機械学習による競馬予想で安定して勝てるのか? (2022年に半年奮闘した上での考察)
この記事は 競馬AI / 予想Tech Advent Calendar 2022 の23日目です。
はじめに
「機械学習による競馬予想で安定して勝てるのか?」
ということで、半年ほど奮闘して実感したことや思ったことを書きます。
対象は中央競馬(JRA)の開催レースです。「馬柱」や「上がり3ハロン」のような一般的な競馬用語は知っている前提で書くので、競馬初心者の方は調べて詳しくなりながらお読みください。
また、この記事では詳細なコードの内容までは紹介しません。
自己紹介
普段はLinuxサーバ上でコマンドを叩くことで生計を立てています。開発職ではありません。得意なコマンドは uptime です。
競馬歴はダイワスカーレットが現役の頃からで、競馬ゲームのウイニングポストもよくプレイしていました。好きな馬はヒカリデユールです。
あらまし
職場の先輩が「機械学習で競馬予想AI作ろうとしてる。自分で予想するより成績いい。まずはWIN5を当てるのが目標」と話を持ち掛けたことから始まりでした。試しにその予想に乗ってみたところその日は全然当たらず、「これは自分で調整した方が (負けた時に) 納得できる」と思い、のめり込んでいきました。
すべて自作できるほどの熱量はなかったので、以下を参考にして作成しました。
(一部有料コンテンツなのでご注意ください。宣伝ではありません。著者とも関係ありません)
ちなみに、同書には購入者向けコミュニティなるものが存在するようですが、そちらには参加していません。
実行環境
Windows上のWSLでJupyterLabを起動して、そこで計算を動かしています。
WSLについては、DistrodでRHEL系OSを入れています。
処理をすべてクラウド化して、Web上でなんかいい感じのUIを作って操作できるようにすることも考えましたが、マシンスペックや維持費を考えると自前のPCで完結させるのが最適解かと思います。
(クラウド上でサービス構築する練習とかで割り切れるならいいんですが、競馬予想が目的だとどうしても計算部分が重くなってしまうので)
かわりに、クラウドストレージ(OneDrive)にデータを保存して、お出かけ用のPCでも気軽に実行できるようにしています。
奮闘記
参考資料とその問題点
参考にしたプログラムで処理している内容については、下記を参照ください。
(こちらは無料公開記事です、宣伝ではありません)
- netkeibaから過去レースと競走成績のデータをスクレイピングし、それを元に加工したデータを学習元データとして使用
- 上記のデータとLightGBMを用いて入着馬の特徴を学習
- 当日の出馬表から同様のデータを作成し、入着する可能性の予想スコアを表示
これだけで売り物になるレベルの読み物です。(というか実際に販売していますが)
ですが、少なからず「おや?」と思った点があったので、いくつか抜粋します。
勿論いいところも多いですが、記事の構成上悪いところのみ抜粋していることをご了承ください。
-
学習元データの母数が広すぎる
芝ダートすべての距離、すべての種類のレースを学習元にしています。あなたは芝2400mとダート1200mで同じ予想をしますか? -
競馬知識不足
競馬歴がある程度長い人が見ると「あれ?」と思うような要素が多いです。代表的なものとしては、上がり3ハロンのタイムの扱い方です。これは芝かダートかで大きく異なり、また距離やペースによっても変わります。なので、前走まで芝を走っていた馬のダート替わり、のような場合に適当でない予想スコアが出ます。 -
的中例が微妙
このへんの話。いいところだけ抽出していたら「高額配当を見事的中しました!」になるのは当たり前、せめて100レースくらいの通算成績を掲載して欲しいところです。同時に、買い目の根拠も乏しく、それについての検証も十分ではないと感じました。
実際にやったこと
技術的に「どんな値が使えそうか?」よりも、「実際に自分で競馬予想をする際に、何を参考にするか?」という目線に立って機能を追加したり削除したりしました。
● 学習元データの細分化
まずは芝とダートで分けました。障害レースはそれとは独立したデータとして区分します。さらに、出走馬のすべてが「前走なし」となる特殊なレースである新馬戦も独立して区分します。
- 芝
- ダート
- 障害
- 新馬
芝とダートはここから更に細分化します。まずは全く傾向の異なる「2~3歳限定戦」と「古馬混合戦」で分けます。
- 2~3歳限定戦
- 古馬混合戦
さらに短距離か中長距離かでも分けます。学習データの量の都合上、ちょうど似たような数になるポイントを探して以下のように分けました。
- 1700m以上 (中距離~長距離)
- 1700m未満 (短距離~マイル)
(一部を除く多くのコースにおいて、1周以上かそれ未満かが分かれる境界線でもあります)
結果、障害レースと新馬戦を除くと8個の学習元データ、合計で10個の学習元データになります。期間は直近10年分です。
距離については、いわゆる 「SMILE区分」 で分けるとより厳密かなと思いましたが、自分の環境ではかえって成績が悪化したので見送りました。
(SMILE区分:Sprint、Mile、Intermidiate、Long、Extendedといった距離区分の国際基準)
● 不要なデータの削除
データが多すぎてもよくないので、不要なデータは極力削除しました。
- タイム (要素として複雑なため)
- 着差 (数値の大小は展開による変動が大きいため)
- 馬体重 (不要)
- 馬体重増減 (レース直前にならないと発表されないため)
- 騎手 (集計方法が適当でないため、理由は後述)
- 血統 (集計方法が適当でないため、理由は後述)
- ほか
● 参考にする期間の短縮
「近5走の平均」なら参考の余地がありますが、「すべての期間の平均」は予想の際に参考になりません。例えば、ダートの強豪として有名なヴァーミリアンを例に挙げると、デビューから8走目までは芝を走っていて、3歳時はいずれも2桁着順でした。これらを5歳や6歳でのダート戦の予想で見るわけはありません。
これは特異な例でもなんでもなく、非常にありふれた例です。データとして参考にする期間はあまり長くしすぎない方がいいと思います。
(実際、前走と前々走の結果あたりしか予想の参考にしない競馬ファンも結構いるものです。競走馬とは、そのくらい短期間で大きく変わります)
● 数値の指数化
- コーナー通過順位の指数化
例えば6頭立ての6番手と18頭立ての6番手では全然意味が違うので、0~1の範囲になるよう補正します。 - 上がり3ハロンのタイムの指数化
芝とダート、また距離による較差の違いを補正するために、生の値ではなく指数化したものを使用します。
適当かどうかはわかりませんが、自分のモデルでは以下のように指数化していたので参考までに紹介します。(最適解ではありません)
芝の短距離の上がりタイムに近くなるように距離とダートで補正をかける。
芝→ 上がり3F/{0.94+(距離/20000)}
例:アイビスSD:32.0/0.99=32.3
スプリンターズS:33.0/1.0=33.0
春天:37.0/1.1=33.6
ダ→ 上がり3F/{1.01+(距離/20000)}
例:カペラS:36.0/1.07=33.6
東京大賞典:37.0/1.11=33.3
障→ ハロンタイム/{0.36+(距離*1.5/100000)}
例:中山GJ:14.3/0.424=33.7
中山大障害:14.0/0.4215=33.2
3000mのレース:13.3/0.405=32.8
障害レースはハロンタイム(1Fの平均タイム的なもの)を使っているため別計算……と思ったが、
面倒なので一旦は平地レースと同じような値になるよう補正する。
● 人気を裏切ったかどうか
(人気-着順)/頭数 のような、穴馬ほどプラスになり人気を裏切った馬ほどマイナスになる単純な指数も追加しました。
穴党の皆さんは自分で予想する時に少なからず参考にする指標かと思います。
後述する穴馬モデルでこのあたりが少なからず関連あるのではないかと思っています。
● その他フラグの作成
気休め程度に以下の判別フラグも追加しました。
- 牝馬限定戦
- ハンデ戦
● 複数モデルの使用
単一のモデルではなく、以下の5つのモデルを複合で使用しました。
- 1着になるかどうかの予想スコア
- 2着以内に来るかどうかの予想スコア
- 3着以内に来るかどうかの予想スコア
- 2着以内に来るかどうかの予想スコア (穴馬モデル)
- 3着以内に来るかどうかの予想スコア (穴馬モデル)
上記のうち穴馬モデルは、「単勝10倍以上で2着or3着以内に来た馬」を学習させたモデルです。
上記5つのモデルの出力結果から、さらに以下を求めました。
- 全モデル(5つ)のスコアの最大値
- 通常モデル(3つ)のスコアの最大値
- 穴馬モデル(2つ)のスコアの最大値
最終的には「全モデル(5つ)のスコアの最大値」を重要視しています。平均値や中央値も試しましたが、自分の環境では最もパフォーマンスがよかったのが最大値だったので最大値を採用しました。
(ただし、異常に大きいスコアは「外れ値」として除外し、残ったものの中の最大値です)
これらを計算した結果、このような出力結果になります。
(見やすくするためにExcelに添付しています、また「着順」列は発走前は表示されません)
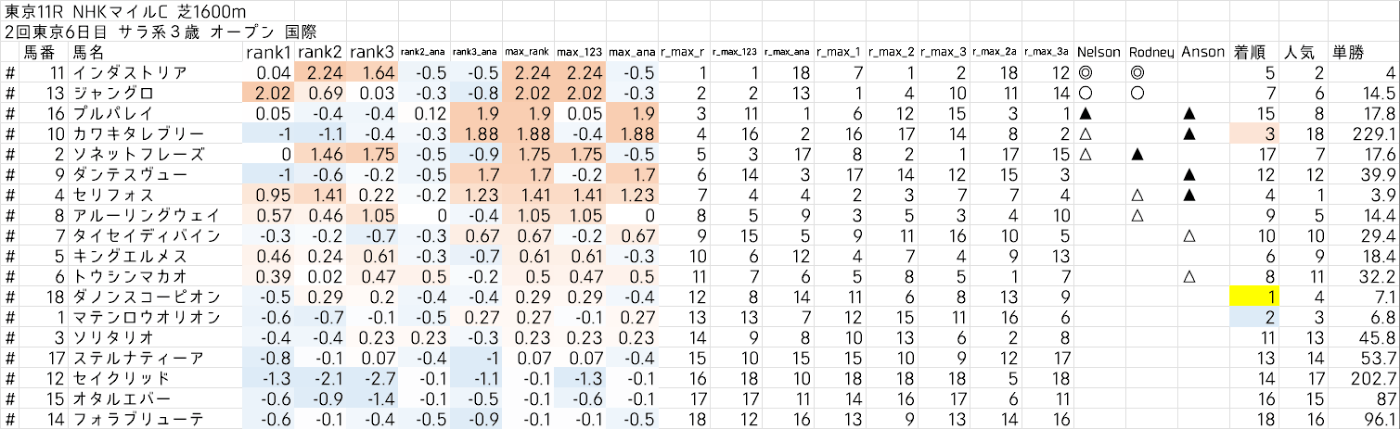
上位から順に◎○▲△△としています。穴馬モデルの最大値の評価のみ、スコアが一定以上の場合に▲か△を表示しています。
上記の例では、最低人気ながら3着に滑り込んだ馬を「全モデルの中で4番目にスコアが高かった馬」として挙げていますね。 作者に似て なかなかの穴党のようです。
● 買い目の最適化
「どの馬の予想スコアが高いのかはだいたいわかった、じゃあそれをどうやって買えば最も儲かるのかね?」
多分、競馬予想AI的なものを作る人が最終的に辿り着く問いがこれだと思います。 これこそが肝心なのですが、色々調べてもここの検証プロセスが雑になっているケースが多かったです。 (だいたいみんな予想スコアを出したあたりで満足して燃え尽きる)
ここは生データを直接編集しながら解析したかったので、表計算ツールの世界最大手でもある Microsoft Excel で集計しました。
Excel職人なのでVBAマクロを使うまでもなかったです。
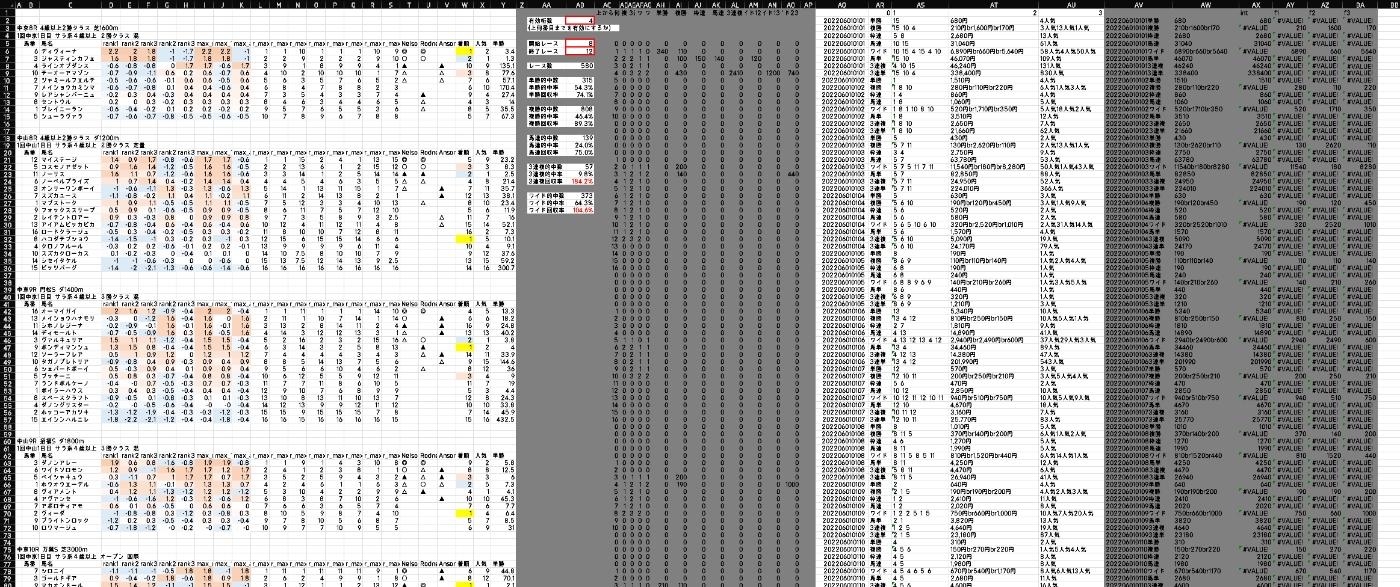
(傾向の解析には Microsoft Power BI も使いましたが、あまり特筆することがないのでここでは省略します)
● その他
netkeibaの出馬表で人気順やオッズを取得したい時に、動的に表示されて簡単に取得できないため、ScrapingAntを経由して取得する処理も追加しました。
(ただし、これらは予想には使わず、あくまで出力結果表示時の補助情報として使っていました)
運用した結果
ひたすら回してみて「どのパターンが最もパフォーマンス良いか」を解析したところ、自分の環境では「第8〜12レース」で「4頭ボックス」のパターンが最も優秀でした。
本来はコースや条件による得手不得手も詳細に分析してみたかったところですが、複雑になりすぎるのでレース番号のみとしています。曖昧な区切りですが、意外にも「第8レースのみやたら強いモデル」のような無視できない特徴がいくつか見られました。
「勝てるパターン」を確立し始めた4~5月にかけてはすこぶる好調でした。
例として、1月~5月下旬(オークスの週)までの集計データが下記になります。
以下に掲載するのは、各場の第8~12レースで各式を4頭ボックスで買った場合の結果です。
(複勝の的中率のみ、1~3着を漏れなく当たった場合を100%としています)
対象レース:580
| 的中数 | 的中率 | 回収率 | |
|---|---|---|---|
| 単勝 | 315 | 54.3% | 74.1% |
| 複勝 | 808 | 46.4% | 89.3% |
| 馬連 | 139 | 24.0% | 75.0% |
| 3連複 | 57 | 9.8% | 184.2% |
| ワイド | 373 | 64.3% | 104.6% |
ちなみに軸指定でなくボックスにした理由も解析によるもので、指数上位3頭に入着率の違いが大して見られなかったからです。3頭を軸にしたらそれはボックスと変わりありません。
(もし突出したスコアがある場合は、それを軸にした方が買い目を絞れるので結果的に高パフォーマンスに繋がります)
控除率を考えると、回収率80%で「平均以上のパフォーマンス」となりますが、
収支の上では回収率100%を超えて初めて「勝ち」となります。
その場合、上の例ではワイドボックスと3連複ボックスで買い続けた場合に「勝ち」ですね。
3連複の回収率に目が行きがちですが、的中率を考えるとワイドの安定感も目を見張るものがあるでしょう。
上記は第8~12レースの話でしたが、このモデルは特に第12レースで非常に高いパフォーマンスを出していました。
対象レース:116
| 的中数 | 的中率 | 回収率 | |
|---|---|---|---|
| 単勝 | 67 | 57.8% | 69.1% |
| 複勝 | 181 | 52.0% | 108.0% |
| 馬連 | 28 | 24.1% | 91.4% |
| 3連複 | 15 | 12.9% | 267.1% |
| ワイド | 94 | 81.0% | 198.8% |
複勝ですら回収率100%超え、ワイドに至っては定期的に万馬券をもたらしてくれました。
4頭ボックスからのワイド万馬券は普通に予想しててもなかなか狙えるものではないので、素直に感服しました。ここでようやく「勝ち筋が見えた」と実感したところです。
うまくいきすぎた例 (ワイド総取り):
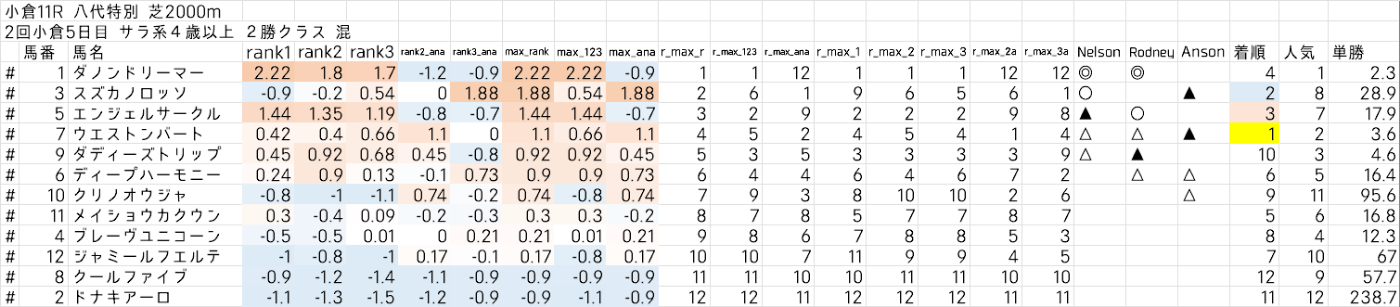
うまくいかなかった例 (多くの例はこんな感じ):
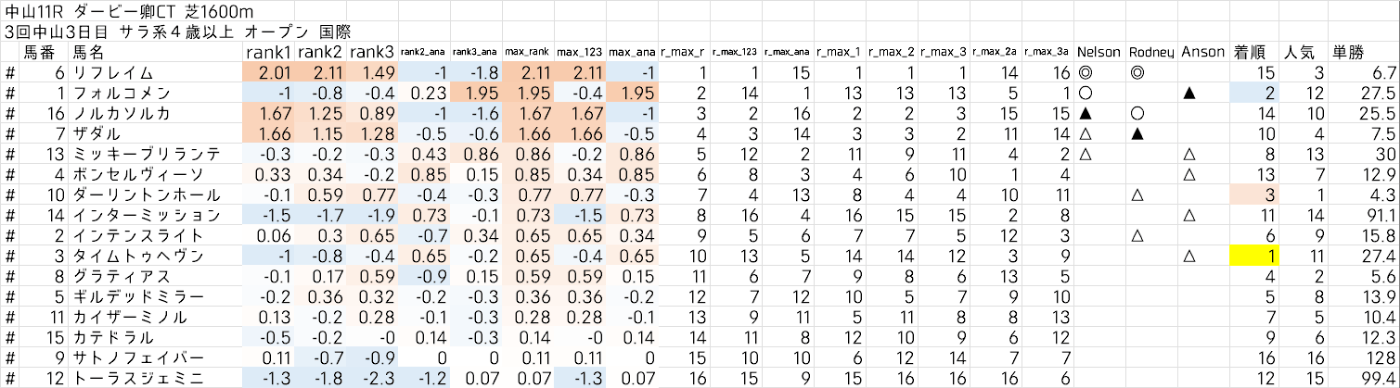
とはいえ、これはトータルの成績の話であり、週によっては全く的中しないこともあります。
この傾向は穴馬モデルほど顕著で、野球で例えるなら「当たればホームランだがそれ以外は三振」というアダム・ダンのような傾向が見られました。
「的中率が低いなら買い目を広げればいいじゃない」と思った方、それは間違いです。買い目を広げれば広げるほど、今度は回収率が下がります。
回収率が上がらない人は、まずは買い点数を減らすことを考えてみてはいかがでしょうか。
ちなみに自分のモデルでは、 回収率だけ見たら3頭ボックスの3連複が最強でした。 買い点数はいくつでしょうか。 1点です。 なお、的中率はお察しください。
しかし、
6月になると目に見えて成績が悪化しました。
同じく対象は各場の第8~12レースです。
対象レース:110
| 的中数 | 的中率 | 回収率 | |
|---|---|---|---|
| 単勝 | 62 | 56.4% | 94.8% |
| 複勝 | 140 | 42.4% | 74.3% |
| 馬連 | 22 | 20.0% | 67.4% |
| 3連複 | 7 | 6.4% | 44.2% |
| ワイド | 58 | 52.7% | 70.6% |
惨憺たる結果でしたが、例によって得意の第12レースでは粘りを見せます。
対象レース:22
| 的中数 | 的中率 | 回収率 | |
|---|---|---|---|
| 単勝 | 11 | 50.0% | 87.0% |
| 複勝 | 28 | 42.4% | 90.8% |
| 馬連 | 5 | 30.4% | 30.4% |
| 3連複 | 2 | 9.1% | 38.8% |
| ワイド | 13 | 59.1% | 125.7% |
ワイドでなんとか回収率100%を超えていますが、5月までのパフォーマンスを見ると物足りなさが残ります。
6月に一体何があったのか。
勘のいい競馬ファンの方はいくつか思い浮かぶ点があると思いますが、
このあたりはいわゆる 「夏競馬」 の季節が始まる頃ですね。
「夏は牝馬」といった言葉もありますし、未勝利戦を除いて3歳限定戦が無くなる時期でもあるので、傾向がそれまでとガラリと変わります。
しかし、季節を知らないアルゴリズムはそれを知りません。結果、5月以前と同じ狙い目のままでは数字は目に見えて悪化。
6月が終わったところで「夏が終わって傾向が落ち着くまでどうしようもないな」と思い、改善案を考えつつ一旦眠らせることにしました。
まとめ
というわけで、1月から6月にかけての半年間であれこれ奮闘した記録でした。
「機械学習による競馬予想で安定して勝てるのか?」
という問いに対しての個人的な答えは、
「勝てる……!勝てるが……今回まだその時期とレースまでは指定していない、そのことをどうか諸君らも思い出していただきたい」
「つまり、本気になれば機械学習による予想をするのは春競馬や特定のレース限定ということも可能だろう」 ということでしょうか。
しっかりと見極めさえすれば、勝ち筋はあります。
しかし「常勝」には程遠いです。馬券的中率100%を望むなら全通り買うしかありません。
「競馬に絶対はない」 という言葉にあるとおりです。
この言葉は 「競馬に絶対はないが、ルドルフには絶対がある」 と続きますが、 そのシンボリルドルフですら何度も敗れたのが競馬というスポーツです。
(どんなに能力の高い馬でも必ず勝てるとは限らない、という競馬の恐ろしさは2009年のエリザベス女王杯あたりを見れば実感しやすいでしょう)
さて、
個人的には、これを競馬予想AIと呼ぶにはまだまだ機能が乏しいと思っています。
(ここまで、あえて「AI」という単語は数回しか使っていません。あくまで「人間の代わりに判断をする人工知能」という意味での「AI」です)
現状だと予想スコアは出してくれますが、それの根拠を提示する仕組みを入れていません。というより、仕組み上それは難しいです。
これは、その予想スコアを見た人間が、予想スコア以上の情報を知れない、 という意味ですね。
(予想印はあくまでスコアに基づくものです)
「この近走の凡走パターンは、大駆けをする穴馬によくある特徴」とか、
そういうコメントを入れるところまで気が回れば「人間の代わりに判断をする人工知能」としてのAIに匹敵するものだと考えています。
または、 「機械学習によって導き出された予想スコア」を別軸の視点で評価して判断するプロセスによっても実現されると思います。 機械学習によって出された結果の最適解を、また別の機械学習なりデータなりで評価して提示する。それができれば最早ただの「計算機」などではなく、「知能」と呼んで遜色ないものだと思います。 (ひと手間加えただけなのに)
もしくは、「勝ち馬を予想するためのAI」ではなく、 「来ない馬を早々に除外してくれる」や「危険な人気馬を教えてくれる」 といった、 勝ち馬とは逆のアプローチから消去法的なソリューションを提供してくれるようなアルゴリズムも有用だと思います。
危険な人気馬については一時期取り組んでみたんですが、その時はうまく抽出しきれず消化不良になってしまいました。しかし回収率を上げるという点においては無視することのできない要素だと思います。
完全無欠に近い競馬予想AIを目指す上では、技術の進歩とかそういうのよりも、それを運用して取捨選択する人間の力量が欠かせません。何度も転んで、何度も試し、ともに一歩ずつ進んでいく。ひたすら調教を繰り返し、世話をして、レースに挑む。 競馬予想AIを作ることは、まるで競馬のようですね。
「『人はなぜ競馬に熱中するのか?』――それには、あらゆる分析を上まわる一つの明快な解答がある。少なくとも私の場合。私は、競馬が好きなのである」(寺山修司「馬敗れて草原あり」)
おまけ1:機械学習での競馬予想に使えそうな要素と使えなさそうな要素
キリよく締まったところで本題は以上にして、
以降はいちIT系競馬ファンから見た「機械学習での競馬予想に使えそうな要素と使えなさそうな要素」の考察をつらつらと書きます。
「機械学習」という言葉をわかりやすく嚙み砕くと、今まで人間が経験と勘でやっていた「職人技」を機械に代替させる手段のことだと思っています。
それらの「職人技」が活きる場面、全く活かせない場面、その他の単純なプログラムの方が利のある点、というのを書いていきます。
以下、すべて個人の感想です。意見には個人差があります。
近走成績
競馬新聞なりnetkeibaなりで馬柱を見るときに、多くの競馬ファンが真っ先に評価対象にする項目は近走成績だと思います。その内容について詳細に見ていきます。
成績とクラス
ある馬は前走1着、ある馬は前走8着、 こう書くと差があるように思います。では次の文章をお読みください。 ある馬は前走3勝クラスで1着、ある馬は前走GIで勝ち馬と0.5秒差の8着。 さっきの文章と力関係が逆転しましたね。
成績を語る上で、そのクラスがどうであったかは欠かせません。
(中央競馬はまだ単純です。地方競馬では更にクラスが細分化されます)
クラスの判定で難しいのが3歳限定戦と古馬混合戦の境目にある期間です。もっとややこしいことに、3歳限定の条件戦がなくなった後でも3歳限定の重賞は芝ダート共にいくつか開催されます。(ラジオNIKKEI賞、レパードS、紫苑S、ローズS、セントライト記念、神戸新聞杯、秋華賞、菊花賞)
ややこしいと思うなら、すべて指数化してしまうのがいいのではないでしょうか。
少なくとも、着順を生の値でそのまま扱うよりは正確なデータになると思います。
位置取り
競馬予想においては非常に重要な要素ですが、機械学習においては正直扱いが難しいと思います。無論、コース別にモデルを作るとかならはっきりした特徴が出るので、使い方によっては有用だと思います。
ただ、出遅れ癖のある馬や直近で戦法を大きく変えた馬には対応ができないので、それは許容するしかなさそうです。また、デュランダルのような殿一気タイプの馬は外れ値扱いされそうですが、それも許容するしかないでしょう。
上がりタイム
かなり前の項で先述したとおり、上がり3ハロンのタイムは芝かダート、あるいは距離によって大きく変わります。なので、どの距離でもどの馬場でも一定の指数になるように加工が必要でしょう。
ペース
スローペースなのかハイペースなのかでレースの展開が大きく変わるのは知ってのとおりです。
ただ、それを機械学習の餌にして食べさせるのは難しいと思います。
走破タイムについても同様で、これはコースによっても変わります。海外の競馬場も含めるとかなり振れ幅が大きいです。
極端な例を挙げると、メジロブライトの新馬戦のように芝1800mを芝2000mのようなタイムで走った馬ですら、その実力を鑑みるとある程度平等に評価しなくてはなりません。
無理に補正するくらいならいっそペースや走破タイムといった要素を除外してしまう選択肢もアリではないでしょうか。
出走間隔
出走間隔の最適解はありません。断言できます。
連闘は必ずしもマイナスではありません。レースで全然力を出せなかった場合などに、疲れが全くないので翌週も使うということは普通にあります。
長期休養も必ずしもマイナスではありません。鉄砲駆けタイプの馬にはむしろ好材料です。
最近増えた「ステップレースを使わずに外厩からGI直行」みたいな場合も、数字の上では「休養明け」扱いになります。例えば2021年のソダシの桜花賞。
ここまで書くと、出走間隔についてはデータとして除外してしまってもいい、くらいに思います。
馬場状態(天候)
「重馬場巧者」のような馬は結構いますよね。その反面、「こんな重い馬場では、どうしようもないよ」と喋った馬もいます[1]。
馬場状態は、人によってはかなり重視するポイントだと思います。(競馬新聞にも「重馬場の通算成績」が載るくらいには重要な要素です)
ただし、日本では「良」→「稍重」→「重」→「不良」の区分ですが、実際の馬場水分量はもっと細分化されています。(データとしてうまく取れるかどうかは分かりませんが、少なくともJRAは毎開催で馬場の含水率を発表しています)
天候については、単純に晴れか雨か曇りかといった空模様は要素として関連が薄いと思います。どうせなら、空模様よりは気象庁の観測データあたりから気温を取ってきた方が面白そうです。それだけで夏競馬かどうかの判定にも使えますし。
馬場の荒れ具合と使用コース
競馬玄人のみなさんなら確実に考慮しているだろう要素です。
開催日が進めば進むほどコースの内側の馬場は荒れ、外差しが決まりやすくなります。直線が600m以上ある新潟外回りコースなんかは、皆が率先して馬場の外側を通りたがるほどです。
反面、Dコース→Aコースみたいに変わった日には、コースの内側に幅9mの「グリーンベルト」が出来上がり、内枠と外枠が真逆の傾向になります。
使用コースのデータはJRA-VANの有料プランで取れると聞きました。(内容を保証するものではないのでご自身でご確認ください)
これも、機械学習の餌にするにはちょっと複雑すぎる要素かと思うので、何かしらのプログラムで指数化するのが良さそうです。
悩むくらいなら考慮しないのも一手。道中の位置取りなんて半分以上は当日の運ですし。
近走成績についての話は以上で、以降はそれ以外の当日参考にする要素について書きます。
調教
調教の内容を全く参考にしない人は結構いると思います。しかし、見る人にとっては重要な要素。ただし、機械に判別させるには要素が複雑すぎます。ポリトラック、坂路、ウッドチップ、馬なり、一杯、先行、同入……
「その馬にとっていい調教内容だったかどうか」というのは、馬の個性によってバラつきがあります。つまり、調教内容は凄いがレースで凡走を繰り返す馬もいて、また調教内容は平凡でもレースでは毎回好走するような馬もいる、ということです。
「その調教の内容がどうだったか」を判断するのは「職人技」の領域ですが、このあたりはまだまだ人間の専門家に任せておいた方がよさそうです。 (トラックマンは機械に奪われない仕事のうちのひとつ)
例によって、これも機械学習の餌にするくらいなら何かしらのプログラムで指数化して判断するのがよさそうです。
当日の展開予想
ペースの項目で書いた内容とやや被りますが、
「当日どういう展開になるか」という予想は、機械学習による入着予想よりも時として重要です。
「レース展開ならnetkeibaの出馬表の一番下に書いてあるじゃないか」というのはごもっともです。 じゃあ今すぐそれをスクレイピングするんだ!
もっとも、展開が分かっただけで勝ち馬が分かるなら皆ここまで苦労していませんが。
ただ、それを機械学習の餌にできるかどうかはまた別問題になります。
有効活用するなら、ペース別のモデルを作るとかでしょうか。
ハイペースは先行総崩れ、スローペースは前残り、のような定説が数値化されるだけのような気もしますが。
馬体重
馬体重の増減量は当日のレース前に発表されます。なので、出馬表データを発表前に取得した場合に備えて何かしらの例外処理を入れる必要があるでしょう。
前走からの増減量だけでなく、過去1年からの増減量、デビューからの増減量、初勝利からの増減量、最後の勝利からの増減量、など切り口は色々考えられると思います。(要素の増やし過ぎには注意しましょう)
ただし、馬体重そのものの値を使うのはオススメできません。サラブレッドの馬格はおよそ400kgから600kgまで幅があり、そこから一定の傾向を導き出そうとしたところで、無視できない量の「外れ値」に悩まされることは必至です。小さい馬が勝てないならドリームジャーニーがグランプリ連覇をすることはなく、重い馬が勝てないならゼニヤッタが全米最強馬と呼ばれることもなかったでしょう。
ちなみにアメリカの競馬では馬体重は発表されません。
これを「つまり馬体重の増減は重要な要素ではない」と捉えるかどうかの解釈はお任せします。
パドック
パドック、つまりレース前の輪乗り。
日本のパドック周回は海外と比べて特に長いようです。
かの名ジョッキー武豊にして「パドック見たって分からない、お客さんは何を見てるんだろう?」と言わしめた要素。
そのエピソードの印象が強すぎて、自分はパドックを参考にしたことはあまりありませんでした。 パドックの見方が分からない、という理由もありますが。
いい機会なので調べ直したら、前述の発言内容は「調子の良し悪しはわかるが、馬の強さまでは分からない」というもののようでした。
さすが騎手というだけあって、実際に跨れば強い馬はすぐ分かるとのことでしたが。そこはファン目線では判断しかねる要素です。
個人的にも、土曜にテレビ東京でウイニング競馬を見ていたら、元調教師の大久保洋吉氏がパドック診断で調子のいい馬として挙げた馬が悉く好走するというのを見て、
「やはり調子の良し悪しは、見る人が見れば分かるものなのだな」と強く感じました。
(大久保師はメジロドーベルやショウナンカンプなどの調教師として有名です)
では、それをデータとしてどう取り込むか。
幸いにして、パドック中継はどんなレースでもグリーンチャンネルでしっかり中継してくれているので、解析をするならそのあたりが切り口になると思います。
ただ、画像解析ならアテはあるんですが、パドックでの状態を確認するとなるとどうしても動画での検証にならざるを得ず、そうした場合にどうやって解析するのが最適解か?というのは少々判断しかねます。(いい方法があるという場合はなんかいい感じで共有してもらえれば全国のIT系競馬ファンが助かります)
馬体
また、パドックからの派生として、馬体の良し悪しという観点もあります。これは動画ではなく静止画でもある程度判断できるところでしょう。
特に新馬戦で「血統で人気になっているが馬体の作りが間に合っていない」という馬を見つける時は特に役立つと思います。
自分は2022年の海外競馬中継で合田直弘さんが「バーイード、素晴らしい馬体ですねぇ」と言っているを、「どこがどう良いんだ……?」と思いながら眺めていたので、正直この観点に関してはサッパリなのが口惜しいところです……
(※バーイードは2022年の欧州カルティエ賞年度代表馬です)
いわゆる「パドック職人」に言わせると、そもそもの馬体の作りから適性がある程度分かるようです。(父が○○○で後ろの脚が短いとダート向き、とかそういうの)
職人技と聞くとどうしても機械学習で代替させたくなりますが、このあたりはレースの予想よりもむしろ一口馬主とかそういう方面に活用できると思います。ご参考までに。
馬具
ブリンカー、シャドーロール、チークピーシーズ、メンコ……
競馬初心者を卒業したあたりで覚え始める単語が並びます。どんな馬具を用いるか、というのは重要な要素です。
しかし、これらのうち出馬表やレース成績などに表記されるのはブリンカーのみです。それ以外の要素はパドック以降の段階で判別する必要があります。
つまり、単に過去データをスクレイピングするだけではブリンカーの有無しか取得できません。
ブリンカー以外の馬具の情報をどうしても活用したい場合は、独自にデータを収集し蓄積しなければなりません。「国枝厩舎所属ならシャドーロールを付けているものとする」のような乱雑な実装はおすすめしません。
なお、メンコは発走前に外すことがあるので注意が必要です。
返し馬
返し馬を見て予想を決める人も意外といるようです。
主要GIレースの返し馬しか見たことのない人も多いと思いますが、グリーンチャンネルでは毎レース中継しています。
ただし、機械に判別させるには映像が雑すぎるので、これはどうやっても無理です。
なんなら返し馬の中継に映らない馬もいますし。
パトロールビデオ
予想の際に前走や前々走のパトロールビデオを参照したことはありますか?その馬が本当に実力を出せたのか、または展開がうまくハマりすぎたのか、色々なものが見えてきます。
ここも正直言って「職人技」の領域だと思うんですが、機械に判別させるには要素が複雑すぎて無理だと思います。 何なら自分で見た方がよく分かると思います。
騎手
機械学習をする時に騎手データを入れる必要はありません。
おそらく、過去の勝率がそのまま反映されるだけかと思います。
それの何が問題かと言うと、過去のデータに反映されていないような最近ブレイクした騎手が低く評価されてしまう傾向が出ます。2022年で言えば、当年にデビューして勝ち星を50以上も重ねた今村聖奈騎手なんてデータにありませんよね。
直近のリーディングのデータや、更に言えばコース毎の得手不得手は多いに参考になるので、データだけ持ってくる形にした方がよいです。
乗り替わりの考慮も、理由が様々なので大レースくらいしか参考にしなくていいと思います。
調教師
データは不要です。理由は騎手の項に書いたとおりです。
直近のリーディングのデータでも持ってきた方が早いと思います。
血統
競馬はブラッドスポーツです。ゆえに血統は奥深いので、安易に機械学習でどうこうするような対象ではありません。
……というのは半分くらい冗談ですが、血統だけでレースの勝ち負けが分かるなら苦労しません。
加えて、血統はその競走馬にとって生涯に渡って変わらない要素であります。
例えば、機械学習にこの要素を加えるというのなら、 その馬にとって生涯のバフやデバフがかかるわけです。 機械学習には不要ですね。「サドラーズウェルズ系の馬は日本の馬場に合わないからマイナス!」とかされたら、フランケル産駒ですら一生推される気がしません。
これも新種牡馬のデータなどは必然的に不足するので、データとして不十分どころか邪魔になると思います。2022年で言えばドレフォン産駒とかですね。初年度から早速クラシック勝ちましたよね、ジオグリフ。
それでも「どの父馬なら勝ちやすいか」というのがどうしても知りたい場合は、たぶん種牡馬リーディングの勝率とかAEIとか見ると早いと思います。
(Average Earnings Index (AEI):その馬の産駒が平均に比べてどのくらい稼いでるかの指標)
もっとも、単年のAEIだけで見るならブゼンダイオー産駒あたりが最強になるわけですが[2]。
ただし、コースや馬場コンディションによってははっきりした傾向が出るものもあるので、これもやはり使いようによっては非常に有用だとは思います。
例が古いですが「トニービン産駒の左回り」のような例は結構あります。
少し挙げた程度でもこのくらいの文量になるので、
もし手に余すようであれば血統についてはバッサリと諦めてしまうのがいいと思います。
自分のモデルでもあえて血統のデータは使っていません。 (血統ばかり見るとつい思い入れが出てしまって碌な結果にならないので。それをわざわざ機械にまで再現させる必要はありません)
特にウマ娘ブームから始めて競馬歴のまだ浅い人たちであれば、まずはダービースタリオンやウイニングポストのようなゲームでもいいので、血統への自身の理解を深めるのが最も手っ取り早いと思います。
(※意見には個人差があります)
(※これはウイニングポストの宣伝です)
おまけ2:余話
余話1
6月末でいったん機械学習での競馬予想をお休みした後、数年ぶりに競馬場に行く機会がありました。日刊競馬を片手に予想を楽しんだところ、なかなかの的中率と回収率だったので、「これもう機械学習いらないのでは?」と本気で思いました。
笑い話のように書いてますが、今まで注ぎ込んだ労力と時間を考えるとかなりマジなトーンで言ってます。
とはいえ、人間の「職人技」を代替する手段が機械学習であるという考えは変わらないので、良いモデルが思いついたらまた改修に取り掛かりたいと思います。
余話2
話は変わりますが、あまり競馬で勝ちすぎると税金の問題が付きまとうのが難点です。
自分は申告が必要なほど勝ったことは無いですが。いずれWIN5を当てるなら避けて通れぬ道ではありますが、その見通しも当分ありません。
確か「事業として利益を上げるために、一定のルールに基づいて継続的に購入する」場合は外れ馬券も経費扱いになる判例があったかと存じますが、
事業として競馬に投資するなら、債券や高配当ETFの方がよっぽど安定して稼げると思います。税金の計算も簡単ですし。
余話3
当初これを始めた目的のひとつに、
「自分も勝てる競馬予想AIを作ってWIN5を当てたい」 がありました。
じゃあWIN5を当てるためにはどのくらいの数字が必要なのでしょうか。
簡単に計算してみましょう。
「単勝的中率50%」の場合、全レース的中する確率は単純計算で50%の5乗=3.125%になります。年に1回や2回はチャンスがありそうです。
「単勝的中率40%」の場合、全レース的中する確率は単純計算で40%の5乗=1.024%になります。2年に1回当たるといいくらいの確率です。
(※いずれも「ガチャを外し続ける確率」の計算ではないのでご注意ください)
対して、各レースで3頭ずつピックアップすると1回の試行あたり3の5乗=243通りの購入が必要となり、これを年間約50回繰り返すとすると、累計で120万円以上の資金が必要になります。
もし2年に1回しか的中が望めず、その的中額が数十万円であった場合は、かなりのマイナスになること必至となります。そのため 「より少ない手数で」「より高い的中率」が求められることになります。
(参考までに、WIN5は控除率が30%なので、回収率70%で「平均以上」となります)
また、頭数を3頭ではなく2頭にする場合は2の5乗=32通りで年間20万円弱と、より低予算での試行が可能となります。
自分の調整したモデルでは、穴馬モデルの影響もあって上位3頭の単勝的中率は40%強が関の山でした。WIN5的中は遠い夢です。(それでもWIN4まで迫ることはありました)
もっとも、WIN5は対象レースが第9~11レースに限られるので、そこの条件に特化したモデルを作成すれば改善を見込めるかもしれません。
なお、2022年現在のNISAによる非課税枠が上限120万円/年なので、やはり債券や高配当ETFに投じた方が安定して稼げると思います。
(ちなみに、2003年に有名になった 「ヒシミラクルおじさん」 は、同じような額から更に単勝を2回コロガシて約2億円にしたとされる伝説があります)
余話4
今回は中央競馬(JRA)の開催レースのみ対象としていますが、地方競馬や海外競馬、ばんえい競馬などでも応用できると思います。それどころか、競馬ですらない競輪やボートレースなどでも、データさえ揃っていれば同様の試みは可能だと思います。(もちろん、取得して使用できるデータの種類はそれぞれ大きく異なりますが)
いずれも 初心者目線であれこれ試すよりは、自分で予想をしてある程度詳しくならないと適切な情報の取捨選択ができません。 なので「詳しくなってから始める」か「始めるために詳しくなる」か、いずれかの工程が必要になると思います。
(もちろん、あまり知識のない状態でしか見えない物事も多いですが、それ以上に「あまり知識がないことが原因によりデータの取り扱いが不適切になる」ことが問題になる点は記事の序盤でも書いたとおりです)
というわけで、手始めにばんえい競馬の観戦あたりでも始めてみるのはいかがでしょうか?
(※これはばんえい競馬の宣伝です)
余話5
「じゃあ競馬に詳しくなるにはどうすればいいのか?」 という直球な質問に対しては、
「 『優駿』あたりを毎月読むのが一番手っ取り早いんじゃないですか?」 という鋭い打球でお返しします。
「優駿」はJRAの機関広報誌という立ち位置なので、他の競馬雑誌と比べるとギャンブル要素も薄めで、牧草を撫でる風を感じるような爽やかでスッキリとした内容の雑誌です。(といっても書店では「ギャンブル」系の棚に置かれることが多いですが)
カレンダーなどのオマケもたまについてくるので、特に初心者へのオススメとしては鉄板です。 実家の居間などにさりげなく置いておくことで、両親や家族の「競馬ってギャンブルでしょ?」のような偏見を和らげる効果もあります。
馬そのものへの理解を深めるなら「UMA LIFE (ウマライフ)」あたりも一度読んでみるといいかもしれません。こちらは乗馬要素が強めの雑誌です。
また、血統の項でも話したとおり、競馬ゲームに興じるのも手っ取り早いと思います。ウマ娘よりはウイニングポストのようなリアル系の方が、競馬の歴史も追うことができてオススメです。近年のものはNintendo Switchにも対応していて気軽にプレイできますし、特に競馬初心者の方はこの機会に最新のものをプレイしてみてはいかがでしょうか?
(※これはウイニングポストの宣伝です)
おまけ3:極端な事例
(2022/12/29 追記)
この記事を投稿した後、久しぶりに2日ほど機械学習予想を動かしてみました。
2022/12/25の有馬記念の日はいわゆる「全く的中しない日」でしたが、3日後のホープフルSの日は一変。最も冴えたのはメインレースでした。
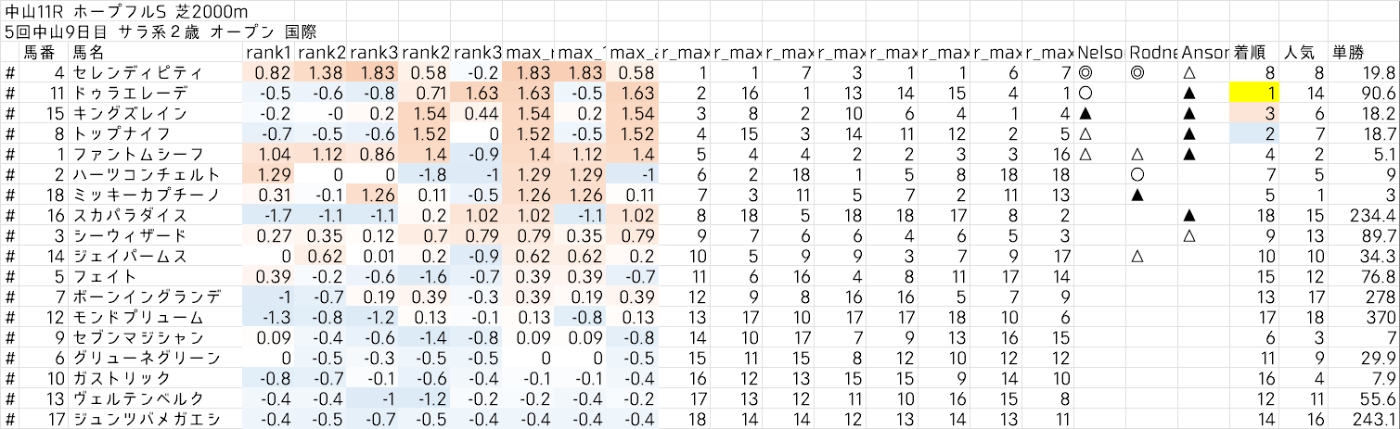
4頭ボックスだとワイド総取り、うち2つが100倍を超えるオッズの大穴馬券でした。馬連や3連複については言わずもがな。半年に渡って集計していた期間でも、ワイド万馬券を複数的中させたケースは記憶にないので、この日は「年に1回の大当たり」と呼べるでしょう。
さて、この極端な事例を見て「安定して勝てるのか?」を考え直してみましょう。
実際に集計するとなると、このレースを集計に入れるか入れないかで回収率が大きく変動します。逆に言えば、こういった大荒れのレースを取ることで回収率を底上げしている、という側面もあります。
(こういう例は株式投資にも似たようなものがあり、「株価の大きく上がった年でも、最も上がった5日分を除いたパフォーマンスは酷いものである」といった例は往々にして存在します)
そもそも、レースというものは安定して荒れるものでしょうか?
2022年は、GIレースで1番人気の馬がほとんど勝てないという不思議な傾向のある1年でした。しかし競馬というものは、勝ち馬はどのレースにも存在しますが、その馬が人気かどうかを決めるのは他でもないファンの皆さんです。 これは、あまりにも不安定すぎる要素です。
「入着する馬を安定して当てる」という目標はある程度達成できたとしても、その上で「安定した回収率を上げる」にはあまりにも不確定要素が多すぎる、ということです。
特に、競馬のような公営競技には控除率という概念があり、平均を見ると「必ず負ける」ようになっています。 決してゼロサムゲームではない マイナスサムゲーム です。
(これに対して、先物取引や為替取引はゼロサムゲーム、長期的な株式投資はプラスサムゲームと言われることが多いです。しかし、機関投資家のようなプロの存在もあるので、特に前者は「実質マイナス」とも言われます)
ちなみに、オッズを下げる方法は簡単です。同じ買い目を買ってくれる人を増やすことです。 資金力のある方は試しに1つの買い目を数千万円分買ってみると分かりやすいかと思いますが、 公営競技ではオッズの裏側に「支持率」があります。単勝2倍の場合は単勝支持率が約40%、の具合です。支持率が増えれば増えるほどオッズは減少します。
「逆に言えば、自分と逆張りの予想を多くの人に買ってもらえば自分の買い目のオッズを上げることができるのでは?」
と思った方、なるほど完璧な作戦ですね。実質不可能という点に目をつぶれば。
YouTubeとかブログとかで競馬インフルエンサー的なものを目指しているみなさん、注目を集めるたびにもっと大切なものを失いつつありませんか? つまり大事なのは、いかに自分の予想を隠しつつ「ハズレの予想」を注目させるかです。
こう書いたところで、競馬新聞や番組で予想印を打っている人のことを「自分の馬券収益を考えずに予想を共有してくれる聖人」と見るか「自分の本当の予想を隠しつつ偽の予想を言いふらす商人」と見るかの解釈はお任せします。 いや、そこまで斜に構えなくていいとは思いますが。
(※実際、WIN5や3連単での最低人気の組み合わせのようなものを除いて、中央競馬のオッズは個人レベルの影響力ではそこまで極端に変動しません)
と、これだけ書いて分かるとおり「安定して勝てる」と断言することはできません。
いかに勝ち筋を見極めて、勝機の薄い勝負には手を出さず、 そして偽の情報で相手を翻弄し、 勝てそうなレースでしっかりと結果を出す。それが重要だと思います。
機械学習うんぬんの話ではなく、最後は一般的な競馬予想講座のような話になってしまいました。結局、最終的に重要になるのはそういう要素だと思います。
-
コスモドリームのおかげで1988年のAEIは脅威の17.27 ↩︎
Discussion