この記事はOptimind Advent Calendar 2023の1日目の記事となります。
経緯
最近のプロジェクトでは、GCPのCloudRun Serviceを使っていて、バックエンドのメインサービスが走っています。多くの場合は問題ないものの、多少時間のかかる操作が存在します。しかし、min-instancesの設定では、インスタンスの再起動がいつでも起こりうるので、たまたまこの時間のかかる処理が当たってしまうと、処理が予想外の中断となってしまいます。
すると、これらの時間のかかる処理を、メインサービスから分離するために、色々と調査と実験を行いました。
CloudRun Jobsについて
なぜCloudRun Jobsにするか
基本GCPのサービスを使う前提ですが、時間のかかる操作を非同期で処理するために、タスクキューとか(CloudTasks)、メッセージサービス(PubSub)とかが候補として上がってくるかもしれません。また、CloudRun Serviceと並行に、CloudRun Jobs, Batchとのサービスも存在し、それも非同期処理に適しているといえます。
なぜ最終的にJobsに決めたかというと、主な理由が2点あります
- Jobsでは最大24時間の実行時間が可能
- CloudTasksは30min(HTTPの場合、AppEngineを使うと長くできますが使っていないので)、Pub/Subは10min
- Jobsを使うことで、Serviceと同じイメージや同じ設定のインスタンスないし同じコードを利用することが可能=メンテナンスのオーバーヘッドが少ない
- CloudTasksにしても,Pub/Subにしても、仲介役しかないので、別途CloudFunctionsとかのコンシューマ・ワーカーを管理する必要がある
- CloudFunctionsのために別途ソースを管理するためのバケットとか、現存のコードの分離とか、色々と面倒なことになる
それで、最終的に、CloudRun Service から CloudRun Jobs を起動させる構築になりました。
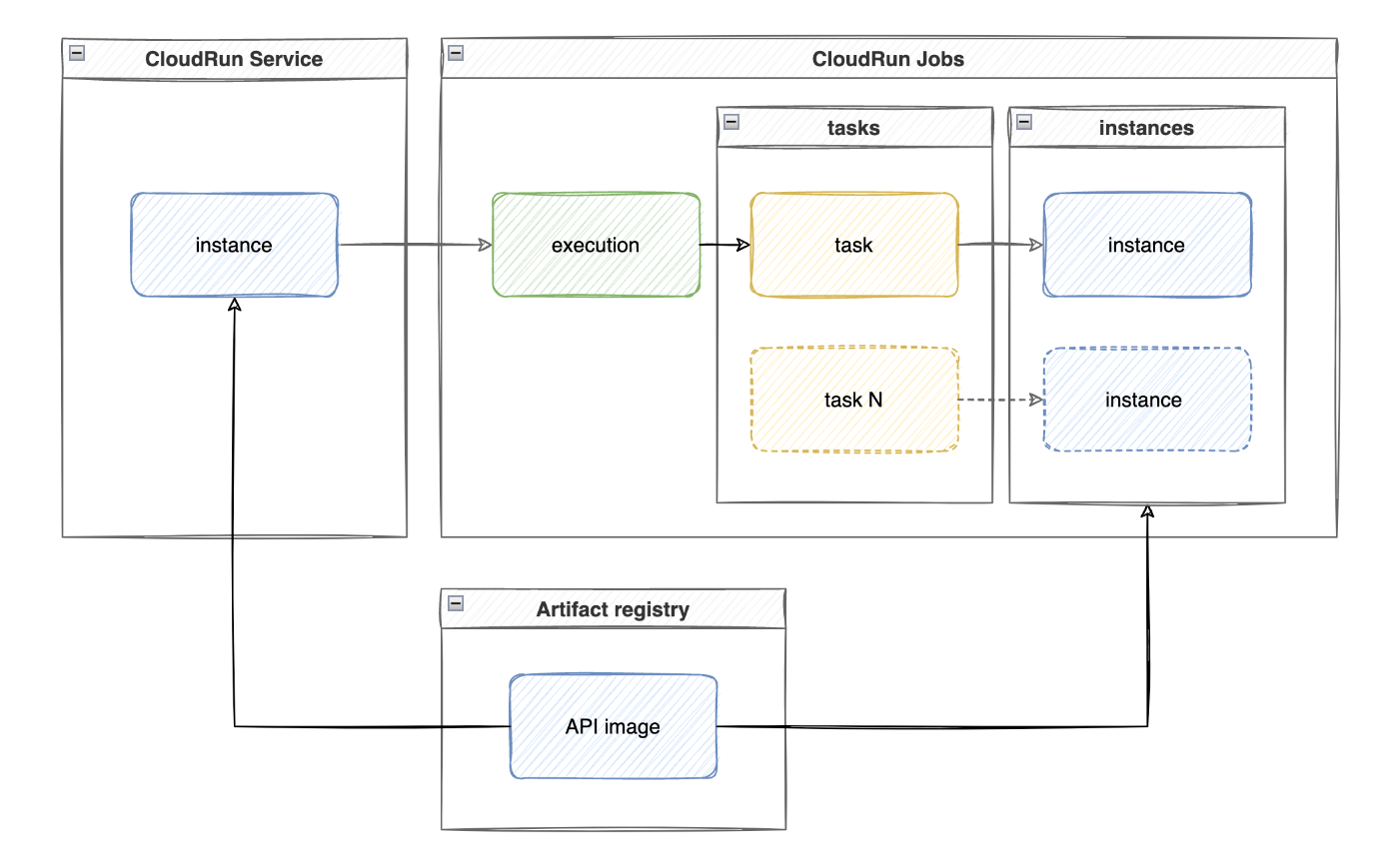
概要
Jobsを使うには2つのステップが必要です。
- ジョブをビルド・作成する
- ジョブを実行する
作成のプロセスは、基本CloudRun Serviceと同じく、イメージを指定してビルドすればOKです。
実行する際に、作成されたジョブのイメージでコンテナーを立ち上げるだけです。ただ、立ち上げる際に、コンテナーの各種パラメーターを上書きすることが可能ですdoc 。
これは先ほど触れた、同じイメージと同じコードを利用できることです。プロジェクトの規模によるものの、現存のコードのままで、実行場所をCloudRun ServiceからCloudRun Jobsへ移動するだけならこのパラメーターの上書き機能が最高です。
例えば、下記のアプリ用のイメージがあるとします。
FROM node:18.16.0-bookworm
RUN mkdir -p /app
COPY . /app
WORKDIR /app
# ...install deps
ENTRYPOINT ["npm", "start", "api"]
これで最後のENTRYPOINTで、サーバーを起動する形になるのですが、Jobsを実行する際に、このENTRYPOINTを上書きすることで、サーバーを起動する代わりに別の操作をすることが可能です。
つまり、各種時間のかかる操作を一つの関数にまとめ、CLIを通してその関数を実行させればよいのです。
使い方
ここでは、公式のcode labの例を利用します。jobs関連のドキュメントはこちらに参照。
始める前にまずいつくか概念や用語について簡単に説明します。この辺りドキュメントではあまり明白になっていない、わかるまで時間がかかるものもあるので、一度確認した方が良いでしょう。
- executionは、ジョブを一回実行させる単位となります。jobs.runを呼び出す際に、task毎に一個新しいコンテナーを立ち上げ、処理が終わったらコンテナーがなくなります。この1サイクルの単位は実行となります。
- operationは、CloudRun Jobsを含めて、APIコールによる戻り値となる一般的なlong-running operationを指しています。これはジョブと違いますが、どちらかというと、ジョブもlong-running operationの一種となり、ジョブ実行後の情報はoperation.metadataに含まれる形になります。
- taskCountは一回の実行(execution)で処理を行うタスク数のことを指します。つまり、1Job = N tasksとなります。なお、一個のタスクで一つのコンテナーが立ち上げられます。何番目のタスクについて、実行時はコンテナーから
CLOUD_RUN_TASK_INDEXとの環境変数で0スタートでアクセスできます。 - parallelismは、同時に実行させるタスクの数です。これは上記のtaskCountに制約され、仮にtaskCountが1であればparallelismを100にしても意味がありません。デフォルトの設定では、可能な限り同期実行を行います。この設定値は実行時に上書きできず、ジョブのリソースを作成する際に決められます。
- maxRetriesはタスク失敗時にリトライする回数を決めます。ただこちらも実行時に上書きできません。デフォルトは3回、実行時に
CLOUD_RUN_TASK_ATTEMPTとの環境変数からアクセスできます。 - timeoutは実行のタイムアウトではなく、各自タスクのタイムアウトとなります。これはデフォルトで1時間ですが、最大24時間まで可能です。
- containerOverridesには、コンテナーを立ち上げる際に上書きする各種パラメーターを含めています
- argsというのは、上記のENTRYPOINTへの上書きです。例えば、
npm start apiを、npm run lintに変える場合は、args: ["npm", "run", "lint"]にすれば良いのです。また、コマンドへのパラメーターも同じ感じで、["npx", "command", "--param1", "value1", ...]とかはできます。 - envは環境変数のkey:valueペアとなります。環境変数で何か制御する場合はこれを使えます。
- clearArgsは現存のENTRYPOINTにあるargsをなしにするものです。
- argsというのは、上記のENTRYPOINTへの上書きです。例えば、
次はいくつかの実行のやり方を紹介します。
HTTP request
HTTP リクエストのやり方では、普通にポストリクエストで送れば良いのですが、認証のアクセストークンが必要となります。エンドポイントはv1も使えるのですが、公式では 、GKEとかを使う場面でv1への互換性が必要以外に全部v2を勧められています。
curl -X POST \
'https://asia-northeast1-run.googleapis.com/v2/projects/<project-name>/locations/asia-northeast1/jobs/screenshot:run' \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H 'Content-Type: application/json' \
-d '{"overrides": { "containerOverrides" : [ {"name": "screenshot", "args": ["https://www.pinterest.com", "https://www.apartmenttherapy.com"] } ], "taskCount": 2, "timeout": "300s"}}'
そのレスポンス例は以下となります。
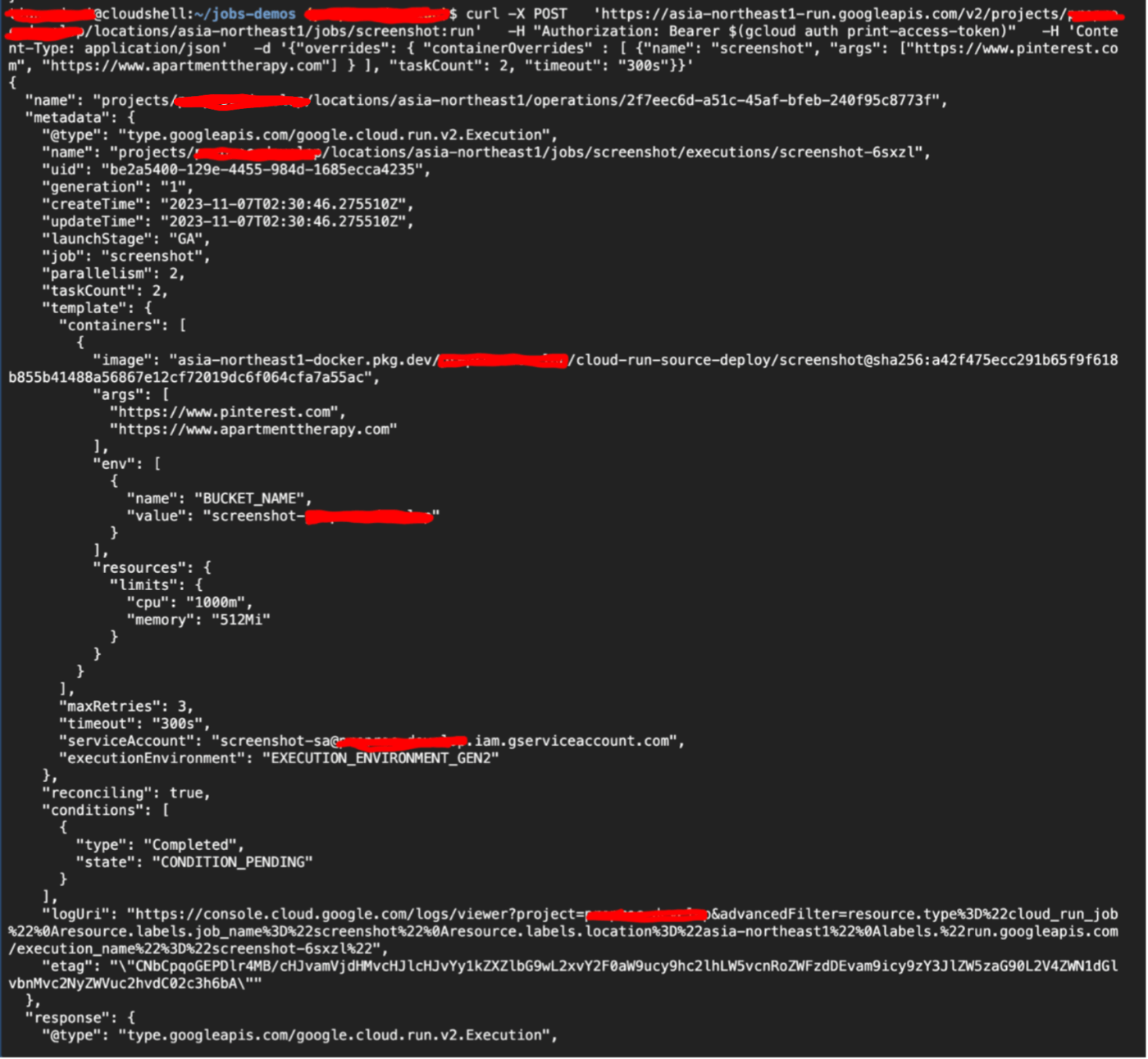
ここでわかるかもしれませんが、レスポンスのnameを見ると、.../operations/...が入っています。先ほど紹介したlong-running operationのことで、実際にジョブの情報を取ろうとするとmetadataを見ると良いでしょう。
CloudRun SDK
次に 公式のSDK を見てみます。
const client = new JobsClient({ projectId: googleProjectId });
const args = [...];
const [jobOperation] = await client.runJob({
name: 'projects/<project-name>/locations/asia-northeast1/jobs/screenshot',
overrides: {
containerOverrides: [{ args }],
},
});
// ここでジョブが終わるまでまつ
const job = await jobOperation.promise();
console.log(jobOperation);
ここで要注意したいのは、runJobのリターン値はジョブの実行(execution)ではなく、long-running operationとなります。実行をそのまま待ちたい場合は、await jobOperation.promise()で可能ですが、 これを入れると、ジョブが終わるまでブロックになってしまいます。
つまり、非同期処理を行う意味で、ジョブの開始だけを待ち、実行は別途ステータスを確認する方針が良いので、今回のようにproducer(メインサービス)とconsumer(ジョブのコンテナー)を分離させるために、producer側ではawait jobOperation.promise()は不要となります。公式の例にはこの行がついているのですが、若干ミスリーディングになりかねないので、本当にやりたいこととあっているか、実装時に注意が必要です。
gcloud cli
最後に、gcloudのcliからも実行可能。ただ、執筆時点(2023/11/30)でbeta版を使う必要があり、でなければ上書きしたいargsとかのパラメーターが存在しません。
gcloud beta run jobs execute screenshot \
--args=https://www.pinterest.com,https://www.apartmenttherapy.com,https://www.google.com \
--region=asia-northeast1 \
--tasks=3
実際の業務でcliを使ってジョブを実行させる場面というとCI/CDのワークフローになるかなと。
問題
起動時間
ジョブを起動させるために、CloudRun ServiceからAPIコールを投げて、CloudRun Jobsの方でイメージからコンテナーを立ち上げて、タスクの実行が開始するまでは、やく30-35秒くらいかかりました。
ただ、この時間はプロジェクトスケールや他の要因によって影響されるかは不明です。理論的に、ENTRYPOINTのレイヤーを書き換えだけで、イメージビルドの所要時間は一定のはずです。
なので、実際の処理は仮に数秒か10秒台で終わるなら、CloudRun Jobsに切り替えるかどうか、少し微妙かもしれません。必要なものだけジョブ化すれば良いでしょう。
リトライ時の冪等性
タスク中にエラーが出てプロセスが終了となった場合、自動でリトライできるようになります。
ここで注意したいのは、何回リトライしても、処理の結果・行為は一致するかどうか(冪等)のところです。
実際に今回このような問題とあいました。ジョブを開始する前に、処理の履歴をDBに保存し、stateだけをpendingにしています。ジョブの中身では、try/catch/finallyに囲まれて、何かエラーが出たら、pendingの状態をfailedに変えます。
しかし、tryのはじめに、渡された履歴IDといったパラメーターを持って、現在pending中との状態をチェックしています。すると、2回目以降の実行では、1回目の失敗ですでにfailedになったため、該当履歴のIDでpending中のものが見つからず、別のエラーとなるのです。
なので、Jobsのリトライ機能を利用するためには、処理自体は冪等かどうか、一度確認した方が良いかと思います。
冪等でない場合は悪いというわけでもなく、それをコード上でどう対処するか、CloudRun Jobsのリトライをやめて、コード内でリトライロジックを実装するか、その辺りの意思決定も必要になってくると。自分の場合は、CloudRun Jobsを利用しない環境も存在するため、maxRetriesを1にし、リトライ機能をコード内実装という方針にしています。
ヒープメモリー不足
この問題は、nodejs独自かもしれませんが、今回出会ったのでメモとして残します。
最初にjobsに使うインスタンスのスペックを、vCPU 1 x Memory 2GiBとしました。実験するためにさほどいらないかなと。すると、いざコードを実行するようになると、heap execeeded the maximu memoryといったエラーが出て、実行が中断となりました。
2GiBのインスタンスだと、 公式 で1.5GiBに明示的に設定するように勧められています。デフォルトでNodejsではヒープ用のメモリ上限を設定していますが(こちらに参照 )、物理的にインスタンスのスペックが足りない場合もあります。仮に4GiBのインスタンスにデフォルトで4Gのheapメモリを与えたとすると、スワップやパフォーマンス問題が出る可能性があります。OSには他のプロセスもメモリ必要なので、公式の例で考えると、4GiBのインスタンスに3、6GiBのインスタンスに4とかくらいの比例で良いでしょう。
ヒープメモリはなぜold-spaceと呼ばれているか、そもそもどういう意味かはこちらに詳しく書いています。
金額
そんなにやすいものではありません。例えば、下記の条件で計算すると
$0.00002160 / vCPU-second beyond free tier
$0.00000240 / GiB-second beyond free tier
- region: asia-northeast1(Tier1 pricing)
- vCPU: 2
- memory: 4GiB
- req per user per day: 50
- process time per req: 60s
vCPU price = $0.00002160 * 50 req/day * 30 day * 2 vCPU * 60s = $3.888
vCPU price = $0.00000240 * 50 req/day * 30 day * 4 GiB * 60s = $0.864
つまり、ユーザー一人だけで月4.5ドル近い費用が発生され、これを人数分で考えるととんでもない費用になります。
下記の画像は、上記の条件*100名ユーザーの場合の月額料金の公式試算額となります。実際には利用割引が着くので単価x人数よりは安いですね。
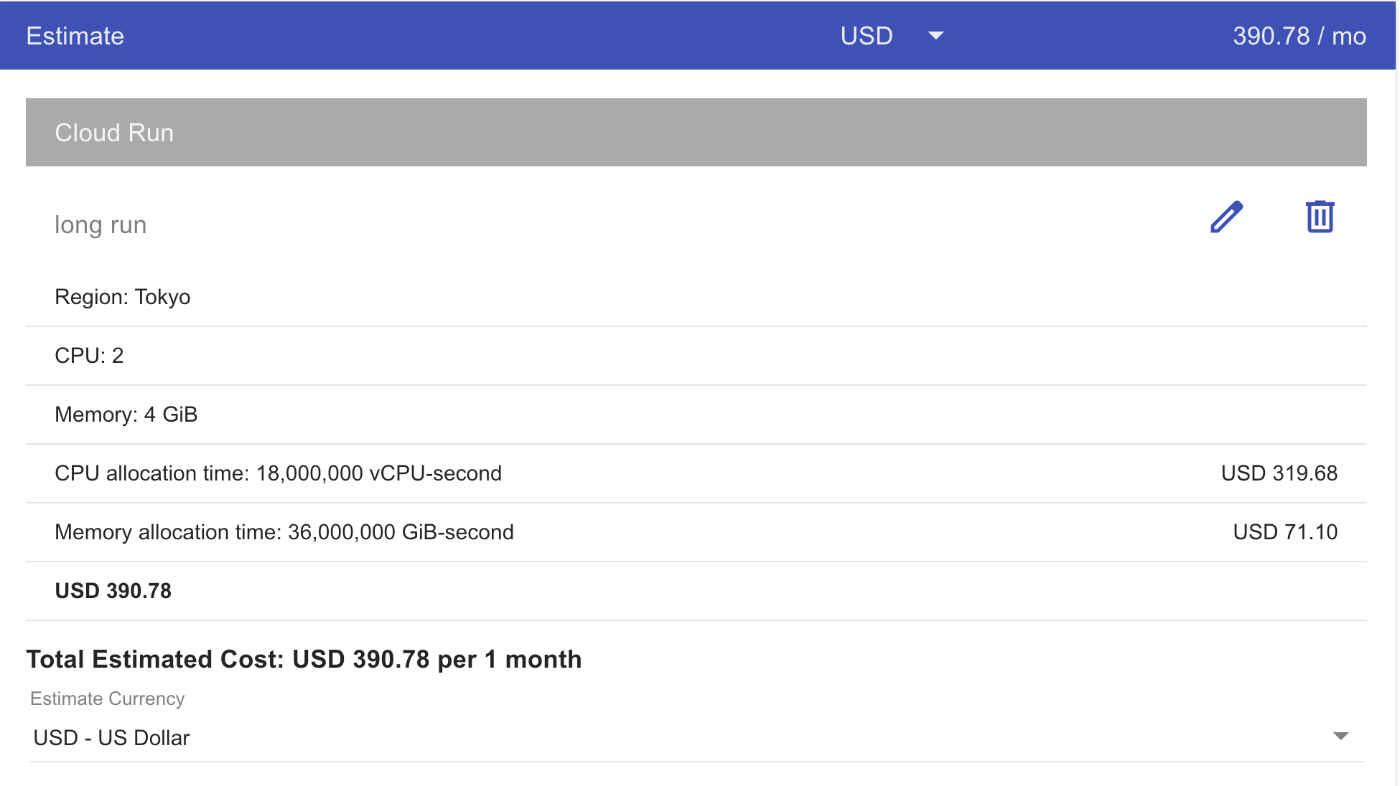
公式の計算ツールはこちら。CloudRun Jobsを採用する前に他の案との料金比較もしておくと良いでしょう。ちなみに同じ条件でCloudRun Functionsで計算したらJobsのほうが安かったんです。
終わりに
今回は業務で使われているインフラ構築の一部を紹介しました。
CloudRun Jobsの面白いところは、やはりDockerイメージのENTRYPOINTやENVを上書きできるところだと思います。おかげで今回のService -> Jobsへの移行は割とスムーズにできました。これもどちらかというと、今回Jobsにする1番の理由だったかもしれません。このやり方自体いろんな可能性を秘めているので、また何か面白い使い方があったらシェアしようと思います。
残念なところというと、今回の実装はJobsの並行処理をうまく利用できず、基本一回の実行で1つのタスクしかありません。元々そういう設計となっていて(順次実行する必要がある)仕方がないかと思います。一回で複数のタスクが投入されるバッチ操作のケース、例えば公式例の複数のウェブサイトのスクショを取るジョブとかだと、ぜひJobsで並行処理してみたいと思います。
また、CloudRun Jobsと結構近いサービスとして、Batchというものがあります。両者の比較についてこちらに詳しく紹介されています。
CloudRun Jobsについて知りたい方、使うかどうか検討されている方に役立つと嬉しく思います。
ではでは。

世界のラストワンマイルを最適化する、OPTIMINDのテックブログです。「どの車両が、どの訪問先を、どの順に、どういうルートで回ると最適か」というラストワンマイルの配車最適化サービス、Loogiaを展開しています。recruit.optimind.tech/
Discussion