この記事は Panda株式会社 Advent Calendar 2023 1日目の記事です。
Panda株式会社は東京大学松尾研究室・香川高専発のスタートアップで、AR技術とAI技術を駆使したシステム開発と研究に取り組んでいます。
このアドベントカレンダーでは、スタートアップとしての知見、AI・AR技術、バックエンドなど、さまざまな領域の記事を公開していきます。
自己紹介
Panda株式会社でAIに関すること全般を担当している仲地です。
普段は筑波大学で情報検索分野の研究をしている博士前期課程の1年です。
はじめに
この記事の想定読者は以下の通りです。
- 想定読者:製品マニュアルを用いた質問応答に興味がある人
- Required: 独自文書を用いた質問応答(例:独自文書を用いてカスタムチャットbotが作成できるGPTs)に興味がある人
- Preferred: マルチモーダル大規模言語モデルについてある程度知識がある。あるいは質問応答分野についてある程度知識がある。
2023年11月06日にOpenAIから独自のカスタムチャットbotを作成できるGPTsが発表されましたが、
この記事では、AAAI2023に採択された製品マニュアルを対象としたマルチモーダル質問応答に関する論文を紹介します。以下に紹介する論文の情報を記載します。
| タイトル | MPMQA: Multimodal Question Answering on Product Manuals |
| 著者 | Liang Zhang , Anwen Hu , Jing Zhang, Shuo Hu , Qin Jin |
| 採択会議 | AAAI 2023 |
| 論文リンク(ACM) | https://dl.acm.org/doi/abs/10.1609/aaai.v37i11.26634 |
| 論文リンク(arXiv) | https://arxiv.org/abs/2304.09660 |
この論文がやったこと
- MPMQA(Multimodal Product Manual Question Answering)という製品マニュアルに関するマルチモーダルなコンテンツへの理解が必要な質問に回答するタスクの提案
- 「PM209」というMPMQAデータセットの構築
- MPMQAタスクを解くモデルのURA(Unified Retrieval and Question Answering)を提案
MPMQA(Multimodal Product Manual Question Answering)
まず、従来のPMQA(Product Manual Question Answering)について説明します。PMQAは、製品マニュアルに含まれる情報を利用して、ユーザーの質問に回答するタスクです。このタスクの目的は、製品マニュアル内のテキスト情報を適切に処理し、ユーザーの問い合わせに対して適切な回答を提供することにあります。しかし、従来のPMQAでは主にテキスト情報に焦点を当てており、イラストや表、画像などの視覚的なコンテンツは無視されがちでした。
この論文が提案したMPMQAタスクにおいては、これらの課題点が考慮され、よりリアルなユーザーシナリオを想定してタスクの設計が行われています。

上記の画像は紹介論文中のFigure1で示されている、MPMQAのQAペアの例です。このQAペアでは、「How to take a selfie in the Selfie Count Down mode?(日本語訳 by ChatGPT:セルフィーカウントダウンモードでのセルフィーの撮り方は?)」というジェスチャーを認識するカメラでの自撮りの撮り方の質問が示されてます。この質問に対して、テキストのみで、正解のジェスチャーを説明すると、「人差し指と親指でアルファベットのLを作るようにして、あなたの顔を切り取るように…」のようになってしまい、変に複雑になってしまいます。このような場合では、画像でジェスチャーを示せるとシンプルに回答できます。
また、既存のマルチモーダル質問応答においては、単一のWebページやinfographicなどから回答を導き出すことに焦点を当てています。しかしながら、製品マニュアルにおいては、その文書の性質上、数十程度のページ数で構成されていることが多いです。このうち、質問に対してほとんどのページは不適合なページなっています。この点を考慮し、MPMQAにおいては、ある製品マニュアルに対する質問に対して回答を出力するタスクを、①ある製品マニュアルに対する質問から、適合するページを取得するPage Retrievalと②質問と、それに適合するページからマルチモーダルな回答を出力するMultimodal QAの2つのサブタスクに分割しています。
以上のように、MPMQAタスクは、従来のPMQAタスクにおけるテキスト情報のみに焦点を当てたアプローチを進化させ、視覚的コンテンツも統合している点と、従来のマルチモーダル質問応答と異なり複数ページから回答の生成を求める点が、製品マニュアルの質問応答として実際のユースケースに適したタスク設計になっています。
「PM209」データセットの構築
筆者らは、先ほど説明したMPMQAタスク用データセットの構築も行なっています。
このデータセットの特徴は以下のようになっています。
- 27の著名な消費者電子ブランドの209の製品マニュアルで構成
- 製品マニュアルの長さ:10~500ページ。平均は50ページ
- 製品カテゴリ:90種類
- 製品マニュアルの全てのページに対して、意味領域(≒テキストとテキストに対応する座標のペア)のラベルをアノテーション。ラベルは以下。
- Text:製品に関する情報を提供するテキストで構成された段落。
- Title:ページ全体や近くの段落をまとめたテキスト。
- Product image:マニュアル内の製品に関連する画像。
- Illustration:製品の特定の機能や操作、目的を視覚的に説明する領域。
- Table:テキスト情報を行と列の形式で伝える領域。
- Graphic:製品コンポーネントの名前と位置を示すvisually-richな領域。
- 上記の製品マニュアルに対して22,021のQAペアが含まれる
- 各質問はマルチモーダルな回答が必要になるように作成されている
- 回答のテキスト部分はアノテータが記述し、画像部分は製品マニュアルから抽出された意味領域をアノテータが選択する
- より実際の製品マニュアルFAQのようなシナリオに近づけるため、質問は一人称の文章で、回答は二人称の文章で記述
既存のPMQAとの統計情報を比較した表が以下のようになっています。この表から分かるように、PM209は既存のPMQAタスクのデータセットと異なり、大規模かつマルチモーダルなコンテンツへの回答が求められるようになっています。

提案モデル:Unified Retrieval and Question Answering(URA)
この論文ではタスクの提案とデータセットの構築だけではなく、タスクを解くモデルの提案も行なっています。モデルはUnified Retrieval and Question Answering(URA)と呼ばれ、前述のサブタスク①Page Retrievalとサブタスク②Multimodal QAをそれぞれを解くように分かれています。
以下がURAの概要図となっています。
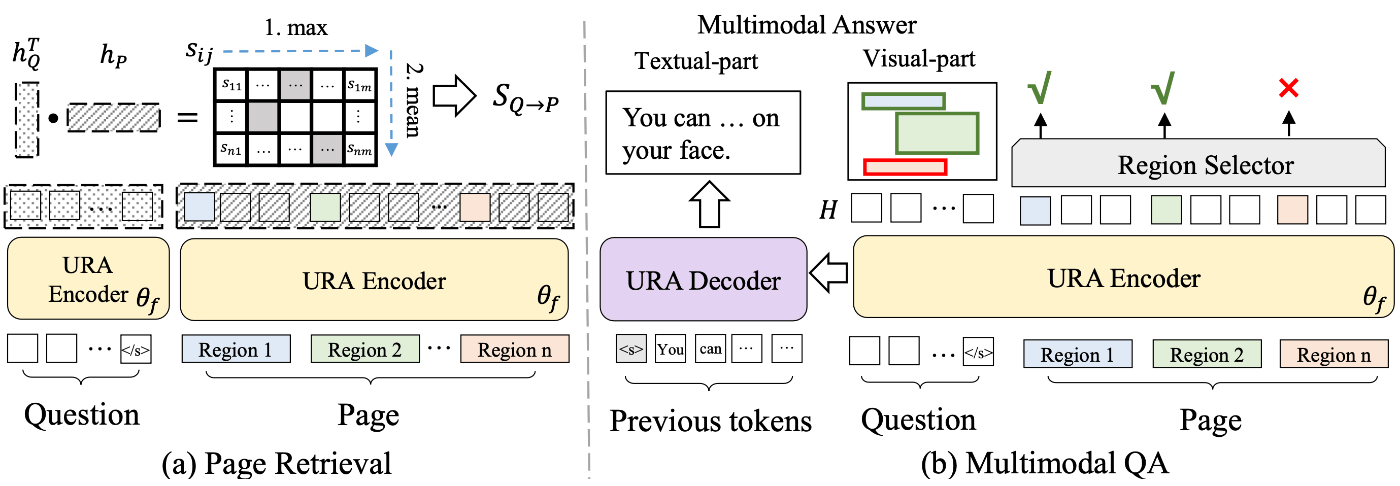
この図中の左側でサブタスク①Page Retrieval、右側でサブタスク②Multimodal QAの解き方が示されています。
URAにおいて主要なコンポーネントは以下の3つです。
- URA Encoder:TransformerベースのEncoderです。テキスト・画像・位置の埋め込み足したものを入力として受け付けます。出力は(系列長, 埋め込み次元数)の埋め込み表現です。
- URA Decoder:TransformerベースのDecoderです。Autoregressiveなテキスト生成モデルで、URA Encoderが出力する埋め込み表現とのインタラクションがあります。
-
Region Selector:URA Encoderが出力する埋め込み表現を線形変換し、意味領域
r_i
①Page Retrieval
「ページ単位で埋め込み表現を作成し、質問の埋め込み表現と似たページの上位
②Multimodal QA
Page Retrievalで取得されたページに対して、それぞれ質問を結合しURA Encoderに入力を行います。そして得られた埋め込み表現
以上のようにしてURAはMPMQAタスクを解きます。
URAの評価実験
論文中では、URAがPM209データセットに対して有効か検証する評価実験についても言及されていました。
ただし、タスクを新しく提案した論文であるため、他の論文が提案した手法との比較というような評価実験ではなく、自身が提案したモデルのAblation Studyのような実験が行われていました。比較したモデルは以下となっています。
評価実験のうち、以下のベースラインと提案モデルを比較した実験結果についてだけ、この記事では紹介したいと思います。
-
\text{PR} -
\text{PR}_g \text{PR} -
\text{PR+TA} \text{PR} -
\text{PR}_{g}\text{+TA} \text{PR}_g -
3 \space \text{Single} -
\text{URA}
実験結果は以下のようになっています。
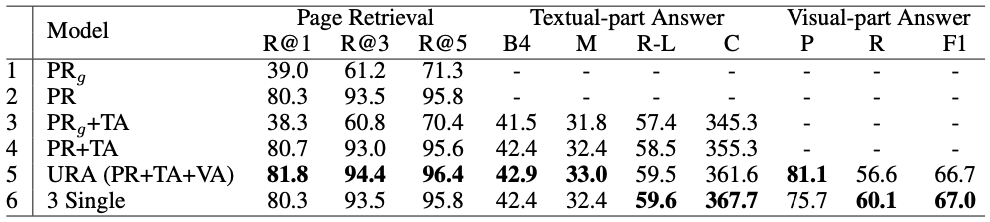
この実験結果から、以下のようなことが実験結果として言及されていました。
- 共通のEncoderに基づくPage Retrievalは、独立したEncoderに基づいたものよりも、効果が低い。
- テキスト回答(
\text{TA} \text{PR}_g -
\text{TA} \text{PR} \text{PR} -
\text{URA} \text{VA} \text{TA}
この論文を読んでのまとめと感想
論文のまとめは以下です。
- MPMQA(Multimodal Product Manual Question Answering)という製品マニュアルに関するマルチモーダルなコンテンツへの理解が必要な質問に回答するタスクの提案
- 「PM209」というMPMQAデータセットの構築
- MPMQAタスクを解くモデルのURA(Unified Retrieval and Question Answering)を提案
この論文を読んだ感想としては以下の通りです。
- (感想)この論文が提案したタスクが実際の製品マニュアルのユースケースに近い
- 製品マニュアルだと、図を用いた説明があったりするので、これを明示的に考慮しなければ解けないという点が実用的だと思いました。
- 製品マニュアル以外にも、作業手順書などは図を用いた説明が多いので、作業手順書のような場合でも似たようなデータセットが作成できそうだと思いました。
- (感想)実験結果の
\text{PR} \text{PR}_g - 超個人的な経験からですが、テキストのみの検索においては、質問と文書のEncoderを共通にしても、検索性能が上がったりすることの方が多いイメージがあります。反対に、この論文中では劇的にスコアが下がっていて面白いと思いました。
- 論文中で提案されたタスクでは、入力として質問側はテキストだけを入力し、ページ側はテキスト以外の座標情報や画像の特徴もまとめて入力しています。このモダリティの違いを考慮できなかったのがここまで差が開いてしまった原因なのかなと思いました。
おわりに
今回は「【論文紹介】MPMQA: Multimodal Question Answering on Product Manuals」というテーマでPanda株式会社 Advent Calendar 2023 1日目を執筆させていただきました。
本記事では、製品マニュアルに関するマルチモーダル質問応答の論文を紹介しました。
明日は、同じく私、nakachi_yによる「Document AIとLayoutLMについての紹介記事」です。お楽しみに!

Discussion