この記事は Panda株式会社 Advent Calendar 2023 2日目の記事です。
Panda株式会社は東京大学松尾研究室・香川高専発のスタートアップで、AR技術とAI技術を駆使したシステム開発と研究に取り組んでいます。
このアドベントカレンダーでは、スタートアップとしての知見、AI・AR技術、バックエンドなど、さまざまな領域の記事を公開していきます。
自己紹介
Panda株式会社でAIに関すること全般を担当している仲地です。
普段は筑波大学で情報検索分野の研究をしている博士前期課程の1年です。
はじめに
この記事の想定読者は以下の通りです。
- 想定読者:Document AIに興味がある人
- Required:色々な形式の文書(例:請求書、製品マニュアルなど)をどうやってAIで分析してるのか気になってる人
- Preferred:BERTやVision Transformerなどのモデルについて、大雑把に知ってる人
この記事では、Document AI[1]において主要なモデルとなっているLayoutLMとその派生系について説明します。
※本記事の”Document AI”は、Google Cloudが2020年から提供しているサービスのDocument AI[3]とは違う概念のことを指しています。
【導入】Document AIとは
Microsoft Research Asiaから2021年11月にPublishされた論文[2]で提案された研究トピックのことです。この論文[2]中では、"Document AI"(ドキュメントAI)とは、Webページ、ディジタルソース文書、スキャンされた文書などの様々なフォーマットを持つ文書から、AI技術を用いて、情報を自動的に理解、分類、抽出するプロセスを指すと説明されています。
このDocument AIのうち、深層学習技術を活用したプロセスの概要図は以下のようになっています。
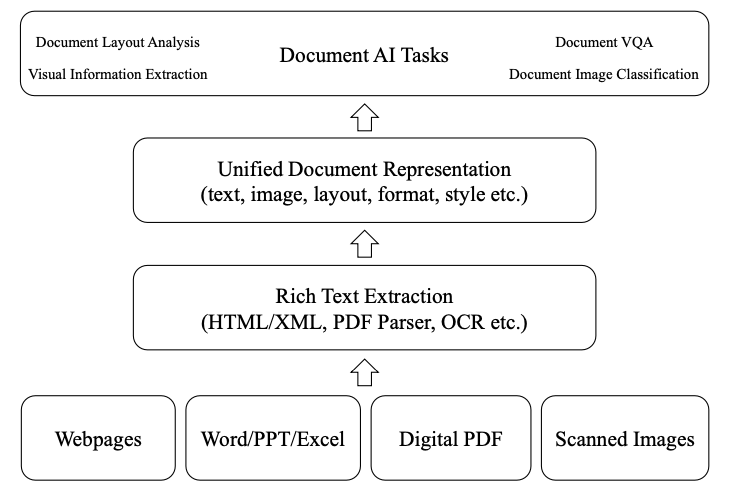
Document AIの論文中のFigure 1を引用
この概要図のうち、一番下にあるのが、入力として想定されている文書の種類です。WebページやPDFなど色々な種類の文書が入力として想定されています。
まず、これらの文書から情報を抽出するコンポーネントにより、様々なコンテンツを抽出します。抽出されるコンテンツは、テキストとそれに対応する座標情報や、画像の情報などがあります。この抽出を行うコンポーネントには、文書の種類によって様々なものが用いられます。代表的なものとしてはHTML/XML抽出機や、PDFパーサ、OCRエンジンなどが用いられます。
次に、抽出されたテキストや座標情報、画像情報などのコンテンツを複合的に組み合わせた統一的な表現(Unified Document Representation)を作成します。この表現の作成には、CNN(Convolutional Neural Networks)やGNN(Graph Neural Networks)、Transformer architecture[4]を活用した、深層学習モデルが用いられます。
そして、作成された表現を活用して、様々な下流タスクを解きます。代表的な下流タスクとして、Document Layout Analysis[5]、Visual Information Extraction[6]、Document Visual Question Answering[7]、Document Image Classification[8]の4つが挙げられています。
以上のようなプロセスで、Document AIは様々なフォーマットで記述された文書から、情報を自動的に、理解、分類、抽出を行います。
長くなりましたがここまでが導入です。次の章から本題のLayoutLMとその派生系について説明していきます。
LayoutLMとその派生系
Document AIの文脈において、Unified Document Representationを作成する際の代表的なものがLayoutLMというマルチモーダルなモデルとその派生系です。
これから順番に説明していきます。
LayoutLM
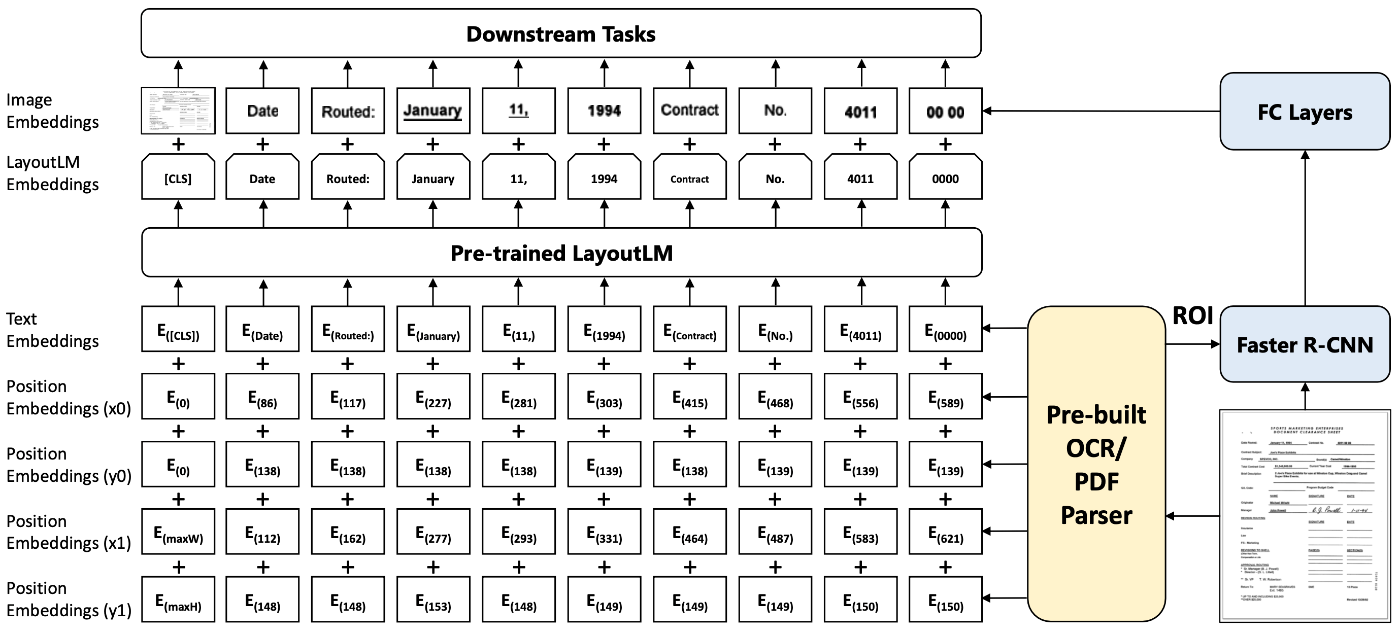
LayoutLMの概要図。[9]のFigure 1より引用
LayoutLM[9]は、Xuらにより2019年12月に提案され、2020年のACM SIGKDDにて採択されました。このモデルはTransformer architectureのうち、Encoderの部分のみを用いたもので、テキストデータのみを扱うことを前提としたモデルのBERTをベースにしています。BERTと異なる点として、LayoutLMはテキストの埋め込み表現と、それに対応するレイアウト情報の埋め込み表現(2-D Position Embedding:テキストが位置する座標情報の埋め込み表現)を足したものを入力として受け付けます。このテキストとレイアウトの情報は既存のOCRエンジンの出力をそのまま使用します。この入力に対してEncoderは(系列長, 埋め込み次元数)の埋め込み表現(LayoutLM Embeddings)を出力します。この埋め込み表現に対して、別の既存モデル(Faster R-CNN[11])の出力を全結合層でEncoderの出力と同じ(系列長, 埋め込み次元数)の形状に整形した埋め込み表現(=Image Embedding)を足し合わせます。この足し合わせた埋め込み表現を最終的な出力としています。この最終的な出力となっている埋め込み表現を用いて、様々な下流タスクを解きます。
LayoutLMの事前学習についてですが、以下の2つの事前学習タスクを解きます。
- Masked Visual-Language Model(MVLM):Masked Language Model(MLM)と同じように、入力される一部のテキストをMASKトークンに置き換え、このMASKトークンの元のトークンを推測させる。MLMと異なるのは、2-D Position Embeddingが利用可能なことで、この2次元の位置埋め込みを活用してトークンの復元が行われるため、文書のレイアウト情報を加味した学習が行われることが期待される。
- Multi-label Document Classification(MDC):IIT-CDIPテストコレクションという、1990年代のタバコ産業訴訟に関連する文書を含む、大規模なスキャン文書画像データセットを用いて、入力する文書のラベルを推測するタスク。
まとめると、LayoutLMはテキストとそれに対応する座標情報の2つを扱うモデルです。画像の情報は既存の他モデルを活用して扱うものになっています。
LayoutLMv2
LayoutLMの改善版として、LayoutLMv2[12]が約1年後の2020年12月に提案されました。(ACL2021に採択されています。)
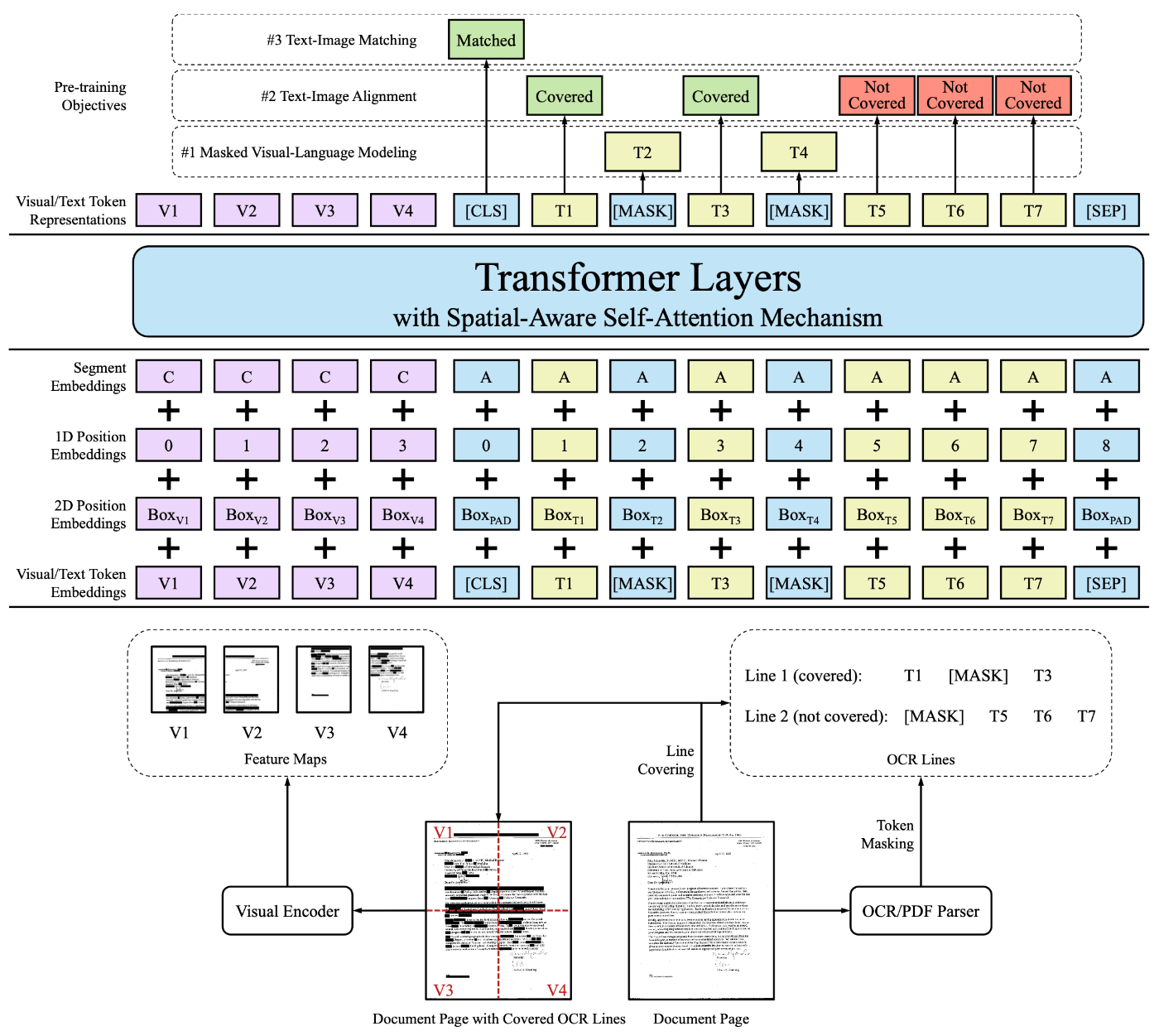
LayoutLMv2の概要図。[12]のFigure 1より引用
LayoutLMv2はLayoutLMとは異なり、画像の情報も同じモデルに入力します。より詳細に説明すると、画像の埋め込み表現を別のCNNベースモデル(ResNeXt-FPN)を用いて作成し、出力される表現をテキストの埋め込み表現と同じ次元に変換します。そしてこの画像の埋め込み表現とテキストの埋め込み表現を一つの系列として、TransformerベースのEncoderに入力を行います。LayoutLMv2はテキストとレイアウト情報と画像の3つをまとめて入力を行う以外にも、アテンション機構の工夫等を行なっていますが、本記事では省略します。
LayoutLMv2の事前学習については、以下の3つが採用されています。
- Masked Visual-Language Model(MVLM):LayoutLMとほとんど同じです。異なる点として、Maskされるトークンが位置する画像の埋め込みが同じくMaskされます。これはVisualの情報からMaskされるトークンの情報をleakしないようにするための処置となっています。
- Text-Image Alignment(TIA):イメージとバウンディングボックスの座標間の空間的な位置対応を学習するためのcross-modality alignmentタスクです。このタスクでは、いくつかのトークンがランダムに選ばれ、その画像領域は文書イメージ上で覆われます。事前学習中、エンコーダーの出力上に分類層が構築され、それぞれのテキストトークンが覆われているかどうかを予測します。このタスクは、既存のOCRエンジンが行と認識した単位で実行されます。
- Text-Image Matching(TIM):さらに、文書イメージとテキストコンテンツの対応を学習するためのcross-modality alignmentタスクです。[CLS]での出力表現を分類器に供給し、イメージとテキストが同じ文書ページから来ているかどうかを予測します。
まとめると、LayoutLMv2は、LayoutLMが画像の情報の扱いを既存の他モデルに頼っていたのに対して、1つのEncoderで扱えるようにし、モダリティの差を埋める事前学習を導入したモデルです。
LayoutLMv3
LayoutLMv3[13]は2022年4月に提案されました。(ACM Multimedia 2022に採択されています。)
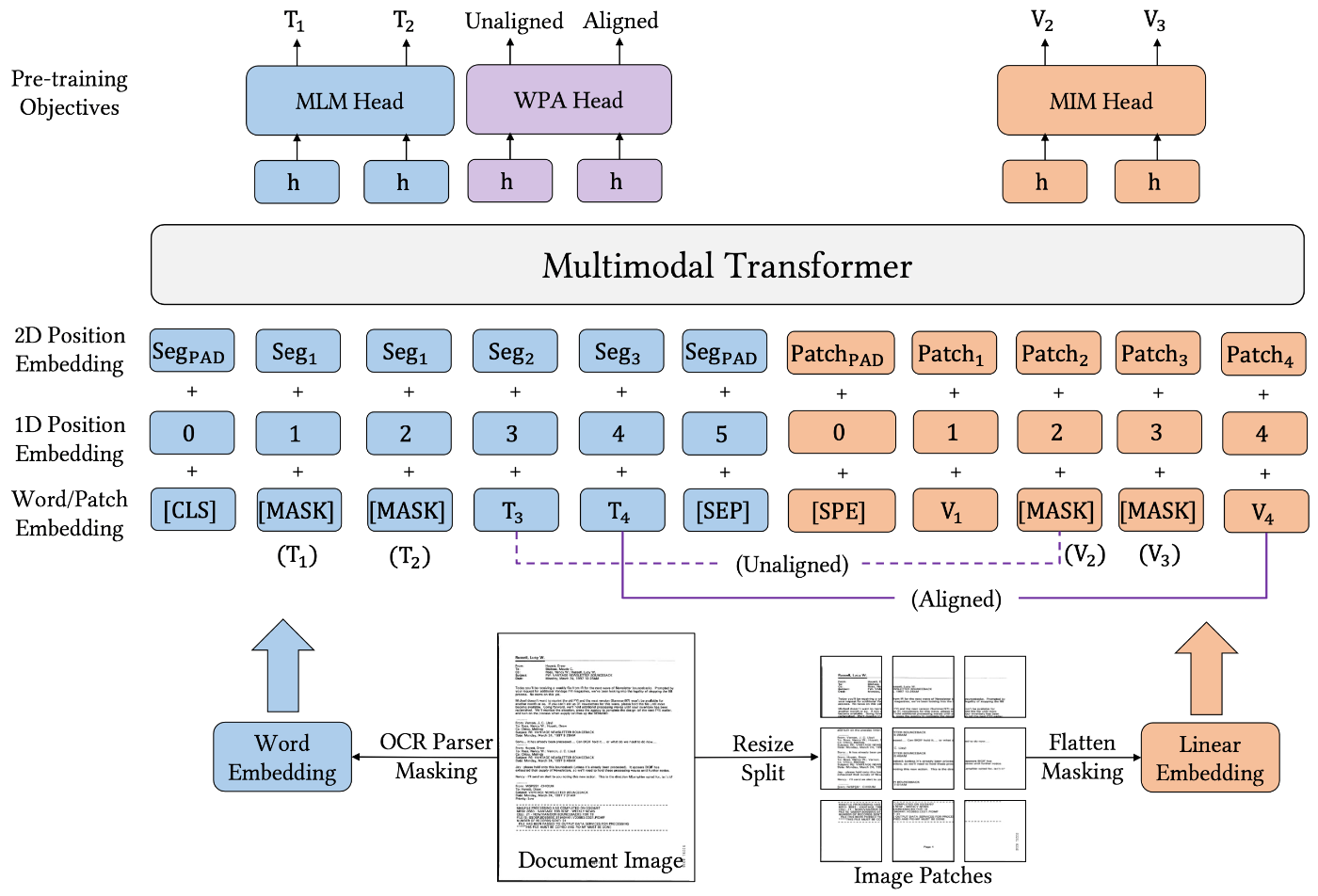
LayoutLMv3の概要図。[13]のFigure3より引用
LayoutLMv3はLayoutLMv2が画像の処理にCNNベースモデルを採用していましたが、ViT[14]と似たような前処理を行うようにし、既存のCNNベースモデルを使用しないようになりました。具体的には、文書を画像にしたものをresizeし、適当な数のパッチに分割します。その後、一つの系列として扱った上で、線形変換を行うことでテキストの埋め込みと次元数を揃えます。そして、LayoutLMv2と同じようにテキスト埋め込みと画像埋め込みを一つの系列としてRoBERTaベースのモデルに入力を行います。これにより、テキスト・レイアウト・画像の3つのモダリティを考慮した統一的な埋め込み表現を得ること狙ったモデルとなっています。
LayoutLMv3の事前学習については、以下の3つのタスクが採用されています。
- Masked Language Modeling (MLM): テキストの一部をマスクし、その文脈からMaskされた単語を予測するタスクです。LayoutLMv2と違い、Maskされたトークンが位置する画像をMaskはしません。画像の情報を用いた上で、正しいトークンを予測するような設定になっています。
- Masked Image Modeling (MIM): 画像の一部パッチをマスクし、その画像の残りの部分とテキストからマスクされた部分を予測するタスクです。
- Word-Patch Alignment (WPA): テキストの各単語がある画像パッチにあるかどうか判別するタスクです。これにより、モデルがテキストと対応する画像パッチの間のアライメントを学習ことを狙っています。
LayoutLMv2の事前学習タスクと異なり、テキストも画像もMaskされた箇所を修復するようなタスクに統一されたことが注目の変更点です。
まとめると、LayoutLMv3は、LayoutLMv2以前のモデルから、以下の3つを変更したモデルです。
①ベースのモデルをBERTからRoBERTaに変更
②LayoutLMv2の複雑になったモデル構造をシンプルに変更
③テキストと画像のそれぞれの事前学習タスクをMaskされた箇所を修復するようなタスクに統一
他の派生系モデル
前述したLayoutLM、LayoutLMv2、LayoutLMv3は主に同じMicrosoftのチームのメンバーが主になって提案したモデルとなっていますが、その他の人たちが開発したモデルもいくつかあります。
以下にその例を示します。
-
LayoutT5(AAAI2021)
- LayoutLMをT5をベースにした派生系モデル
-
XYLayoutLM(CVPR2022)
- XYカットアルゴリズムを用いて、読み順を明示的に考慮させるLayoutLMの派生系
-
LayoutReader(EMNLP2021)
- LayoutLMをReading Order Detection用に改善した派生系モデル
-
GeoLayoutLM(CVPR2023)
- Visual Information Extraction用に、明示的にエンティティとエンティティの位置関係を学習させた派生系モデル
おわりに
今回は「Document AIとLayoutLMについての紹介」というテーマでPanda株式会社 Advent Calendar 2023 2日目を執筆させていただきました。
本記事では、Document AIにおいて主要なモデルとなっているLayoutLMとその派生系について紹介しました。
明日は、amagai_rによる「【Unity】プラットフォーム依存の処理の書き方について」です。お楽しみに!
注釈
[1]: https://www.microsoft.com/en-us/research/project/document-ai/
[2]: Document AI: Benchmarks, Models and Applications(arXiv2021)
[3]: https://cloud.google.com/document-ai?hl=ja
[4]: Attention Is All You Need(NeurIPS2017)
[5]: Document Layout Analysis:文書のレイアウト内の画像、テキスト、表、図、チャートとその位置関係を自動的に分析、認識、理解することが求められるタスク
[6]: Visual Information Extraction:文書の非構造化された内容からエンティティとその関係性を抽出するタスク
[7]: Document Visual Question Answering:デジタル文書やスキャンされた画像に対し、PDF解析やOCRなどのテキスト抽出ツールを用いてテキスト内容を自動認識し、そのテキストの内部論理に基づいて自然言語の質問に答えるタスク
[8]: Document Image Classification:文書画像を分析し識別し、科学論文、履歴書、請求書、領収書などの異なるカテゴリーに分類するタスク
[9]: LayoutLM: Pre-training of Text and Layout for Document Image Understanding(KDD2020)
[10]: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(NAACL2020)
[11]: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(NeurIPS2015)
[12]: LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding(ACL2021)
[13]: LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking(ACM Multimedia2022)
[14]: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(ICLR2021)

Discussion