はじめに
2024年6月20日、21日の2日間にわたり開催された AWS Summit Japan にて、弊社プロダクト ハピタス の生成AI活用の取り組みが取り上げられました!
当日の様子については以下の記事をご覧ください。
生成AI導入の背景については以下の記事をご覧ください。
本記事では、生成AIプラットフォームであるAmazon Bedrockを活用し、2024年7月1日にローンチしたハピタスの検索機能改善の概要とアーキテクチャについて紹介します。
ハピタスとは
オズビジョンはハピタスというポイントモール事業を運営しています。
500万人超の会員と3,500社のEC事業者をマッチングし、流通総額は約1,800億円で国内トップ水準の購買プラットフォームです。

ローンチした機能
ハピタスの検索窓から、「ANA」という文字で検索した場合を想定します。

改善前:検索欄から「ANA」を検索した場合
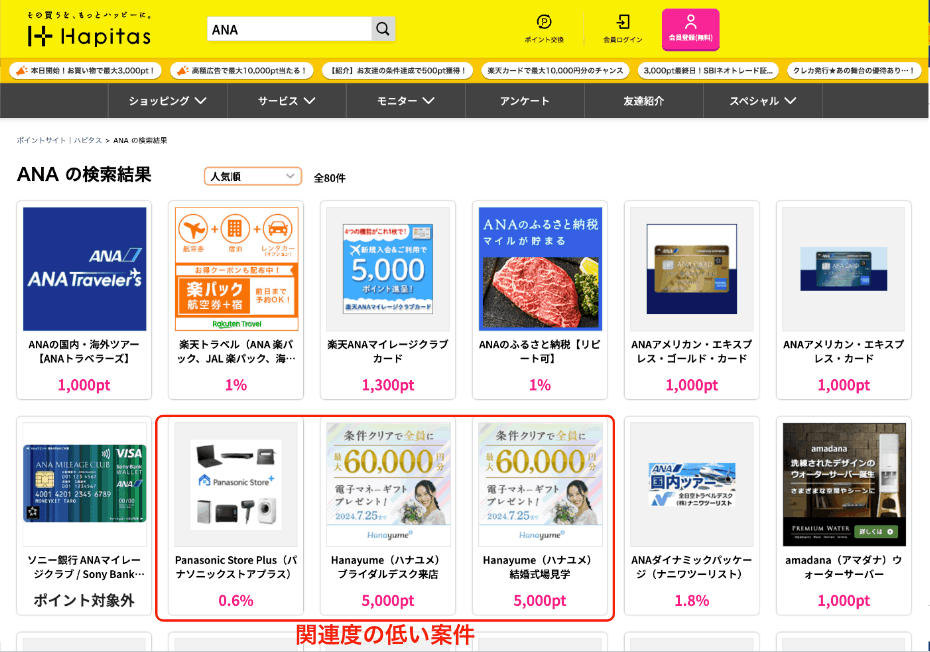
改善前の場合、検索ワードの「ANA」との関連度が低いPanasonicやHanayume(ハナユメ)の広告が検索結果の上位に表示されていました。
改善後:検索欄から「ANA」を検索した場合

プルダウンを"おすすめ(ベータ)"に切り替えると、改善後の検索結果が表示されます。

改善後の場合、改善前に表示されていた関連度の低い広告は上位に表示されなくなりました。
いくつかまだ除外できていない広告も上位に表示されているため、精度向上の取り組みは引き続き行います。
この改善により、明確な意思や検索ワードを持たずに広告を探すユーザーに対して、より関連度が高い検索結果を表示し、ハピタスを利用することで得られるユーザー体験の向上を目指しています。
アーキテクチャ
改善前
単純な文字列検索により、同じ文字が含まれている検索結果が表示されるだけでした。

改善後
ベクトル検索により、検索キーワードと類似性関連性の高い検索結果が表示されるようになりました。

処理の流れについて
登録・更新
- 定期的にハピタスの広告データの差分のCSVファイルをS3に送信
- ECSからCSVファイルを読み取り、Bedrock (Amazon Titan Text Embeddingsモデル v2を利用) からベクトルデータを生成
- 生成したデータをPostgreSQLに登録
検索
- 検索ワードをLambdaからBedrock (Amazon Titan Text Embeddingsモデル v2を利用) でベクトルデータに変換
- PostgreSQLからベクトル値の類似度の高い順に広告IDの一覧を返す
- 広告ID一覧をWebサーバが受け取り、MySQLの最新情報を元に不要な広告をフィルタ、必要なデータを付加し、結果をユーザーに返す
アーキテクチャの意図
Q.なぜ、ハピタスは東京リージョン、新環境の生成AI側はバージニアリージョンなのか?
→レイテンシー遅延を心配したが、許容できる速度 (0.3s)であり、価格が割安になり、且つ新しいモデルを試したかったから
- 既存の検索の通信レイテンシーは 東京リージョンから外部への通信はないので 0s (ブラウザへの応答に約 1.3s)
- ベクトル検索の通信のレイテンシーは 0.3s ほどと考えられる
- ベクトル検索はブラウザへの応答に約 2.5s (内 ベクトル検索API 内部処理 1.8s, WEBサーバ内部処理 0.4s )
Q.ベクトルDBにOpenSearchではなくAmazon Aurora Serverless [PostgreSQL] を利用している理由は?
→OpenSearchが使われる事が多いが、Amazon Aurora Serverless [PostgreSQL] を使うことで、コストを少しでも抑えたかったから
Q.ベクトルデータ登録処理にLambdaではなくECSを利用した理由は?
→Lambda のほうが低コストだが、実行時間15分が上限の制約があり、処理に30分以上かかるから
Q.API Gatewayを通さず、そのまま既存バッチサーバ、既存WebサーバからベクトルDBの更新をしなかった理由は?
→役割を既存環境に持たせすぎないため。また、既存環境ではphpを使っているが、機械学習に関連するライブラリが豊富なPythonを使いたかったため、新環境でPythonを使ってベクトルDBの更新を行うことにした。
Q.Titan Embedding v2 (2024/4/30 リリース) を使われている理由は?
→当初はCohere Embed Model v3を使用する予定だったが、弊社のユースケースではTitan Embedding v2を使用したベクトル検索と結果にほとんど差がなかったから。また、価格が5分の1で済むため、Titan Embedding v2を採用した。さらに、バージニアリージョンを使用することで得られるメリットも享受できる。
おわりに
今回の検索機能改善により、よりユーザーの直感に近い情報を提供できるようになりました。
今後も精度向上の取り組みを行っていきます。
最後まで読んでいただき、ありがとうございました!

Discussion