はじめに
この記事は Panda株式会社 Advent Calendar 2023 5日目の記事です。
Panda株式会社として初めてのAdvent Calendarとなります。
Panda株式会社は東京大学松尾研究室・香川高専発のスタートアップで、AR技術とAI技術を駆使したシステム開発と研究に取り組んでいます。
このアドベントカレンダーでは、スタートアップとしての知見、AI・AR技術、バックエンドなど、さまざまな領域の記事を公開していきます。
本記事は、Panda株式会社 Advent Calendar 2023の4日目の記事「 OpenAIのAPIとUnityで音声会話チャットボットを作る ~ チャット機能編 ~」の続きです。
環境
- Unity 2021.3.9f1以降
システム構成
このシステムでは、ユーザーが音声で質問すると、Unity Technologies Japanが開発者のために提供しているオリジナルキャラクター「ユニティちゃん」が音声で応答するチャットボットを作成します。ユーザーの音声での入力はマイクを使用して録音され、その音声データはテキストに書き起こされます。次に、この書き起こされたテキストをOpenAIのchat completions APIに送信し、ユーザーの質問に対する適切な応答を生成します。chat completions APIに送信するテキストには、ユニティちゃんの喋り方を指定するプロンプトと感情分析を含めることで、返却された応答から「ユニティちゃん」の表情を操作します。さらに、生成された応答はGoogle Cloud Platform(GCP)のText-to-Speechサービスを使用して音声データに変換されます。そして、この音声データをUnity内で再生することで、アバターが音声で応答することを実現します。
それぞれの機能を実現するために本記事を含めて以下の4つの記事に分けて実装について説明します。アドベントカレンダーで公開される記事になっているため、投稿日現在(2023/12/05)、アクセスできない記事が含まれています。
- OpenAIのAPIとUnityで音声会話チャットボットを作る ~ チャット機能編 ~
- (本記事)OpenAIのAPIとUnityで音声会話チャットボットを作る ~ 音声入力編 ~
- OpenAIのAPIとUnityで音声会話チャットボットを作る ~ 音声生成編 ~
- OpenAIのAPIとUnityで音声会話チャットボットを作る ~ 喜怒哀楽編 ~
音声入力用のUIを準備する
音声入力機能は、マイクを用いてユーザの発話を録音し、それを音声認識しテキストに書き起こすことで実現します。今回は、音声認識にOpenAIが開発したWhisperを利用します。WhisperのモデルはGithubで公開されています。しかし、今回はUnityから簡単にモデルを利用するために、OpenAIが公開しているtranscriptions API経由でWhisperの音声認識を利用します。
OpenAI transcriptions APIで音声の書き起こしを行う際には、サーバに対して音声ファイルをアップロードする必要があります。そのため、ユーザが音声入力する際は、録音の開始・終了を行えるボタンを作成する必要があります。
前回の記事で作成したUIに新しく音声入力用のボタンを追加していきましょう。
1. 音声入力を管理するボタンを作成する
ヒエラルキーを右クリックし、UI → Legacy → Buttonの順で選択し、Buttonをシーンに追加します。
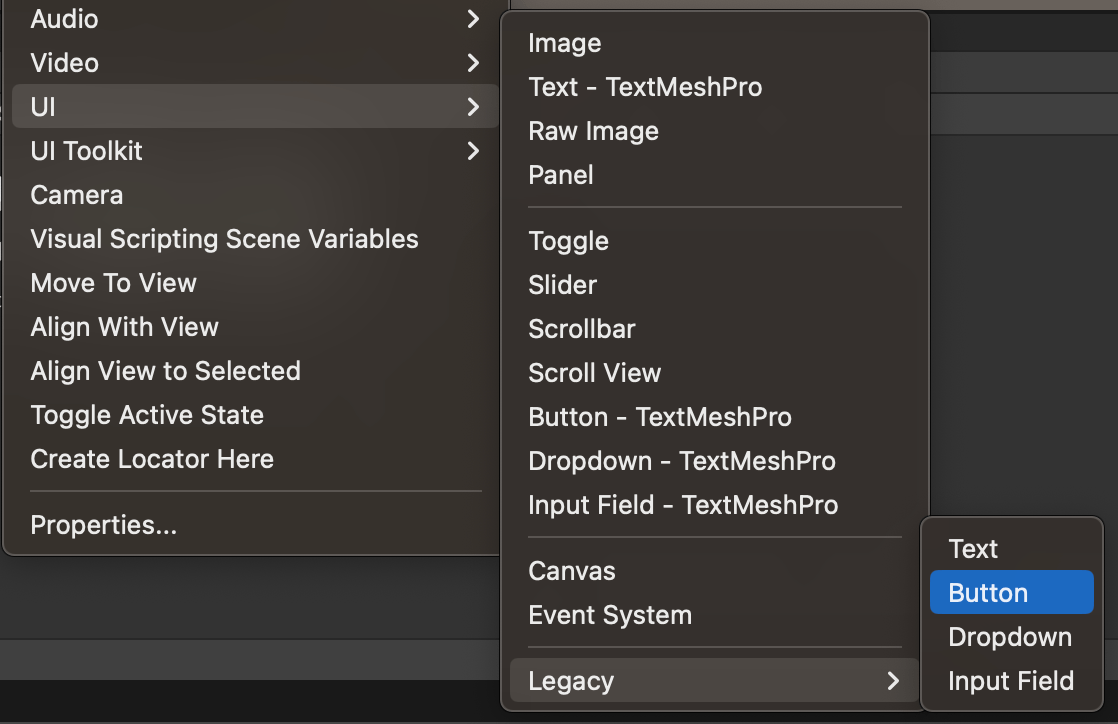
追加後、Buttonの位置を調整し、テキストボックスや送信ボタンの隣に移動します。

2. 録音の開始・終了
ユーザがボタンをクリックするたびに音声の録音を開始・停止するスクリプトを作成します。
SpeechManager.csの全体
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
using static WhisperSpeechToText;
public class SpeechManager : MonoBehaviour
{
public void OnClick()
{
var whisperSpeechToText = GetComponent<WhisperSpeechToText>();
var recordingstate = GetComponentInChildren<Text>();
if (whisperSpeechToText.IsRecording())
{
recordingstate.text = "録音開始";
whisperSpeechToText.StopRecording();
}
else
{
recordingstate.text = "録音停止";
whisperSpeechToText.StartRecording();
}
}
}
以下のコードは、レコーディングを開始・終了する際に実行されます。録音がすでに始まっている場合は、録音を終了する処理を実行します。録音が始まっていない場合は、録音を開始する処理を実行します。
- 録音がすでに始まっている場合再び録音ができるようになったことがわかりやすいように
recordingstateを録音開始にします。その後、この記事の後半に記述するレコーディング終了処理を呼び出します。 - 録音が始まっていない場合録音が開始し、録音が止められるようになったことがわかりやすいように、
recordingstateを録音終了にします。その後、この記事の後半に記述するレコーディング開始処理を呼び出します。
if (whisperSpeechToText.IsRecording())
{
recordingstate.text = "録音開始";
whisperSpeechToText.StopRecording();
}
else
{
recordingstate.text = "録音停止";
whisperSpeechToText.StartRecording();
}
このスクリプトを録音開始ボタンにアタッチし、ButtonのOnclick()イベントに追加することでボタンを押すことで録音開始・終了ができるようになります。
OpenAI transcriptions APIとの連携
ユーザが発話した音声データをテキストに書き起こすために、OpenAIが提供するWhisperモデルを利用して、与えられた音声データを書き起こしテキストに変換します。WhisperはWebから収集された680,000時間の多言語音声データを学習させた自動音声認識システムです。OpenAIはこのモデルと推論コードをオープンソース化しています。
今回は音声ファイルをアップロードするとWhisperのモデルを実行し音声の書き起こしテキストを返却してくれる「OpenAI transcriptions API」を利用します。このモデルを利用するには、入力に音声データとAPIキーを含むリクエストをOpenAIのAPIに送信し、モデルからの出力を受け取る必要があります。Unityからモデルを利用するには、UnityWebRequestを使ってAPIにリクエストを送信します。
1. APIに対するリクエストの送受信
UnityWebRequestを用いて、APIにリクエストを送るコードを作成します。リクエストにはユーザの入力メッセージとプロンプト、APIキーを含める必要があります。
APIを呼び出すために必要なリクエストと返却される形式についてはOpenAIのtranscriptions APIのドキュメントから確認することができます。
「https://api.openai.com/v1/audio/speech 」にFromをPostすることでリクエストを送ることができます。
WhisperSpeechToText.csの全体
using System;
using UnityEngine;
using UnityEngine.Networking;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using UnityEngine.UI;
public class WhisperSpeechToText : MonoBehaviour
{
[SerializeField]
private string openAIApiKey;
[SerializeField] private InputField _textInterface;
public int frequency = 16000; // 周波数
public int maxRecordingTime; // 録音最大時間
private AudioClip clip;
private float recordingTime;
void Update()
{
// レコーディング中であれば
if (IsRecording())
{
recordingTime += Time.deltaTime;
// レコーディング時間が超えていないことを確認する
if (Mathf.FloorToInt(recordingTime) >= maxRecordingTime)
{
StopRecording();
}
}
}
public void StartRecording()
{
recordingTime = 0;
// すでにレコーディング中であればレコーディングを止める
if (IsRecording())
{
Microphone.End(null);
}
// マイクの録音を開始する
Debug.Log("RecordingStart");
clip = Microphone.Start(null, true, maxRecordingTime, frequency);
// 録音が正しく開始されたかを確認
if (clip == null)
{
Debug.LogError("Microphone recording failed.");
}
}
public bool IsRecording()
{
return Microphone.IsRecording(null);
}
public void StopRecording()
{
Debug.Log("RecordingStop.");
// マイクのレコーディングを止める
Microphone.End(null);
// AudioClipをWAV形式のバイナリデータに変換する
var audioData = WavUtility.FromAudioClip(clip);
// Send HTTP request to Whisper API
StartCoroutine(SendRequest(audioData));
}
IEnumerator SendRequest(byte[] audioData)
{
string url = "https://api.openai.com/v1/audio/transcriptions";
string accessToken = openAIApiKey;
// フォームデータを作成する
var formData = new List<IMultipartFormSection>();
formData.Add(new MultipartFormDataSection("model", "whisper-1"));
formData.Add(new MultipartFormDataSection("language", "ja"));
formData.Add(new MultipartFormFileSection("file", audioData, "audio.wav", "multipart/form-data"));
// UnityWebRequestを作成する
using (UnityWebRequest request = UnityWebRequest.Post(url, formData))
{
// リクエストヘッダーを設定
request.SetRequestHeader("Authorization", "Bearer " + accessToken);
// リクエストを送信し、応答を待機
yield return request.SendWebRequest();
// エラー処理
if (request.result != UnityWebRequest.Result.Success)
{
Debug.LogError(request.error);
yield break;
}
// JSONデータのレスポンスをパースする
string jsonResponse = request.downloadHandler.text;
string recognizedText = "";
try
{
recognizedText = JsonUtility.FromJson<WhisperResponseModel>(jsonResponse).text;
}
catch (System.Exception e)
{
Debug.LogError(e.Message);
}
// 書き起こしされたテキストを出力する
Debug.Log("Input Text: " + recognizedText);
_textInterface.text = recognizedText;
}
}
}
public static class WavUtility
{
public static byte[] FromAudioClip(AudioClip clip)
{
using var stream = new MemoryStream();
using var writer = new BinaryWriter(stream);
// Write WAV header
writer.Write(0x46464952); // "RIFF"
writer.Write(0); // ChunkSize
writer.Write(0x45564157); // "WAVE"
writer.Write(0x20746d66); // "fmt "
writer.Write(16); // Subchunk1Size
writer.Write((ushort)1); // AudioFormat
writer.Write((ushort)clip.channels); // NumChannels
writer.Write(clip.frequency); // SampleRate
writer.Write(clip.frequency * clip.channels * 2); // ByteRate
writer.Write((ushort)(clip.channels * 2)); // BlockAlign
writer.Write((ushort)16); // BitsPerSample
writer.Write(0x61746164); // "data"
writer.Write(0); // Subchunk2Size
// Write audio data
float[] samples = new float[clip.samples];
clip.GetData(samples, 0);
short[] intData = new short[samples.Length];
for (int i = 0; i < samples.Length; i++)
{
intData[i] = (short)(samples[i] * 32767f);
}
byte[] data = new byte[intData.Length * 2];
Buffer.BlockCopy(intData, 0, data, 0, data.Length);
writer.Write(data);
// Update ChunkSize and Subchunk2Size fields
writer.Seek(4, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 8));
writer.Seek(40, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 44));
// Close streams and return WAV data
writer.Close();
stream.Close();
return stream.ToArray();
}
}
public class WhisperResponseModel
{
public string text;
}
全体のコードを元に、OpenAI transcriptions APIにリクエストを送る方法を紹介します。
Unityでファイルをアップロードするには、テキストデータとバイナリデータを同時に送信することができるMultipartFormFileSectionを利用してフォームデータとしてAPIにPOSTする必要があります。
以下の部分で、OpenAI transcriptions APIにリクエストを行うためのフォームデータを作成します。OpenAIのtranscriptions API referenceのリクエストボディを確認すると、以下の二つが必須項目であることが分かります。
- file file:書き起こししたい音声ファイルのオブジェクトを指定する
-
model string: 使うモデルのIDを指定
whisper-1など
IMultipartFormSectionのリストを作成し、modelとfileを指定します。modelにはwhisper-1、fileにはバイナル形式の音声データとそのファイル名(audio.wav)、コンテンツタイプ(multipart/form-data)を指定します。
今回、音声入力は日本語を想定しているので、処理する言語languageを日本度jaとします。
// フォームデータを作成する
var formData = new List<IMultipartFormSection>();
formData.Add(new MultipartFormDataSection("model", "whisper-1"));
formData.Add(new MultipartFormDataSection("language", "ja"));
formData.Add(new MultipartFormFileSection("file", audioData, "audio.wav", "multipart/form-data"));
以下にOpenAI transcriptions APIにPOSTリクエストを送るためのコードを記述します。まず、UnityWebRequest.Post(url, data)で指定されたURLにPOSTリクエストを送信するためのUnityWebRequestオブジェクトを作成します。usingステートメントはUnityWebRequestオブジェクトが使われなくなった時に自動的にリソースを開放することができるので利用しています。
OpenAI transcriptions APIを使うには、ヘッダーにAPIキーを設定する必要があります。request.SetRequestHeader("Authorization", "Bearer " + accessToken);を用いてアクセストークンの設定を行います。
その後、yield return request.SendWebRequest();でここまでで作成したリクエストを非同期的に送信し、サーバからの応答があるまで待機します。
// Create UnityWebRequest object
using (UnityWebRequest request = UnityWebRequest.Post(url, formData))
{
// リクエストヘッダーを設定
request.SetRequestHeader("Authorization", "Bearer " + accessToken);
// リクエストを送信し、応答を待機
yield return request.SendWebRequest();
・・・
}
リクエストが返却されたら、その結果を処理します。まず、エラー処理を行い、エラーが発生しなかった場合はレスポンスをクラスに変換し、Unity側から扱えるようにします。レスポンスはJSON形式のテキストが返却されるのでJsonUtility.FromJsonを使い、シリアライズしてから音声の書き起こしテキストをrecognizedTextとして保存します。
// エラー処理
if (request.result != UnityWebRequest.Result.Success)
{
Debug.LogError(request.error);
yield break;
}
// JSONデータのレスポンスをパースする
string jsonResponse = request.downloadHandler.text;
string recognizedText = "";
try
{
recognizedText = JsonUtility.FromJson<WhisperResponseModel>(jsonResponse).text;
}
catch (System.Exception e)
{
Debug.LogError(e.Message);
}
OpenAI transcriptions APIから返却されるレスポンスは次のとおりです。
-
text: 入力された音声データを書き起こしたテキスト
この要素を持つクラスをWhisperResponseModelとして定義します。
public class WhisperResponseModel
{
public string text;
}
2. マイクを使った録音を開始・終了
以下はマイクを使った録音を開始する関数です。実行時にrecordingTimeを0に初期化します。recordingTimeはレコーディングの時間を計測するための変数です。すでにレコーディング中であればMicrophone.End(null);を用いてレコーディングを一度止めます。その後マイクでの録音を開始します。
録音を開始する際はclip = Microphone.Start(null, true, maxRecordingTime, frequency);を用い、AudioClipを作成しclip変数に格納します。
public void StartRecording()
{
recordingTime = 0;
// すでにレコーディング中であればレコーディングを止める
if (IsRecording())
{
Microphone.End(null);
}
// マイクの録音を開始する
Debug.Log("RecordingStart");
clip = Microphone.Start(null, true, maxRecordingTime, frequency);
// 録音が正しく開始されたかを確認
if (clip == null)
{
Debug.LogError("Microphone recording failed.");
}
}
以下はマイクを使った録音を終了する関数です。Microphone.End(null);を用いてレコーディングを止めます。その後AudioClipをWavUtility.FromAudioClipを用いてWAV形式のバイナリデータに変換します。そして、コルーチンを使ってOpenAI transcriptions APIにバイナリデータを送信します。これにより、マイクを使って録音された音声データをテキストに変換することができます。
public void StopRecording()
{
Debug.Log("RecordingStop.");
// マイクの録音を開始する
Microphone.End(null);
// AudioClipをWAV形式のバイナリデータに変換する
var audioData = WavUtility.FromAudioClip(clip);
// OpenAI transcriptions APIにリクエストを送信する
StartCoroutine(SendRequest(audioData));
}
3. 音声データをバイナリ形式に変換する
OpenAI transcriptions APIはflac、mp3、mp4、mpeg、mpga、m4a、ogg、wav、webmのいずれかの音声ファイルを入力として受け取ります。Unityでマイクを使って録音する際には、Microphoneを使ってオーディオデータを格納・処理できるAudioClipに記録することができます。しかし、AudioClipはそのままAPIに送信できないため、APIに送れるバイナリ形式に変換する必要があります。今回はMacOSでもWindowsOSでも扱える非圧縮音声用のwavを経由しバイナリ形式に変換します。AudioClipからwavの変換に必要なコードは以下の通りです。wavの形式に合わせサンプリングするコードです。説明は割愛します。
WhisperSpeechToText.cs の抜粋
public static class WavUtility
{
public static byte[] FromAudioClip(AudioClip clip)
{
using var stream = new MemoryStream();
using var writer = new BinaryWriter(stream);
// Write WAV header
writer.Write(0x46464952); // "RIFF"
writer.Write(0); // ChunkSize
writer.Write(0x45564157); // "WAVE"
writer.Write(0x20746d66); // "fmt "
writer.Write(16); // Subchunk1Size
writer.Write((ushort)1); // AudioFormat
writer.Write((ushort)clip.channels); // NumChannels
writer.Write(clip.frequency); // SampleRate
writer.Write(clip.frequency * clip.channels * 2); // ByteRate
writer.Write((ushort)(clip.channels * 2)); // BlockAlign
writer.Write((ushort)16); // BitsPerSample
writer.Write(0x61746164); // "data"
writer.Write(0); // Subchunk2Size
// Write audio data
float[] samples = new float[clip.samples];
clip.GetData(samples, 0);
short[] intData = new short[samples.Length];
for (int i = 0; i < samples.Length; i++)
{
intData[i] = (short)(samples[i] * 32767f);
}
byte[] data = new byte[intData.Length * 2];
Buffer.BlockCopy(intData, 0, data, 0, data.Length);
writer.Write(data);
// Update ChunkSize and Subchunk2Size fields
writer.Seek(4, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 8));
writer.Seek(40, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 44));
// Close streams and return WAV data
writer.Close();
stream.Close();
return stream.ToArray();
}
}
以下のコードでAudioClipをWAV形式のバイナリデータに変換します。
// AudioClipをWAV形式のバイナリデータに変換する
var audioData = WavUtility.FromAudioClip(clip);
以上で、OpenAI transcriptions APIにリクエストを送信するスクリプトWhisperSpeechToText.csの説明を終わります。
このスクリプトを録音開始・終了ボタンにアタッチします。
インスペクターからOpenAIApiKeyに前回の記事で取得したOpenAIのAPIキーを記述し、Frequency、MaxRecordingTimeを指定します。TextInterfaceにはメッセージを入力するボタンをアタッチします。
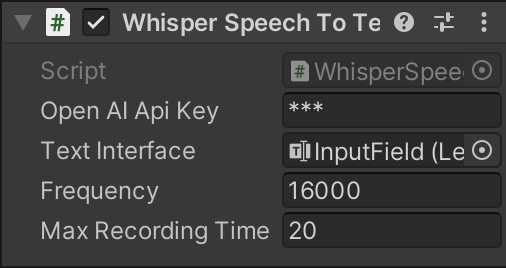
これにより、ユーザの音声発話を入力できるチャットボットを実現することができます。
おわりに
今回は「OpenAIのAPIとUnityで音声会話チャットボットを作る ~ 音声入力編 ~」というテーマでPanda株式会社 Advent Calendar 2023 5日目を執筆させていただきました。
本記事では、UnityでOpenAIのAPIを用いてユーザの音声発話を入力にできるチャットボットを作成しました。
明日の記事も私、Panda株式会社代表取締役の田貝奈央による「OpenAIのAPIとUnityで音声会話チャットボットを作る ~ 音声生成編 ~」です。この記事を読めばチャットボットの応答を音声で出力できるようになります。明日の記事をお楽しみに!

Discussion