はじめに
おはようございます。こんにちは。こんばんは。
Offers と、Offers MGR を運営している株式会社 overflow のバックエンドエンジニアばばです。
overflow にジョインしてはや 10 ヶ月がたちました。前回のブログではまだひよこだった私も、少しずつアウトプットも増えてきました。
直近ではプロダクトで利用するテキストデータから特徴タグなどを抽出するアノテーションデータ生成パイプラインを構築しました。弊社のシステムは AWS を利用しており、今回は AWS Glue DataBrew (以降 DataBrew と呼びます) を組み込んだことで、スケーリングを担保しつつ短期間でのパイプライン実装できたのでその取り組みをご紹介します。DataBrew そのものよりかは、AWS のサービス間連携や Contiuous Delivery の苦労が多かったのでその辺りを重点的に説明しています。
アノテーションデータ生成のプロセス
はじめに、今回構築したアノテーションデータ生成パイプラインについてご説明します。
社内にあるテキストデータから特定のルールに従い抽出した特徴語を抽出し、テキストおよび出典元などと紐付けるデータを生成するパイプラインとなります。出典元の分類やタグ付けなどを行うことができます。
アノテーションデータ生成パイプラインのプロセスは次の通りになります。
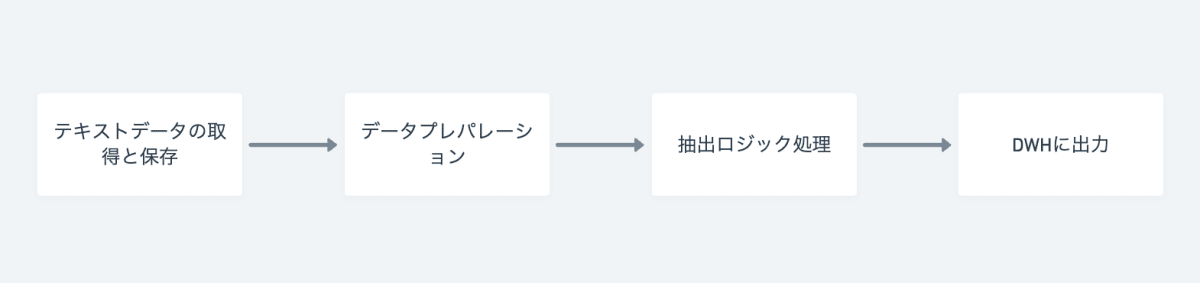
- テキストデータの取得と保存
プロダクト DB・ログ・API・スクレイピングなど様々な手段でデータを取得します。この段階では加工せずほぼ生データのまま保存しています。 - データプレパレーション
- で取得したデータの前処理を行う工程です。ステージングなどともいわれ、データのクレンジング、PII のマスキング、生計などを行います。
- 抽出ロジック処理
2. でクレンジングしたテキストデータを単語などに分解し、テキストの特徴として抽出します。テキストの単語の分解には形態素解析、特徴の抽出にはルールベースまたは機械学習・AI を用いることが一般的です。今回は、初期フェーズのためすでに社内に存在していたラベル辞書に基づき、ルールベースで実装しています。 - DWH に出力
3. で抽出されたアノテーションデータを、メタデータととも DWH に保存します。
現時点では数種類ですが、今後様々なデータセットの入力を想定しているため、データプレパレーションでフォーマットなどを吸収し、抽出ロジックを汎用的に実装する方針としました。
AWS 上でのアーキテクチャ図はこちらです。
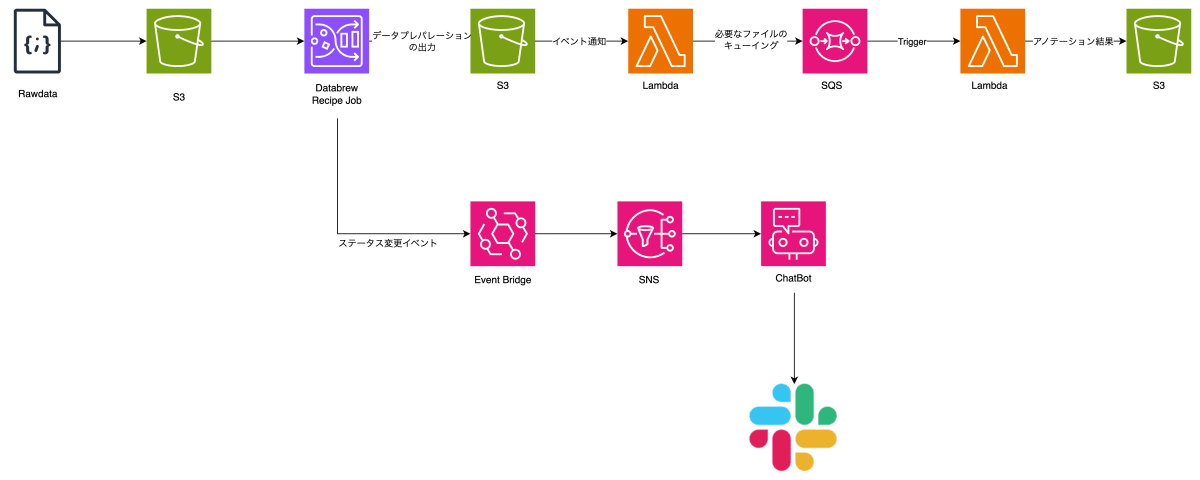
制御の都合で DataBrew と抽出ロジックの間に Lambda + SQS を挟んでますが、基本はこのフローです。
(他にもエラー通知や CloudWatchLogs などはありますが割愛しています)
AWS Glue DataBrewとは?
AWS Glue DataBrew はノーコードのデータクレンジングツールです。データプレパレーションのタスクを自動化できます。
類似サービスとしては、GCP の Dataprep by Trifacta があります。
DataBrew のフロー
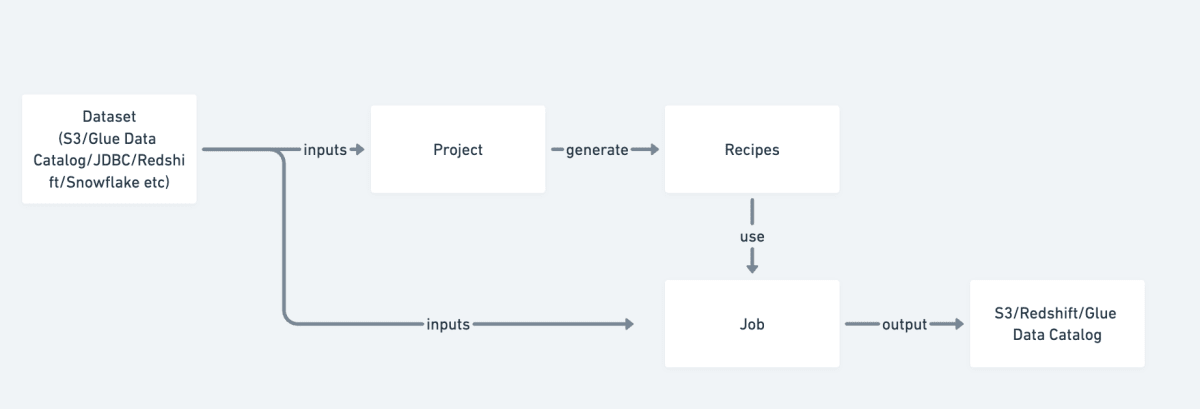
はじめに Dataset を定義します。
S3 など(Redshift などからの入力も可能)から CSV などのデータ(サポートしている形式)を読み込むとスキーマが自動検出されます。
プロジェクトを作成してレシピと呼ばれる変換ステップを作成します。DataBrew インタラクティブセッションでデータをプレビューしながら視覚的に変換ステップを実装できるのが最大のメリットです。
レシピジョブを作成して、データセットとレシピを指定して変換します。ジョブには簡易的なスケジューラがあり cron 形式で指定できるため、EventBridge Scheduler いらずです。
なお、レシピは、プロジェクトを作成して AWS コンソールの GUI で作成できますし、JSON/YAML でルールを定義して AWS CLI や SDK からアップロードを行うこともできます。
弊社では、初期作成はコンソール上で作成し動作検証がとれたものを JSON 形式に出力しバージョン管理しています。
(後述する CD を構築する上で、このレシピの分離は大変助かりました。本番でコンソールを操作してレシピの作成やジョブ実行のテストなど極力やりたくないですよね)
DataBrew インタラクティブセッションでレシピを作成する
S3 などから入力したデータセットを DataBrew インタラクティブセッションで開き、レシピと呼ばれる変換ステップを作成します。
セッションを開始すると読み込んだデータセットからスキーマ(カラム名や型)が検出され、スプレッドシートのような UI のサンプルデータビュー(グリッド)やスキーマのテーブル、そしてレシピ操作画面が表示されます。
次はスキーマ検出の例です。カラム名とデータ型が推測されたほか、データの品質や値の分散などの簡単なプロファイルが表示されます。
データサンプリングのサイズや方法を決めることで、スキーマ検出の精度を改善できます。データに大きな偏りがない限りはデフォルトの値でも十分な精度でした。
レシピは UI の操作で作成できます。ツールバーのメニューが多く、どの機能がどういう動きになるのかがわかりにくいので、最初は慣れが必要かもしれませんが・・・。
レシピの例
JSON 形式で、次の要件を満たすレシピのサンプルです。
- 重複行を排除
- user カラムのネストしたオブジェクトから id を抽出し user_id としてカラム追加
- title カラムの
[TEST]で始まる行を削除
[
{
"Action": {
"Operation": "DELETE_DUPLICATE_ROWS",
"Parameters": {}
}
},
{
"Action": {
"Operation": "EXTRACT_VALUE",
"Parameters": {
"path": "`user`.`id`",
"sourceColumn": "user",
"targetColumn": "user_id"
}
}
},
{
"Action": {
"Operation": "REMOVE_VALUES",
"Parameters": {
"sourceColumn": "title"
}
},
"ConditionExpressions": [
{
"Condition": "STARTS_WITH",
"Value": "[TEST]",
"TargetColumn": "title"
}
]
}
]
レシピの発行
レシピは AWS コンソールまたは AWS Cli などからレシピを発行できます。
AWS CLI では以下で発行できます。
# 初回
aws databrew create-recipe --name my-recipe --steps file://recipe.json
# 2回目以降
aws databrew update-recipe --name my-recipe --steps file://recipe.json
# 発行
aws databrew publish-recipe --name my-recipe
DataBrewで利用可能な変換メソッド
変換メソッドの種類は 250 以上あり、SQL や簡単な変換処理はおおむね実装されています。特に、機械学習の前処理で使うワンホットエンコーディングなどの計算処理や、個人識別情報(PII)まわりのステップが充実しています。
-
カラム操作の基本ステップ
- 移動
- 複製
- 削除
- 挿入
- ソート
- 型変換
-
クリーニングステップ
- 文字変換(大文字、小文字、キャピタライズ、センテンスケース)
- 日付フォーマット
- 文字追加(引用符号、プリフィックス、サフィックス)
- 文字抽出(デリミタ区切り、位置、正規表現、抽出)
- 文字削除(特殊文字、空白、任意文字 etc)
- 文字置換
-
データ品質ステップ
- フィルター(正規表現、電話番号・クレジットカード・郵便番号など)
- フラグ付け(正規表現、電話番号・クレジットカード・郵便番号など)
- 重複行の削除・フラグ付け
- 欠損値補完(平均値、中央値、最頻出、直近値、空白、NULL、合計値、任意)
- 欠損値削除
- 重複列の検出
- 特定カラムの重複行削除
- 値置換(平均値、中央値、最頻出、直近値、空白、NULL、合計値、任意)
-
個人識別情報(PII)ステップ
- 暗号化・復号化
- 暗号ハッシュ
- マスキング(日付、デリミタ内など)
- 行のシャッフル
-
異常値検出ステップ
- 異常値のフラグ付け
- 異常値削除
- 異常値置き換え
-
カラム構造変換ステップ
- カラム追加 (BOOL 値、case 文)
- カラムのマージ
- カラムの分割(デリミタ、位置、間隔)
-
カラムフォーマットステップ
- 数字
- 電話番号
-
データサイエンスステップ
- 2 値化 (閾値と比較)
- バケット化(数値範囲でグループ化)
- カテゴリの数値マッピング
- ダミー変数(ワンホットエンコーディング)
- スキューネス (歪度)
- テキスト分割
-
算術関数
- 絶対値
- 四則演算
- 指数対数演算
- 剰余
- 浮動小数演算
- 乱数
- 三角関数
- 論理演算
-
集約関数
- カウント
- 合計
- 最大・最小
- k 番目の値
- 平均
- 中央
- 最頻
- 標準偏差
- 分散
-
テキスト関数
- 数値テキスト変換
- マッチング
- 検索
- 文字列操作(繰り返し、トリミング、大文字および小文字変換)
-
日時変換関数
- タイムゾーン変換
- 算術演算
- 部分フィールド取得
- 現在日時取得
-
分析(ウインドウ)関数
- 前後値を利用した欠損値補完
- N 行前後の値取得
- 移動平均・最小・最大・個数
- グループ
-
Web関連関数
- IP アドレス↔数値変換
- URL QueryString の抽出
Recipe Jobの実行
レシピを作成した後にデータを変換するには Recipe Job を作成して実行します。
入力となるデータセット、変換に利用するレシピ、出力先(S3 の他、Redshift や RDB、Snowflake も指定可能)やジョブの実行環境を指定し実行します。
出力先も、上部毎に出力を分けたり、置き換えたりと柔軟な設定が可能になっています。
スケジューラによる定期実行も可能です。
DataBrewを運用する際の注意点
実際にプロダクションで運用する際は、GitHub Actions や IaC ツールを利用し自動化していると思います。弊社では、GitHub Actions と Terraform を組み合わせて Continuous Delivery(CD)パイプラインを構築しています。
その際に困ったことなどを中心に説明していきます。
DataBrewと他のサービスとの連携
AWS でのサービス間連携では AWS EventBridge を使うことが多いですが、DataBrew で EventBridge でイベントをハンドリングします。
以下のようなイベントが発行されます。
{
"source": "aws.databrew",
"detail-type": "DataBrew Job State Change",
"detail": {
"jobName": "my-datebrew-job",
"state": "SUCCEDED"
"jobRunId": "db_abcdefg0123455667........",
"message": "Job run succeded"
}
}
DataBrew に限らず EventBridge 全般でいえることですが、フィルタを適切に指定してください。
source, detail-type のほか detail の jobName でフィルタしないと、他のジョブが完了したのに通知されるなど想定外の出来事がおきるので要注意です。
(開発初期に、イベントを受信をトリガーに Lambda 関数を起動させていたのですが、意図しないパラメータで呼び出されることがあり調査に難航しました)
もし、複雑なワークフローや分岐が発生する場合は、ワークフローエンジンを使うことをおすすめします。Apache Airflow や Digdag などもありますが、別途サービスを起動する必要があるため、手軽にやるのであれば AWS Step Functions を使うと可視化できるので便利です(AWS も推奨しています)。
また、Slack 通知したい場合は AWS User Notifications 経由で設定できるとのことですが、弊社では EventBridge で捕捉したイベントを SNS 経由で AWS ChatBot に流し、Slack やメールに通知しています。
わかりやすい通知が届くので便利です。

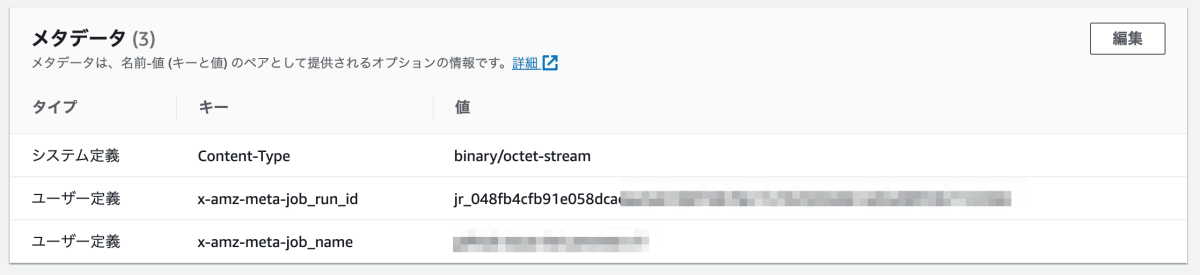
DataBrew JobのOutputがどのジョブが出力したのか知りたい
S3 の場合、オブジェクトのメタデータとしてジョブ名(キー: x-amz-meta-job_run_id) と Id (x-amz-meta-job_name) が保存されています。
調査や別の入力などでフィルタする場合に役立ちますが、EventBridge から通知される jobRunId と一部異なる(EventBridge では db_ だったのが jr_ になっている) ので要注意です。
TerraformでDataBrewを使う
AWS の IaC ツールとして Terraform を採用している組織も多いと思いますが、弊社でも Terraform を利用しています。
Terraform で AWS リソースを扱うには AWS Provider を使うことが一般的ですが、残念ながら 2023-10-26 時点で AWS Provider には DataBrew Resource は実装されていません。
代替として、 AWS Cloud Control (awscc) Provider を使うことができます。AWS Cloud Control Provider は AWS Cloud Control API の CloudFormation リソース定義から生成されるもので、サービス提供から比較的はやくに実装されます。HashiCorp 社により維持されています。
次は Terraform コードのサンプルです。
terraform {
required_providers {
awscc = {
source = "hashicorp/awscc"
version = "0.x.0"
}
}
}
provider "awscc" {
region = "ap-northeast-1"
}
resource "awscc_databrew_dataset" "my_dataset" {
name = "my-dataset"
input = {
s3_input_definition = {
bucket = "my-bucket"
key = "target-data"
}
}
format_options = {
json = {
multi_line = false
}
}
}
resource "awscc_databrew_project" "my_project" {
name = "my-project"
dataset_name = awscc_databrew_dataset.my_dataset.name
recipe_name = "my-recipe"
role_arn = "role arn..."
}
resource "awscc_databrew_job" {
name = "my-job"
role_arn = "role arn..."
type = "RECIPE"
dataset_name = awscc_databrew_dataset.my_dataset.name
recipe = {
name = "my-recipe"
version = "1.0"
}
outputs = [{
location = {
buckert = "output-bucket"
key = "output-key"
}
format = "JSON"
}]
}
AWS Cloud Control Provider は、API 呼び出し時のパラメータバリデーションを plan 段階では行わないため、AWS の API ドキュメントおよび開発環境でテストしてから適用することをおすすめします。 また、Terraform State にエラーした状態で保存されて壊れてしまうので、Apply でエラーが発生した後に再度実行する場合は state rm コマンド当該リソースを削除する必要があります。
さらに、レシピを作成・発行する機能については、AWS Cloud Control Provider では対応しておらず AWS Console か AWS CLI/SDK で行う必要があります。
terraform data と、local-exec provisioner をくみあわせて実装しました。
resource "terraform_data" "my_recipe" {
input = file("recipe_dir/my-recipe.json")
}
resource "terraform_data" "update_my_recipe" {
lifecycle {
replace_triggered_by = [aws.terraform_data.my_recipe]
}
provisioner "local-exec" {
command = "aws databrew update-recipe --name my-recipe my-recipe.json"
working_dir = "recipe_dir"
}
}
なお、Job の作成時はレシピのバージョンを明示する必要があります。そのため、常に最新バージョンを使うジョブを作りたい場合は、次のステップが必要になります。
- レシピを更新 (Apply 実行)
- 更新後のレシピバージョンを取得
- ジョブを更新(Apply 実行)
すべてを terraform で実装するには、Apply を 2 回する必要があります。
さらに、レシピのバージョン取得についても、Terraform の Data Sources で取得できないため、AWS CLI/SDK を使います。 以下の実装でおこないました。
#!/bin/sh
result=$(aws databrew describe-recipe --name my-recipe --no-cli-pager 2> /dev/null)
echo $result | jq -r '{ RecipeVersion: .RecipeVersion }'
data "external" "recipe_version" {
program = ["sh", "get_recipe_version.sh"]
}
課題点
上記で説明したとおり、DataBrew はデータプレパレーション処理を簡略化できましたが、いくつかの課題点もあります。
データ量によりコストが増える
DataBrew は RecipeJob の実行料金が、Glue に比べても 10〜40%ほど高く、Fagate に比べると同スペックのノードに対して 2 倍程度の価格差があります。
また、DataBrew インタラクティブセッションも 1 セッション 30 分単位で、セッションあたり 1USD かかります(ただし初回利用は 40 回のセッション無料サービスあり)
そのため、画面上でレシピを頻繁に編集したり、ジョブを実行する場合のコストに注意する必要があります。
増分処理ができない
DataBrew Job は、更新されたデータのみを対象にするなどの機能がなく、すべて洗い替えとなります。
どうしても増分処理を行いたい場合、データセットを差分のみに絞り、マージ処理を別に行うなど複雑さが増します。
ただし、今年 7 月に、AWS Glue Job上でDataBrewレシピを含める機能 がリリースされましたので、Glue Job を使うことで柔軟な運用が可能になると思います。
dbtの方が低コストで便利なのでは?
トランスフォームレイヤーについて dbt (Data build tool) という選択肢があったのでは?と思われるかたもいらっしゃるおもいます。
特に、すでに ELT フレームワークを採用している場合、Redshift 上での変換処理となるため SQL を使う dbt が有力候補となるかもしれません。
また、Athena を使うことで DWH を使わない場合でも dbt の恩恵をうけることができます。
ただし、dbt はただの CLI のため、dbt cloud を使うか、実装は ECS Fargate や EKS などコンテナを使う必要があります。dbt cloud は別途料金がかかります。
まとめ
本記事では、弊社システムにおける AWS の DataBrew の利用事例の紹介と、運用上時の注意点や課題点についてご説明しました。
AWS のノーコードのデータプレパレーションツールですが、レシピが分離していることや API-CLI と連携しているため、他のサービスとの連携がしやすい作りになっており、当該処理の実装を高速化し当面のスケール問題も回避できました。
一方、データ量の増加に向けてのコストの問題がありますが、Glue Job との連携などで回避策もありそうです。
DataBrew は、技術ブログなどで登場することも少なくマイナーな存在ですが、手軽にデータ分析を求められたときの参考になれば幸いです。

Discussion