C++ #includeはどこに書くと必要最小限になる?
きっかけ
遊びで書いたコードのリファクタリングをchatGPTにお願いしたところ、using namespace stdはusing namespace std::coutのように限定的に使うほうがよくなるとアドバイスを頂いた。
確かにコードは必要最小限で書く方が良いことはわかっているけど、なぜそこまで大事なのか肌感覚で理解できていないことに気が付いた。
そこで、コードを必要最小限で書くとは何なのか学びなおしを行った。
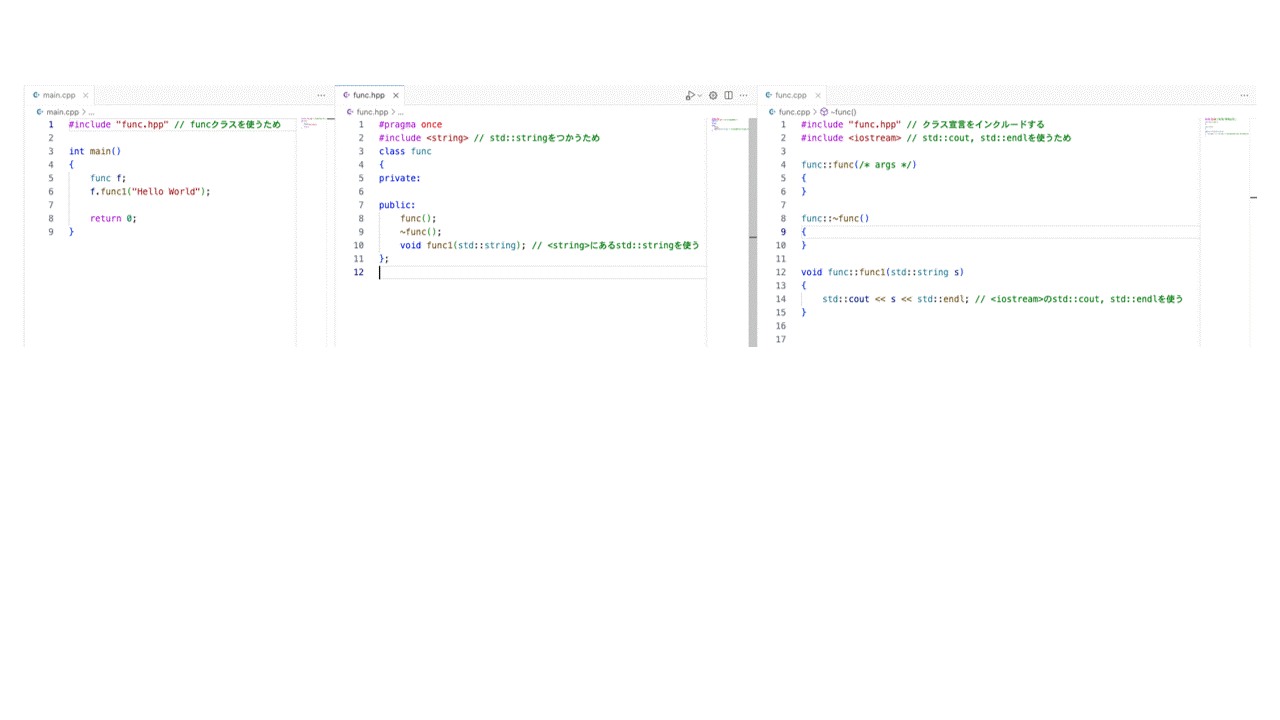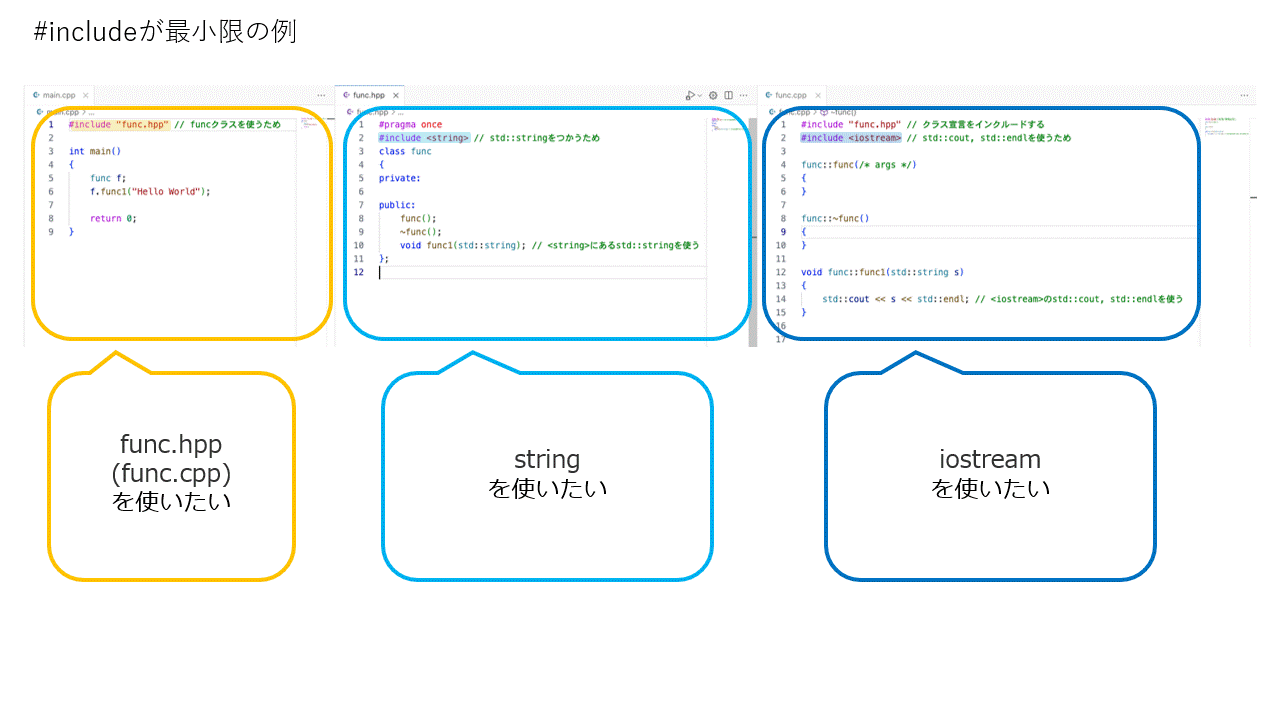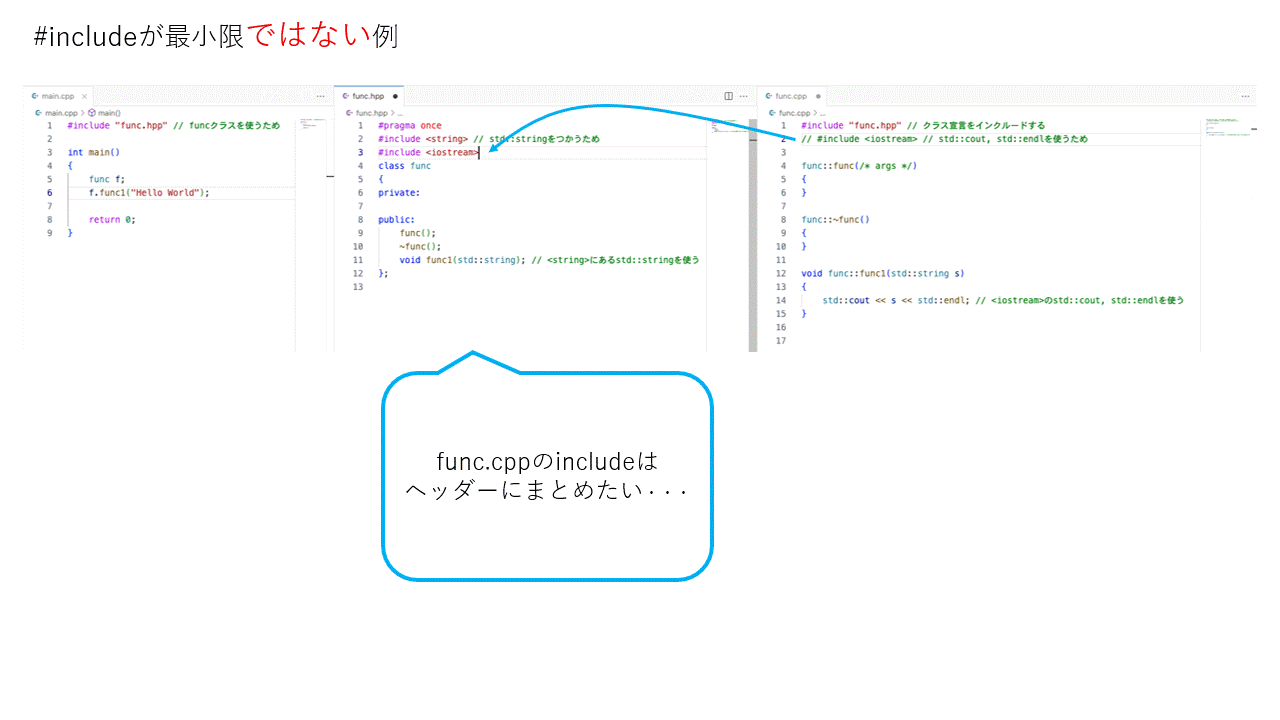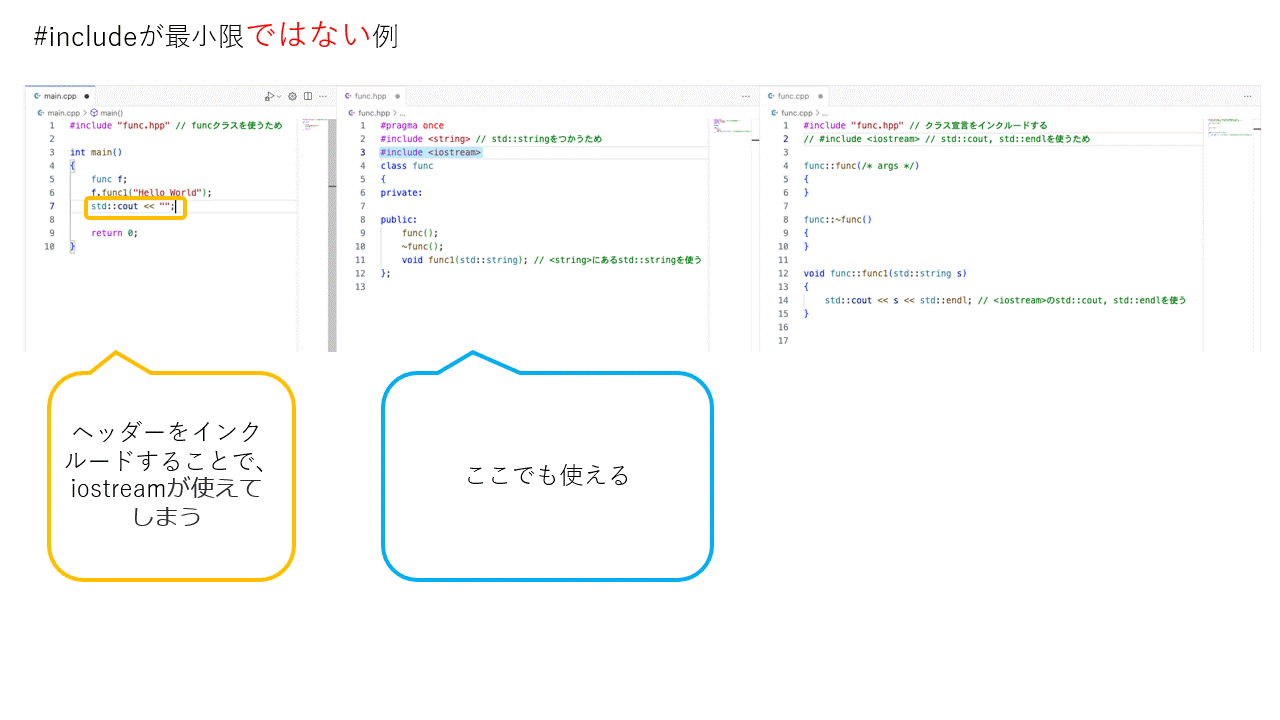
#includeはヘッダーファイル、ソースコードどこに書く?
ヘッダーファイルやソースコードごとに必要なものだけをインクルードする。
概要をgifで示す。
サンプルコード
- ヘッダーファイル:funcクラスの宣言など。
#pragma once // 2重インクルードを防止する
#include <string> // std::stringを使うため
class func
{
private:
public:
func();
~func();
void func1(std::string); // <string>にあるstd::stringを使う
};
- ソースコード:funcクラスの処理内容。
- func1は引数で受けた文字を標準出力に出力する。
#include "func.hpp" // クラス宣言をインクルードする
#include <iostream> // std::cout, std::endlを使うため
func::func()
{
}
func::~func()
{
}
void func::func1(std::string s)
{
std::cout << s << std::endl; // <iostream>のstd::cout, std::endlを使う
}
- ソースコード:mainの処理、func1を使う。
#include "func.hpp" // funcクラスを使うため
int main()
{
func f;
f.func1("Hello World");
return 0;
}
そもそも #include とは?
インクルードを行うとビルド実行時に読み込まれて、インクルードの記述された場所に展開される。
clang++ -o main main.cpp func.cpp
ビルドすると、複数のヘッダーファイル、ソースコードは最終的に1つの実行ファイルになる。
イメージは以下のようになる。(実際と異なります、あくまでイメージです。)
VSCode(エディタ)などの補完機能でも同じように扱われる
補完機能(予測変換)あるエディタでも#includeが宣言されると対象のファイルが読み込まれる。
下記にイメージ画像を示す。

(展開場所をわかりやすくするために、コメント文にしています。)
ソースコード(main.cpp, func.cpp)でヘッダーファイル(func.hpp)をインクルードすると自動的に#inculde<string>も展開されるのでmain.cpp, func.cppでもstd::stringが使えるようになる。
最小限になっていない例
例としてfuncクラスのインクルードはすべてfunc.hppで行う。
(恥ずかしながら、私が大学生の時にやっていたことです。)
#pragma once
#include <string>
#include <iostream> // ヘッダーでは標準出力していないのに記述
class func
{
private:
public:
func();
~func();
void func1(std::string);
};
#include "func.hpp" // 展開されるので、標準出力が使える
// #include <iostream>を書かなくていいのでコードがすっきりするけど・・・
func::func()
{
}
func::~func()
{
}
void func::func1(std::string s)
{
std::cout << s << std::endl; // <iostream>のstd::cout, std::endlを使う
}
このようなことをするとコードの見栄えはよくなりますが、main.cpp, func.cppでもVSCodeの補完機能でstd::cout, std::endlが見えてしまう(実際に使える)状態になる。
大規模なプロジェクトになると名前の衝突などを避けるためにもインクルードは必要最小限に行うことが望ましい。
参考文献
https://qiita.com/sksmnagisa/items/16d6782ff4e61fe9218c
【C++】C++のヘッダインクルード周りの話 その1(includeの目的と分割コンパイルの基礎)
https://rinatz.github.io/cpp-book/appendix-preprocessor-directives/
ゼロから学ぶ C++ プリプロセッサ司令
Discussion
これが真だと仮定すると、
は意味をなさないということになってしまいます。
実際にはそうではなくて翻訳単位が分かれるというところが大事になるのでした。
つまり次のようになるはずです。なお簡単のためにSTLヘッダーのincludeは展開しないで記載します。
翻訳単位1では
翻訳単位2では
コメントありがとうございます。
おっしゃる通り、この記事では分割コンパイルや翻訳単位の概念に触れておらず、その点が明確に伝わらなかったかもしれません。
実際には「ソースファイル(翻訳単位)ごとにコンパイルされ、最終的にはリンカで結合されて1つの実行ファイルになる」という流れになります。
この翻訳単位で考えると、各ソースファイルで必要なヘッダーファイルだけをインクルードすることは、ビルド時間短縮やコードの依存関係管理において非常に大切です。
ご指摘いただいた点を踏まえ、コメントを生かせる形で記事内容の更新を検討いたします。貴重なご意見をいただき、心より感謝いたします。