Apollo Lake(SkyLake)のGPUについてのメモ2 - EU
メモリとキャッシュ周り
Execution Unit
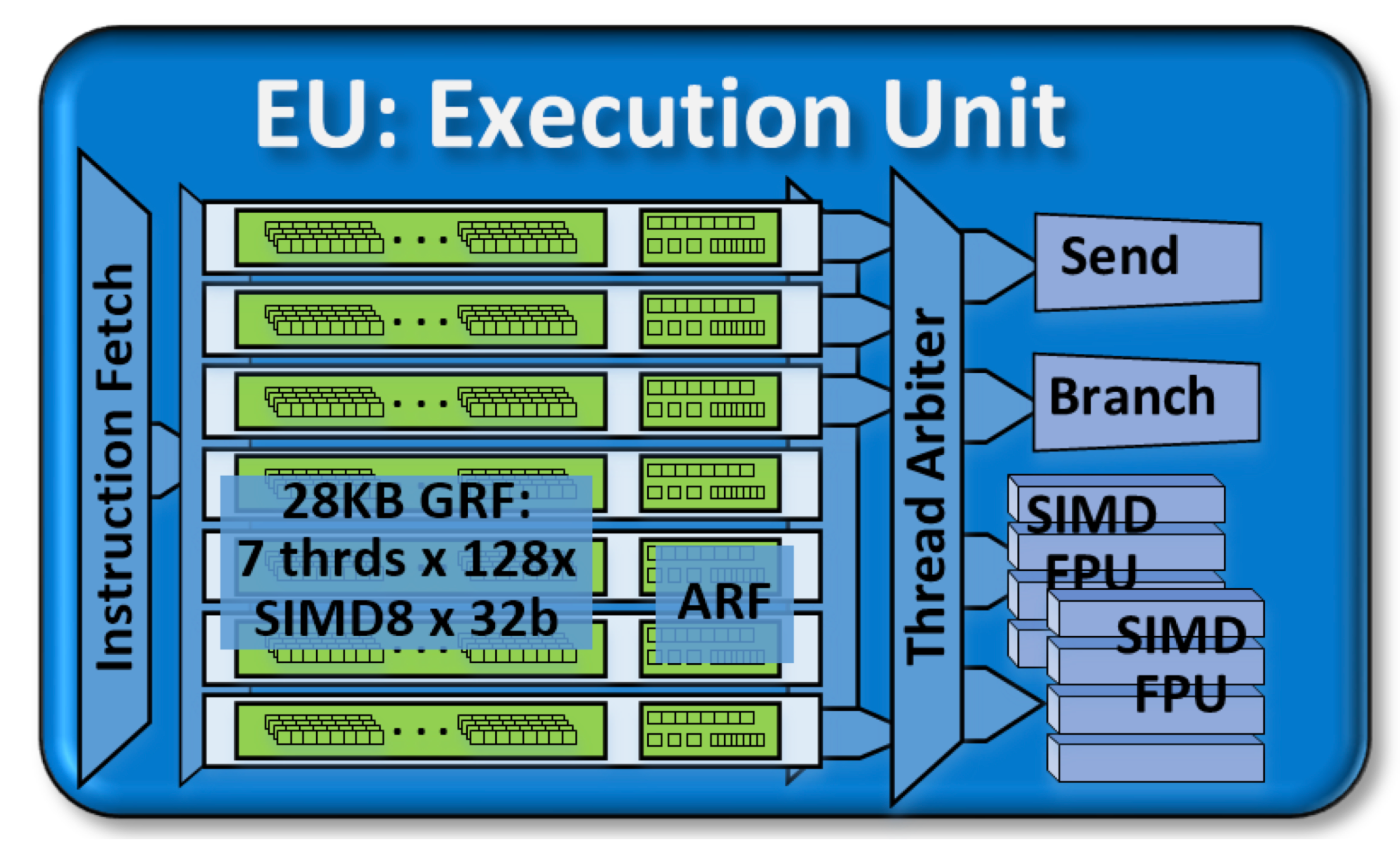
(The Compute Architecture of Intel® Processor Graphics Gen9 - intelより引用)
1つのスライスには3つのサブスライスがあり、1つのサブスライスには6個(SkyLakeは8個)のEU(Execution Unit)があります。
EU1つはSMTによって7ハードウェアスレッドを持ち、GRF(4 [KB])とARFがそれぞれのスレッドに固有で割り当てられています。
1EUはSendユニットとBranchユニットを1つづつ、32bit幅×4レーンのSIMD FPUを2つ持っています。
SendユニットはEUのI/Oポートに当たります。メモリアクセス系命令の実行を担っており、サンプラーからの読み込みやスレッド間同期、メモリ(L3キャッシュ)へのアトミックアクセスを行います。
Branchユニットは条件分岐命令の実行を担う部分です。SIMT方式におけうPredicate機構相当のことを行えます。
SMT+IMT
1EUは7スレッドを持ちますが、これはCPUにおけるHT(ハイパースレッディング)とは少し異なります。7スレッドが同時に実行されているわけではなく、あるタイミングでは2スレッドが2つのFPU(SIMD演算器)を占有する形で実行されます。同じタイミングで、残り5スレッドはEU内部のパイプラインの各段を埋めています。
7つのスレッドは、同じ命令を実行することもあれば、全く別の命令を実行することもできます。パイプラインによってFPUに投入されるため、あるスレッドがFPUを使用して演算を行なっている間に、別のスレッドはメモリアクセスをしたり、固定機能ユニットによる実行を行なったりする事ができます。
この戦略は、SMT(Simultaneous Multi-Threading)によるEUのリソース使用率の向上と、IMT(Interleaved Multi-Threading)によるメモリアクセス時間の隠蔽を組み合わせたものです。
NVIDIAのGPUのやっているSIMTでも、32スレッドをまとめたワープの単位でIMTすることによってメモリアクセス時間の隠蔽を行なっています。一方、ワープ内各スレッドはCUDAコアと呼ばれる実行単位(演算器)を占有して実行されています。しかし、CUDAコアはSIMD演算器ではなくパイプラインやSMTのような複雑な機能を持たない単純なものなので、命令実行時に遊んでいる部分がそれほど多くはなさそうです。
対してintelのGPUは、7つのスレッドが1つの実行単位(EU)でパイプラインによって実行されており、命令の実行はSIMDによって並列化されます。intelのGPUはあくまでSIMD演算による並列化を志向しているため(あるいはCPU的であるため)、このような実行形態の差が生まれているのだと思われます。
カーネルとスレッド、SIMD
SIMTモデルでは、プログラミングレイヤでのカーネル1つは1スレッドに対応していました。intelのGPUはSIMTではなく、1カーネル=1スレッドではありません。
intelのGPUにおける並列化は突き詰めるとSIMDによるものであり、1カーネルはSIMDの1レーンに対応しており、1スレッドはSIMD演算によって複数のカーネルをまとめて同時実行します。各カーネルインスタンスはSIMDの各レーンで独立してシリアルに実行されているように見えます。
OpenCLやDirectCompute、OpenGLなどGPUコードを生成するコンパイラが複数のカーネルインスタンスを束ねてSIMD実行するコードを生成します。EUの1スレッドはそのように束ねられた複数カーネルを同時実行することになります。その際、1スレッドが何カーネル担当するかはコンパイラが選択し、そのように選択された1スレッド当たりのカーネルの数をSIMD幅と呼びます。OpenCLやDirectComputeでは、SIMD8/16/32が一般的に利用されるようです。
各スレッドはSIMD幅の数のカーネルを同時(FPUのレーンの制約を受けるため必ずしも同時ではないかも)に実行するため、EU1つはそれに7(スレッド数)をかけた数のカーネルを同時に実行します。例えば、SIMD16の場合は16×7=112カーネル、SIMD32の場合は32×7=224カーネルが単一のEUで同時実行されます。これは最大数であり他の処理との兼ね合いもあるのでいつもそうなるわけではないですが、サブスライスではこれに6(8)をかけた数のカーネルが、GT1.5/2の1GPU(1スライス)ではそれに3をかけた数のカーネルが同時実行されることになります。
SIMDのダイバージェンス
あるSIMD幅に対して、スレッド内のすべてのカーネルが同じ命令を実行している間はFPUを最大活用できますが、条件分岐によってカーネルが分岐した場合にその前提は崩れます。
条件分岐命令が実行された場合、スレッドは分岐の2つのパスをそれぞれ順番に実行します。その後、分岐結果を表すフラグレジスタの内容に基づいて実際に分岐した方の結果だけを残し(メモリへ出力し)ます。
これはSIMTモデルで行われるPredicate機構と同じことをSIMDの各レーンについて行なっています。分岐命令はBranchユニットにて実行され、Branchユニットは分岐のネストを追跡し、実行マスク(Execution Mask、live-ness mask)によってどのレーン(カーネル)だけを実行すべきかを記録しておくことで分岐を効率化するなどの役割を担っています。
FPU
FPU(Floating-Point Unit)は1EUに2つありどちらも32bit幅×4レーンのSIMD演算器です。FPUと言っていますが、整数演算や論理演算にも対応しています。1つのFPUは4つの32bit浮動小数点数(or 整数)のSIMD演算、もしくは8つの16bit浮動小数点数(or 整数)のSIMD演算を実行できます。また、積和算(FMA, MAC, MAD)を1サイクルで行うことができるたため、積和算ではスループットは倍になり、32bit数値で16 [operation/cycle](=(add+mul)×2FPU×SIMD4)となります。
FPUは2つありますが2つとも同じものではなく微妙に違いがあり、それぞれALU0、ALU1と呼び分けられています。どちらもレーン数(幅)は同じですがALU1は数学特殊関数と64bit浮動小数点数をサポートする拡張数学ユニット(Extended Math Unit)を備えています。
SIMD幅とFPU
EUのISAとGRFはいくつかのSIMD幅をサポートできるように柔軟に設計されています。32bitデータの場合1つのFPUは物理的には4並列ですが、論理的には1,2,4,8,16,32の幅のSIMD命令やレジスタを対象とする事ができます。
例えばSIMD16命令の場合、そのオペランドは2つの隣接する2本のGRFレジスタをまとめて連続した16要素幅の1つのレジスタとして扱い、そのような論理的なSIMD16命令は物理的なSIMD4 FPU演算に透過的に分解されて繰り返し実行されます。
そのため、幅の広いSIMD命令はそれだけ実行サイクルがかかることになりますが、EU内部はパイプライン化されているため、その実行の間にも他のスレッドの処理を進めておく事ができ、スループットを最大化します。
AOS -> SOA
GPUにおける実行形態がSIMDからSIMTへと移行したのは、可変個のデータがあるときや、ある1単位のデータの要素それぞれで別のことをしなければならない場合に演算器の利用効率が低下するため、特にGPGPUにおいて非効率となるためでした。しかし、intelのGPUはSIMTではなくどちらかというとSIMDによる並列化を志向しています。
SIMT以前のSIMDで効率が低下しうる問題はSIMDのせいというよりも、データをどう処理するか?という実行モデルの問題でした。従来のGPUはAOS(Array of Structure)という実行モデルで処理をしており、例えばあるピクセルの色情報RGBAの4要素データに対して同じ処理を適用する場合、4レーンのSIMD演算器で1つの色情報を処理する事で1ピクセルに対する処理を1サイクルで行います。ただグラフィックス用途でも要素の一部(例えばアルファチャンネルA)だけに別の処理を行いたい事があり、するとSIMD演算器の利用率が低下します。GPGPUでは1つのデータは必ずしも4要素(あるいはその倍数)ではないため、さらに問題は深刻になります。
これに対してSOA(Structure of Array)という実行モデルでは、各データの1要素だけを取ってきてそれを並列処理し、残りの要素に対しても同様にします。例えば先ほどの色情報の例では、まずRに対する処理を行い次にG次にBというように処理していきます。1データ(1ピクセル)を処理するのに時間がかかるようになりますが、全データを処理するにかかる時間は変わりません。これによって、1つのデータの各要素に対する処理が異なっていても演算器が空いてしまう事がなくなり、1データの要素数によって効率が低下することもなくなります。このSOAによる実行の実装の1つがSIMTです。

(The Compute Architecture of Intel® Processor Graphics Gen9 - intelより引用)
intelのGPUにおいてもSOAによりデータを処理しますが、その実装はSIMTではなくSIMDによるものです。どういうことかというと、SIMTでは1スレッドに1データの1要素をそれぞれ担当させるのに対して、intelのGPUはSIMDの1レーンに1データの1要素を担当させます。これまでRGBAの4要素に対する処理を一括実行していたSIMD演算器は、あるサイクルではRだけ次のサイクルではGだけ...というように処理するようにすることで、SIMDによるSOA実行を実装しています(こうして見ると、実際のところNVIDIAのCUDAコアとSMも似たようなものなのかもしれません)。
特にこの第9世代のGPUからは実行モデルが変更され、従来AOSとSOAの両方をサポートしていたのがSOAのみに一本化されています。1つのFPU(SIMD演算器)のレーン数が4レーンなのはAOSサポートの名残であると思われ(グラフィックス用途では、色情報や3次元同次座標、クオータニオンのように1データ=4要素を仮定してよかった)、将来はより大きな幅になっていく可能性があります。
パイプライン
次の図は、EU内パイプラインの様子を図示したものです。

(The Compute Architecture of Intel® Processor Graphics Gen9 - intelより引用)
おおよそ、図の左から右へ処理が流れていき、大まかに次のようなフローになっています。
TCunit
TCはThread Controlの略のようです。これは上図の左端から2列のブロックが該当します(Thread Nまで)。
EU内で命令は命令キューに格納されており、命令はプリフェッチされています。また、命令はLUTベースの方法によって128bit -> 64bitに圧縮されており、命令キューから各スレッドロードされた時に元に戻されます。
命令キューは1スレッドあたり2キャッシュライン(8×128 [bit] = 2×64 [byte])分あります。キューには圧縮された命令がキャッシュライン単位で読まれているため、2キャッシュラインには最大16命令が格納されます。
キューからの読み出し時には、異なるスレッドが同じキャッシュラインを読まないようにフィルタされているようです。
各スレッドは命令キューから命令を読み出し、命令間(スレッド間)の依存関係をマークしチェックする事で、ハザード(データハザード、制御ハザード)を防止します。そのようにマークされた実行順序に従って各スレッドは実行されます。
各スレッドの状態はARFに各スレッド固有に保持されています。
GAunit
GAはGRF Arbiterの略のようです。このユニットはおそらく、CPUでは命令発行ポートとか呼ばれている部分にあたります。
GAunitは上記図中では2つに分かれて描かれており、GRF Operand FetchというブロックとWB Arbiterというブロックが該当します。どちらも、GRFへのアクセスを担っており、異なるのはアクセス方向(読みor書き)です。
GRF Operand FetchはGRFからデータを読み込むユニットです。MEUnit > ALU0 > ALU1の優先度によって読み込み要求を処理します。SIMD命令のオペランドは1〜3オペランドであり、src0から順に読み込んでいきます。ここでのMEUnitの処理は、GRFからメインメモリ(L3キャッシュ/SLM)への出力です。
WB ArbiterはALU等の処理結果をGRFへ書き込む(出力する)ユニットです。ここでは逆にMEUnitの優先度が最も低くなっています。ここでのMEUnitの処理はメインメモリ(L3キャッシュ/SLM)からGRFへデータを読みだしてくる事とGPU内の固定機能ユニットの結果をGRFへ出力する事です。
アキュムレータ(Accumulator register)はここにあります。
ALU0(FPU Unit)
ALU0は1つ目のFPUで、32bit数値に対して4レーンの物理幅を持つSIMDユニットです。DirectX11準拠、IEE754に準拠したFP16/32/64が利用可能です。また、FP32のみAltMode(丸めなどを簡略化するモード)が利用可能です。
ALU0内部では、データ型や演算によってパイプラインが分割されており、実行レイテンシ(パイプラインに投入されてから出てくるまでの時間)が異なります。
- 32bit整数 : 3 [clock]
- 32bit浮動小数点数 : 3 [clock]
- 積, 内積 : 7 [clock]
- 64bit浮動小数点数 : 7 [clock]
これらのパイプラインは7スレッド間で共有されており、例えばあるスレッドが32bit整数パイプで処理をしている時、別のスレッドは32bit浮動小数点数パイプで処理をすることができます。ただし、SIMD演算器そのものは32bit4レーンのものが1つだけなので、最終的なSIMD演算器は同時に1スレッドしか使用できません。
また、データ型と処理によって一回の演算で実行可能な(論理SIMD幅から分解された)SIMD命令の幅が異なります
- 16bit浮動小数点数/整数 : SIMD8
- 32bit浮動小数点数/整数 : SIMD4
- 16/32bit数値に対する積 : SIMD2
- 64bit浮動小数点数/整数、内積 : SIMD1
そして、FPUによるSIMD命令の実行レイテンシは最小2 [clock]であり、論理SIMD幅によって異なります
- SIMD1/2/4/8 : 2 [clock]
- SIMD16 : 4 [clock]
- SIMD32 : 8 [clock]
これは32bit浮動小数点数におけるレイテンシの値です。
ALU1(EM Unit)
ALU1は1つ目のFPUで、ALU0の機能に加えて数学特殊関数と64bit浮動小数点数をサポートする拡張数学ユニット(Extended Math Unit)を備えています。正確にはALU1 = ALU0 + EM + INTDIVとなり(INTDIVは整数型の割り算です)、内部のパイプラインもそのように分割されています。
- 32bit整数 : 3 [clock]
- 32bit浮動小数点数 : 3 [clock]
- 積, 内積 : 7 [clock]
- 64bit浮動小数点数 : 7 [clock]
- EM : 7 [clock]
- INTDIV : 7 [clock]
EMでは以下の命令(数学特殊関数)がサポートされています。
- 1引数
- INV : 逆数(1/x)
- LOG
- EXP
- SQRT
- RSQ : 逆平方根(1/√x)
- SIN
- COS
- 2引数
- POW
- FDIV : 浮動小数点数の除算
- 2引数2出力
- INTDIV : 整数の除算
FDIVとSQRTではIEEE754に準拠した結果を生成することができ、その場合は中間値として拡張精度の浮動小数点数(FP32/64に対して34/64bit)を使用します。
EMとINTDIVのレイテンシは全て7 [clock]で、数値の幅によって1度に実行可能なSIMD幅が異なります。
- 32bit数値 : SIMD2
- 64bit数値 : SIMD1
JEUnit
JEUnitは分岐命令の実行とフローコントロールを担うユニットです。この記事冒頭のEU概略図においてBranchユニットとされていたものです。
無制限の分岐ネストと最大31チャネルのダイバージェンスをサポートしています。また、非構造化フローコントロール(Unstructured flow control、gotoみたいなの)もサポートしているようです。
JEUnitの分岐結果はフラグレジスタや実行マスクの形でTCUnitに戻り、TCUnitではそれに合わせて命令の再ロードなどが行われます。
MEUnit
MEUnitはメモリアクセス関連の命令(L3キャッシュ/SLMへのアクセス、アトミックアクセス)およびスレッド間同期の実行を担うユニットです。この記事冒頭のEU概略図においてSendユニットとされていたものです。
MEUnitのメモリアクセスには読み込みと書き込みの2つの方向があります。
各種スペックの数字
| GT1.5 | GT2 | 備考 | |
|---|---|---|---|
| EU数 | 18 | 24 | 6(8)EU×3サブスライス×1スライス |
| HWスレッド数 | 126 | 168 | 7スレッド×EU数 |
| 同時実行されるカーネルインスタンスの最大数 | 4032 | 5376 | SIMD32幅×HWスレッド数 |
| L3キャッシュ | 512 [KB] | 512 [KB] | 512 [KB/スライス]×1スライス |
| SLM | 192 [KB] | 192 [KB] | 64 [KB/サブスライス]×3サブスライス×1スライス |
| FLOPS(FP32) | 288 [FLOP/cycle] | 384 [FLOP/cycle] | EU数×SIMD4幅×2FPU×(MUL+ADD) |
| FLOPS(FP64) | 72 [FLOP/cycle] | 96 [FLOP/cycle] | EU数×SIMD4幅×(MUL+ADD)/2 |
| IOPS(32bit整数) | 144 [IOP/cycle] | 192 [IOP/cycle] | EU数×SIMD4幅×2FPU |
他の世代のGPUとの差異
このSkyLake世代からしばらく、intelの10nmプロセス開発の遅延によってCPUマイクロアーキテクチャの抜本的な改善が行われておらず、GPUも同様なはずです。10nmのCPUはモバイル向けIceLakeがGPU付きで発売されていましたが、このGPUはこの世代のGPUからあまり変更はなさそうです(性能はトランジスタの増加によって上昇しているでしょうが、設計そのものに大きな変更はなさそうです、調べてないですが・・・)。
次にintelのGPUが抜本的に変化するのはXeと呼ばれるGPUの世代からです。XeはGPGPUでの利用をより意識して設計されており、よりコンピューティングのためのGPUとなっています。Xeを搭載しているCPUはデスクトップではRocket Lake(14nm)、モバイルではTiger Lake(10nm)があり、その他単体のGPUの販売が予定されている他、HPC向けのアクセラレータにも展開される予定です。
そのため、Xe以前(第11世代)まではここで見た設計・構造と大きく変わらないはずです。逆に、8世代以前とはそこそこ違いがあり、5世代より前は完全にグラフィック向けのGPUとなっています。
- 6世代(Sandy Bridge)から11世代(Ice Lake)までは基本的構造は同じ
- FP64対応が7世代(Ivy Bridge/Bay Trail)以降
- 8世代(Broadwell/Silvermont)まではFP16非対応
- 8世代まではスレッドプールの対応が各サブスライス毎
- SLM対応は7世代以降
Xeで大幅に変化したといってもEUの基本構造や設計方針などはHD Graphicsとよく似ており、SMT+IMTとSIMDによる実行形態も引き継いでいるようで、全く別物になってはいなさそうです。
参考文献
- The Compute Architecture of Intel® Processor Graphics Gen9 - intel
- Intel® Open Source HD Graphics Programmer's Reference Manual For the 2016 Intel AtomTM Processors, CeleronTM Processors, and PentiumTM Processors based on the "Apollo Lake" Platform (Broxton Graphics) Volume 6: 3D-Media-GPGPU
- Intel® Open Source HD Graphics, Intel IrisTM Graphics, and Intel IrisTM Pro Graphics Programmer's Reference Manual For the 2015 - 2016 Intel CoreTM Processors, CeleronTM Processors, and PentiumTM Processors based on the "Skylake" Platform Volume 7: 3D-Media-GPGPU
- Intel® Processor Graphics: Architecture & Programming
- List of Intel graphics processing units - Wikipedia(en)
- Intel Apollo Lake GT1.5 - TechPowerUp
- GPUコンピューティング機能を強化したSkylakeのGPU - PC Watch
- 実行モデルを変更したSkylakeのGPUコア - PC Watch
- Skylake’s graphics architecture: Intel is still gunning for dedicated GPUs - Ars Technica
- 何故GPUでSIMTが流行ったか (仮) - Qita
Discussion