Apollo Lake(SkyLake)のGPUについてのメモ1 - キャッシュとメモリの構成
Apollo LakeのGPUは第9世代intel HD Graphicsで、デスクトップ向けではSkyLakeに乗ってるやつと同じです。型番だと、HD Graphics 500シリーズです。
この記事の内容はドキュメント等の資料から読み取ったことをまとめただけで、実験などによって裏打されたものではありません。そのため、実際のHWやその仕様とは異なる部分がある(間違いがある)可能性があります。
GPU外観

(Intel Apollo Lake GT1.5 - TechPowerUpより引用)
これは第9世代intel HD GraphicsのGT1.5と呼ばれるもののブロック図で、まさにApollo Lakeのものです。
1つのGPUには3つのサブスライス(subslice)があり、1つのサブスライスには6つのEU(Execution Unit)が乗っています。L1キャッシュは各サブスライスで共通、L3キャッシュはGPU全体で共通であることがわかります。
EUとはインテルのGPUにおける実行ユニットの最小単位であり、CPUだとコアと呼ばれる単位です。CUDAと対応させてみると、サブスライスがSMに、EUがCUDAコアに対応しそうです(厳密には異なりますが)。
このブロック図(Apollo Lake)では6 [EU/subslice]に見えますが、本来(SkyLakeのもの)は8 [EU/subslice]であり、Apollo Lakeではサブスライスあたり2つのEUが無効化されています。なお、Apollo Lakeには8 [EU/subslice]となるモデルはありません。

(Intel Skylake GT2 - TechPowerUpより引用)
こちらはSkyLakeに乗ってるGT2と呼ばれるもののブロック図で、EUやサブスライスを少し詳しく描いたものです。
1スライス(Slice)は3サブスライスからなり、SkyLakeの上位モデルではこのスライスを増やすことで性能をスケールアップします。GT1/1.5(Apollo Lake)やGT2(SkyLake)は1スライス+非スライス部分=1GPUです。
サンプラー(Sampler)は、テクスチャマッピングなどで使用されるテクスチャや表面画像を読み込むためのユニットで、内部にL1とL2の2階層のキャッシュを持ちます。サンプラー全体は読み込みしかしないため、このユニットにデータを書き込み(出力)することはできません。必然的に、サンプラーの持つL1L2キャッシュもリードオンリーです。
サンプラーのL1とL2キャッシュの間には各種圧縮テクスチャフォーマットを展開する機能があるようです。このような性質から、サンプラーの持つL1/L2キャッシュは非グラフィックス用途では使用できなさそうです。
各EUはサブスライスに一つあるデータポート(Data Port)と呼ばれるロード/ストアユニットを介してメインメモリを読み書きし、そこにL3キャッシュが介在します。サブスライスから見たメモリ帯域は、読み書きともに64 [Byte/Cycle]で、L3キャッシュにヒットするとメモリアクセスのレイテンシが削減できます(帯域は変わりません)。
データポートは共有メモリ(Shared Local Memory)へのアクセスやSIMD演算におけるスキャッタ/ギャザー(散らばった読み書き)操作などもサポートしています。それらメモリ領域への効率的なアクセス(メモリ帯域の最大化)のために、データポートは分散したメモリアクセスを重複しない64バイトのキャッシュラインリクエストに対するより少ない操作となるように統合してくれます。
例えば、16個の32bit浮動小数点数値を使用するSIMD16演算において、16個の異なる領域に対すギャザー操作(バラバラのアドレスからの読み込み)は、全てのアドレスが1つのキャッシュライン内に含まれていれば1回の64バイトリード操作にまとめられます。
CPUとの接続
Apollo LakeのGPUはCPUと同じダイにあり、物理的に1つのチップ上にあります。CPUコアなどの他の部分とはリングバスによって接続されており、リングバスのへの接続点はGPU全体で一つです。メモリコントローラやディスプレイインターフェースともリングバスを介して接続しています(Apollo Lakeにはないですが、eDRAMを持つモデルもGPU/CPUとeDRAMはリングバスを介して接続します)。また、GPUはリングバスによってLLC(Last Level Cache、CPUのL3キャッシュ)とも接続しており、LLCはCPUとGPUで共有されています。

(The Compute Architecture of Intel® Processor Graphics Gen9 - intelより引用)
メモリとキャッシュの構造
キャッシュ階層
EUから見たキャッシュ階層は
- L1(命令)、テクスチャキャッシュ
- L3
- LLC(GPU外部、CPUと共有)
となっています。テクスチャキャッシュはおそらく非グラフィックス用途に使用可能ではありません。
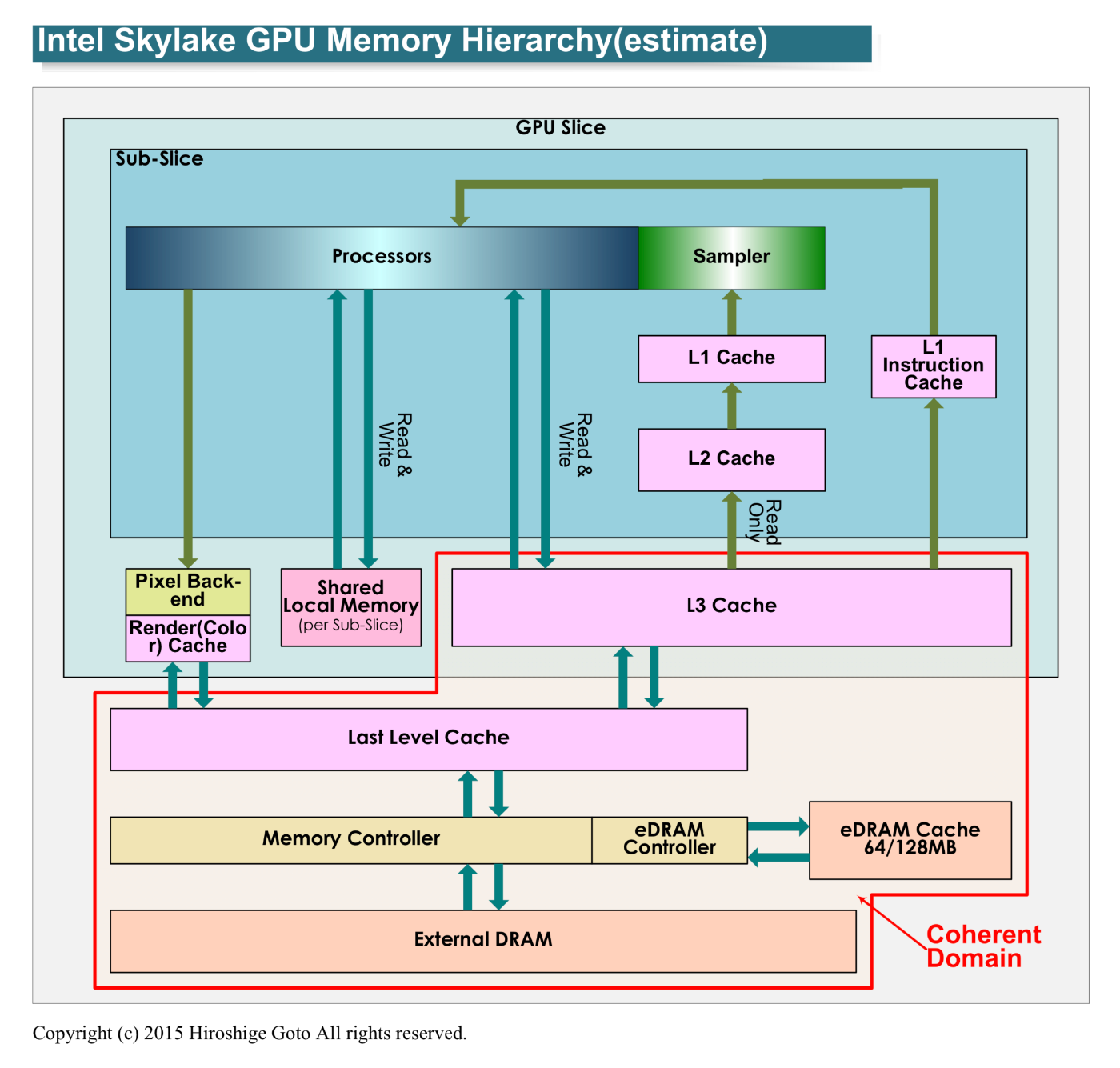
(GPUコンピューティング機能を強化したSkylakeのGPU - PC Watchより引用)
GPGPUに関わってくるのは、L3キャッシュとLLCキャッシュだけです。
L3
L3(not キャッシュ)の容量は1スライス(not サブスライス)あたり768 [KB]で、アプリケーション(使用法)によって次の3パターンの利用法があります。
- GPU処理におけるL3キャッシュとして
- 固定機能パイプライン(Fixed fucntion unit)のシステムバッファとして
- このバッファのことをURB(Unified Buffer?)と呼ぶ
- 共有メモリ(Shared Local Memory)として
例えば、グラフィックス用途(3Dレンダリング)には、固定機能パイプラインのためにシステムバッファ(非キャッシュ)としてより多くの容量を割り当てることがよく行われ、コンピュート用途(GPGPU)には512 [KB/slice]の領域がL3キャッシュとして利用され、残りの領域は共有メモリ(64 [KB/subslice])として利用可能となります。
すなわち、L3の領域(768 [KB])はL3キャッシュとSLM・URBによって分割して利用されます。
L3キャッシュは厳密にはサブスライス毎に分割されたL3キャッシュパーティションの集合体ですが、これらのパーティションはL3ファブリックによって集約され、単一の大容量L3キャッシュとして機能します(あるいはそう見えます)。このL3ファブリックはスライスを跨いでも拡張可能であり、複数のスライスを有するモデルにおいてはL3キャッシュはGPU全体で共有されるより大きなキャッシュとして見えるようになります。
L3キャッシュのキャッシュラインサイズは64バイトで、L3領域は2倍のクロック(おそらくGPUのベースクロックに対してという事だと思われ、GPUのコアクロックに対して倍という事?)で動作しているようです。
SLM
SLMは共有メモリ(Shared Local Memory)の略で、1サブスライスあたり64KB利用可能です。これはコンピューティング用途のために用意されているもので、ハード的にはL3キャッシュと同じもので同じところにあるため、帯域幅はL3と同じ64 [byte/cycle]でありレイテンシも近い値になります。
ただし、SLMはL3よりもさらに細かくバンク分割されており、64バイトにアラインしていないアクセスや隣接しない領域へのアクセスを並列化することでメモリアクセスの帯域幅を最大化します。1つのSLM領域内の異なる位置への16個の32bit値アクセス(全てリード or 全てライト)を同時に行う事ができます。
SLMはアプリケーションによって使用しないように設定する事ができますが、その場合その領域はURBに充てられるため、使用しないからといってL3が増えるわけではありません。L3の最大容量は512 [KB/slice]です(グラフィックス用途ではURBにより多く割り当てる事ができます)。
当然ですが、SLMはL3キャッシュなどとコヒーレントではありません。SLMはキャッシュではなくプログラマブルなメモリ領域です。
SLMはソフトウェアレイヤでOpenCLのローカルメモリ(work-group local memory)やDirectX Computeの共有メモリ(thread-group shared memory)に対応し、GPUのドライバランタイムはOpenCLワークグループやDirectX Computeスレッドグループを1つのサブスライスにマップするため、それらのワークグループ内のカーネルは同じSLM(64 [KB])を共有することになります。
L3とSLM(とURB)のバンク分割
L3キャッシュとURB、SLMは同じL3の領域を互いに分け合う事で実装されています。ただし、そのバンク分割は異なっており、L3キャッシュの部分は16 [KB]毎にバンク分割されるのに対し、SLMの部分は4 [KB]毎にバンク分割されます。
L3はまず192 [KB]のバンクに分割されています。このバンク単位は並列でアクセスする事ができ、1サブスライスに1バンクが当てられています。L3は1スライスで768 [KB]=192 [KB]*4なので、1バンクが全スライスで共通となっています。おそらく、各サブスライスに当てられた192 [KB]のバンクのうち64 [KB]分はSLM(URB)で使用される領域で、L3キャッシュとして使用可能な領域は128 [KB]になります。L3キャッシュはスライス全体で512 [KB]あるので、残り128 [KB]はスライス共通の4つ目のバンクから当てられるものと思われます。
したがってL3の1バンク192 [KB]は、128 [KB]分がL3キャッシュとして利用され、それ以外の部分がSLM(URB)として使用されることになります。
192 [KB]に分割されたL3の各バンクは、用途毎に領域が分けられた後でさらにバンク分割されます。次の図はL3の1バンク(192 [KB])分の領域をSLMとL3キャッシュに分割する様子を図示したものです。
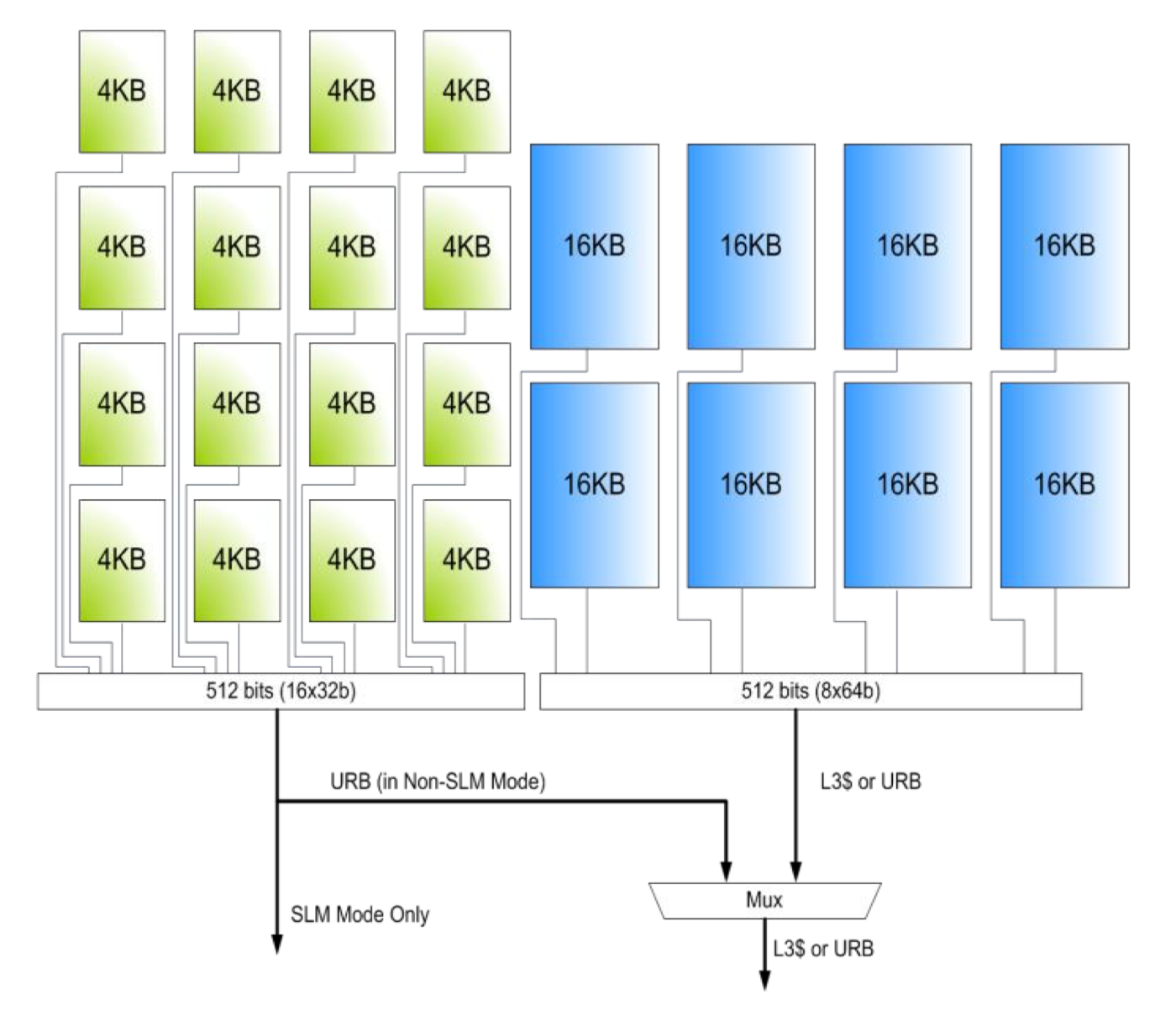
(Intel® Open Source HD Graphics Programmer's Reference Manual Volume 6: 3D-Media-GPGPUより引用)
SLMを有効にした場合左側の緑色のブロックがSLMとして使用されます。この緑の部分はL3バンク(192 [KB])の一部を取ってきて16*4 [KB]にバンク分割する事で確保されます。SLMが無効であるとき、この領域はURBが使用します。
SLMの各バンクへは同じクロックサイクル内で独立してアクセスする事ができ、その粒度は32 [bit/bank]になります。すなわち、異なるバンクへのアクセスとなるリード/ライト(全て同じであること)を16個分同時に行えます。
L3キャッシュへのアクセスも帯域幅は同じですがバンク分割とアクセスの粒度が異なり、8*16 [KB]にバンク分割され、64 [bit/bank]のアクセスを8バンク同時に行えます。SLMの方が細かい粒度でアクセスができる事で、帯域幅の最適化が促進されます。
バリアとアトミックアクセス
第6世代以降のintel GPUはスレッド(グループ)間でのアトミックアクセスやバリアをハードウェアサポートしています。それらの機能はブロックとしては1スライスに1つあります(第9世代の場合)。
バリア機能は、サブスライスあたり最大16のアクティブスレッドグループで同時に使用可能です。
アトミックアクセス機能はL3キャッシュを介したメインメモリアクセスとSLMのアクセス時に使用可能で、第9世代では32bitのアトミック操作をデータ型によらずハードウェアサポートしています(前世代は浮動小数点数が未サポート)。
レジスタ
EUから使用可能なメモリ領域は、EUから近い順に
- GRF ARF(EU内部)
- SLM(スライス内部)
- メインメモリ
となります。
このうち、1のGRF/ARFはプログラマブルな領域ではなく、EU内部に閉じているレジスタです。
GRF
GRF(General purpose Register File)は汎用レジスタの集まりです。
GRFは1スレッド毎に128本あり1本あたり32 [byte]で、1スレッドあたり4 [KB]利用できます。1EUあたり7HWスレッドなのでトータルで28 [KB/EU]となります。
GRF1つは32 [byte]で次のようにデータを格納でき、SIMD命令で直接利用する事ができます。
- 32bit×8個
- 32bit浮動小数点数
- 32bit整数
- 16bit×16個
- 16bit浮動小数点数
- 16bit整数
GRFはバイトアドレッシングで、複数のレジスタをまとめて幅の広い1つのレジスタとして扱ったり、矩形ブロックとして扱ったりと柔軟なアドレッシングが可能です。
その他特性
- 領域は未初期化
- 28 [KB]の領域は4つに論理的に分割されている
- 各バンクは3ポートメモリ(2リード1ライト)
- 1ポートあたり128 [bit]幅の帯域
- 32本ごとにバンドルされており、異なるバンドルへのアクセスは衝突しない
- 共同発行されたスレッドによるアクセスは衝突しない
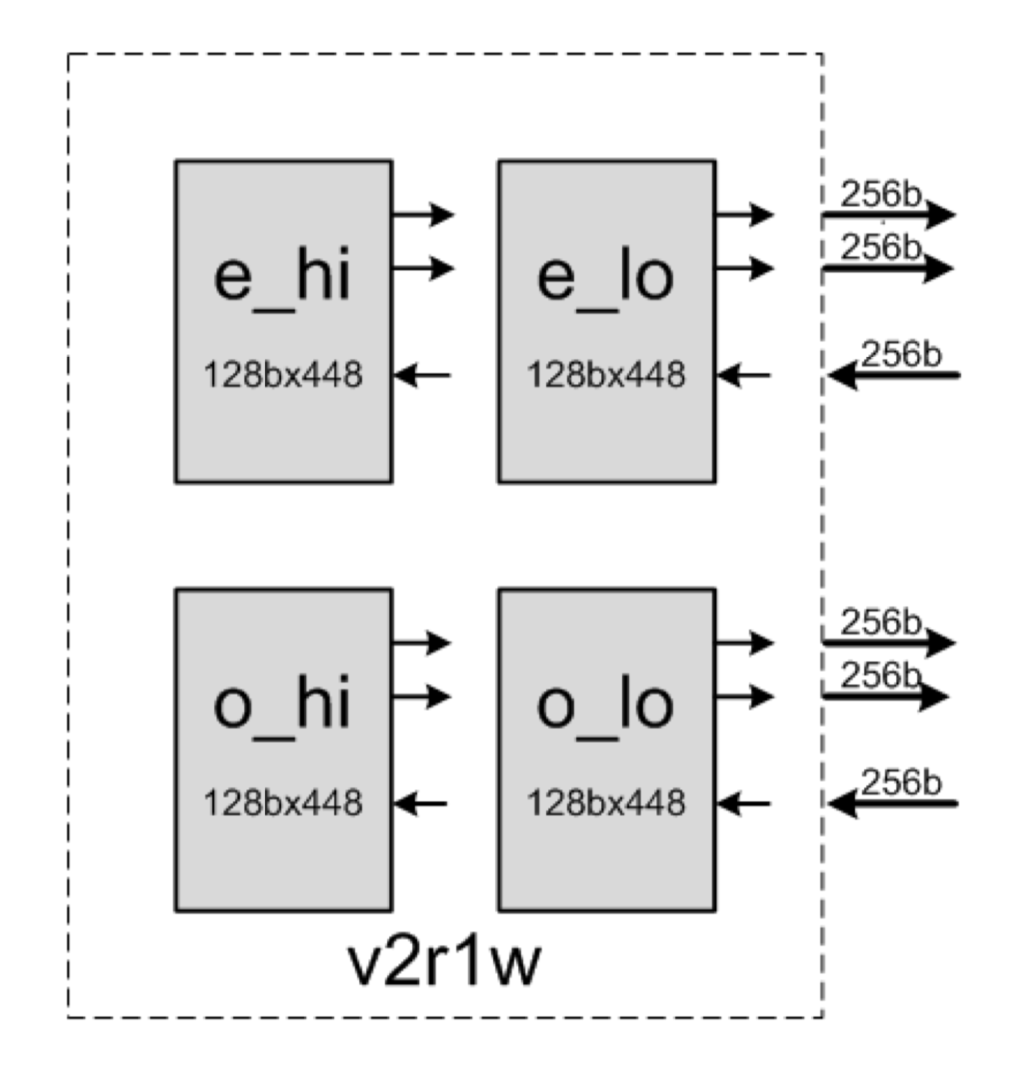
(GRFの分割とアクセスポートの様子 (Intel® Processor Graphics: Architecture & Programmingより引用))
GRFはプログラマから見るとスタック領域として利用可能な領域となります。
ARF
ARF(Architecture Register File)は各スレッドの状態を保持しておくためのレジスタで、各種命令実行のための専用のレジスタ(Architecture Aegister)の集まりです。以下のレジスタがあるようです。
- Null register
- Address (index) register
- Accumulator register
- Flag register
- Stack Pointer
- Status register
- Control register
- Notification register
- Instruction Pointer register
- Thread dependency register
- Time stamp register
- Debug register
これらのレジスタはスレッド毎に用意され、独立しています。
なお、GRFとARFの分類は論理的なもので、物理的には1つのSRAM領域に配置されているようです。
Accumulator
Accumulator registerは2本用意されており、連続した積和算を高精度かつ低遅延に実行できます。
| データ型 | チャネル数(並列数) | チャネル辺りbit幅 | 数値の扱い(形式) |
|---|---|---|---|
| 16/32/64bit浮動小数点数型 | 16/8/4 | 16/32/64 | 浮動小数点数型に対して使用される時は、GRFと同じ幅(精度)となる |
| 32bit(符号付/無)整数型 | 8 | 64 | 符号有無に関わらず64bitの2の補数形式 |
| 16bit(符号付/無)整数型 | 16 | 33 | 33bitの2の補数形式で、16bit符号付(無)整数型2つをソースとする単一命令による乗算をサポート |
| 8/64bit整数型 | サポートされない |
積算処理を書くときに64bit整数や8bit整数を使うと遅くなる、みたいな事が起こるかもしれません・・・
各種メモリとキャッシュの関係性
第9世代intel HD Graphicsの各種キャッシュとメモリ領域やEUなどは以下のように接続されています。
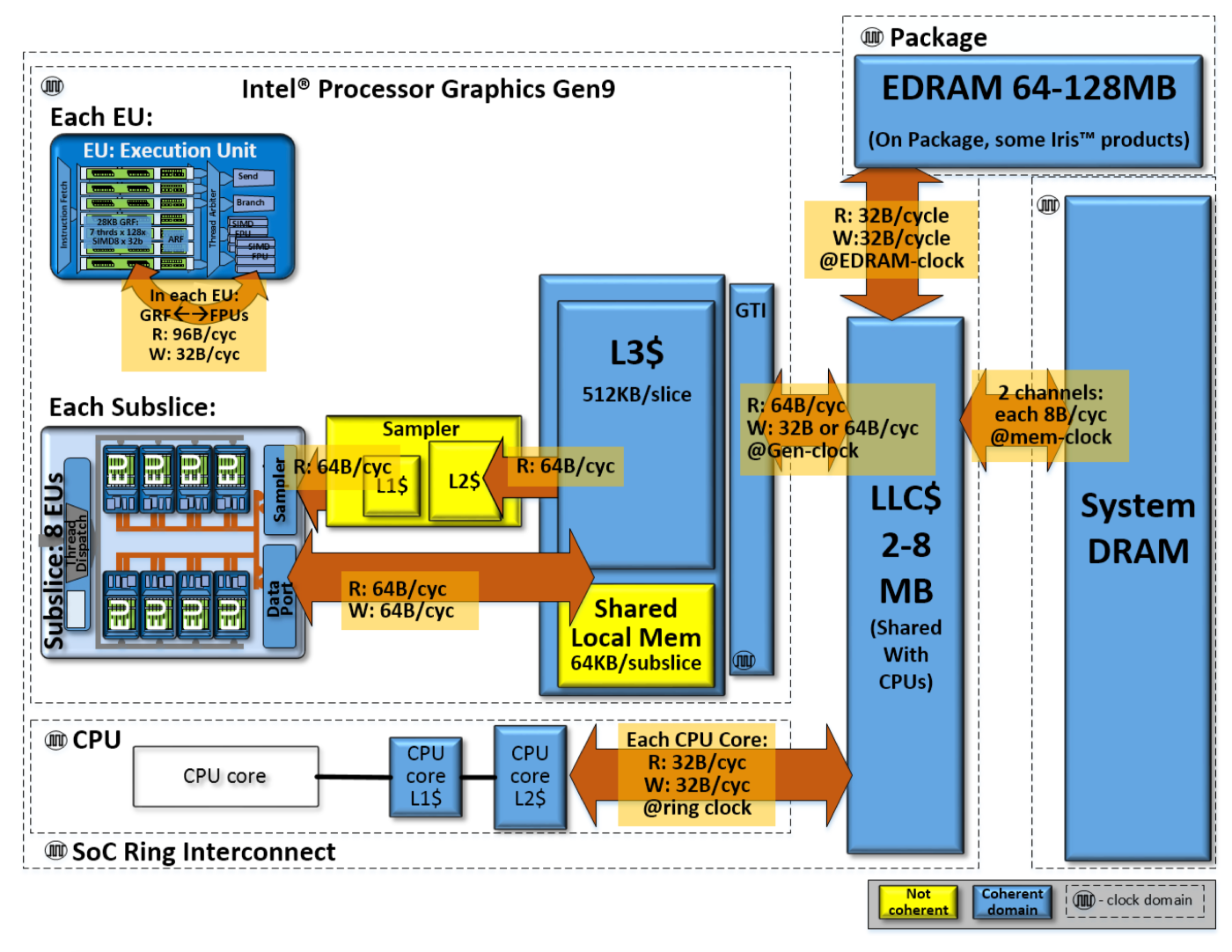
(The Compute Architecture of Intel® Processor Graphics Gen9 - intelより引用)
サブスライスは個別にデータポートを持っているため、1スライス内のサブスライス-L3間の帯域幅は64*3 [byte/cycle]となります(サンプラーも同様)。
GTIとはGraphics Technology Interfaceの略で、GPUのゲートウェイとなる部分で、リングバスへ接続している部分です。
これらの図で、EUとSLM、テクスチャキャッシュ(Sampler内L1L2)を除いた部分のキャッシュとメモリ領域は全て一貫性が保たれます(グローバルにコヒーレント)。
図中の各ブロックのクロックは同じではない可能性があります。図示されているように、各ユニットは独自のクロックジェネレータを持っており、それぞれ別のクロックで動作しています。したがって、N [byte/cycle]の示す帯域幅はNが同じでも秒間では同じ幅にならない可能性があります。
EU
参考文献
- The Compute Architecture of Intel® Processor Graphics Gen9 - intel
- Intel® Processor Graphics: Architecture & Programming
- Intel® Open Source HD Graphics Programmer's Reference Manual Volume 6: 3D-Media-GPGPU
- INTEL® OPEN SOURCE HD GRAPHICS PROGRAMMER'S REFERENCE MANUAL (PRM) FOR THE 2016 INTEL ATOM™ PROCESSORS, CELERON™ PROCESSORS, AND PENTIUM™ PROCESSORS BASED ON THE APOLLO LAKE PLATFORM (BROXTON GRAPHICS)
- List of Intel graphics processing units - Wikipedia(en)
- Intel Apollo Lake GT1.5 - TechPowerUp
- GPUコンピューティング機能を強化したSkylakeのGPU - PC Watch
- 実行モデルを変更したSkylakeのGPUコア - PC Watch
- Skylake’s graphics architecture: Intel is still gunning for dedicated GPUs - Ars Technica
Discussion