Philosophy of Software Design 感想
前の連休で、Philosophy of Software Designとの本を読んだので、感想も多々あり、この記事を書くように思った。
多少章の繋がりとアレンジに違和感を覚える箇所があるものの、全体的に結構説得力のある観点が多いと感じている。良い設計をするために、複雑度を下げるのが必要だ。その複雑度とは何か、どうやって下げていくのかについて、さまざまな観点から、細かい例も含めて説明している。
ここは本の内容をまとめながら、自分の経験と感想を交えて書いていきたい。
ソフトウェア設計における複雑度
著者は1章から、ソフトウェアの設計と開発手法からまず問題を提起している。
Because software is so malleable, software design is a continuous process that spans the entire lifecycle of a software system
この性質のゆえ、ヲーターフォールのような、設計を開発プロセスにおける一回切りのフェイズだけ捉えている手法には根本的な問題がある。一方で、アジャイルのようなインクリメンタルな開発アプローチが、全体の一部から設計と開発を始め、毎回のイテレーションにおいて問題を曝して軌道修正していく手法をとっているので、自然にソフトウェア開発に適している。インクリメンタルなアプローチを採用することを言い換えると、software design is never done とも考えられる。
ソフトウェアの設計を常に考える、と思いつつ、何を考えるのか、は次の質問となるだろう。著者は、良い設計をするために、複雑度を下げるというのはソフトウェアの設計における最も重要な課題・要素だと主張している。そのため、設計を常に考える=複雑度を下げることを常に考えることとも言える。
この複雑度を下げるために、概ね2つのアプローチがあると。
- コードをシンプルに、読みやすくする(simpler and more obvious)。
- 複雑な実装をカプセル化する(encapsulate the complexity)→モジュールデザイン(modular design)とも。
具体的なテクニックや考え方・マインドセットについては色々とあるが、先に複雑度の本質とは何かを考えておく必要がある。
複雑度の本質
2章では複雑度の本質(the nature of complexity)というタイトルとなっている。複雑度の定義について、実用的な側面から、理解しにくいかつ修正しにくいあらゆる要素が複雑度として見られると述べている。
Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system
一方で、ROIの観点から見れば、複雑度を、コストと利益(cost and benefit)として考えることもできる。複雑なシステムには、小さな変更にも多大な労力が掛かるに対して、シンプルなシステムには、大きな変更にもさほど大変な作業にはならない(若干理想的に言えば)。また、複雑度は、システムの規模と必ずしも相関しているわけではない。大規模なシステムは、ほとんどの場合難しいと言えるが、小規模なシステムでも、必要以上に複雑になることがあり得るからだ。
この複雑度を数式で表すと、次の通りとなる。
仮にシステムにはnの部分があるとし、それぞれの部分の複雑度cに、開発者がその部分に費やした時間投資tをかけた結果を集計したものだと。
また、理解しやすさというのは、書いた人が判断するわけではなく、仮に他の開発者が読んで分かりにくいと思うと、そのコードが分かりにくいコードである。ただ、これはある意味で、なぜ分かりにくい、どうしたら分かりやすくなるという問題意識のきっかけにもなるので、決して悪いことだと捉える必要がないだろう。
3つの症状
複雑度は概ね3つの症状に現れている。
- 変更連鎖(change amplification) 例えば、一つの機能を改修する為に様々な違う箇所の変更が必要となるケースがそれに当たる。
- 認知的負荷(cognitive load) 開発者がタスクを遂行する上でどのくらいの知識を持たないといけないかとして定義されている。当然、知っておかないといけないことが多ければ多いほど、負荷が高くなり、複雑度も増していく。この側面で言えば、同じ機能を実現するために必ずしも行数の少ないコードが良いというわけではなく、認知的負荷を軽減できるかどうかにかかっている。
- 不知なる不知(unknown unknowns) これは、タスクの遂行時にどこを変えれば良いか、何を知っておかないといけないか、が分からない状況を指す。言うまでもないが、これは3つの症状の中でも最悪なパターンとなる。
複雑さの起因
複雑度は概ね2つの起因をもつ
- 依存性(dependencies) 広く言えば、コードピースが単独で(in isolation)理解または変更することができない場合は、依存性が存在すると認識できる。なんらかの形で他のコードなりドキュメントなり情報を取らないといけないことなので、開発中に使うdependenciesのことだけには限らない。もちろん、依存性をなくすことが当然できないが、複雑度を下げる意味で、依存関係をシンプルかつ分かりやすくすることが目的となる。
- 曖昧性(obscurity) 曖昧性は、重要な情報が明らか(obvious)ではない時に生じる。これは多くの場合、ドキュメンテーションが足りないことに起因する。または、コードルール上の一貫性が欠けていると、同じ問題に導く。しかし、ただドキュメンテーションを増やして良い問いことではなく、良い設計にはいっぱいドキュメントが必要ではないケースが多いからだ。結局、シンプルな設計が曖昧性を下げることに最も重要だと。
この2つの起因により、上記の3つの症状が生じている。
tactical vs strategic
さらに軽視してはいけないのが、複雑度は累積していく(incremental)ものだ。一つずつ、とにかく早く出せ、動けば良いや、という時の積み重ねで、イテレーションが進む中ですぐに膨らんでいく。また、割れ窓理論のように、一人の開発者が複雑度の増加に気にしない行動を取ると、他の開発者も似たような策略をとってしまい、複雑度の増加が加速してしまう。やがて膨大な技術的負債になり、返さないと割とすぐに報われる。この累積に歯止めをかけるためには、容認なし(zero tolerance)のマインドセットが必要なのだ。
3章では、複雑度の累積を避けるために、より高いレベルのコーディング戦略について述べている。ここで、著者は策略的プログラミング(strategic)と戦術的プログラミング(tactical)と分けている。strategicとtacticalの意味合い的に若干近い部分があるので、このままでは分かりにくいかもしれないが、要するに、
| 戦術的プログラミング | 策略的プログラミング | |
|---|---|---|
| フォーカス | 早急な開発とバグ修正 | 長期的なシステム構造と拡張性 |
| 時間と努力 | 最初は時間が少ないが、将来的には問題が増える可能性 | 最初は時間がかかるが、将来的にはメンテナンスが容易に |
| デザインの考慮事項 | デザインパターンにはあまり重きを置かない | デザインパターンに重きを置く |
| 潜在的な欠点 | 時間とともに問題が増え、開発速度が遅くなる可能性 | 進行が遅くなる可能性 |
そのため、開発リソースの投資との意味で言えば、長期的にstrategicの方が有利になるはず。と言いつつ、これは若干理想的すぎていると自分は感じている。著者が大学の教授で、実際のIT会社でどのような現場的な事情があるか、実際に経験しないとやはり理想論を言ってしまうのではないかと多少は感じている。正しいのは間違いないが、著者が主張するように100%で策略的なマインドセットに行くことがかなり難しいだろう。例えば、こちらの作者が、8:2の割合で、むしろスピーディな戦術的マインドセットを薦めている。ここの割合は多少調整する余地があるだろうが、100%の戦術的なマインドセットは絶対に勧められず、すぐに技術的負債に追われてしまうような羽目になるだろう。
自分は割と設計に気になる方で、時間の許す限り、現時点のコードベースの規模と解決したい課題を考えて、それに適しているアーキテクチャや設計は何かについてグラフ化・ドキュメント化し、チームで議論して結論づけている。もちろん、良い設計はイテレーションで改善されていくので、「完璧」でなくて良い。ここのtrade-offも、毎回悩ましいが、良い経験にはなると信じている。
深いモジュール(deep module)
modular design
4章からは、モジュールの設計について多く書いている。その中核に置く思想として、モジュールの中身は深く(deep)、代わりに外部に曝すAPIはシンプルにすることに集約できる。もちろん、この思想はOOPのカプセル化や抽象化と共通している。プログラミングパラダイムと関わらず、複雑度を下げる意味で、利用する側に内部の複雑なロジックを隠すところは同じなのだ。
理想的には、モジュールがお互いに完全に独立し、依存関係がない設計となっている。が、これは当然不可能で、システムの動きは様々なモジュールの連携によって達成するもので、モジュールの間にコミュニケーションが必要であるため、必然的にお互いのことを知らなければならない。依存性の発生は、モジュールAが変わったことにより、モジュールBも変えないといけない、からとなる。
不可避な依存性を管理するためには、モジュールは基本インターフェイスと実装との2つの部分で考える。インターフェイスは、モジュールが何をするか(what)を定義し、実装は定義された動きをいかに実現するか(how)を指す。以前契約式設計について書いていたが、その契約の部分はまさにインターフェイスとなっている。
この管理の仕方には2つのメリットがある。
- 外部に曝す複雑度が最低限に抑えられる=呼び出す側に必要な情報を最小限に
- 仮に実装で変わったとしても、インターフェイス=契約を守っている限り、他の依存モジュールに変更を行う必要がない
1つ目は先ほど触れたカプセル化と抽象化のことだと認識できる。つまり、インターフェイス=モジュールの抽象化として考えられる。複雑度解消との意味で、前述の原因3つ目の不知なる不知の解消にも直結できる。2つ目はSOLID原則の依存性反転(dependency inversion)とも考えられる(こちらの例に参考)。これは複雑度の原因の1つ目の変更連鎖に役立つに違いない。
深いモジュールの形
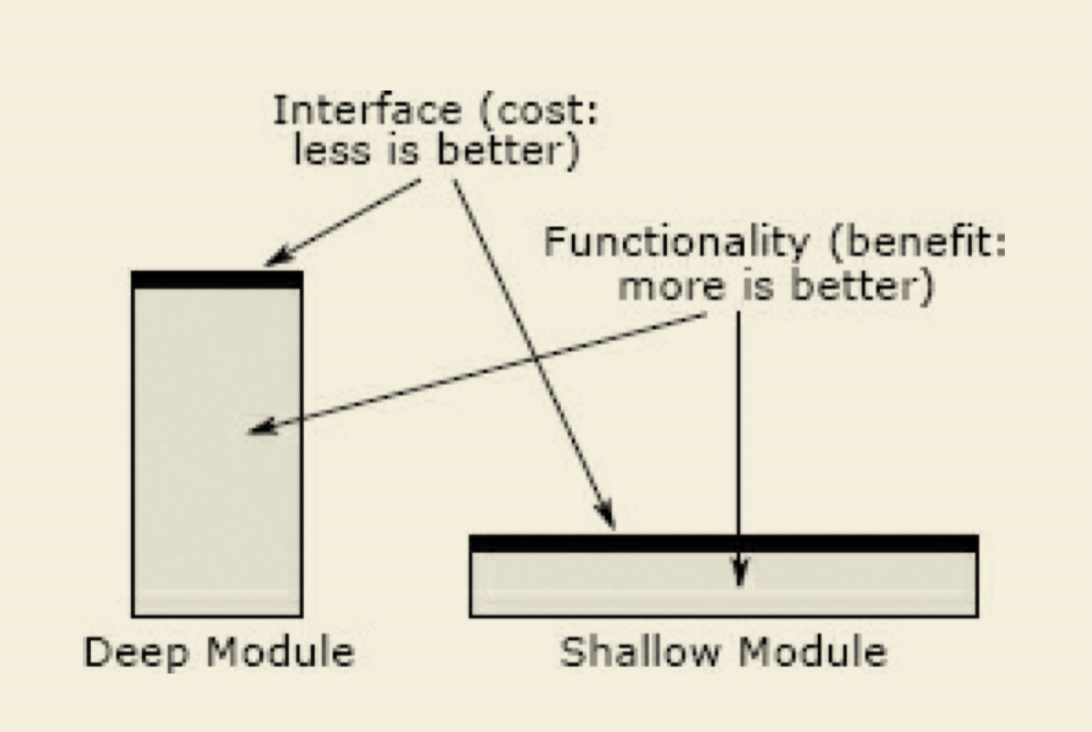
Module depth is a way of thinking about cost versus benefit
モジュールの実装について、著者はdeep moduleと強調している。コストとベネフィットの面で考えると、モジュールの機能はベネフィット、インターフェイスはコスト(複雑度の観点から)として考えられる。ここでUNIX系OSのfile I/Oのインターフェースを例として挙げられている。
int open(const char* path, int flags, mode_t permissions);
ssize_t read(int fd, void* buffer, size_t count);
ssize_t write(int fd, const void* buffer, size_t count);
off_t lseek(int fd, off_t offset, int referencePosition); // change pointer position
int close(int fd);
非常にシンプルなインターフェースで、複雑な実装を抽象化できている。このような美しい設計は、何十年経ても変わらないままでいられる。
ただし、インターフェイスが多い=間違い、インタフェースが少ない=正しいというわけではない。判断の基準はやはり、インターフェースで定義されている関数には、機能面の交差と重複があるかどうか、重要な情報を省略しているかどうか、知らなくて良い情報が含まれているかどうか、とのところにあるかと。この辺りは、5章周りのhiding and leakageで詳しく議論されている。
一般的目的(general purpose)のモジュールを設計するときに、現在の需要に基づいていくつか自分に問いかけてみると良い
- What is the simplest interface that will cover all my current needs?
- 注意点として、単純にインターフェースで定義する関数の数を減らして、逆に関数の引数を増やすというのはシンプルにならない
- In how many situations will this method be used?
- 仮にレアケース、コーナーケースのために1つの関数が存在すると、これは一般ではなく特定目的(special-purpose)になってしまう
- Is this API easy to use for my current needs?
- 上記のfile IOの例のように、定義された関数で全ての需要が満足できると良い
抽象化のレイヤー
今までの話よりも現実味をもつ抽象化のレイヤーについて、7章で述べている。実際のシステムでは、抽象化が一回で終わることがなく、複数のレイヤーに分けられている。このレイヤーの切り分けも、システムの複雑度を下げるためにかなり有用である(認知的負荷軽減)。
例えば、ウェブアプリケーションのバックエンドでは、ウェブレイヤー→ビジネスロジックレイヤー→データアクセスレイヤーとのように分けることがある。各レイヤーがそれぞれに責務を果たしており、処理の流れに応じてレイヤー間のコミュニケーションが発生する。最終的に、フロントエンドへ曝すインターフェースとして、APIのエンドポイントとHTTPリクエストのメソッドの形に集約される。
似たような例がCSの世界に山ほど存在する。OSIモデルのネットワーク通信プロトコルの階層構造とか、ファイルシステムとかプログラミング言語ももちろんそれにあたる。
違うレイヤーを設計する際に、問題をどう発見するか、どう対処するかはここで議論されている。
通り抜け(pass-through methods/variables)
仮に抽象レベルでA->B->Cのレイヤーがあるとする。Cで必要な情報を、AからBを経由して渡しているか(通り抜け変数)、AとBは何もせずただCの関数を呼び出している(通り抜けメソッド)ケースを指す。しかし、AとBでは全くその情報を利用しない=知る必要がない。これは抽象レベルの混乱になっているため、レイヤー間の責務の切り分け・定義がはっきりになっていないのが原因となる。
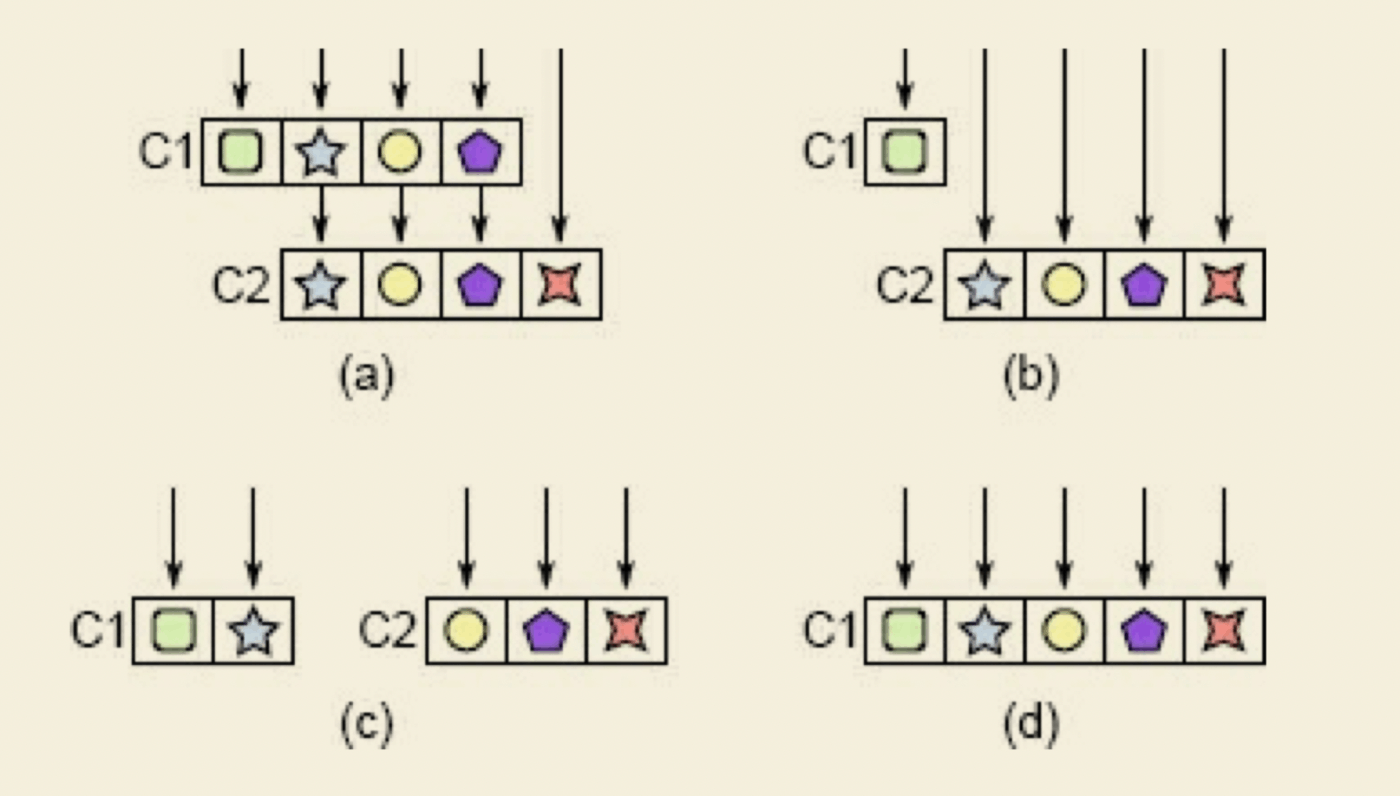
上記の図のように、解消するためにb, c, dの方法が挙げられる。
ただ、通り抜けメソッドが全てアウトとは言えない。これと関わっているdispatcherのパターンが存在する。例えば、HTTPリクエストに対して、同じエンドポイントであっても、GETとPOSTとかのメソッド次第で処理が違ってくる。この時にdispatcher(Django, Laravel, Railsなどかなり多くのFWに採用されている)が有用である。という意味で考えると、dispatcherはリクエストの振り分け役として、一つの抽象化のレイヤーとして考えられるだろう。
また、通り抜け変数について、Reactのprops drillingが例として挙げられる。解消のために、コンテキストオブジェクトのパターンが運用されるようになり、アプリケーションのインスタンスにとってグローバルなアクセスができるようになる。著者はコンテキストオブジェクトがこの問題の完璧な正解だと考えていない、一つの問題点としてはレースコンディションが生じるからだ。だからこそ、コンテキストは不可変(immutable)にする必要がある。と言いつつ、現時点でより良い案がまだ考案されていない。
デコレーター
デコレーターをシンプルに言えば、汎用機能を指定する関数・クラスに追加するラッパー(wrapper)である。本来このパターンは、OOPの観点というより、AOP(aspect oriented programming)の観点から、横断的な汎用機能を簡易に提供するために作られている。これは濫用すると、モジュール内で至る所で使われてしまい、切片から積み上げられたシャローモジュールに変貌してしまう恐れがある。
デコレーターを作る前に、本当の汎用機能とは何かについて考えた方が良いかもしれない。この線引きがかなり難しいが、一概には言えないと思う。少なくとも自分の経験から、以下のようなケースなら運用して良いかと
- logger/debugger/profiler デバッグやログのためには基本良い運用例
- rate limiter 特定のAPIに対してかけるのが便利
- retry/backoff 上記と対になっている
- cache コストの高い・重複性のある計算に
- plugin 本となるオブジェクトの機能拡張、flask/fastAPIとかで見られる
@app.get('/')とかもこれにあたる - validation 認証とかも含め、関数実行する前・後のパラメーター・結果確認->ただウェブアプリだとミドルウェアのレイヤーとして抽象化するのが多いので、必ずしもデコレーターにする必要がないとは思う
- error handler try/catchを1回に集約するが、実運用で汎用できるようにエラークラスの設計に工夫が必要
複雑度を深いところに置く(pull complexity downwards)
it is more important for a module to have a simple interface than a simple implementation
本の8章あたりに述べている。割と自明なことかなと。
一緒にするか分割にするか
9章では、機能分割について議論されている。この問題についていくつかの指針が考えられる。
- 重複利用性:複数のモジュールで利用されることであれば、その機能を抽象化して分割した方が良い。general purpose <=> special purpose。
- 直交性(orthogonal):機能の間に関連を持たないのであれば、分割した方が良い。逆に言えば、関連性のあるものを一箇所に集約したい。これは凝集度(cohesion)の考えにも近い。AとBの間に関連があるかどうかを考えるときに、AがないとBが理解できない(逆も然り)問題が存在するかどうかで判断できる。
- シンプル化:仮にAとBを一箇所に置くと、インターフェースがシンプルになるのであれば、一緒にするのが良い。逆に特にメリットが感じられないのであれば、分割のままでも良い。
エラーハンドリング
これも複雑度を増す悪の一つだと著者は主張している(10章周り)。ただ、エラーは必ず存在するもので、対処しなければならい。
エラーの処理は通常のコードよりも難しい。その理由とは
- 原因は全て挙げられない(キャッチできない)→ これに派生する問題としてインターフェースが違うカスタムエラータイプをいっぱい定義する
- エラー処理時に更なるエラーを生み出す可能性がある
- エラーの種類に応じて、処理して良いか、プロセスを終了した方が良いかは分かれる
- 処理する場所を間違いやすい
エラー処理の複雑度を下げるために、ここで著者はいくつかのテクニックを紹介している
- エラーの存在をなくす(define errors out of existence)。例えば、deleteというAPIがあるとして、そのリソースが存在しないときに、エラーがスローされている。deleteのインターフェースは何をすれば良いかと考えると、該当リソースを削除するから該当リソースが存在しないのを確認するというように変更すると、このエラーをスローするよりも、結果をtrueにリターンすれば良い(もちろん、意図的にエラーを知らせたい場合は論外)。実際にSQLのDBにもこのように実装されていて、仮にレコードが存在しなければ何もしない(削除されたレコード数0をリターンする)。似たような例は、jsのsplitメソッドも見られる。
- 外部に曝すエラーを減らす(exception masking)。これはエラー処理の箇所を統一する話ではなく、モジュール内部とかのローレベルでエラーを適切に処理することで、エラーを隠すことである。例えば、TCP通信でいろんな理由でパケットがなくなることがあるが、その都度エラーを出すというわけではなく、再送するように実装している。また、分散システムでレースコンディションを避けるためにロックの獲得でリトライ機能を入れると似ている。
- エラー処理の箇所を統一(exception aggregation)。いたるところで重複しているエラー処理ロジックを一箇所に集約する考えである。ほとんどのウェブFWがユーザーがハンドリングしない場合エラーを捕獲する機能を提供している。前述のdispatcherパターンを例にすると、一つのリクエストに対して、POST対応のメソッド、GET対応のメソッドにおいてそれぞれエラー処理を書くというより、dispatchのレベルでやった方が良い。express.jsとかでは、エラーハンドリングのミドルウェアを全てのリクエストの最後に置き、そこで集約的に処理するのがよく見られる。
- プログラムを終了する(just crash)。一部のエラーは処理しようもないので、直ちにプログラムを中止にすれば良い、とのこと。例えば、メモリーが足りない(out of memory)とか、今時のPCスペックにはほぼあり得ないはずなので、アプリのバグだと認識しても良い。ほとんどのI/O系のエラー、例えばファイルの読み込み、ネットワークソケットをオープンするとか、リカバーする用がないものに対して、エラーハンドリングではなく、きちんと原因のメッセージを書いてプログラムを終了にするのが適切なのだ。
もちろん、根本的にシステムをシンプルにすればエラー処理もシンプルになる(当たり前ではあるが)
Comment Driven Development
TDDのように、CDDも考えられる(もちろん実在)。この言葉自体は著作の中に出ていなかったのだが、かなりの章(12, 13, 15, 16)でこれについに述べている。
なぜコメントを書くのか
コメントは開発者がシステムを理解する上でかなり重要である。認知的負荷の軽減との意味でも、複雑度を下げるに貢献している。さらに、コメントを書くことを正しくできると、設計を改善することにつながる。
ただ、この認識は広く認められているわけではなく、様々な理由でコメントを書かない開発者がいる。例えば、
- “Good code is self-documenting.”
- “I don’t have time to write comments.”
- “Comments get out of date and become misleading.”
- “The comments I have seen are all worthless; why bother?”
それぞれの主張に対して著者は反論している。
良いコードは自明のはず
残念ながらこれは理想にすぎない。コードで表現できない設計上の考え方が多すぎる。GOFパターンを見たことのないジュニアエンジニアに、何かのパターンを見せて、別途情報なしでなぜこう書くのか、ほとんどの場合は理解しようもない。コードで自明するのは、そのコードで処理したいロジックであり、設計がどれほど伝わるかはだいぶ経験によるものになる。
また、コメントはインターフェースの抽象化において理解を支える立場にある。開発者がインターフェースを見て、結局どう使うかを知るために、実装コードを読まないといけないのであれば、インターフェースが実装の複雑さをカプセル化という観点から、抽象化が失敗している。OSSのFWなどのソースを読むと、ほとんどのインターフェースなどにコメント(ドキュメント)がちゃんとついている。他でもなく、良い実践だからだ。
コメントを書く時間はない
機能開発時に時間が押している場合によく見られる言い訳になる。ただ、開発者自身の整理にも、他の開発者のためにも、1割程度の時間をコメントに費やして、そのリターンがだいぶ大きい。というのも、0-1のフェーズでの機能実装によるタスクが、ソフトウェアのライフスパンから考えて、非常に少ない部分となる。開発者の大半の時間は、コードを書くより読んでいるからだ。コメントは、この「読む」体験を向上させるのに不可欠な部分である。
コメントがメンテされないと事実と食い違いが生じる
コードレビューちゃんとしろ!
価値のないコメントしかない
なら価値のあるコメントを書く。コードで自明する部分は繰り返す必要がない。コードで説明しきれない部分を丁寧に書くことによって、読む側の認知的負荷を下げるのが価値のあるコメントになる。
コメントを書く理由
The overall idea behind comments is to capture information that was in the mind of the designer but couldn’t be represented in the code.
一言に言えば、コードで表現しきれない設計者の考えを掴むことができるからだ。この本の主旨、複雑度を下げる観点からだと、認知的負荷の軽減と、不知なる不知をなくすことができる。
コメントをどう書くのか
すでに「なぜ」の部分である程度明らかになっていると思う。理想の状態として、インターフェース・シグネチャ+コメントだけで、実装コードを見ずにこのモジュール・関数の機能がわかるのが良い。この目的を達成するために、いくつかの実践が挙げられている。
- 慣習に従う。言語それぞれのドキュメントを書く慣習があり、そのガイドラインを実現するためのプラグインなどもある(jsdoc, godocとか)。
- コードを繰り返さない。前述しているが、すでにコードを読んで自明なことをもう一度コメントで書く必要がない。DRY原則にも反している。
- ローレベルのコメントで精度をあげる。これも抽象化への理解との意味で、より詳細な説明が良い。自分がよくやるのは、定義を書いた後に、e.g.とかで具体例を追加することだ。例えば、URL解析の関数を書いたとして、そのコメントに具体的にどんなURLが対象なのか、例として挙げると解像度が非常に上がる。
- ハイレベルのコメントで直感的にする。自分の結論でもあるが、誰が何をする(who & what)、という形で一言でまとめよう。
コメントの種別で見る
ほとんどのコメントは4種類のカテゴリーに分けられる。
- インターフェース
- ハイレベルの説明はまず簡潔に書く
- 引数とリターン値について精確に書く、特に制約があるかどうかを
- 副作用がある場合はきちんと書く(あれば)
- スローするエクセプションを書く(あれば)
- 呼び出しのための前提条件を書く(あれば)
- データ構造の属性(data structure member)
- 例えばクラス・オブジェクトの属性についての説明とか
- 実装コメント(implementation comment)
- 例えば関数内部でアルゴリズムのステップをコメントで書くとか
- 目的は読む側に、whatを理解させるため、howではない
- ただ個人的に、whyも入れたりすることがあり→特に何らかの理由で意図的に通常の実装法ではないアプローチを採用するとき
- モジュール間コメント(cross-module comment)
- 例えば他の依存モジュールの説明とか
- 何を書くかというより、どこに置くのかが一番の問題→著者はdesignNotesとのファイルに置くことを案として出しているが、OSSのソースを読む感覚だと、ファイルの一番上に書くのが多い気がする
その中でインターフェースとデータ構造の属性のコメントが最も大事となる(後ろの2つももちろん良い実践となる)。
コメントファーストの実践
TDDでテストを先に書くように、CDDはコメントを先に書く。コメントを設計のプロセスとして考えるのが最もらしい。
強調したいのは、コメントは先に書かないと、後から補足したコメントは基本的に良いコメントにはならない。時間が経てば経つほどこの傾向が強い。当時の考えを思い出すために辛いかもしれない。自分の考えを整理するステップでもあるので、設計の楽しみが感じられると個人的に思う。
ここで著者は自分がクラスを作成するときの実践ステップを例に挙げた。
- インターフェースのコメントを書き始める。
- 最も重要な公開メソッドのインターフェースのコメントとシグネチャを書く→メソッドの実装は空のまま。
- これらのコメントについて正しいと感じるまで練り直す。
- 最も重要なクラスインスタンス変数の宣言とコメントを書く。
- メソッドの本体を埋め、必要に応じて実装コメントを追加。この時に追加メソッドや変数が必要と気づいたらまた上記のステップを繰り返す。
また、コメントは設計ツールでもある。
If the interface comment for a method provides all the information needed to use the method and is also short and simple, that indicates that the method has a simple interface
逆に言えば、コメントが書きにくい=メソッドや変数への説明がやりにくい、と感じる場合、もしかすると設計上の問題が生じているかもしれない。
メンテナンスが大事
コメントを書かない理由の一つとして、時間の経つにつれてコメントがメンテされず精確でなくなることが挙げられている。
コードレビューは一つ確保する仕組みでありつつ、コメントを関連する箇所に近いところに書く(当たり前ではあるが)のも大事。
もう一つテクニックとして、繰り返しをしないことだ。データ構造のコメントによく発生しやすい問題だと感じている。例えばgraphQLでスキーマを定義するときに、同じフィールドを使うスキーマが複数存在する場合がしばしばある。全てのスキーマで同じコメントを書くと、仮に変えようとするときに、全部変えないといけない。一箇所だけにかき(上から1回目に現れたところとか)、他は参照先だけを書くようにするのが良いだろう。
コミットメッセージにコメントを書かない
コミットメッセージで詳しくコミットの内容を記述する開発者もいる。コミットメッセージは基本短い一行(英数字50文字程度)のほうが良い。長くしたり、改行したりすると、確認するには手間がかかるからだ。また、コミットの詳細内容は基本的にコード内のコメントとして書くべきものだ。
個人的な補足
自分のコメントを書く実践の中でよく、TODO, NOTE, WARN, FIXMEといったプリフィックスを使う。これらのプリフィックスを活用することで、
- コメントの意図が一発で伝わる→特にチーム内でガイドラインとして統一した方が効果が上がる
- 関連するプラグイン(vscode-todo-highlightとか)で素早く箇所を特定・フィルターすることができる
といったメリットがある。特に後者では、TODOだけを洗い出してタスク化したい時とか、FIXMEの内容を探して問題を修復したい時に負担を大きく軽減できる。
実装においての良い実践
主に14、17、18章の内容となる。
良い命名を探す
設計時に若干軽視されやすい部分ではあるが(と言いつつCleanCodeではかなり強調されている)、良い命名がドキュメンテーションのためにもなる。逆に、悪い命名は複雑度を上げることになる。
良い命名について、こちらでCleanCodeの内容に基づいてまとめているので、ここは割愛する。
もう少し考えよう、というレッドフラグの意味で、下記の場合は特に要注意:
- 名前が複数の意味を持つ
- どの名前に決めるかが難しい
一貫性を保つ
一貫性を持つことは複雑度を下げるために非常に大事なポイントとなる。どこで一貫性を保つか、具体的に言えば以下となるが、自分のコメントと実践法を追記している。
- 命名 → よく見られる例として、CRUD操作のそれぞれのメソッドの命名が言語やFWによって違うものの、同じコードベースの中で一致しなければならない。retrieveの代わりに別途getとか、fetchとかを定義してしまうと、読む側にとって、何が違うのかとの疑問が生じてしまい、認知的負荷がかかってしまう。
- コードスタイル → できる限り社内・チーム内共通のガイドラインとしてレポジトリーと一個おき、その中でコードスタイルのドキュメントやコンフィグを設定しておく。再利用とメンテコストの観点からでもおすすめな実践だと思う。
- インタフェース → オーバーロードして定義する時に、引数が変わっても、機能として一貫性を保つことが大事。ただ、引数はオーバーロード時に変えて良いとして、リターン値を変えるのがあまりおすすめではない(マッピングの認知的負荷がかかる)。引数とリターン値を同時に変えたい場合は、別のインターフェースを作った方が良い気もする。
- 設計パターン → 一般的にコミュニティ全体で蓄積されていた知見をそのまま適応すると、コンテキストの共有との意味で認知的負荷や学習のコストが下がる。よくReact <-> Vueのエンジニアに「互換性」があるとか、BE側のFWでLaravelができればDjangoもできるとか、共通する設計パターンがあるからだ
- 不変値(invariants)→ これは定数(constants)のことと少し違い、とある条件においてプログラムの行為が不変することをさす。という意味では、関数型プログラミングで提唱するピュア関数(副作用を生み出さない関数)がこの不変性を持っている。例えば、商品とのクラスを定義する時に、priceとの属性に、マイナス値がついてはいけない。
さらに、どのように一貫性を保つか、著者はいくつか方法を挙げている。
- ドキュメント -> 先ほども触れていたが、共通するガイドラインのドキュメントを用意した方が良い
- バリデーションで強制する -> 例えばCIやコミットフックの形で、リンターとかでタイプ、フォーマットなどについてチェックして、通らない場合はマージ・コミットできないようにする
- 郷に入っては郷に従え(when in Rome, do as the Romans do)-> 慣習に従うこと。例えばJSではキャメルケースが基本なので、あえてスネークケースにしないこと。
- 既存の慣習を変えない → もっと良いアイディアがある、というのは慣習を変えるには十分な理由ではない。一貫性の価値がより大きいからだ。
明白なコードを書く
これも冒頭あたりで触れたが、明白=他の人が読んでコードの意図が伝わりやすいを意味する。
では具体的にどう実践すべきかについては、著者は以下のように挙げている。
- ホワイトスペースを賢明(judicious)に使う -> これについてCleanCodeの中にも触れた覚えがある。スペースはただのスペースではなく、コードの意味ある集約の区切りのために目印として利用できる。スペースを利用してコードを区切りすることによって、読む側にとってより読みやすくなる。
- コメントを書く -> コメントの重要性について既に多くの章で述べているので、ここは割愛。
逆に何がコードを明白でなくするのか、以下のように挙げている。
- event-driven programming -> jsが分かりにくい一つの理由として、node.jsでもDOM APIでもこのパラダイムを採用しているからだ。人間の時系列による(procedure programming)認知パターンと合わないため、コードの実行流れを追うには苦労する。ただこのパラダイムは不可欠であり、ハンドラー関数がどういう時に呼び出されるかをコメントの形で丁寧に書くことが良いだろう。
- generic containers -> 例えばJAVAの
Pairとか。ただ、グループ化された要素は、より一般化な名前になってしまう(key & value)となり、本来の名前が伝わる意味がなくされるのだ。この問題も、ソフトウェアは書きやすいように設計するのではなく、読みやすいように設計すべきだと反映している。 - 宣言と割り当て(declaration and allocation)の型を一致 -> 例えばJAVAのLISTで宣言した変数に対して、初期化するときにサブクラスのArrayListでインスタンスを作ることがこれに反している。
- 読み側の期待に反するコードを書かない -> これは経験と関わりそうな問題だが、例えばindex.jsファイルがよくサーバー側の入り口ファイルとして使われている。ここでアプリの初期化なり、ミドルウェアの適応なり、といったコードをもちろん書かない。ある程度の共通認識として、どこで何を書くというのは書き側にも読み側にも持っているはずで、それを反することをしないこと。
終わりに
19章周りでソフトウェア設計のトレンドについて触れている。OOPの継承vs組み合わせとか、アジャイルとか、設計パターンとか、割と章の一節で尽きない内容が多いので、別途深掘りできるきっかけでまた書きたい。20章ではパフォーマンスのために設計する内容となっている。この辺りは実践で、メトリックスの監視や負荷テストなどが挙げられる。システムの複雑度を下げるとの趣旨から少し離れている気もして、今回は割愛している。
この記事を書くときに事実上2回目を読むことになった。振り替えてみると、複雑度の本質の分析、下げるためのマインドセット(strategic)、深いモジュールとコメントファーストの実践を中心に、複雑度を下げる施策とその理由について述べてきた。
さほど分厚い本ではないものの、非常に吟味すべきな内容が多い。ソフトウェア開発において他の理念と考え、SOLIDとか、契約式とか、非常に共通点が多く感じていた。ウェブアプリの開発を学んで既に3年を経つ今、多少自分の経験も含めて読み返すと、共鳴できる箇所も多々ある。
この本について自分が凝縮していくと、下記の3つのキーワードにつきることだろう。
- 認知的負荷
- 抽象化
- CDD
複雑度の本質をより本質的に言えば、読み側の認知的負荷が高いからだ。その対処法として抽象化とコメントが相互補うの立場にあり、認知的負荷を下げるために存在する。この認識が今後の開発ライフに役立つように思いたい。
だらだらとここまで書いたが、今日は一旦これまで。
ではでは。
Discussion