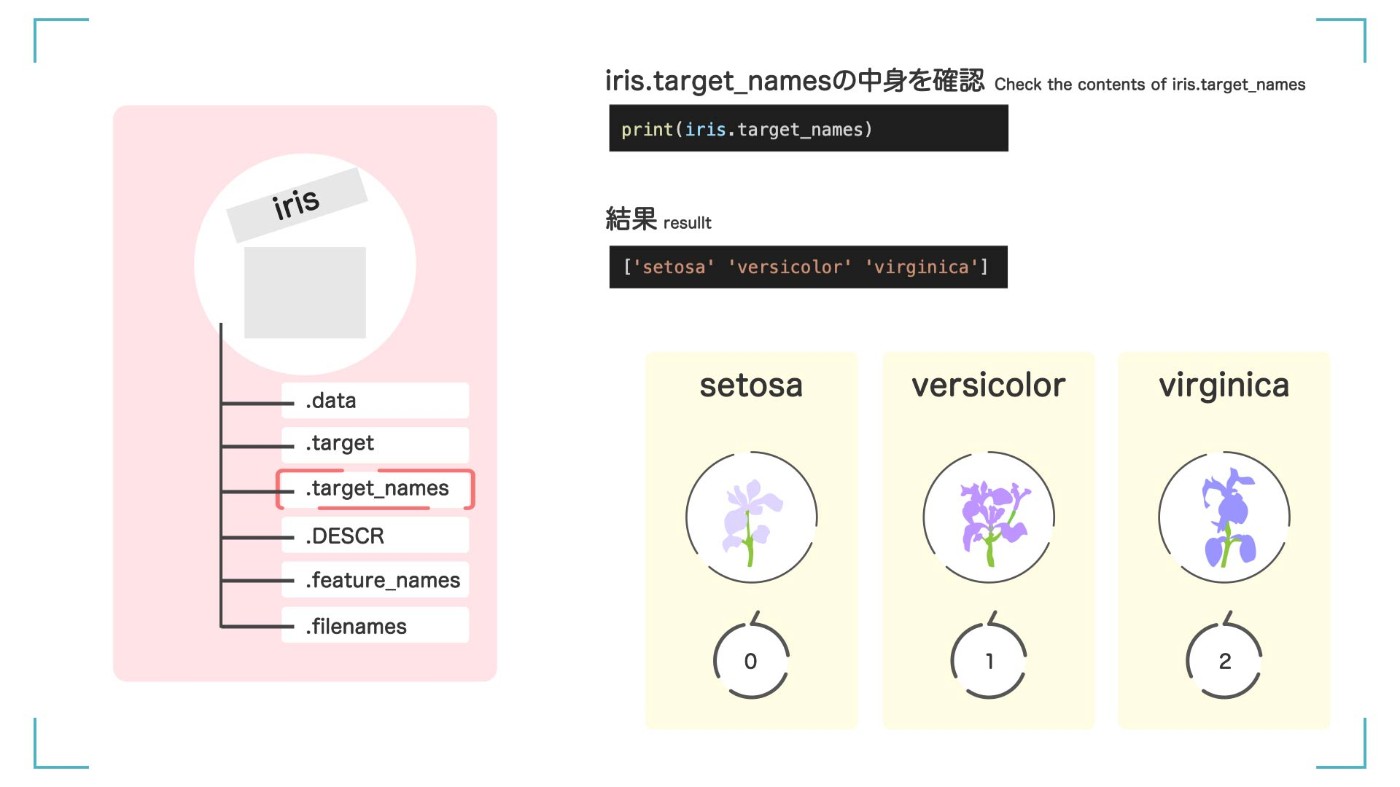
iris.target に書いてあった 0、1、2 の具体的な種類の名前
iris.DESCR って?
なお、これらの情報は、iris.DESCR の中に全て書いてあります。
print(iris.DESCR)
結果(長いです)
.. \_iris_dataset:
## Iris plants dataset
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
DESCR は、【Describe】=【説明する】の略です。詳細情報がまとめて書いてあってとても便利です。データのサイズや型が分からなくなったら iris.DESCR を確認してみてください。
iris データセットの全体像
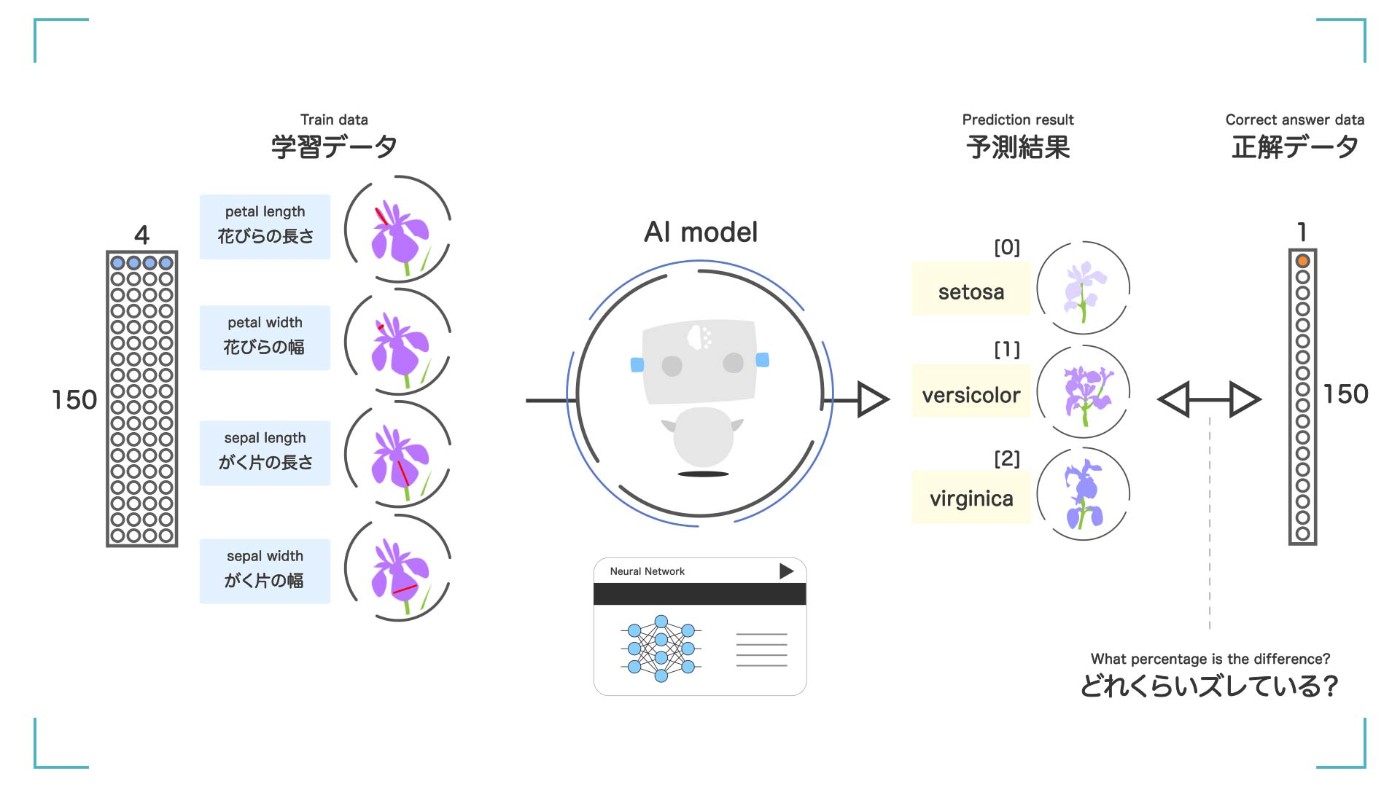
iris データセットの全体像
これで、今回使う iris データセットの全体像がつかめました。花びらの長さ、花びらの幅、がく片の長さ、がく片の幅という 4 つの特徴を用いて、'setosa' 'versicolor' 'virginica'のどれに当てはまるかを分類する人工知能を作りましょう。
iris データセットのチートシートです。スクショして使ってください。

iris データセットのチートシート
プログラムに戻ります
もう一回、ソースコード載せときます ↓
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
# Load datasets
iris = datasets.load_iris()
# Load as pandas.DataFrame
df_iris = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Add target
df_iris['target'] = iris.target
# Split the dataset
data_train, data_test, target_train, target_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=0)
# Define Neural Neowork model
clf = MLPClassifier(hidden_layer_sizes=10, activation='relu',
solver='adam', max_iter=1000)
# Lerning model
clf.fit(data_train, target_train)
# Calculate prediction accuracy
print(clf.score(data_train, target_train))
# Predict test data
print(clf.predict(data_test))
# Show loss curve
plt.plot(clf.loss_curve_)
plt.title("Loss Curve")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.grid()
plt.show()
この変数 iris を、pandas の Dataframe に入れます。Excel 形式の枠組みに入れるみたいなイメージです。
# Load as pandas.DataFrame
df_iris = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Add target
df_iris['target'] = iris.target
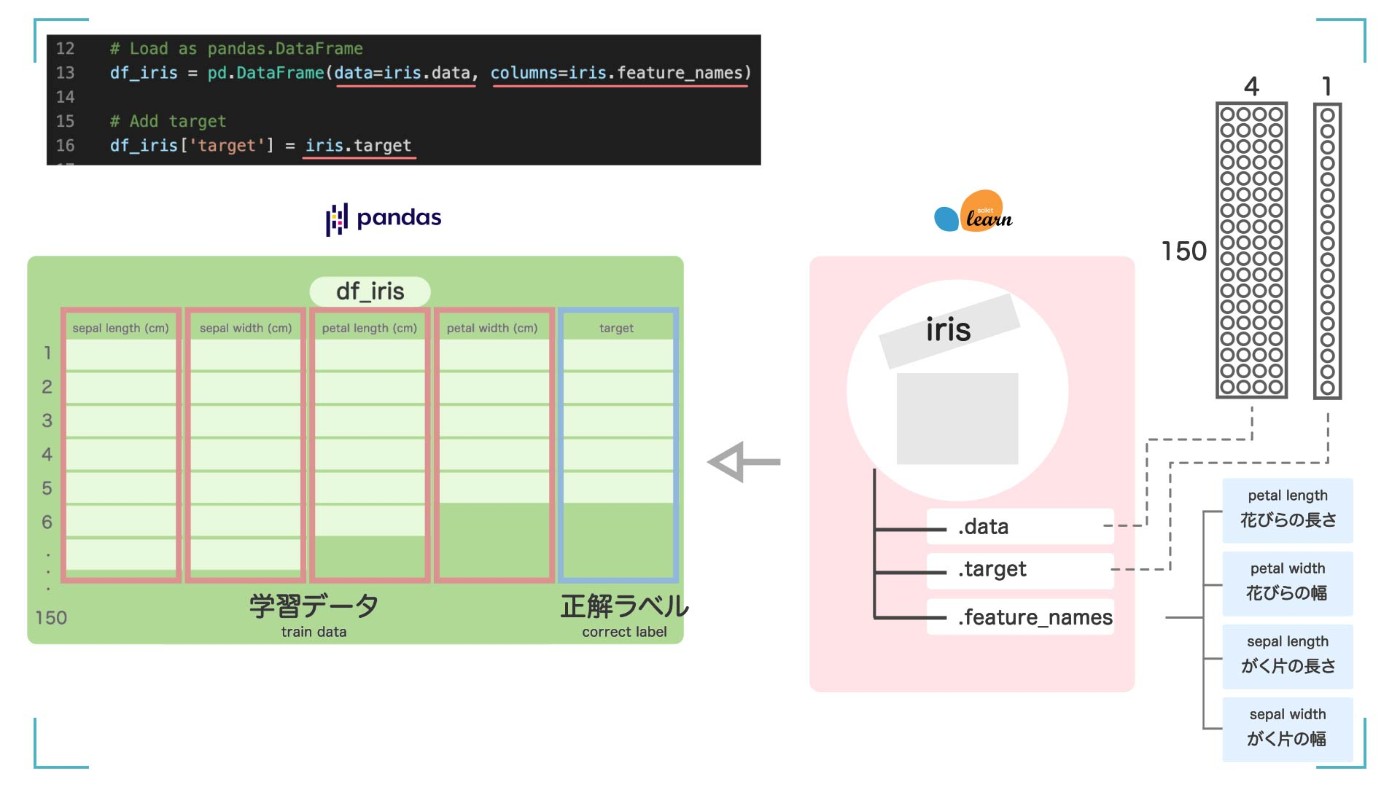
pandas の Dataframe に入れる
Dataframe に入れることで、データの 【平均値】や【中央値】などの情報を素早く確認できる ようになります。
こんな感じ
print(df_iris)

中身はこんな感じ
df_iris.describe()を使うとdf_iris のいろんな情報を見ることができます。
print(df_iris.describe())
結果
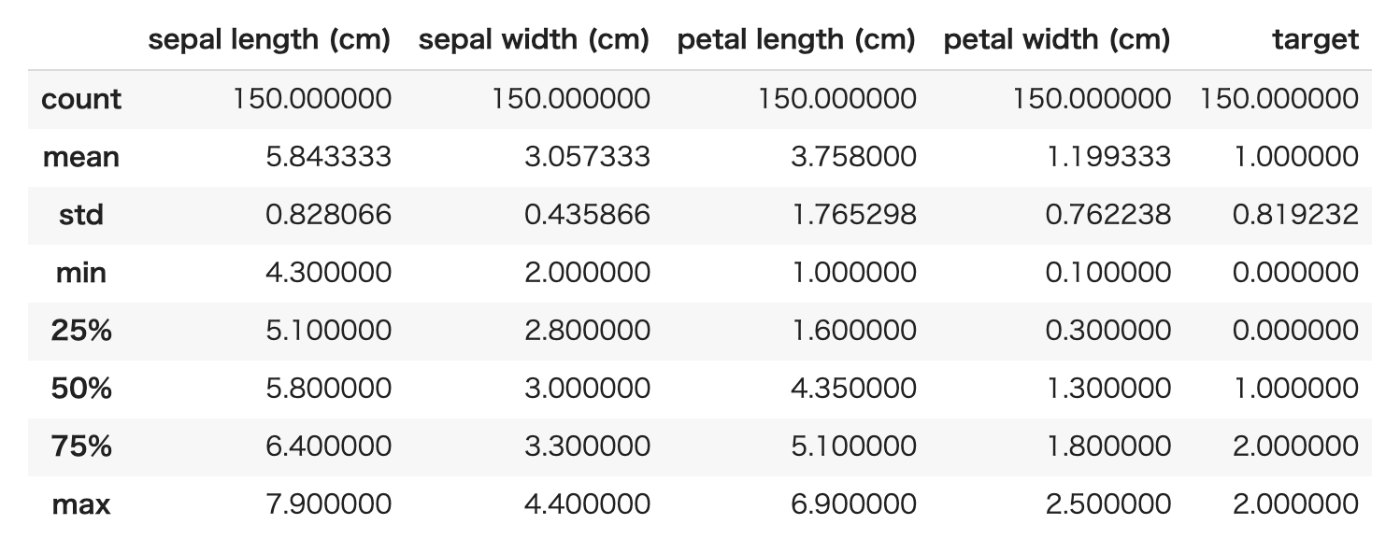
describe()関数を使うと、df_iris の情報を一度に確認できる
【データの個数、平均、標準偏差、最小値、1/4 分位数、中央値、2/4 分位数、最大値】が一目で分かります。便利です。このように、最初にデータを読み込んだ時には、なんとなくの傾向/分布をみることから始めましょう。
次に、データを学習しやすく加工していきます。機械学習をするときはデータを、【訓練データ】と【テストデータ】に分ける必要があります。
【訓練データ】と【テストデータ】ってなに?
-
【訓練データ】
⏩ AI(モデル)が賢くなるために学習するデータです。 -
【テストデータ】
⏩ 学習済みの AI がどれだけ賢いのかを測るためのデータです。
⏩ 学習が終わって最後に使用します。
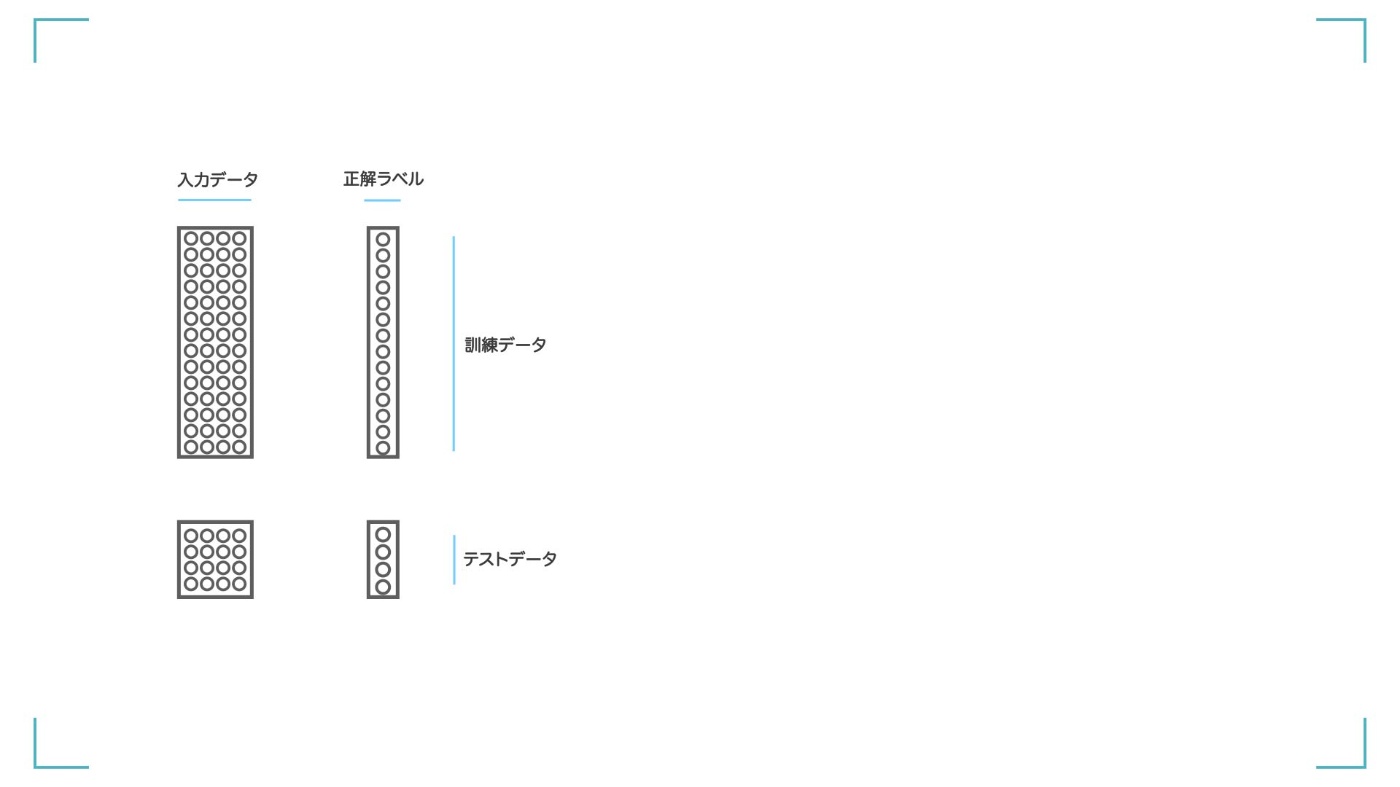
STEP① データは訓練データとテストデータに分けて扱う

STEP② 訓練データを使ってモデルを学習させる

STEP③ 学習が完了する
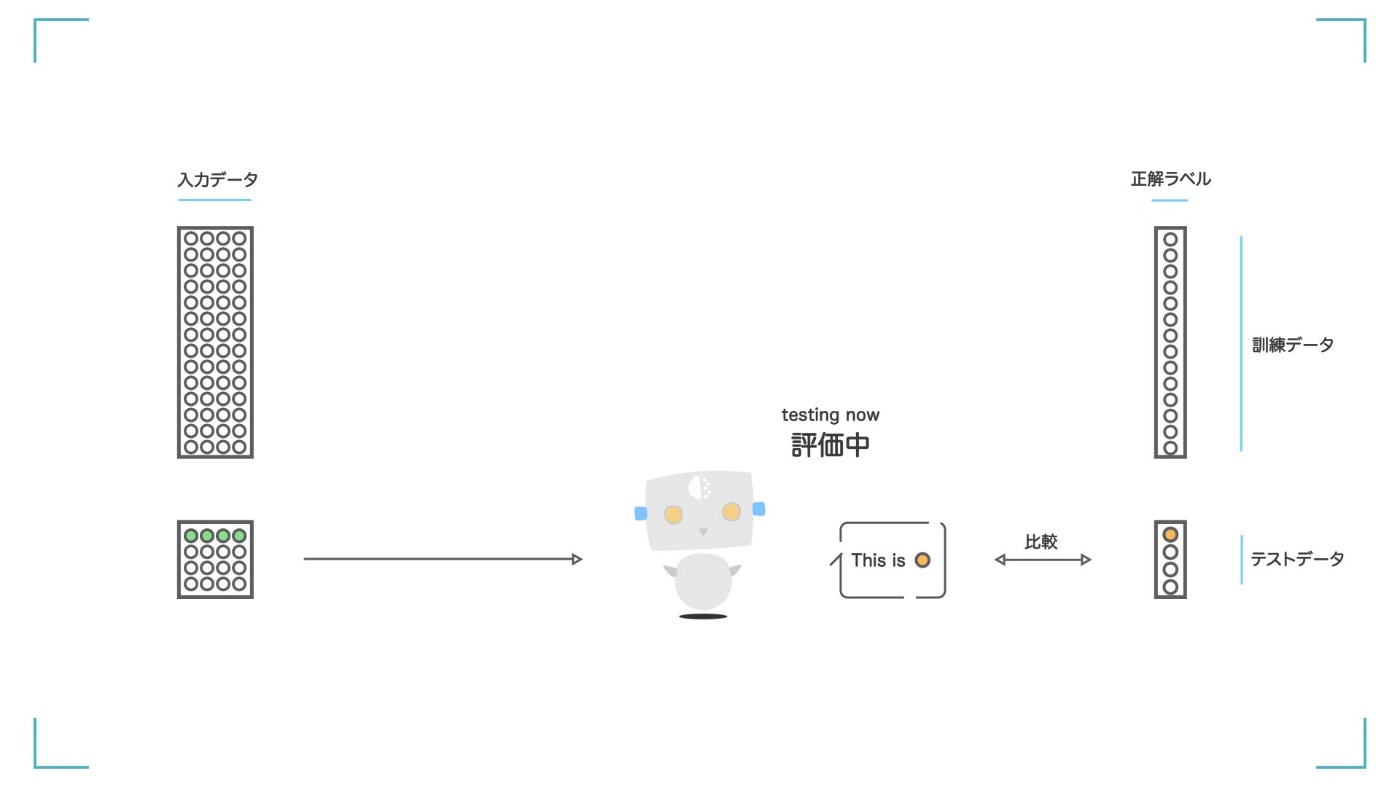
STEP④ テストデータを使って評価を行う
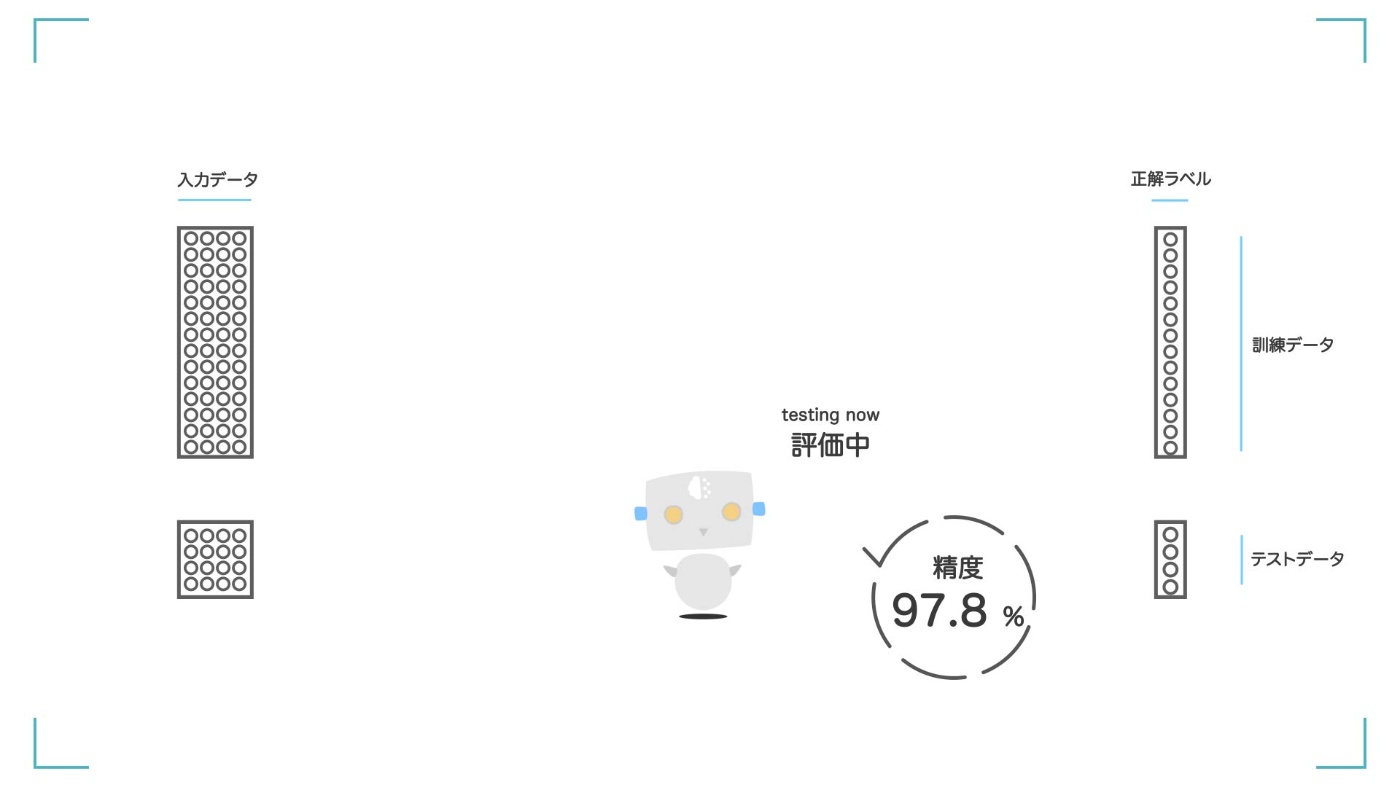
STEP⑤ 評価の結果が出てくる
全部で 150 個あるデータを【訓練データ】と【テストデータ】に分けます。train_test_split 関数を使うと、簡単に分けることができます。
# Split the dataset
data_train, data_test, target_train, target_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=0)
引数として、先ほどの【iris.data】と【iris.target】を渡します。test_size=0.2 とすることで、全体の何%を【テストデータ】として使用するかを決めることができます。
今回は 20%なので、【訓練データ】= 80%(120 個)、【テストデータ】= 20%(30 個)としました。結果は、data_train, data_test, target_train, target_test という 4 つの変数に入れられました。
図解
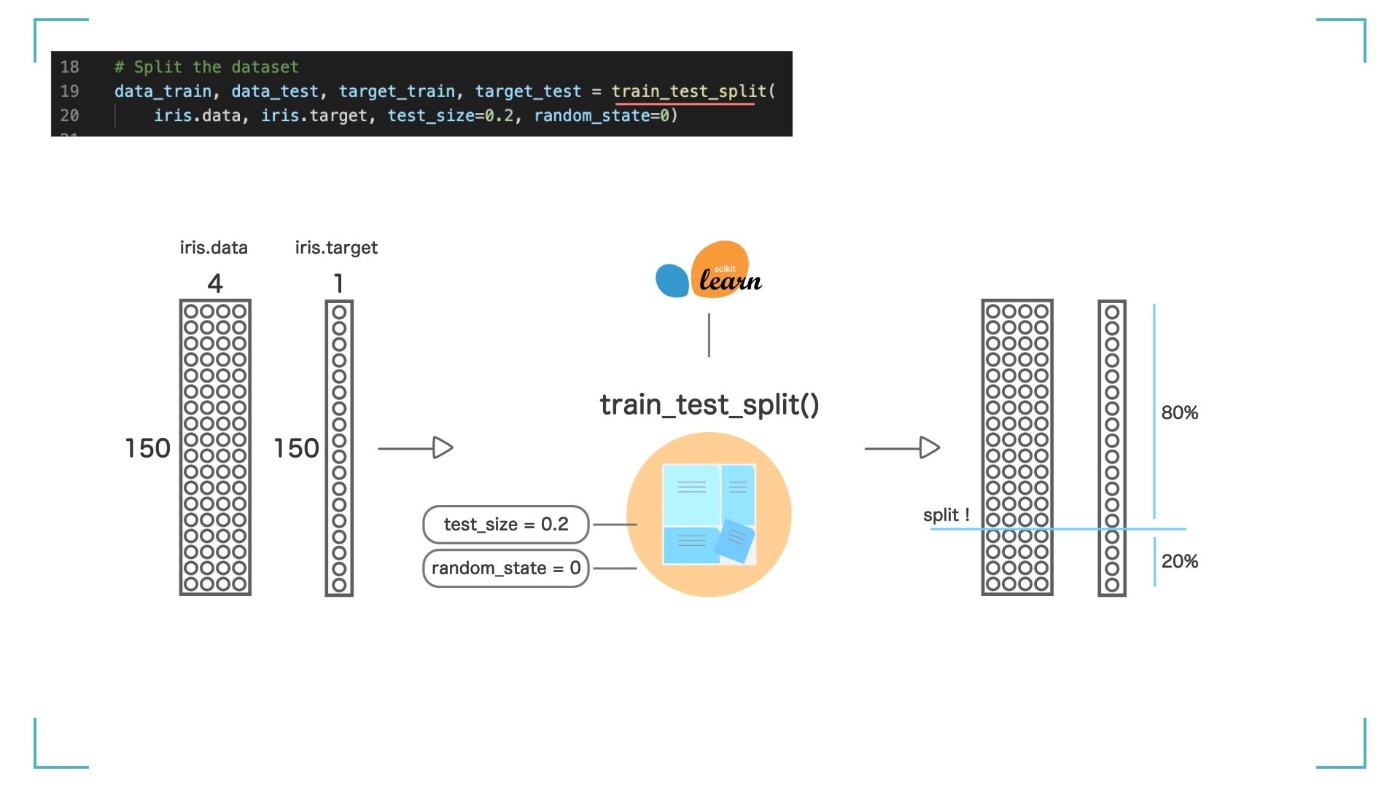
train_test_split()関数を使って、、
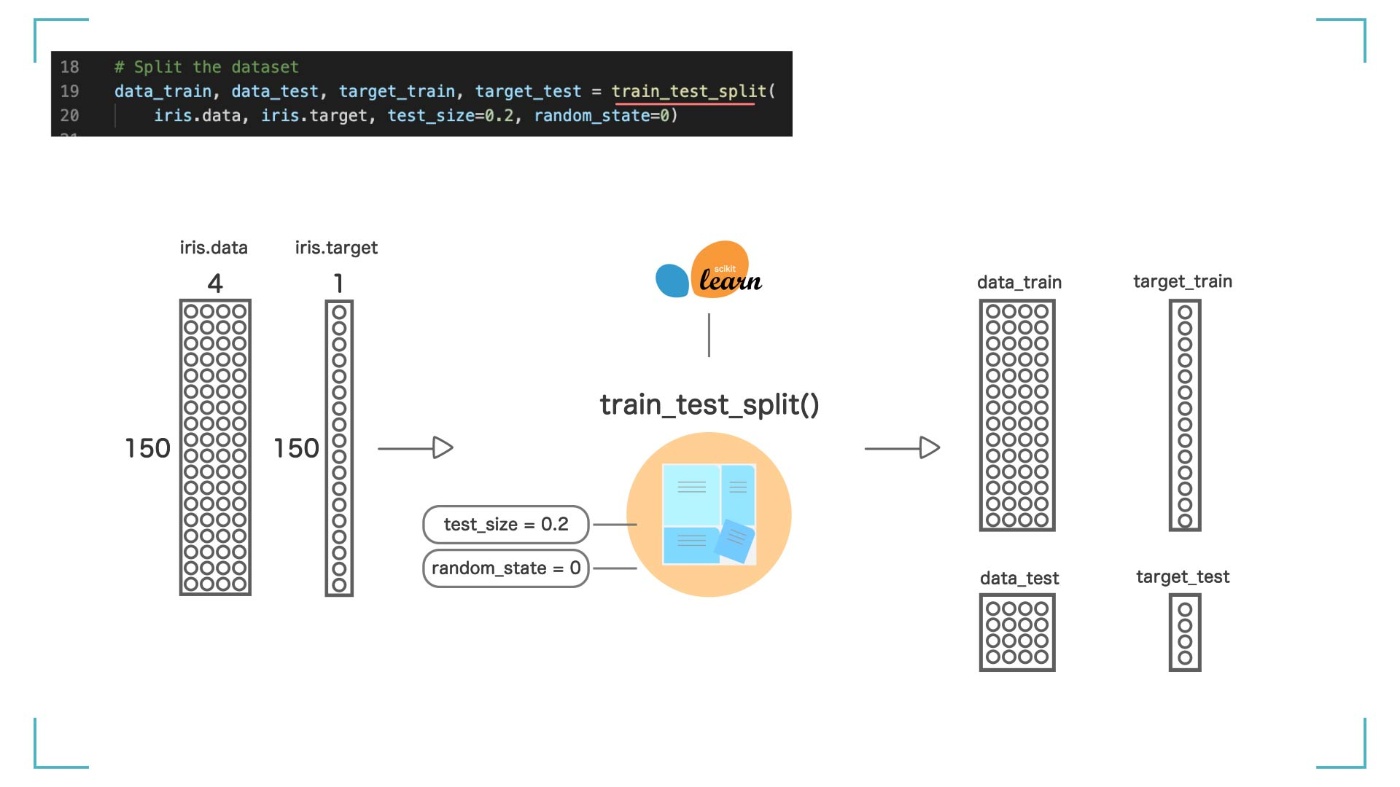
訓練データ(data_train, target_train)とテストデータ(data_test, target_test)に分ける

Step2 のまとめ
Step3: モデルの作成
さて、データの準備ができたので、いよいよ人工知能(機械学習モデル)を作っていきます。今回は、ニューラルネットワーク(Sklearn.neural_network)というアルゴリズムをつかいます。アヤメの花の種類を予測する【分類問題】なので、MLPClassifier を使います。
# Define Neural Neowork model
clf = MLPClassifier(hidden_layer_sizes=10, activation='relu',
solver='adam', max_iter=1000)
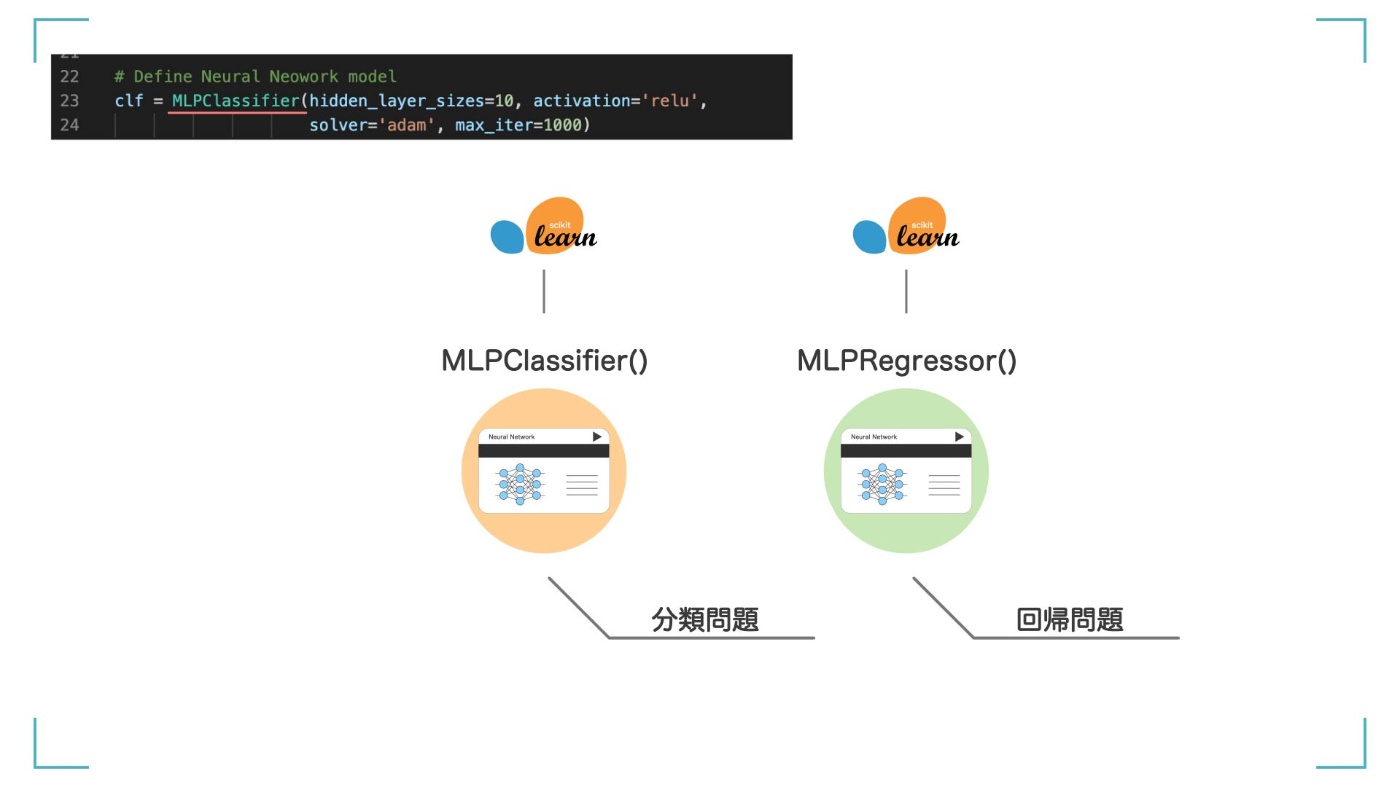
今回は分類問題なので、MLPClassifier を使う。開基問題の場合は MLPRegressor を使う。
MLPClassifier って何?
MLPClassifier は以下のような意味です
- MLP =多層パーセプトロン(MultiLayer Perceptron)
- Classifier =分類器
ニューラルネットワークって何?
ニューラルネットワークを簡単に説明します。入力層に学習データ(ここではアヤメの情報)を入力すると、入力層 → 中間層 → 出力層を通りながら勝手にいろいろ計算をします。
何回も計算(学習)することで正解ラベル(ここではアヤメの品種 0,1,2)との誤差を小さくしていき、最終的に良い感じの予測結果が出力層に出てくるというアルゴリズムです。

ニューラルネットワークとは?
ニューラルネットワークをもっと詳しく知りたい方は、初心者向けの記事と動画を上げていますので、よければご覧ください。
clf = MLPClassifier()とすることで、【clf】という名前でニューラルネットワークのモデルの枠組みを作成します。この【clf】が人工知能(機械学習モデル)そのものになります。AI エンジニアが使う難しい言葉で言うと、ここで【インスタンス化】をしています。分からなくても大丈夫です。
clf って何?
clf は Classifier(分類器)の略です。
しかし、これだけでは【clf】はまだ何もできません。AI とは言えない、ただの箱です。そこで、MLPClassifier()に、いくつか引数を渡すことで、いろいろな設定をすることができます。モデルにオプションを付けて、自分好みにカスタマイズできるってことです。
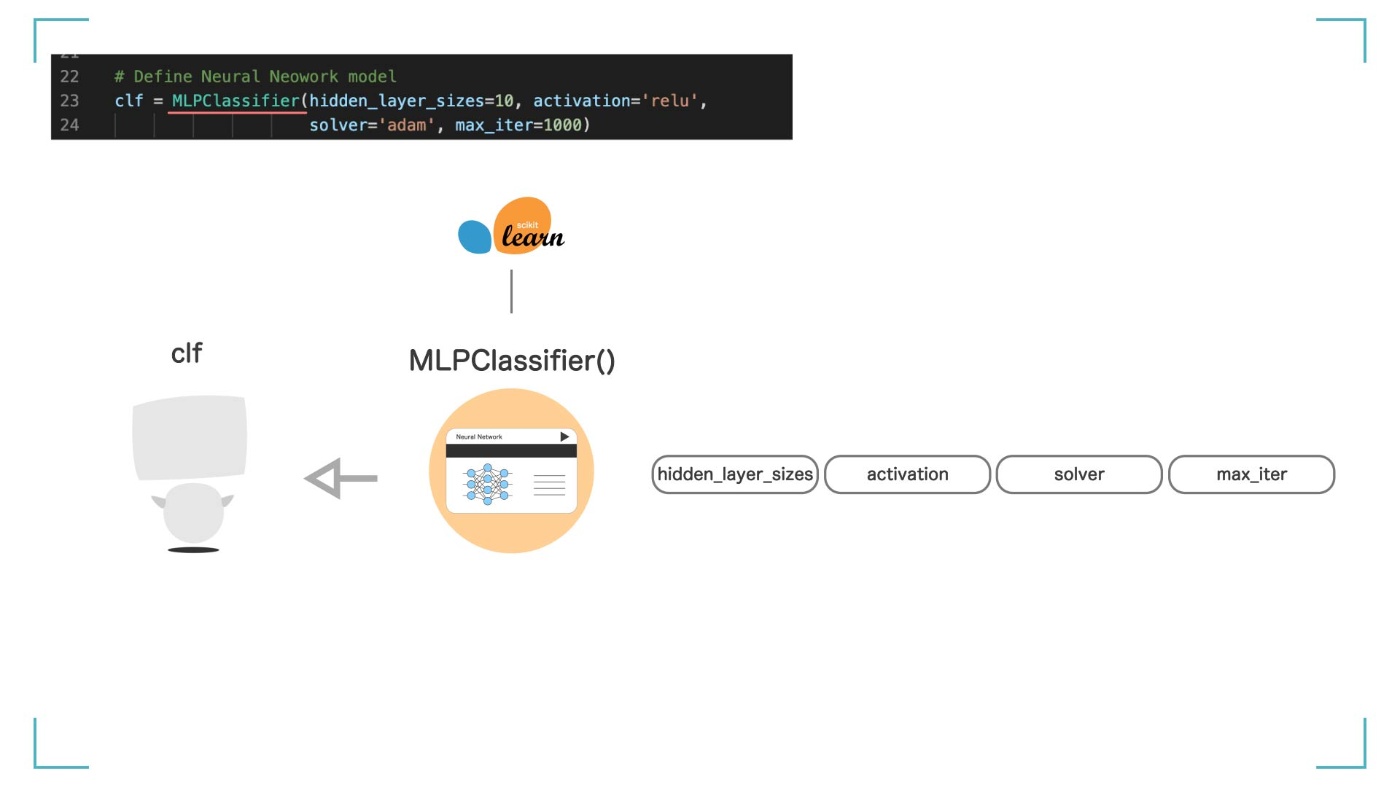
4 つの引数を設定することで、モデルをカスタマイズしている
ここでは、4 つの引数を渡しています。それぞれ説明していきます。
引数 ① hidden_layer_sizes
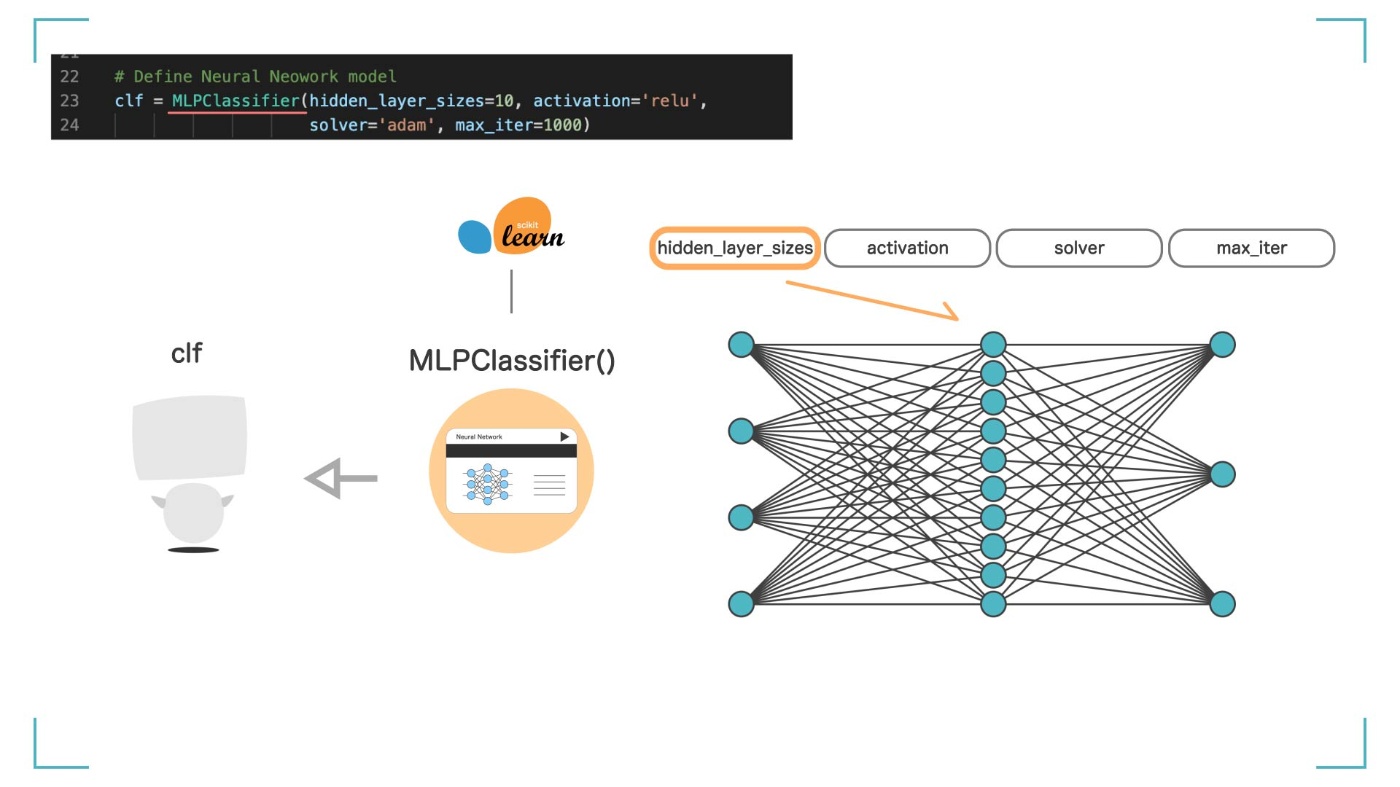
引数 ① hidden_layer_sizes
hidden_layer_sizes では、ニューラルネットワークの中間層(隠れ層)のニューロンを何個にするかを決めます。値が大きければ精度は上がります。今回は hidden_layer_sizes=10 とします。
引数 ② activation
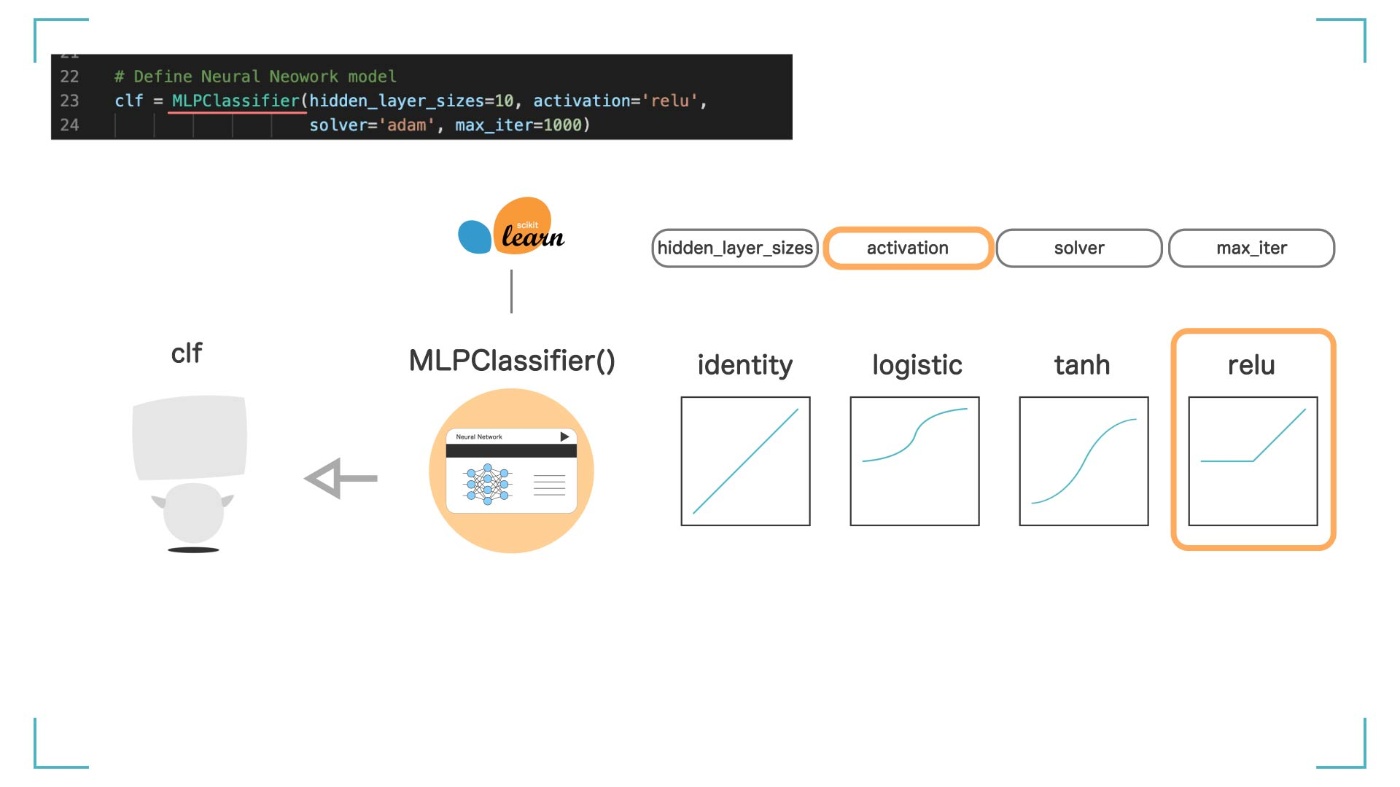
引数 ② activation
activation では、活性化関数に何を使うかを決めます。‘identity’, ‘logistic’, ‘tanh’, ‘relu’の 4 つの中から選ぶことができますが、今回は人気でシンプルな'relu'という活性化関数を使います。
引数 ③ solver
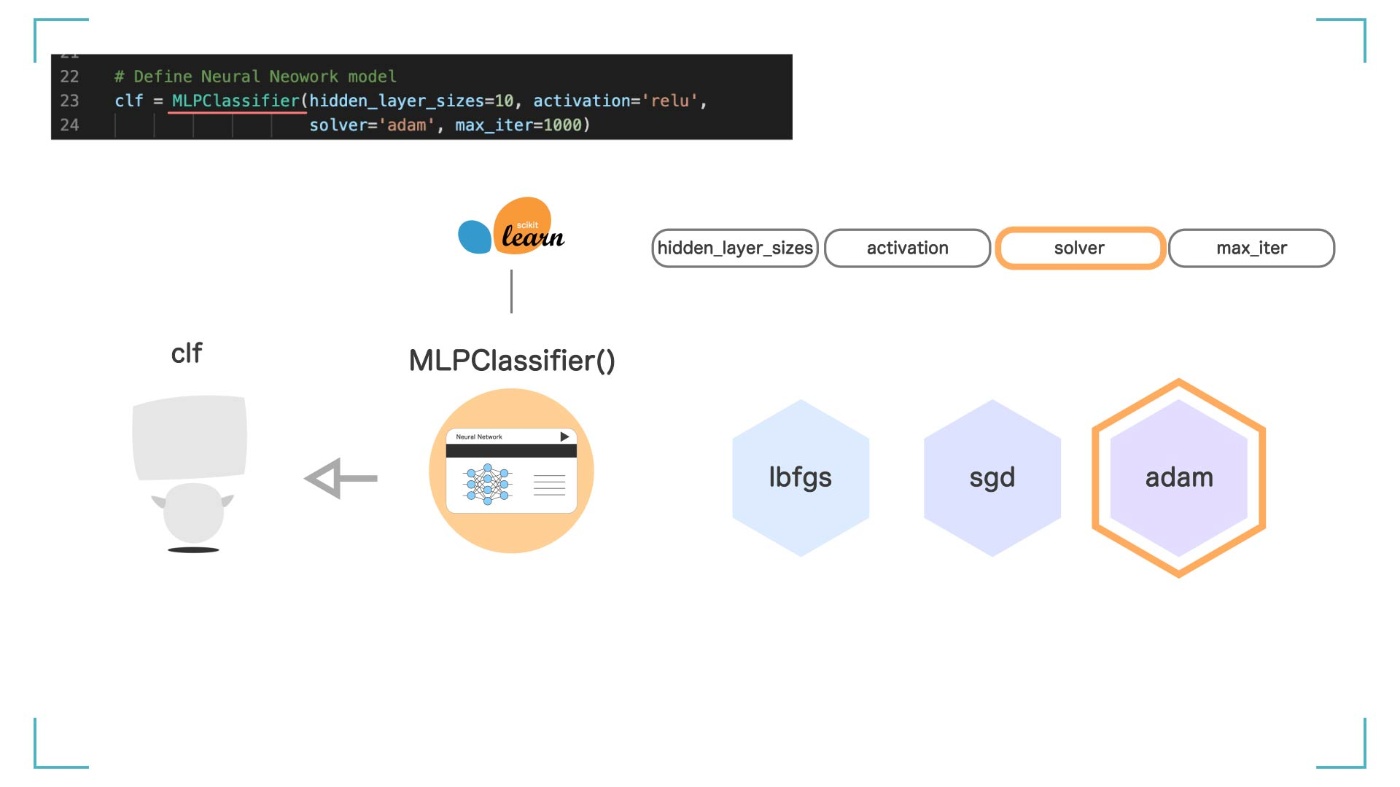
引数 ③ solver
solver では、最適化の手法に何を使うかを決めます。‘lbfgs’, ‘sgd’, ‘adam’の 3 つの中から選ぶことができますが、現在最も評価されている手法である'adam'という手法を使います。
引数 ④ max_iter
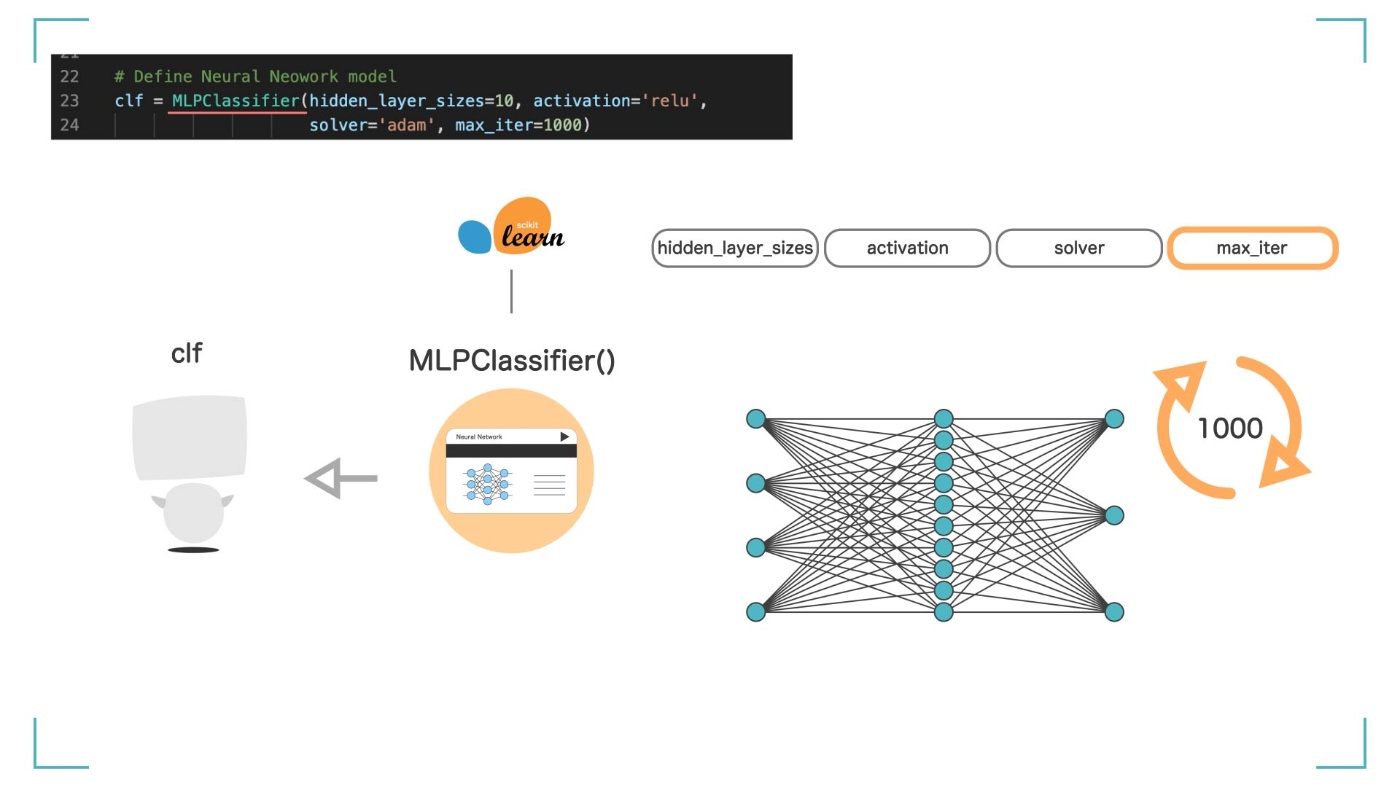
引数 ④ max_iter
max_iter では、繰り返し回数を決めることができます。値が大きければ精度は上がります。今回は max_iter=1000 とします。
今回はこの 4 つを設定して、AI を作ります。
今回設定した 4 つ以外にも,,,
今回設定した 4 つ以外にも、MLPClassifier()では、全部で 23 個の設定をカスタマイズすることができます。自分の好きなようにカスタムしてみてください。
23 の設定ができる

Step3 のまとめ
Step4: モデルを学習させる
さて、ようやくモデルができました。次はいよいよ学習です。学習といっても、とても簡単で、clf.fit(data_train, target_train)の1行で完了します。fit 関数はモデルの学習を実行する関数です。引数として【訓練データ】を渡すことで、勝手に学習してくれます。
# Lerning model
clf.fit(data_train, target_train)
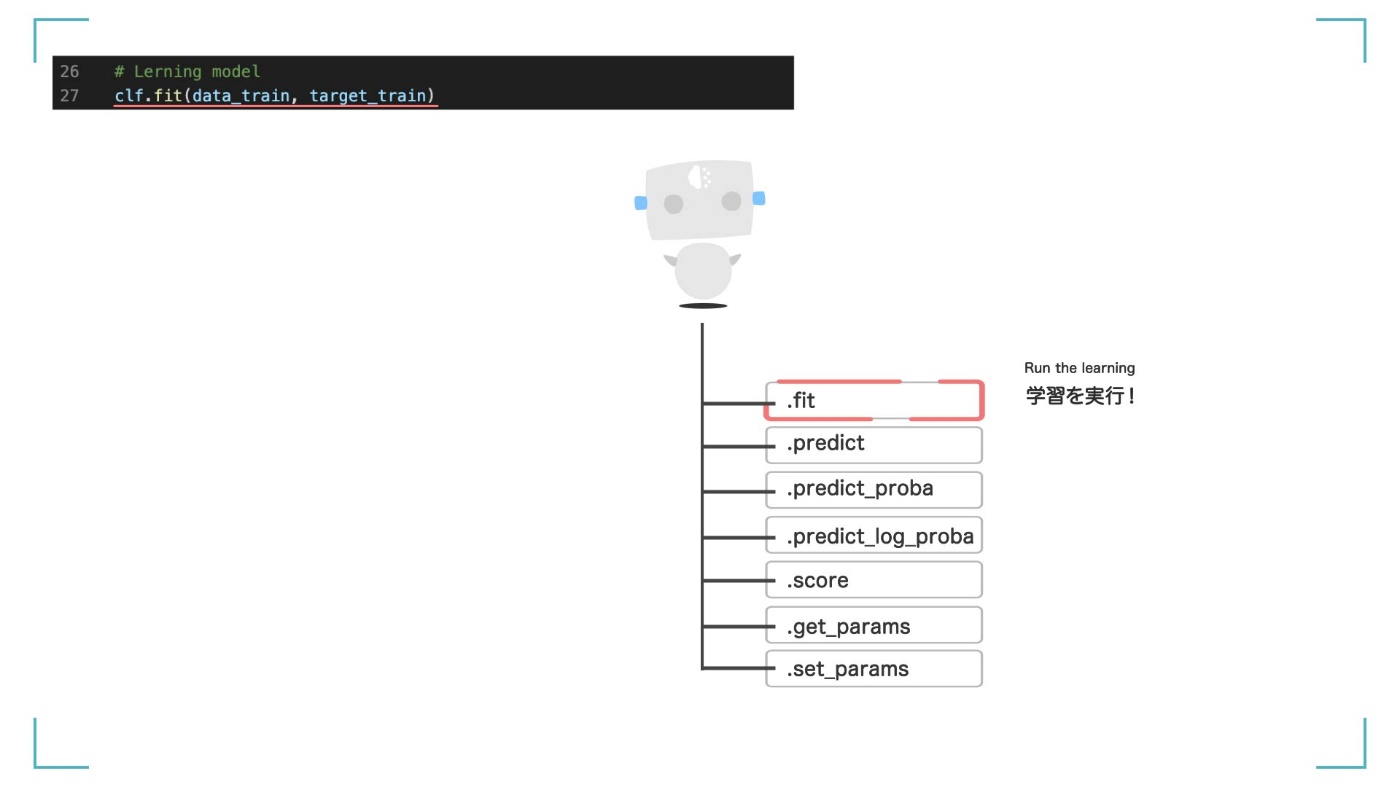
fit 関数はモデルの学習を実行する関数
この fit()を実行する前と、終わった後では、【clf】の中身が書き換わって、違うものになっています。見た目は同じ【clf】という箱ですが、ただの箱から、人工知能へと進化しています。

fit()で学習したら

clf が学習済み状態になる
さて、いま作った人工知能がどれくらい賢いのかを確認していきます。score 関数を使って精度を出します。
# Calculate prediction accuracy
print(clf.score(data_train, target_train))
0.975
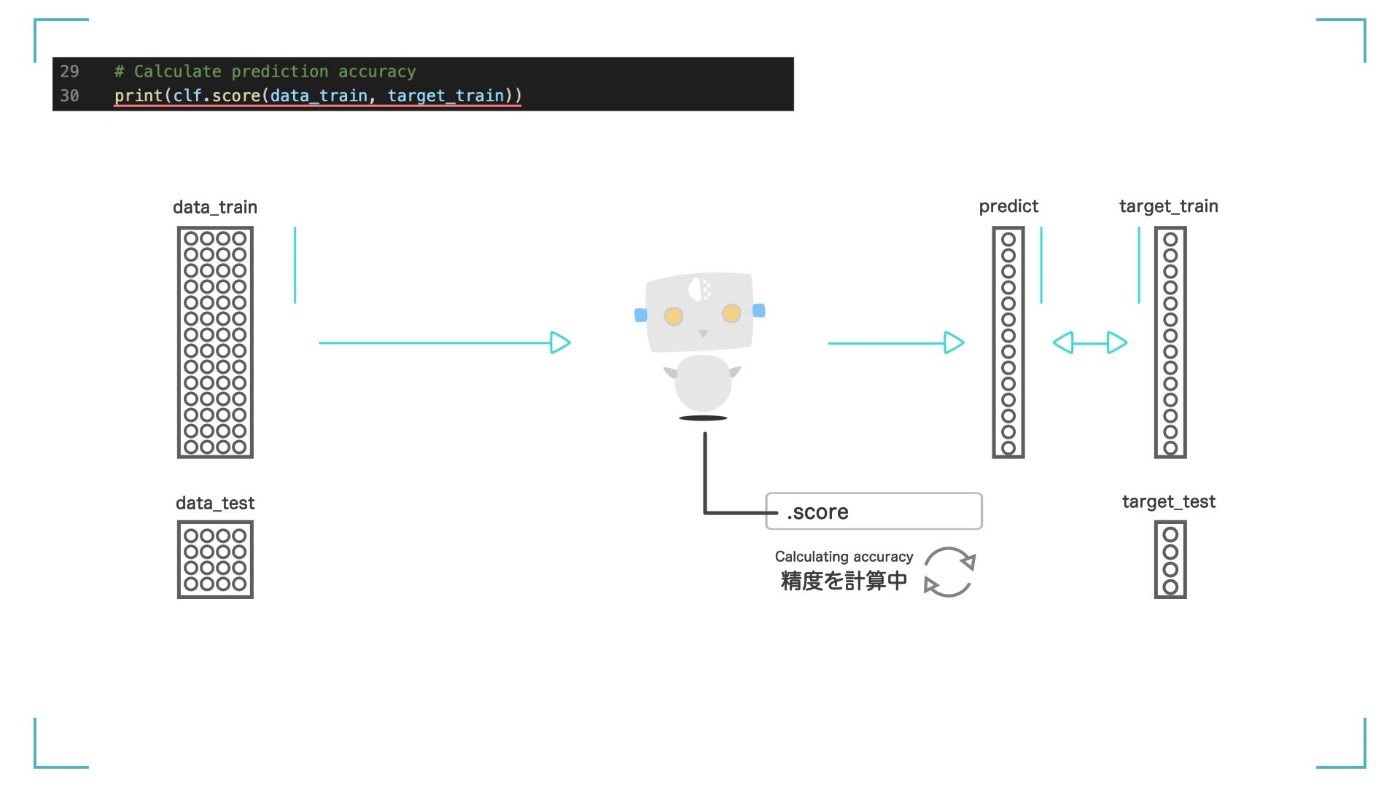
score 関数を使って、モデルの精度を計算
結果は【0.975】 つまり、97.5%の精度でアヤメの品種を分類できていることになります。もし 100 個のデータを見せたら、3 つくらいは間違えちゃうってことです。でも、95%を超えているのでなかなか良いスコアです!
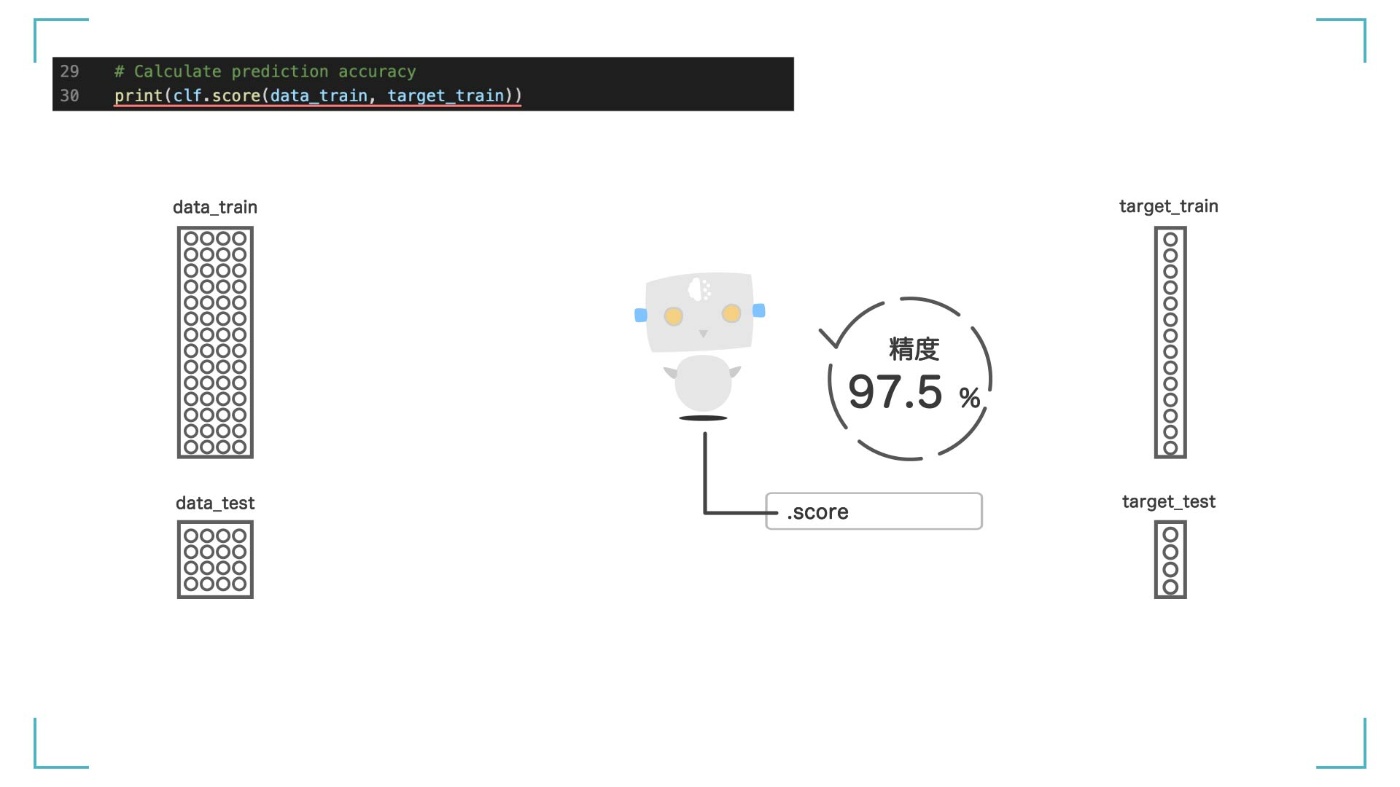
97.5%という結果が出てきた
ただ、このスコアはあくまで、学習した【訓練データ】をどれだけ分類できるかという数値です。何回も学習したデータに対してのスコアなので、高スコアで当然です。本当に知りたいのは、【学習に使っていないテストデータでは、どれだけ正しく予測することができるか】というスコアです。

Step4 のまとめ
Step5: 予測
predict 関数を使って予測をします。ここで登場するのが、さっき用意しておいた【テストデータ】の【data_test】と【target_test】です。
引数として渡すのは、【data_test】です。テストデータ【data_test】だけを人工知能に見せて、正解ラベルの【target_test】の値を正しく予測できるかを確認します。
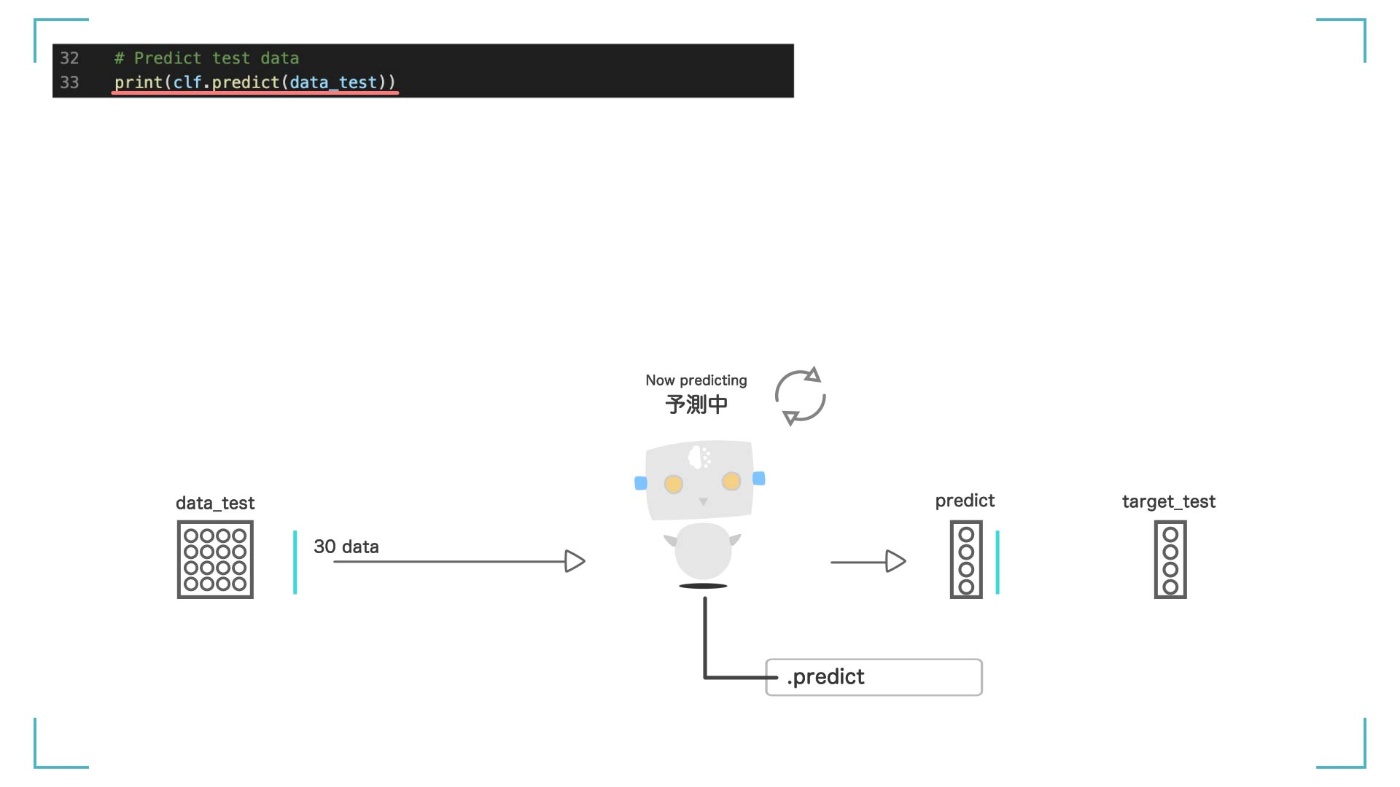
predict 関数を使ってテストデータの予測
# Predict test data
print(clf.predict(data_test))
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 2 0 0 2 0 0 1 1 0]
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 2 0 0 2 0 0 1 1 0]のように出てきました。これは、人工知能に渡した【data_test】の 30 個のデータがどの品種と予測されたかの結果です。正解ラベル【target_test】と比較してみましょう。
print(target_test)
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1, 0, 0, 2, 0, 0, 1, 1, 0])
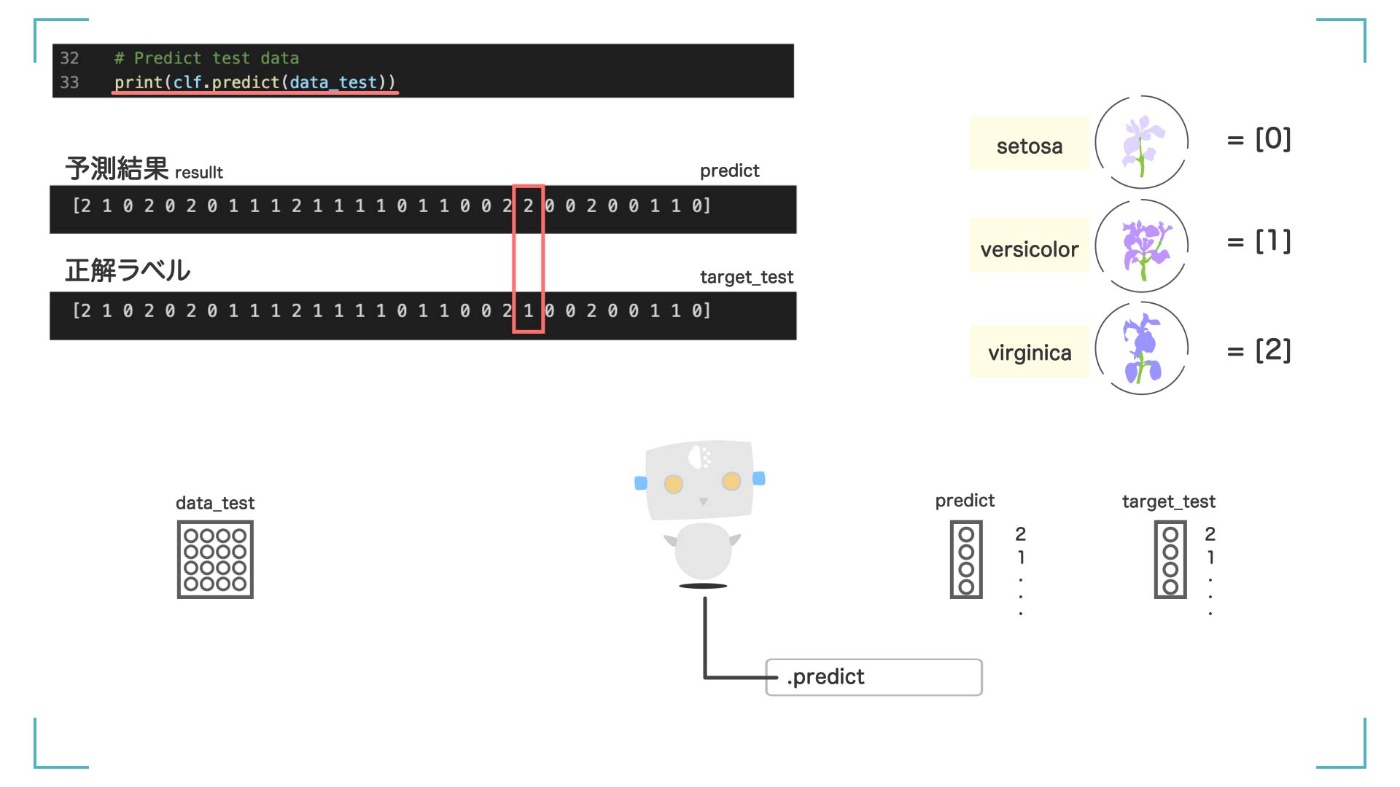
予測結果と正解ラベルを比較
比較すると、22 番目が違います。本当は 1 のところが、2 に分類されてしまっています。おしいですね。
しかし、今まで一度も見せていないデータをここまで正しく分類できるのは、AI っぽいですね。しかも、人工知能には【データを渡しただけで自分で学習してくれる】ので、魅力的です。

Step5 のまとめ
Step6: 学習過程の表示
最後に、AI が学習をしている最中の状態を可視化してみます。clf.loss_curve_には学習中の損失の値(Loss)が配列として入っています。
損失(Loss)とは?
損失とは、不正解の割合みたいなものです。正確には異なりますが、この値を小さくすることで、AI の精度がよくなっていきます。
print(clf.loss_curve_)
[1.3079614069226488,
1.290595120396943,
1.2735468633194589,
,
,
(1000回分のLoss)
,
,
0.1744929329385299,
0.17422939487479655,
0.1739668447807053]
学習を繰り返すたびに、その時の Loss 値を clf.loss_curve_に入れていきます。今回は、max_iter=1000(学習を 1000 回繰り返す)としたので、clf.loss_curve_ には 1000 個の損失値が入っています。
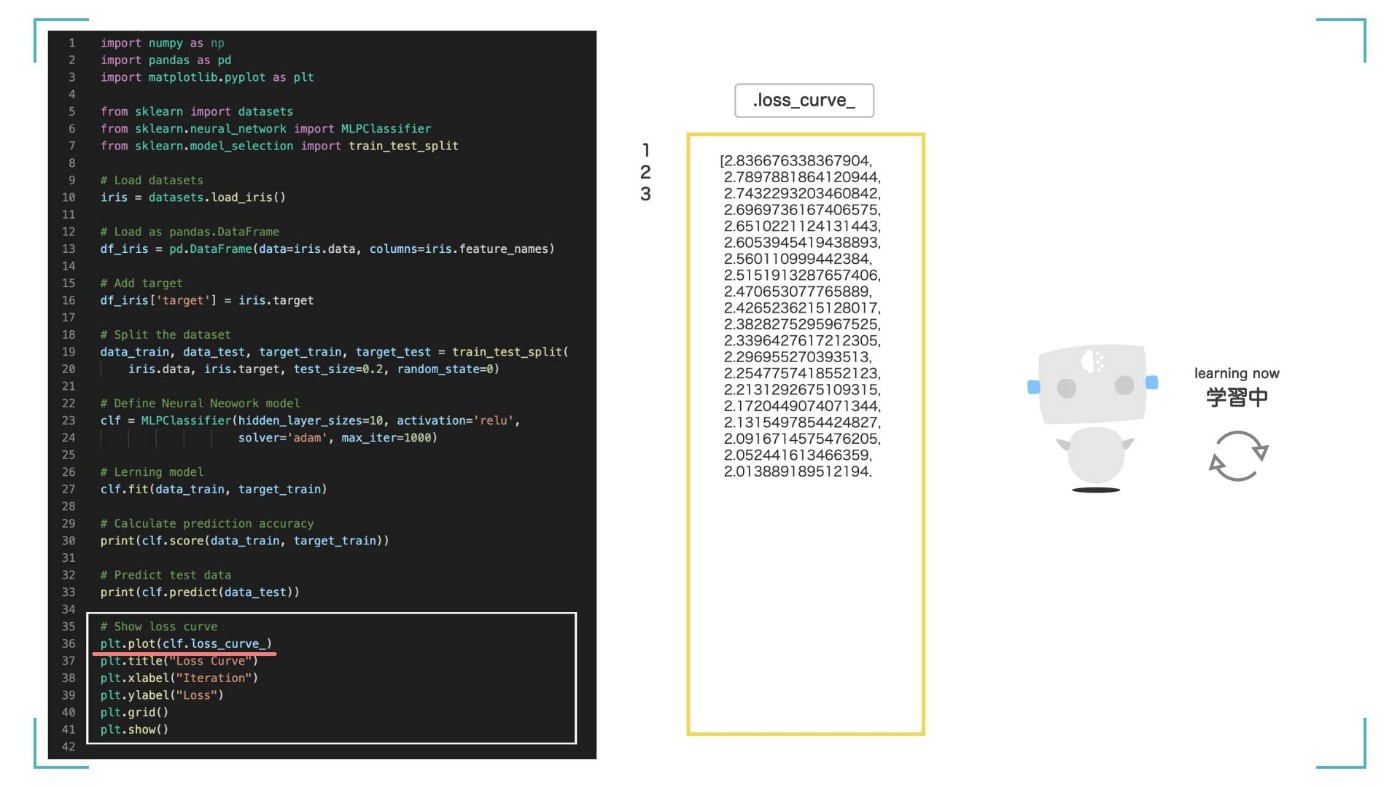
学習を繰り返すたびに、その時の Loss 値が入る
matplotlib というライブラリを使うことで簡単に図を作ることができます。
# Show loss curve
plt.plot(clf.loss_curve_)
plt.title("Loss Curve")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.grid()
plt.show()

学習の過程。だんだん精度が良くなっている。
結果はこのようになります。学習が進むにつれて、Loss がだんだん小さくなっていることがわかります。AI が学習している過程が見れると、どこで行き詰まっているのかも把握することができて便利です。

Step6 のまとめ
まとめ
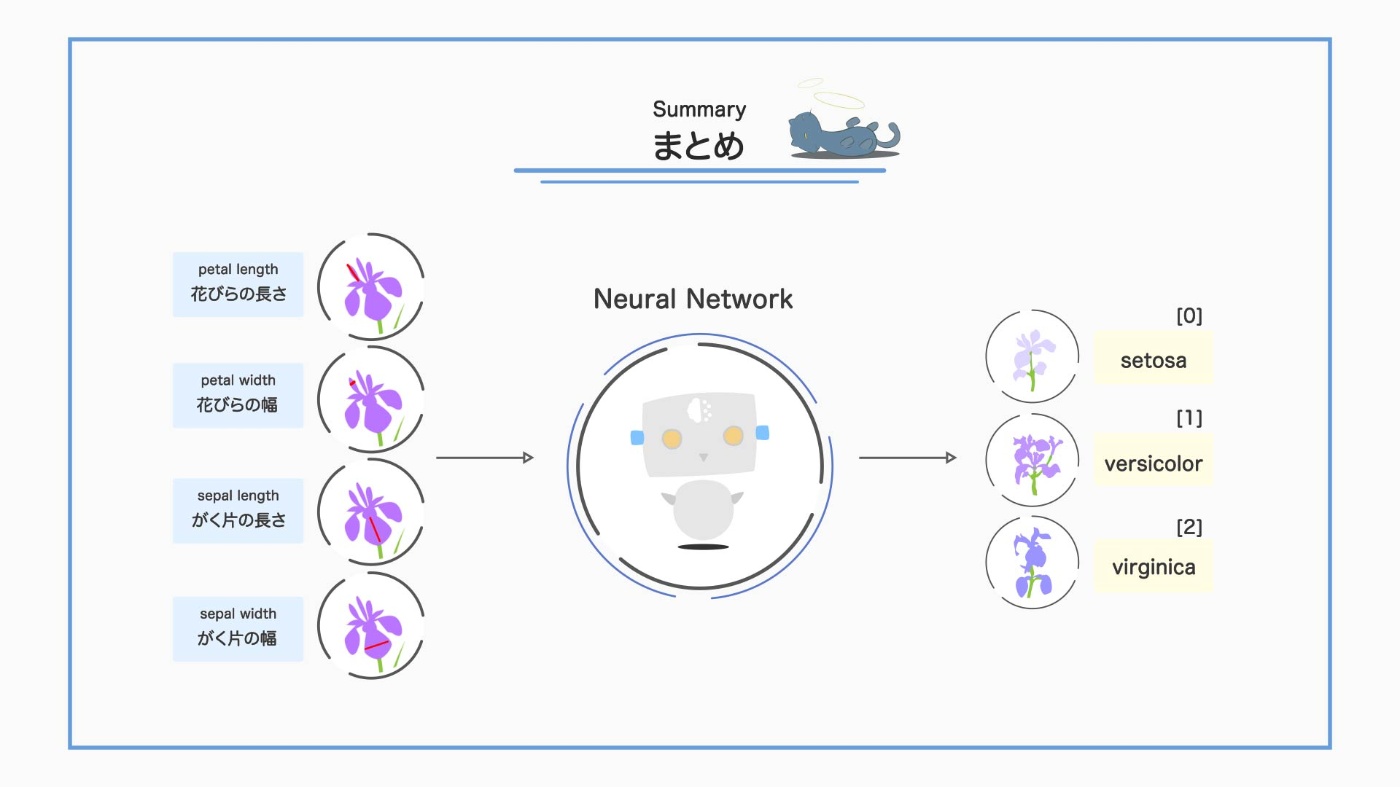
今回のまとめ
今回は、scikit-learn の Neural Network を使ってアヤメの品種を分類する簡単な AI を作ってみました。結果として、精度 90%超えの【アヤメ分類 AI】を作ることができました。
また、実際に学習させるのはとっても簡単で、むしろデータの準備の方に時間がかかることもわかったと思います。データの質は AI の質に直結するので、注意しましょう。
少しでもみなさんの理解が進んだなら嬉しいです。質問などありましたらコメントよろしくお願いします。
ニューラルネットワークについてもっと詳しく知りたいかたは、こちらも併せてご覧ください。
なお、この記事の内容は YouTube で動画にもしています。併せて見ていただくと嬉しいです。
人工知能/AI/機械学習をもっと詳しく
ねこアレルギーの AI
YouTube で機械学習について発信しています。
お時間ある方は覗いていただけると喜びます。
Created by NekoAllergy
Discussion
分類する花の種類を増やしたい場合はどのようにすれば良いですか?
コメントありがとうございます!
花の種類を増やすためには、自身でデータセットを作成する必要があります。今回の
(150, 4)のデータに対して、(150, 5)のように1列追加するイメージです。教師ラベル
targetも併せて追加します。(ラベル3を加えるイメージです)これらのデータは'numpy.ndarray'型のため、比較的簡単に修正できると思います。詳しくはぜひ調べてみてください。
とても興味深かったです。
これを応用していけば、もっとすごいのできますか?
コメントありがとうございます!
自然言語処理、画像認識、音声認識、自動運転など、さまざまな分野に応用することができます。今回は超基礎的な内容ですが、データの準備、学習、推論などの流れは変わりません。
ぜひ勉強してみてください。
すっごくわかりやすかったです。ほかのページもいろいろ見させていただきます
とっても嬉しいコメントありがとうございます!他の記事も見ていただけると喜びます!