本について
著者Kent Beck氏はソフトウェア開発領域の先駆者です。アジャイル、TDD、設計パターンはもちろん、JavaのJUnitといったテストフレームワークの開発者でもあります。この本では著者が経験則でまとめられている、より良いコードを書くためのリファクタをどうやっていくのか、のテクニックと運用法をメインにまとめられています。最後のパート3ではリファクタリングに関わるものに限らず、ソフトウェア開発設計上の考慮する理論について述べています。33章もあるものの、ほとんどが2-3ページのものなので結構読みやすかったです。もちろん、その分述べきれないトピックもあったりするが、読者にとっての思考のヒントになるのが目的として捉えて良いでしょう。
今回はその内容を振り替えしながら、学びや感想を書いていこうと思います。
テクニックと運用
パート1と2の部分がメインになります。コードをよりtidyにするためには、15個のテクニックがまとめられています。
ガード条件・前置き条件(Guard Clauses)
これは、本番の処理を始める前に、前置条件をクリアしていない場合に早期リターンする、とのテクニックです。
例えばインプットデータに対するバリデーションとか(if params is null then throw/returnなど)が考えられますが、これをやりすぎると逆に読みづらくなります。
仮にガードをひたすら書かないといけない、という時は、バリデーション自体を一つのレイヤーとして切り出すことを考えた方が良さそうです。
これについて以前自分は、controllerレイヤーにvalidationを入れるという考え方を強く持っていましたが、最近では「レイヤーに限らずより一般化で利用できるバリデーションのツールが良い」と思いました( Nest.jsのパターン がその例です)。
実行しないコードを削除(Dead Code)
これはシンプルにいらないという話よりも、他の開発者も含めチームや会社がそのいらないコードを書いたコスト、読むコストがかかるよ、との観点です。
「後から必要になるかも、だから残しておきたい」、については2つの観点があります。
- version controllの価値を考えてみよう
- YAGNIの原則を思い出そう
コードスタイルの統一(Normalize Symetries)
よく言われる話ですが、例えばJSの場合関数の定義にはfunction declaration/expressionといった複数のやり方があって、どれかに統一しよう、と。
これも読みやすさからの観点でいうと、一致しない場合は多少違和感を感じたり、その意図について困惑したりすることがあるからです。
リンターとかでは一部解決できるものの、ときにはチームのコード規約・ガイドラインとしてドキュメント化して、レビューなどを通して浸透していく必要がありそうです。
新しいインターフェース、古い実装(New Interface, Old Implementation)
pass-throughのインターフェースを作って、そのたかでは古いものを呼び出すことだけにする。多少、アダプターパターンと近い考えでもあります。
ただ、これをやるときに、今までのテストが落ちるかどうか、インターフェースの変更によって後方互換性を持っているかどうか、を十分に確認した上で行うべきだと思われます。
直近では実はその逆のことをやっています。とある機能を新しいAPIに移行しているのですが、古いAPIと共存する形で実装しています。というのは、新しいAPIの行為に関しては完全に明白になっていないため、随時切り替えや、ABテスト的なことが容易にするために、両者を共存させているのです(あくまでも一時的なものなので、永続化したい場合はfeature toggleとかのパターンを考えたいです)。外見上まさに、Old Interface, New Implementationになっているかと。
interface Params {
...
}
function funcA(params: Params) {
if (condition) {
_unstable_oldApi(params)
} else {
newApi(params)
}
}
多少別トピックにもなりそうですが、インターフェースを新しくしたいケースと、段階を踏んでひとまず変更しないケースもある、と思いました。
読む順番(Reading Order)
人間はどうしても時系列的に思考するので、コードを読む的にもステップバイステップで書かれると読みやすくなります。
もう一つの観点は、これはクラス、関数内部のシンボルの順番だけではなく、ファイル間も実は気にするべきものだと思われます。
ファイルの分割と命名も、ある程度この読む順番を意識して良いでしょう。実は今チーム内でdataformを使っていますが、そのファイルの命名はまさにステップを意識して、実行段階順にフォルダーに番号をつけるようにしています。
コードの読む時間が大半を占めるので、この辺りの心遣いがとても大事だと思います。
結合順番(Cohesion Order)
これも割と自然かもしれませんが、結合度の高いファイルや関数などを近いところに置くことです。
で、結合度を下げればよくないか(いわばdecoupling)、とも言われるかもしれません。ただ、結合度を下げるためには何かしらの設計パターンを運用して大きく構造を変える必要があったり、そもそもやり方がわからなかったり、チーム全体が今現在飲み込めるほどの変化ではなかったり、といった要因も考えられます。
それらの要因も考慮すると、結合度を下げることを目標とするよりも、結合度と向き合う(live with the coupling)方が優先になるかと。
宣言と初期化を同じところでやる(Move declaration and initialization together)
変数を宣言して値を付与せずに、どこかで初期化することが、よくみられるパターンです。
もちろん、クラスのプロパティ宣言のように、そうしないといけないケースもありますが、違う場所でやると混乱や意図しない問題の発生に繋がりやすくなります。
これと少し関連する話ですが、不可変の宣言を行うのが優先的に考えるべきです。例えばjsのようにletとconstの宣言のキーワードがありますが、const v;だけで値を付与せずに宣言することができません。
仮に条件分岐での値を付与したい場合も、letで宣言して、分岐内で値を付与するのがあまりお勧めしないパターンです。分岐内部で定義すればよく、上のスコープへのアクセスは本当に不要ではないか、の場合はほとんどです。
長い表現を変数に付与する(Explaining Variables)
これは変数の命名の話ではなく、表現(expression)が長くなる時は一つの変数に付与して読みやすくする話です。
例えば、とあるオブジェクトを定義する際に、時には計算を通してプロパティを決める場面があります。これを直接プロパティに計算をやるのではなく、まずは変数にしておきましょう、とのことです。階層が増えたりするとなおさら混乱に見えます。
// 🙅
return {
varA: process.env.SHOULD_USE_STRING ? a.toString() : Number.parseInt(a.toString(), 10),
varB: ...
}
// 🙆
const varA = ...;
const varB = ...;
return { varA, varB }
ただ全てやらないといけない、というわけでもないと思います。時にはa ?? 0とかかなり短めなものも全然アリかと。個人的な基準というと、フォーマッターによって改行されてしまう場合や繰り返しがある場合は別途おくのが良いかなと思います。
定数を活用する(Explaining Constants)
よくあるマジックナンバーとかの話も含まれますが、要は人間にわかる説明的な言葉で定数を命名して運用しましょう、とのことです。
例えば、並行実行する時に同時実行数のリミットを設定したい場合、ただの数字ではなく、その数字を定数化しよう、とのことです。
// 🙅
const res = await concurrentRunner(promises, 10)
// 🙆
// 別のファイル
const MAX_CONCURRENT_REQ_COUNT = 10;
// import ...
const res = await concurrentRunner(promises, MAX_CONCURRENT_REQ_COUNT)
個人的に思ったのが、読みやすさの観点から、ENUMもこの活用例と思って良いでしょう。
// 🙅
function getPostStatus(status: number): string {
switch (status) {
case 0:
return "Draft";
case 1:
return "Published";
default:
return "Unknown";
}
}
// 🙆
enum PostStatus {
Draft = 0,
Published = 1
}
function getPostStatus(status: PostStatus): string {
switch (status) {
case PostStatus.Draft:
return "Draft";
case PostStatus.Published:
return "Published";
default:
return "Unknown";
}
}
引数を明示的にする(Explicit Parameters)
ここで著者が主張したのは、からにmap/dictionary/object型の引数を、関数に渡している場合、明示的にどのプロパティ・キーを使うかを明示的にすることです。
この辺りは多少言語依存の部分があります。著者の例では、関数foo(params)を、foo_body(params.a, params.b)のように明記化することで、使う引数はなんなのかを明示的にしています。
言語依存というのは、例えばTS/JSの場合だと、 destructuring assignment ができるので、もう一つの関数で囲めなくてもどれを使うかは明示的になるのです。
もちろん、元々、必要な引数だけ渡すという意味では、params.a, params.bを取り出すことは最もです。
余談ですが、自分チーム内ではポジショナルパラメータを消極的に使っており、基本2つ以上になる場合はオブジェクトにしています。型がわかるのはもちろん、順番を覚えないといけなかったり(IDEにたすけてもらるが)、間違えたりするリスクもないのです。引数を明示的にする意味では、オブジェクト型が良い実践ではないかと思います。
コードをチャンクに分ける(Chunk Statements)
これはいわば、空白行をうまく利用して、「関心の近いコード」を一つまとめることです。
自分はよく併用するのは、ログやコメントを挟むことです。例えば、
logger.info('setup...')
const serviceA = ...
// 空白行
logger.info('step 1: ...')
await funcA(...)
// 空白行
logger.info('step 2')
await funcB(...)
長い関数は特にですが、これほど些細なことでだいぶ読みやすさが改善されます。
ヘルパー関数を抽出する(Extract Helper)
これもよく言われるもので、共通のものとか、粒度を下げることとか、ヘルパー関数を作ろう、と。
リファクタリング文脈ではもう一つのケースとして著者が指摘したのは、変更したい内容を関数として抽出するのはどうか、とのことです。実用性はともかく、確かに自分にはあまり意識していませんでした。
ヘルパーと呼べるかはともかく、関数の抽出について自分の中の基準として
- 共通するロジックで繰り返しに利用できる
- 関心がまとまっているコード群
- 長めになって読みづらくなっている
- 明らかに周りのコードとレイヤー・抽象度が違う
塊を作る(One Pile)
tidyという、整然にしたいことと言われると、結構コードピースを小さくする傾向・バイアスが生じやすいのです。これはかなり同意です。かつてClean Codeで「関数の行数を3行くらいまで!」(3章)と読んだ記憶があります。流石に無理すぎるのですが、小さくするという意図がかなり強く読み取れます。
その方向と相反して、著者が主張したいのは、時にOne Pileにまとまったやつにしたようが読みやすくなるよ!とのことです。
典型的な症状として
- 引数のリストが長い・重複
- 重複のコード、特に条件
- ヘルパー関数の命名がわかりづらい
- 共有される可変データ構造
がある時に、ひとまずコードを1箇所に置いてから、分割する必要があるか、どう改善するかを考える策が取れます。
といいつつ、自分には著者の症状基準について多少理解しづらく感じました。おそらく普段は別のアプローチ、例えば命名を練ること、抽象度を統一すること、コメントを活用すること、といったところを取っています。
ただ経験上One Pileにして読みやすくなるとのことはなくはないです。例えばテスト書く時に、テストデータが重複しやすいので、1箇所にまとめて変数に定義するか、ないしfixtureファイルに移動するか、といった分割意志の強いやり方があると思います。ただそのケースだと、どんなデータを使ってテストしているかが、パッとわからなくなります。重複になってもテストケースが長くなっても良いが、とにかくテストデータはテストケースの中で直書きしよう、との動きがありました。
コメントで説明する(Explaining Comments)
コメントは理解を増やすためには非常に重要なツールです。
いつコメントするかについて、著者は
- アハを感じた時 -> 難解なものをようやく理解した、その理解したものをコメントで書いておこうと
- 問題・欠陥を見つけた時 -> よく、TODOとかFIXMEとかのキーワードで書くのではないでしょうか
- ファイルにヘッダーコメントがない時 -> 一部の言語では慣習になっていると思いますが、このファイル・モジュールの存在意義を伝えるための場所になるので、もしなければ追加しようと
と上げています。
以前別の記事 でCDD(Comment Driven Development)との概念を言及していましたので、より詳しいコメントの使い方と実践についてぜひそちらを参考してください。
重複のコメントを削除する(Delete Redundant Comments)
これは同じコメントを削除することではなく、簡単いいうと、コードで自明なことは別途同じことをコメントで追加しないことです。
命名がある程度練っていると、そのまま伝わることが多いのです。コメントで書きたいのは、やはりコードで表現しきれないものになります。例えば、
- TODO, FIXMEなどの指摘、前述の問題や欠陥を補足すること
- NOTEなどの背景情報、なぜこの値に設定しているか、なぜこの実装、このAPIに採用しているかなど
- 関係の近いモジュールとの関係性(どこでどう使われているか)
などが考えられます。
マネジメント
パート1の内容について、紹介しながら自分の経験と感想を交えて書いてきました。パート2では主に、これらのテクニックをどう組み合わせでやるか、どの粒度でやるか、いつtidyを考えるか、などをまとめています。
リファクタコードの変更を出すタイミング
一つ大前提として、リファクタの目的もしくはメリットというのは、開発者にとっての読みやすさと、機能改修のしやすさ(最終的にコストパフォーマンスの経済的メリットにつながる)にあると考えられます。基本リファクタは、とある機能改修(behavior change)のために行われているのです。ここでよくあるパターンとして
- リファクタのコードを、機能改修と同じPRに出す
- 変更行数が多くてレビュー大変と言われる
- リファクタを別PRに分割
- リファクタのPRは意味わからない(Pointless)と言われる
- 最初に戻す
著者の観点として、リファクタのPRは、独立に存在すべき、かつなるべく少ない変更=小さくすべき、とのことです。
they go in their own PRs, with as few tidyings per PR as possible
より深いところにいくと、コード変更は基本、システム行為の変更(behavior change)とコードベース構造の変更(structure change)に分けられます。前者はいわゆる機能改修で、システムの行為自体が変わります。後者はシステムの行為から変更が観測されず、コードのみ変更が反映されます。
リファクタは機能改修のための準備として捉えられるため、PRを提出する時に、B(ehavior) -> S(tructure) -> B -> SSS -> BB -> Sのように、交互に作っていこう、とのことを提案しています。さらに、Sの変更について熟達してきたら、レビューさえしなくてもよくなります(もちろん、その場合は堅牢なテストCIが求められます)。
PRの適切なサイズは多少トレードオフがあります。開発サイクルの早いチームでは、レビューまでの時間が短いので通常より小さいPRにしても問題なく回れます。ただサイクルが早くない、もしくはレビュアーが限られている場合は、小さいPRにしても渋滞が発生します。また、分割をやりすぎると、コミット粒度のPRが作られてしまって、全体像やコンテキストが見えなくコメントしづらいこともあります。また、著者が行為と構造の変更をバッチにするスタイルを進めていますが、それもやりすぎると、競合解消や、意図しない行為変更ないしリファクタのリファクタが起こりうるのです。ある程度、レビューのコストとPRのサイズ(バッチ変更を含め)のスウィートポイントがあるはずだと。

自分のチームでは、PRサイズについて一応diff300行程度を目安にしています。それ以上大きくなる場合は、一つフィーチャー開発のブランチを切り出して、そちらにマージさせていくか、タスクの細分化を検討するか、との運用です。行為と構造のPR分けはしておりませんが、明示的な セマンティックPRタイトル を運用しているため、feat, refactor, chore, testといったタイプと変更スコープでPRの性質、影響範囲を制限することで、「詰めすぎてないか」の検知ができます。
連鎖(Chaining)
ここはパート1で紹介されたテクニックの併用パターンを紹介しています。例えば
- ガード条件・前置き条件(Guard Clauses)を作った場合、その条件自体をヘルパー関数または変数として抽出することがよく考えられます
- コードスタイルの統一(Normalize Symetries)を行った場合は、命名スタイルなどが一致するようになったため、関連性の高いコードを同じ箇所に移動するなど、順番調整もしやすくなるし、逆のパターンも考えられます。
- コードをチャンクに分ける(Chunk Statements)時に、ついでにコメント追加もやりたくなります。
- 塊を作る(One Pile)時に、チャンクに分けることで読みやすくしたいです。
- 長い表現を変数に付与する(Explaining Variables)時に、ついでにその表現を説明するコメントを削除することもできる。
などが挙げられています。
いつやるのか
結局tidyの変更はどのタイミングやるのか、について著者はいくつかの状況を列挙しています。
-
Never -> これは、このソフトウェアは生涯機能(行為)変更する必要がない場合に該当します。政府向けのウェブアプリとか?と思いつくでしょう。ただ、笑い話かもしれませんが、ちょうどコロナの時(2020年3月頃)に主流ブラウザーがTLS1.0/1.1へのサポートを中止すると宣言し、その後中国の政府のウェブサイトが閲覧できなくなってしまい、やむを得ず変更を撤回した、とのことがありました。つまり、自分たちが変わらなくても、世界が変わっています。生涯変更しないソフトウェアは、いずれ死ぬことを見越した上で、全くリファクタなしで良いでしょう。もしくは、「動けば良く、壊れた時にまた考える」とのスタイルになります。
-
Later -> 「あとでやる=いつまでもやらない」ことも思われるかもしれません。とにかくやってみよう。可読性、変更容易性が良いコードの一般的な基準でもあり、リファクタの目的にもなっていると思います。ほとんどのソフトウェアは機能変更が求められ続けるので、次の変更をやりやすくするための一歩になります。あと、非常に著者と同意ですが、リファクタをきっかけに学びになるし、何かの設計パターンとかを運用してリファクタすると、達成感が満ちて気持ちよくなります。
-
After -> 行為変更がすでに終わった、しかし汚い実装やハックがあったものだ。この時により良い書き方を思い浮かんだので、リファクタをやるべきなのか?は、状況によると著者は考えています。もし、すぐに同じ部分のコードに変更を加えようとしている、このタイミングでやるとコストが低い、行為変更が多いほどリファクタが大変になる、というケースだと、このタイミングでやるべきだと。
-
First -> 本作のタイトルにもありますが、❓がついています。答えは、状況次第です。リファクタして次の変更が容易になるのか、もしくはコードが読みやすくなるのか、であればやりましょう。あとは、変更内容とやり方が明白になっているなら、やりましょう。
理論と考え方
この部分はパート3になります。よく聞かれる設計のメリットの話はもちろんありながら、個人的に面白い視点もありました。
ソフトウェア設計の本質
著者は、ソフトウェアをメリットのある関係性をもつ要素(benefitially relating elements)として主張しています。
ここの要素はソフトウェアを構成するパーツでもあり、通常木構造のように階級を持っています。関係性を考える時は、要素の間には通常invoke, publish, listen, referといった関係性があります。もちろん、関係を築くことは何かしらのメリットがあるからです。
今まで行為と構造の言葉が何回も出ていますが、システムの構造というのはまさに、要素の階級、要素間の関係性、その関係性によって生じるメリットの3要素を指しています。
構造と行為
ソフトウェアの価値は2つの面で表されています。
- 今できること(what it does today)
- 将来できる可能性・選択肢(the possibility of new things we can make it do tomorrow)
そして、ソフトウェアの経済的価値はまさにその可能性・選択肢にあるわけです。環境が変化するほど、この価値が拡大されます。選択肢や可能性を支えるのは、拡張や変更に強いソフトウェアの構造にあります。
ただ問題は、構造の変更は行為の変更ほど合法的(legible)ではありません。ロードマップでは機能のことばかりリストアップし、決して〇〇をリファクタすることを入れません。
この部分は「ソフトウェアの価値」との視点から著者が構造=設計の重要さを主張していました。確かに自分の中には、今まで技術負債とか、変更容易性とかの言葉を重要視していましたが、経済的価値にはあまり着目できていませんでした。著者は他の説にも結構強調していて、例えば、読みづらいコード=読むには時間がかかる=企業がその時間に支払うことになる、といった観点とか。そういう意味だと、技術出身でない取締役に技術負債解消の一環としてリファクタの必要性を説明する視点としても捉えられそうな気がします。
結合度と凝集度
結合度(coupling)は、要素の間が緊密に関連することを指しています。というのはかなり誤解です。緊密に関連するという判断基準は、あくまでもコード変更時の話に限ります。いわば、Aを変更したら、B(s)も変更しなければならない、この時にのみ、結合度を考える意味があります。もし変更が起こらない場合、仮に近く関連しそうに見えても、結合しているわけではないと捉えても良いでしょう。
コンスタンティンの等式(Constantine's Equivalence)によると、ソフトウェアのコストはほとんど変更のコストに相当するらしいです。もちろん、これは極端なケースを除き、多くのソフトウェアにとって、リリース後は何もしないわけではない。運用保守が徐々に長くなり、ページUIの刷新、インフラの増築、APIの移行、アーキテクチャーの進化など、様々なレベルの変化が想定できます。時間が経つほどリリースまでの部分が小さくなります。
そしてさらに、変更の中で最も時間がかかるのは、ビッグチェンジ、の部類です。そのビッグチェンジとは基本変更の連鎖によるもので、つまり結合度に由来します。この式を整理するとなんと、ソフトウェアのコストは、大抵結合に起因する、との結論になるのです。
cost(software) ~= cost(change) ~= cost(big changes) ~= coupling
=>
cost(software) ~= coupling
言い換えれば、ソフトウェアのコストを下げるには、結合度を下げるのが大事です。
といっても、システム内で要素の結合は当たり前のことで、結合度を0にすること自体は不可能・無意味です。やはりスウィートポイントがあるはず。
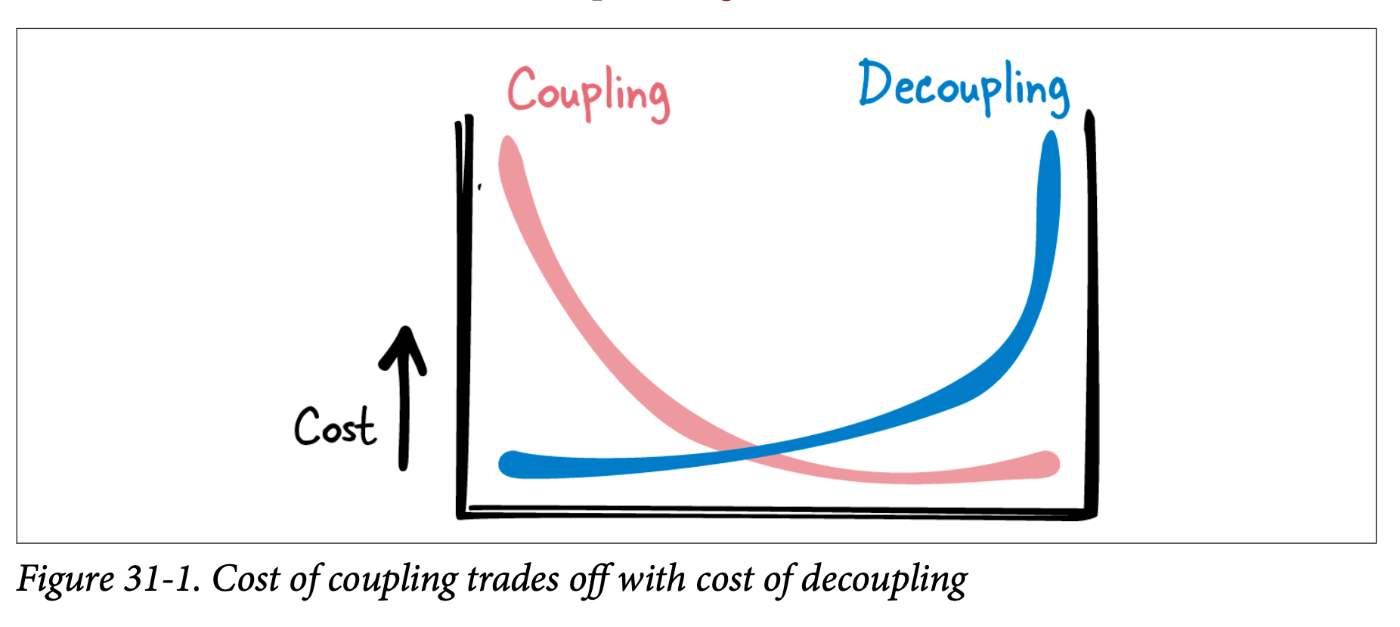
で、結合する要素を1箇所にまとめて、より高い階級の要素として抽象化することが、凝集度(Cohesion)が指しているものです。直交する(結合がない・関連性が薄い)要素は分割する、関心分離とか、よく聞こえますが、同じことだと思います。
結局、結合を下げる、凝集する要素構造を作るには、具体的にどうすれば良いか。に関しては、いわゆるSOLID原則とか、GOF設計パターンとかの領域になります。SOLIDを指導ルールとして見なし、GOFのパターンはその実践、との関係になります。このトピックについて過去には簡単に 紹介する記事 もあるので、よければ参考してみてください。
終わりに
著者はtidy firstに❓を意図的につけています。ソフトウェアのアーキテクチャーの重要性は耳に胼胝ができるほど言われていると思いますが、いつ・どのようにやるべきか、この本はむしろ関心を寄せています。もちろん、構造変更の大技の部分(設計パターンの実運用とか)に関してはすでに著作がいっぱいあるし、この本が着目するリファクタはあくまでも小技中心になっています。tidy firstやるべきかどうかは、様々な要因にかかっています。
- コスト -> コスト削減できるのか
- 収益 -> 収益に貢献できるのか
- 結合度 -> より少ない変更要素になって、変更しやすくなるのか
- 凝集度 -> より小さいスコープに要素がまとめられるようになるのか
- メンタル -> 開発者のあなたのメンタルに平和と満足感をもたらすのか
もう一つ大事な視点というのは、開発者は通常チームワークをしています。これらの小さなリファクタでも、他の人の仕事をよりやすくすることが、非常に価値があると思われます。Microsoft社がグレートSWEと思われるTOP5の特徴について論文を出しており、他の人の仕事を容易にする、少なくともやりづらくさせないことが入っています( 参考 )。
他の本と違って、いきなり設計パターンとか大技を教えるわけではなく、気軽にリファクタ可能な、スモールピースを持続的に届けられる、小技を中心に紹介しています。しかし、小技にしても、大技にしても、哲学レベルでは思想が一致するはずです。リファクタ、いわば構造変更は、開発者以外の人にはその価値を実感させることが容易ではありませんが、この本は割とその経済的価値わかりやすく伝えていると感じました。何よりも、開発者のメンタル満足感、チームへのポジティブな影響が、tidyをし続ける原動力になるのでしょう。

世界のラストワンマイルを最適化する、OPTIMINDのテックブログです。「どの車両が、どの訪問先を、どの順に、どういうルートで回ると最適か」というラストワンマイルの配車最適化サービス、Loogiaを展開しています。recruit.optimind.tech/
Discussion