序文
overflow で副業としてお手伝いさせて頂いている satomacoto です。
先日、Offers で機械学習を使うと良さそうかもというプロジェクトについてご相談を受けいくつかコメントさせて頂いたところ、意外とおもしろいということで、本稿を寄稿させて頂くことになりました。overflow での具体例を交えて機械学習プロジェクト取り掛かり方についてご紹介させて頂きたいと思います。
Offersでの事例の概要
今回の事例での状況は以下の通りでした。
- Offers 内でのユーザ行動からそのマッチングが成立するかどうかの確度を見積もりたい。
- 確度を定義するためにはいくつかのステップがあり、その中で面談に至りそうか判断し、面談マークをつけている。
- 現在はこの面談マークづけは手作業で行われている。
- スケールさせるためにもこの作業を自動化したい。
- 手作業で行っている状況の詳細は以下の通り。
- Worker(副業するエンジニア/デザイナー)と Client(採用する企業/担当者)のインタラクションの行動ログがデータベースに蓄積されている
- 面談に至りそうかというアノテーション面談マークを、ある行動に対して付与する
- どのような行動に対してアノテーションがつけるかという基準は明文化されていない
- 専任のデータサイエンティスト/ML エンジニアはいない
自動化するためには、どんなアプローチをとるにしても、何が正解となるかというデータが非常に重要な手がかりになります。今回の場合、面談に至りそうかどうかというアノテーションが具体的な特定の行動に対して付けられていたので、直感的には非常に取り組みやすい状況であると考えられました。
サービスインまでの流れ
プロジェクトに取り掛かる前にサービスインまでの流れを確認します。
- ベースラインモデルの構築
- ひとまず結果が出るところまで簡単でいいので作ってしまう。
- 何が、どれくらいできたらサービスに使えそうか判断するために、サンプルの出力を手作業で作ってしまって、アウトプットのイメージをある程度作っておくと、手戻りが少ない。
- モデル改善
- モデルの工夫
- 特徴量エンジニアリングなど
- サービスイン可否判断
- 運用に耐えうると判断できたらサービスに組み込む
- デプロイ
デプロイ後の改善サイクル 2~4 を繰り返すことまで見越しておくと良いかと思います。デプロイできそう&性能の改善サイクルが必要だったら、デファクトな MLOps のフローに乗っかっていくのがコスト的にも幸せになれそうです。
ちなみに、何を解決したいか、どんなデータを使えるか、どんなモデルに落とし込めそうか、どんな評価をすればいいのか、といったことを言語化しておくとブレずに進むことができると思います。
アプローチの選択肢と準備
今回の事例の場合、ClientとWorkerとのインタラクションを行動データに基づきを「面談マーク」を付けるかつけないかの二値分類 というタスクと見なせます。すなわち、面談マークをつける/つけないを判断するモデルを作ってみて、運用できそうであればサービスに組み込んでいくというプロジェクトになりそうです。
二値分類をするためには、たとえばルールベースによる手法と機械学習による方法があります。
- 機械学習
- 正例/負例の集合を訓練データとして機械学習する
- ググるためのキーワードは、二値分類、テキスト分類、ベクトル空間モデル、固有表現抽出
- 機械学習モデルは、scikit-learn、TensorFlow、PyTorch などを使って自前で構築、あるいは AutoML ツールを使って構築。構築したモデルをサービスに組み込む。
- ルールベース
- ルールベースは、たとえば、メッセージに「面談」「候補日」など特定のキーワードが入っている、メッセージに日付が含まれている、など、CS の方が面談マークをつけるための知識をコードに落とし込む
- 正規表現と IF-THEN ルールで作り込む、など
機械学習においてどのようなタスクと見なし、どのような手法を取れば良さそうかというのは、いろんなところでチートシートが用意されていたりします。
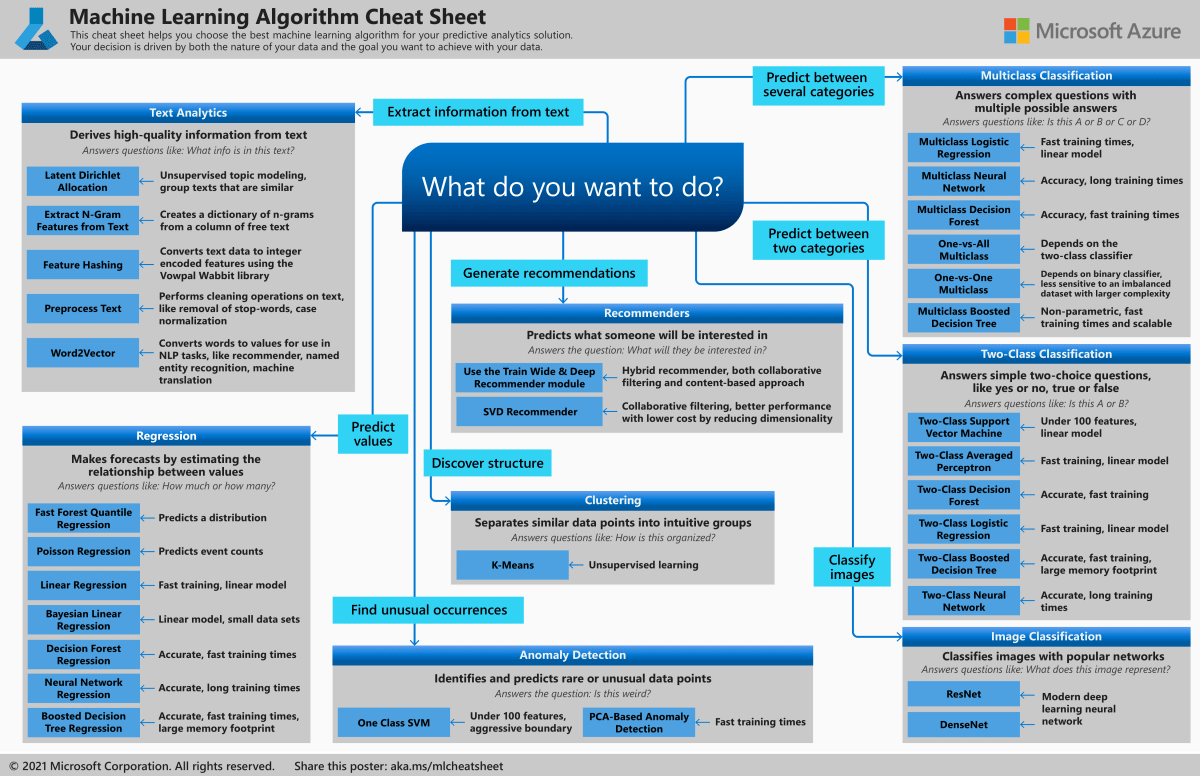
https://docs.microsoft.com/ja-jp/azure/machine-learning/algorithm-cheat-sheet より引用
どんなアプローチでやるか決めたら、データセットを整えます。データセットとはモデルを開発するために必要なデータ群のことです。
また何がどれくらいできたら正解なのかを定めるために評価関数も決めておきます。Precision が高い方がいいのか、Recall が高い方がいいのか、など。ただし、実際どんなアウトプットが出てくるかは、出してみないとわからないこともよくあります。精度が 90%がいいのか 70%でもいいのかは、意外と結果を見て使ってみるところまで行って初めて決まるものだったりもします。なので、軽くアウトプットを見てから固まっていくという方針でもいいかと思います。
対応案
以下は具体的にアドバイスした内容です。取り掛かりなのでまずは1週目の結果を出しに行くことを提案しました。
データセットの準備
モデルを作る/評価するためには正解データ(正例)だけでなく、不正解データ(負例)も必要です。以下を含むデータセットを準備します。
- 面談フラグのついている行動
- 面談フラグのついていない行動
かなりデータが不均衡になりそうなので、もし性能が出なかったら何らかの対策が必要になるかもしれませんでした。
参考
評価関数の設定
モデルの性能を表す評価関数を設定します。
- 正解率何%合っているか
- 精度面談フラグが付いているものの中で何%面談したか
- 再現率面談したものの中で何%面談フラグが付いているか
- LogLoss, AUC 出力を確率にしたときの正解の程度
もし機械学習に慣れ親しんでなければ、1 回結果を出してみて数値と感覚のマッチングの確認してから変更するのもありです。たとえば精度 90%というのがどれくらい合っているという受け取り方は、利用の目的によってかなり違います。
参考
機械学習モデルの学習
データセットと評価関数を決められたら機械学習モデルを開発していきます。結論をまず初めに取っ掛かりをとにかく早く進めるために、自然言語もデータセットに含まれていたので、以下のいずれかもしくは両方をやってみることを提案しました。
- AutoML、たとえば Vertex AI を試してみる
- テキスト分類の機械学習を自前でベーシックなものを実装する。Qiita とか Zenn にあるやってみた系でも最初は良さそう
専任の方がいなくて、手っ取り早くやるなら AutoML を使ってしまうと良さそうです。AutoML はデータを用意すればあとはよしなにやってくれるサービスです。テキスト分類が日本語に対応しているのだと楽です。機械翻訳してからでもいけるかもしれません。もし対応してなかったら自前で前処理する必要が出てきます。正攻法だと自分で scikit-learn や PyTorch, TensorFlow なんかを使ってモデルを組むと良いでしょう。
AutoML
大手の SaaS や IaaS、PaaS も出しています。以下はサービスの例です。今回は特に自然言語に関するモデルが構築できるものを選んでいます。普通の Web サービスに比べるとコストがかかる&ロックインされがちなので、どこも力を入れているように見えます。とはいえ、頑張って頑張って機械学習モデルを構築するよりもいい結果が出ることもあるので、初動だけでも金銭的に許せば、まずはこれらトライしてみる価値はあると思います。
-
GCP
-
いずれも日本語に対応していそう
-
Vertex AI
-
AutoML Natural Language
-
-
AWS
-
残念ながらテキスト系の AutoML は 日本語に対応していなそう。。。
-
手元でテーブルデータに変換できるなら AutoML もある
-
AutoML ではないが SageMaker を使う事例はいくつかありそう。前処理など必要になるので、自前で実装するのと変わらないかも。少しコストかかるかもしれないので注意
-
あとがき
今回は、機械学習専任の人がいないチームでの機械学習のプロジェクトの取り掛かりについて書かせて頂きました。一通りやってみたら、実際にサービスに入れられそうかどうか判断します。この辺は具体的な結果をお見せしながら、次の機会にでも書かせて頂ければと思います。

Discussion