今更だけどCLIP入門してみた

はじめに
初めまして!
株式会社ラクスパートナーズ所属、MLOpsエンジニアのニャンちゅうです。
目的
普段DSをしていないエンジニアが最新のモデルについてキャッチアップすることを目的としています。
今回はCLIPとはどういう手法か、またCLIPの手法を用いたCLIPDrawを試してみたいと思います。
要点
- DALL・E2がすごい!
- DALL・E2はCLIPとGLIDEを組み合わせた2stageモデル
- CLIPはラベル自由度が高い、膨大なデータで学習、zeroshot予測が可能なモデル
- CLipを用いたClipDrawは言語表現から抽象的な画像を作成することができる。
経緯
この記事を書くきっかけはDALL・E2です。
DALL·E2は自然言語からとてもリアルな画像を生成してくれるAIです。
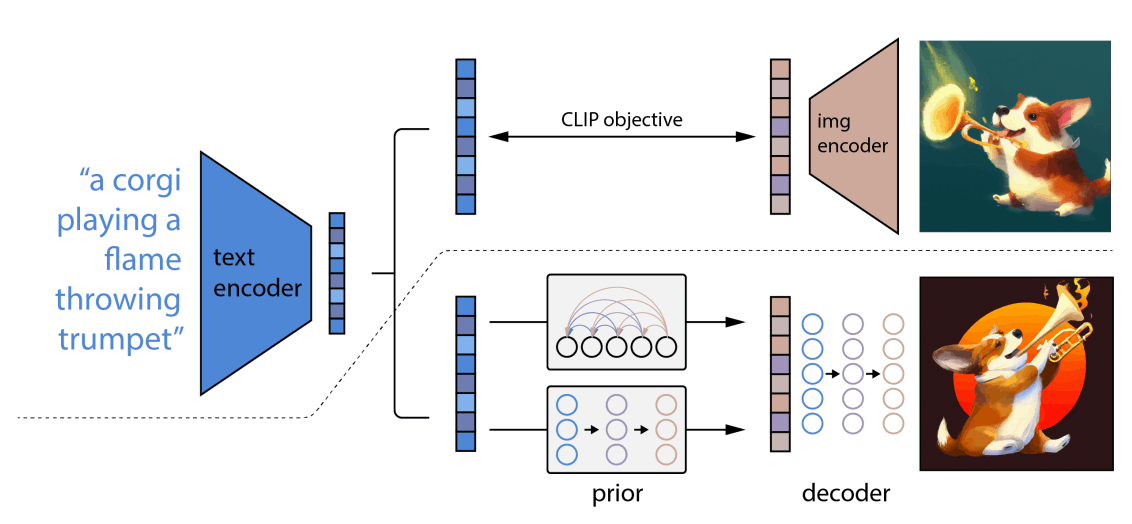
DALL・E2の構成
DALL・E2はCLIPとGLIDEを組み合わせた2stageモデルなのだそうですが、
DS分野のキャッチアップを最近疎かにしているMLOpsの私としてはCLIP?,GLIDE?状態に陥ってしまいました。
そこで、この疑問をきっかけに今回はCLIPに焦点を当てて学んでいきたいと思います。
CLIP
OpenAIが提案したテキストと画像を学習したモデルです。
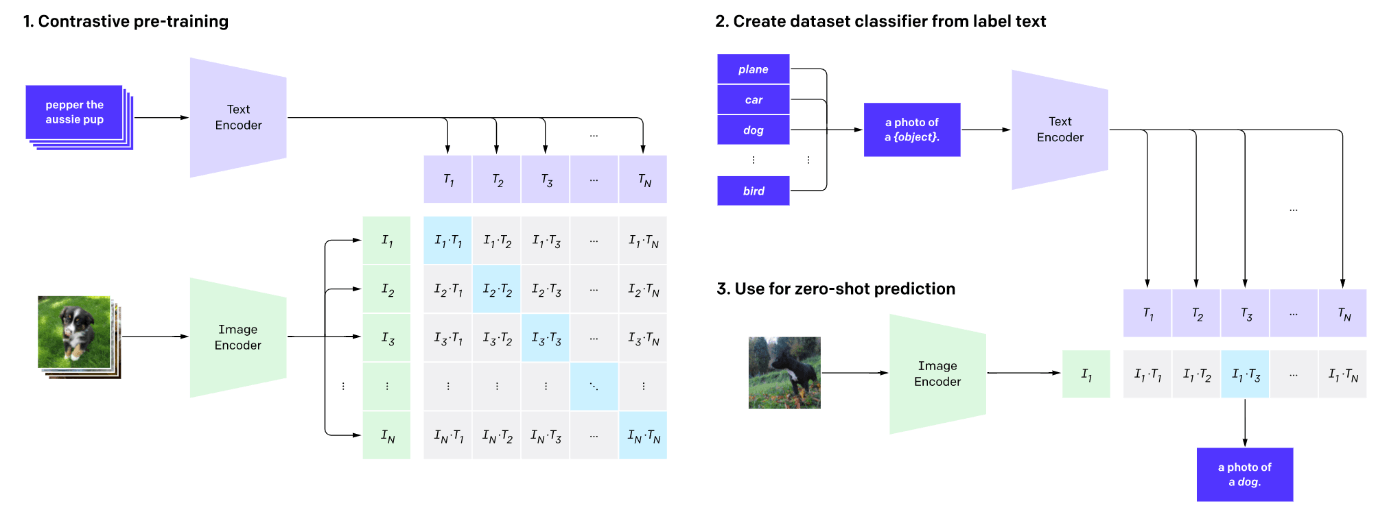
CLIPの特徴
-
ラベルの自由度が高い自然言語教師型画像分類モデル。
一般的な分類モデルは画像とラベルで学習を行うが、CLIPは画像と画像を説明するためのテキストで学習を行うため、ラベルの自由度が高い。 -
学習に使用しているデータが膨大!
ラベルの自由度が高いことによって、分類モデル学習に必要なラベル付の作業を省くことが可能となり、それによって大規模なデータを用いての学習が可能となった。タイトルもしくは説明がファイル名に反映されている画像データを集めるだけで良くなったからです。 -
見たことない画像に対しても有効
これまでの手法に比べて学習データセットに含まれていないカテゴリ画像に対しても優れた精度を誇る。
これは自然言語をラベルに用いることで言語表現同士の関連性を獲得しているからと言えます。
CLIPモデルの意義
言語表現の埋め込みに成功したことは色々な可能性を秘めている。
ex.事前にタグ付されていない画像の自然言語を用いた画像検索
公開されているモデル
OpenAI[1]のクリップモデルがgithubで公開されています。
ClipDraw
CLIPDrawは、自然言語入力に基づいてストロークベースの画像を合成する方法です。
ClipDrawができた経緯
Image Synthesis -> Drawing Synthesis
The field of text-to-image synthesis has a broad history, and recent methods have shown stunningly realistic image generation through GAN-like methods. Realism, however, is a double-edged sword – there's a lot of overhead in generating photorealistic renderings, when often all we want are simple drawings. With CLIPDraw, I took inspiration from the web game Skribbl.io, where players only have a few seconds to draw out a word for other players to guess. What if an AI could play Skribbl.io? What would it draw? Are simple shapes enough to represent increasingly complex concepts?
ブログより引用
意訳:最近のAI技術は驚くほどリアルに画像を作り出せるけど、大変な作業を要する。多くのケースではもっと簡単にシンプルな絵を望んでいる。それを体現できたら面白いじゃないか。
ClipDraw生成過程
学習済みのCLIPモデルを使用します。CLIPから得られる画像とテキストの特徴ベクトルを利用します。

CLIPDrawoの学習フロー
diffvgライブラリ
diffvg is a differentiable rasterizer for 2D vector graphics.
訳:diffvgは2次元ベクタ画像用の微分可能なラスタ形式変換器
曲線の生成と最適化に使用しています。
ClipDrawのパラメーター
prompt:str = "a drawing of cat" # 生成対象の説明
num_paths:int = 256 # ストローク数
num_iter:int = 1000# 学習エポック数
max_width:int = 10 # ストロークの太さのMAZ値
canvas_width: int = 224 # 生成対象画像の横
canvas_height: int = 224 # 生成対象画像の縦
使ってみる。

a drawing of a engineer
こちらエンジニアを書かせようとしたら工学エンジニアの方が書かれてしまいました。

a drawing of a software engineer
今度はソフトウェアエンジニア書かせてみました。
椅子に座ってコーヒーを飲みながら作業している様子を表現できていますね。

a software engineer in shibuya
渋谷で働いているエンジニアを書いてみました。
今度は髪がパーマで眼鏡をかけてMacで仕事をしている様子が描かれています。
後ろの背景は渋谷の地図でしょうか?
ニャンちゅう描けるか?
筆者のアイコンはニャンちゅうです。
なんとか言葉を選んでclipdrawを使ってニャンちゅうのアイコンが描けるのか試してみました。
設定したパラメーターは以下。
prompt:str = "a blue cat with smile"
num_paths:int = 222
num_iter:int = 1000
max_width:int = 100
canvas_width: int = 224
canvas_height: int = 224
結果はこちら!

おっ!以外に…似てなくもないかな。
ちなみに似ていると判断された割合は下記
stitch: 57.67% # スティッチ
blue: 17.32% # 青
kitty: 2.66% # キティーちゃん
cat: 1.54% # 猫
kitten: 1.29% # 子猫
学習済みモデルのclipはニャンちゅうという単語を認識しておらずニャンちゅうを書くように指示を出すとよくわからないものを書き出してしまいました。
対策としてはclipのモデルをファインチューニングしてから使用することが考えられますが、今回の記事ではここまでにします。
まとめ
CLIPがどんなモデルなのかを整理しました。
CLIPを用いたCLIPDrawを使用して実際に絵を書いてみました。
補足
次は余裕のある時にGLIDEのモデルについて書いてみたいと思います。
参考資料
DALL・E2論文はこちら
ClipDraw
DALL・E2についてはこちらの記事で詳細をまとめてくださっていますので参考ください。
CLipの解説記事
Discussion