この記事は Panda株式会社 Advent Calendar 2023 8日目の記事です。
Panda株式会社は東京大学松尾研究室・香川高専発のスタートアップで、AR技術とAI技術を駆使したシステム開発と研究に取り組んでいます。
このアドベントカレンダーでは、スタートアップとしての知見、AI・AR技術、バックエンドなど、さまざまな領域の記事を公開していきます。
自己紹介
Panda株式会社でAIに関すること全般を担当している仲地です。
普段は筑波大学で情報検索分野の研究をしている博士前期課程の1年です。
はじめに
この記事の想定読者は以下の通りです。
- 想定読者:AIを使った作業支援に興味がある人。
この記事では、2023年11月30日にMetaの研究チームであるFAIR(Fundamental Artificial Intelligence Research)により、arXivに投稿された論文「Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives」について紹介します。
この論文は人間の行動を理解するための、マルチモーダル&マルチビューな大規模ビデオデータセットに関する論文です。
以下に、論文の書誌情報を記載します。
| タイトル | Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives |
|---|---|
| 著者 | Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaéz, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, and Michael Wray |
| 採択会議 | preprint |
| 論文リンク(arXiv) | https://arxiv.org/abs/2311.18259 |
この論文がやったこと
- Ego-Exo4Dという、多様で大規模なマルチモーダルかつマルチビューなビデオデータセットの作成。
- Ego-Exo4Dデータセットを用いた4つのベンチマークタスクの提案
背景
この論文の背景には、AIが人間の技術を理解することにより、様々な分野での応用が進むという期待があります。特に、拡張現実(AR)でのバーチャルAIコーチによるリアルタイムガイダンス、ロボット学習における器用な操作スキルの獲得、ソーシャルネットワーク上で動画による専門知識の共有コミュニティの形成など、AIの理解が進むことで多方面にわたる革新が期待されています。
しかし、この目標を実現するためには、既存のデータセットの限界を克服する必要があります。これまでのデータセットでは、一人称(Egocentric)視点と三人称(Exocentric)視点の統合が困難であり、規模が小さく、カメラ間の同期が欠けているものが多いです。また、実世界の多様性に対応するためには、これらのデータセットが実用的な映像ではなく、単一視点に限定されていたりするため、十分ではありませんでした。
これらの課題を解決するため、論文では「Ego-Exo4D」というデータセットを紹介しています。このデータセットは、一人称と三人称のビデオを時間同期して捉え、世界中の多様な環境で撮影されています。これにより、AIが人間の技術をより深く理解し、新たな応用分野での使用が可能になることが期待されています。
Ego-Exo4D データセット
Ego-Exo4Dデータセットは、人間の熟練した活動を一人称と三人称の両方の視点から捉えたもので、人間の動作やスキルの理解を深めるためのデータセットです。
Ego-Exo4Dデータセットの最大の特徴は、多様なシナリオと環境で撮影された、大量のマルチモーダル・マルチビューのビデオデータを含むことです。これには、日常的な活動から専門的な技術まで、幅広い範囲の人間の行動が含まれています。一人称視点のデータは、被験者が実際に行動を行う際の視点を提供し、三人称視点のデータは、周囲の環境や他者との相互作用を捉えます。この両方の視点を組み合わせることで、より人間行動の理解が可能になります。
以下の画像1は、Ego-Exo4Dデータセットの一例です。自転車の修理に関するビデオに、複数視点のビデオが同期されています。一人称視点のビデオは、作業者が装着しているAriaグラス(※Metaが開発したデータ収集用メガネ型デバイス)により撮影され、三人称視点のビデオは、作業環境に設置された4〜5台のカメラ(※Ariaグラスと同期したGoProカメラ)を使用して撮影されています。さらに、以下のような様々なモダリティのデータが、ビデオの時間軸に沿って同期されています。
- 7チャンネルオーディオデータ: 音声データは7つの異なるチャンネルから収集された音響情報。
- 動きや向きのデータ: 加速度計やジャイロスコープなどを含むセンサーによる動きや向きのデータ。
- アイトラッキングデータ: 被験者の視線の動きを追跡し、どこを見ているかの情報。
- RGBおよび2つのグレースケールビデオデータ: RGBカメラは通常のカラービデオを提供します。グレースケールSLAMカメラは空間的な情報と動きを捉えるために使用されます。これら2種類のカメラを使用して得られたビデオデータ。
- 3D環境点群データ: 環境の3D構造を点の集合体として表現し、空間的情報を提供しているデータ。
- 言語リソース:①一人称視点での作業者による自己の行動のナレーション、②三人称視点での各作業者の行動に対する動作の説明、そして③専門家によるパフォーマンスの批評の3つのテキストデータ。
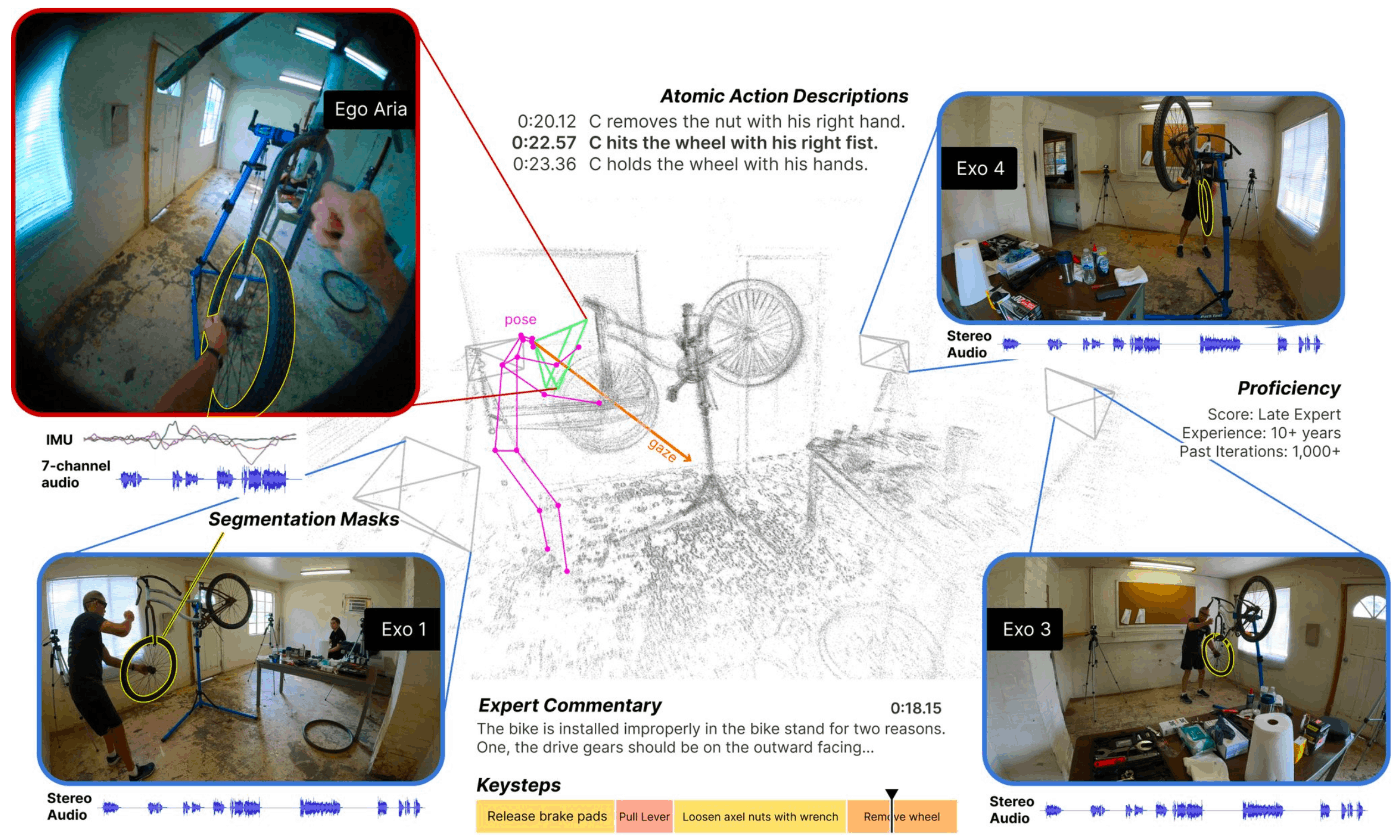
画像1:論文中のFigure1より引用
以上のようなデータで構成される、Ego-Exo4Dデータセットは、5,625本、合計時間1,422分のビデオで構成されています。
このデータセットは、8つのドメイン、839人のAriaグラスを装着した作業者によって世界中の13都市、131の異なるシーンで撮影されたもので、各撮影シーンは1分から42分の間の連続して撮影されたビデオになっています。
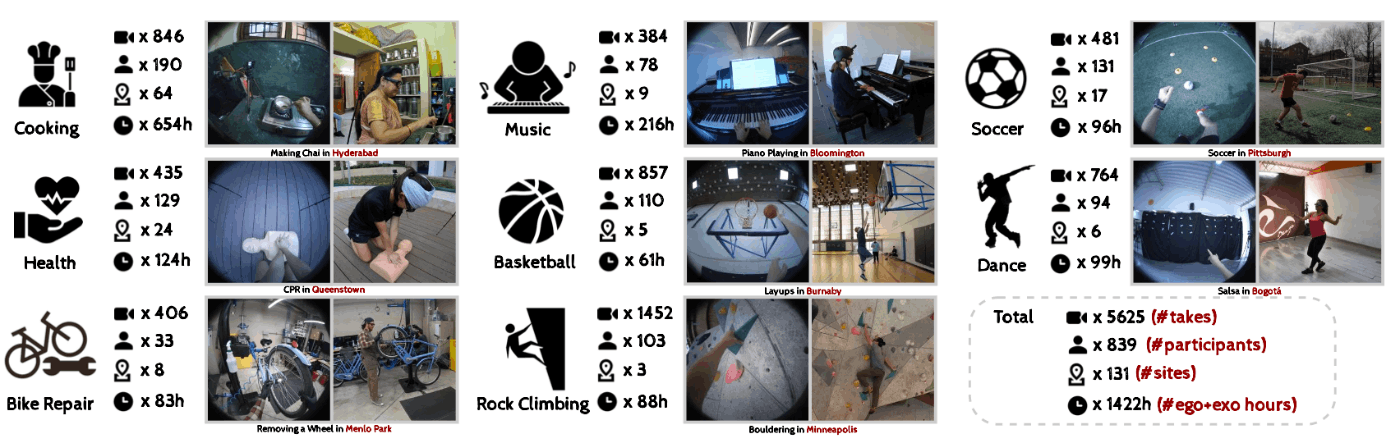
画像2:論文中のFigure2より引用。様々なドメインのビデオが含まれている。
Ego-Exo4Dベンチマークタスク
この論文中では、Ego-Exo4Dデータセットの作成だけではなく、Ego-Exo4Dデータセットに対する4つのベンチマークタスクの提案も行なっています。以下にそのタスクについてまとめます。
1. Ego-exo relation
一人称視点ビデオと三人称視点ビデオの関連性の特定および理解を評価するタスクです。以下の二つのタスクに分けられます。
1-1. Ego-exo correspondence

画像3:論文中のFigure4の左側より引用。Ego-exo correspondenceタスクの説明資料
一人称視点ビデオと三人称視点ビデオの両方に映っているオブジェクトの対応関係を理解することに焦点を当てたタスク。具体的には、同期された一人称視点ビデオと三人称視点ビデオペアから、一方のビデオ内の特定のオブジェクトに関連するマスクを他方のビデオで予測することが求められるタスクです。
1-2. Ego-exo translation

画像4:論文中のFigure4の右側より引用。Ego-exo translationタスクの説明資料
与えられた三人称視点ビデオから一人称視点ビデオを合成することを目標としたタスクです。このタスクはさらに「Track Prediction」と「Clip Prediction」の二つのサブタスクに分解されます。「Track Prediction」は与えられた三人称視点ビデオのオブジェクトマスクの動きを、基にそのオブジェクトの動きを一人称視点ビデオとして合成するタスクです。「Clip Prediction」は「Track Prediction」タスクの正解データ(オブジェクトマスク)に対して、正しいRGB値を予測するタスクです。
2. Ego(-exo) recognition
画像5:論文中のFigure5より引用。Ego-exo keystep recognitionタスクの説明資料
手順的な活動(※procedural activitiesを直訳したので、間違ってる可能性があります)のキーステップ(重要なステップ)を認識し、それらの依存関係をモデル化するタスクです。このタスクは以下の3つのタスクに分けられます。
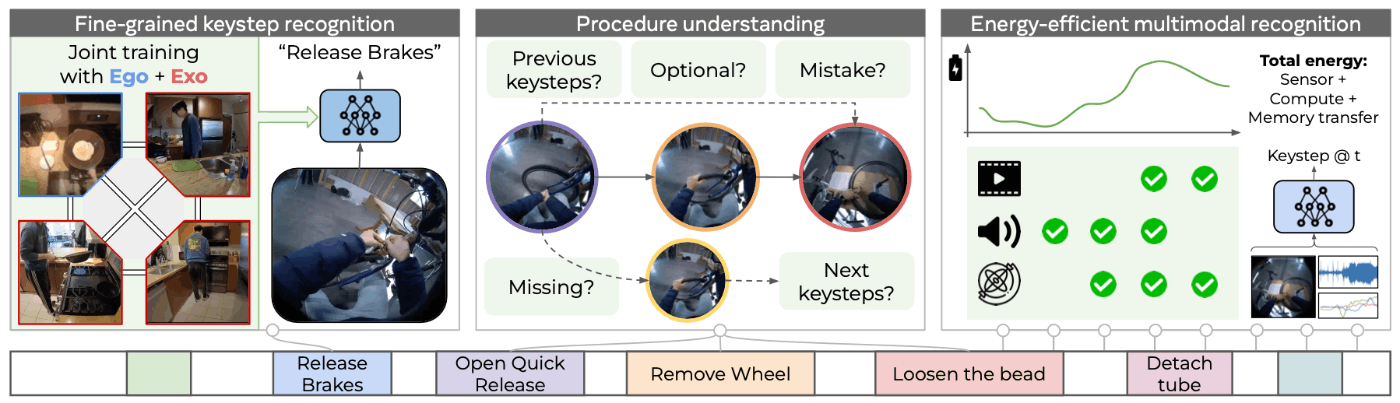
2-1. Fine-grained keystep recognition
このタスクは、一人称視点ビデオで実行されているステップを認識することが目標です。例えば、「オムレツをひっくり返す」のような特定のキーステップを、17の手順的な活動にまたがる689のキーステップの中から識別する必要があります。訓練時には、同じ活動の複数の視点からのビデオにアクセスできますが、テスト時には一人称視点ビデオのみが与えられます。
※ビデオ中のあるフレームのステップに対してオブジェクト検出するタスクというわけではなく、ビデオ中のここからここまではこのキーステップですよという時刻を推定するタスクです。
2-2. Energy-efficient multimodal keystep recognition
現在の活動検出モデルは、豊富な計算リソースとバッテリーを前提としています。タスクは、実世界のハードウェアでの実現可能性に向けて、エネルギー効率の良いビデオモデルを構築することに焦点を当てています。具体的には、オーディオ、IMU、RGBビデオデータから、各フレームで実行されているキーステップを識別し、続くタイムステップで使用するセンサーを決定するonline action detection taskとして定義されています。
2-3. Procedure understanding
手順理解タスクでは、ビデオから手順の構造(キーステップの順序、前提条件など)を自動的に理解することが目的です。モデルは、ビデオセグメントとその前のビデオセグメントの履歴を与えられ、過去のキーステップを決定し、セグメントがオプショナルであるか、手順上の間違いであるかを推測し、欠けているキーステップを予測し、次のキーステップ(依存関係が満たされているもの)を予測する必要があります。
3. Ego(-exo) proficiency estimation

画像6:論文中のFigure6より引用。Demonstrator and demonstration proficiency estimationタスクの説明資料
一人称視点ビデオから、スキルレベルを推測するタスクです。教育やパフォーマンス評価を正確に捉えることを目指しています。以下の二つのタスクに分けられます。
3-1. Demonstrator proficiency estimation
一人称視点ビデオを分析して、作業者が初心者、初級、中級、または上級のどのレベルに属するかを分類タスクです。
3-2. Demonstration proficiency estimation
一人称視点ビデオから、特定のアクションの熟練度を時間的に識別し、各アクションの品質(良い実行または改善が必要)と確率を示します。
4. Ego pose

画像7:論文中のFigure7より引用。Ego poseタスクの説明資料
一人称視点ビデオから作業者の熟練した身体運動の情報を復元するタスクです。出力として各タイムステップにおける作業者の身体と手の三次元空間上の関節位置が求められます。
以上のようなタスクが提案されています。
おわりに
今回は「【論文紹介】Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives」というテーマでPanda株式会社 Advent Calendar 2023 8日目を執筆させていただきました。
本記事では、Ego-Exo4Dという多様で大規模なマルチモーダルかつマルチビューなビデオデータセットを提案した論文を紹介しました。
明日は、同じく私、nakachi_yによる「【論文紹介】HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World」です。お楽しみに!
参考文献
- "Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives". arXiv. 2023-11-30. https://arxiv.org/abs/2311.18259, (参照 2023-12-08)
- "Ego-Exo4D". ego-exo4d-data.org. https://ego-exo4d-data.org/, (参照 2023-12-08).
- “AIに職人技を教えるデータセット、メタが公開 料理、ダンス、バイク修理など”. 週刊アスキー. https://weekly.ascii.jp/elem/000/004/173/4173968/, (参照 2023-12-08).
- "Introducing Ego-Exo4D: A foundational dataset for research on video learning and multimodal perception". AI at Meta. 2023-11-30. https://ai.meta.com/blog/ego-exo4d-video-learning-perception/, (参照 2023-12-08).
- "Introducing Project Aria". Project Aria. https://www.projectaria.com/, (参照 2023-12-08).
- “【記者発表】人のように一人称視点から実世界を理解する AIの実現に向けて ――大規模一人称視点・外部視点映像データセットEgo-Exo4Dを公開――”. Institute of Industrial Science, the University of Tokyo. 2023-12-05. https://www.iis.u-tokyo.ac.jp/ja/news/4379/, (参照 2023-12-08).

Discussion