【論文メモ】DALL·E 2
はじめに
OpenAIから2022年4月6日に発表されたDALL·E 2は、テキストを入力として複数の概念や要素を組み合わせた高精細な画像を生成することができるAIモデルです。
公式のデモをいくつか紹介します。
例えば"An astronaut riding a horse in a photorealistic style"(写実的な馬に乗る宇宙飛行士)という文章からは以下の画像が生成されます。

またテキストをもとに画像編集も行うことができ、影やテクスチャを考慮して特定の位置に要素を追加したり削除したりすることができます。以下の例では異なる位置に別のスタイルでコーギーが追加されているのが分かります。


特定の画像をベースに複数のヴァリエーションで生成することもできます。

この他にもTwitterでは著者の方がユーザーから募集したテキストを元に様々な生成例を紹介しています。
DALL·E 2はこちらのブログによるとこの夏にプロダクトとしてローンチされる予定とのことで、2022年4月現在はWaitlistが公開されています。
論文メモ
ここからはDALL·E 2の元論文であるHierarchical Text-Conditional Image Generation with CLIP Latentsについて簡単にまとめていきます。
DALL·E 2は要素技術としてはText-ImageのマルチモーダルモデルCLIPとdiffusion modelの生成モデルGLIDEが使われています。(どちらもOpenAIから提案されています)
まずはCLIPとGLIDEについて簡単に紹介します。
CLIP
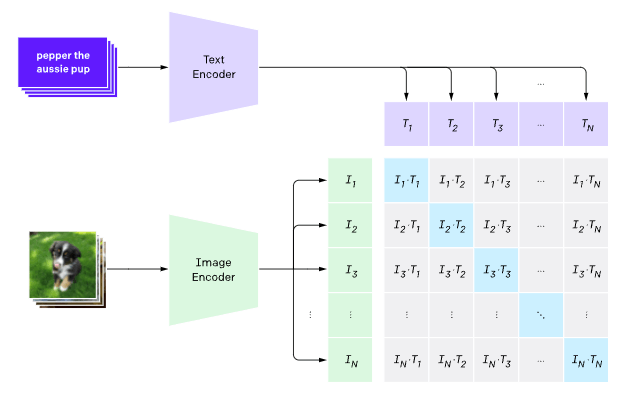
CLIPは4億のテキスト画像ペアをContrastive Learningで学習させたマルチモーダルモデルです。テキストとそれに対応する画像(例:「芝生にいる犬」と実際の犬の画像)を近づけるよう学習させることで、テキストと画像に関するリッチな埋め込み表現を得ることができます。大量のペアで事前学習を行うことで様々なタスクに応用可能なモデルとなっていて、例えば画像とテキストの類似度を測ることで追加の学習が不要なZero-Shot分類を行うことができます。
DALL·E 2においても事前学習によるリッチな埋め込み表現が活用されています。
GLIDE

GLIDEはdiffusion modelベースのText-to-Image生成モデルです。
Diffusion modelは生成モデルの一種で、マルコフ過程により各ステップごとに画像データにノイズを加えていき、ノイズから実データを復元するようにモデルを学習させます。詳しくはこちらのブログやこちらの動画を御覧ください。
アーキテクチャとしてはDiffusion Models Beat GANs on Image Synthesisで提案されたTransformerがベースとなっており、64pxの画像を超解像と組み合わせることで最終的に256pxでの生成を行っています。GANモデルと比較して多様な画像を生成できることがメリットな一方で、クエリが複雑になるとうまく生成できないという問題がありました。
参考までに筆者が日本語データで再現実装を行った生成例を載せておきます。
元論文の35億パラメータよりも小さなモデルではありますがそこそこいい感じの生成結果が得られています。

DALL·E 2
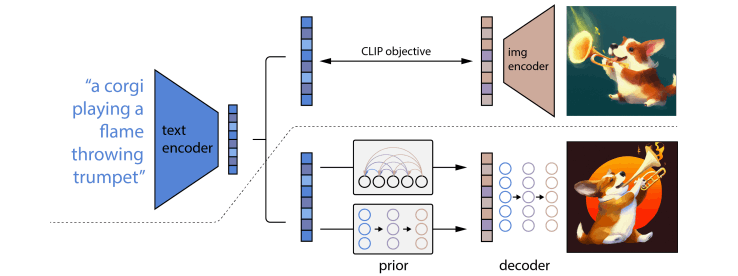
DALL·E 2はCLIPとGLIDEを組み合わせた2stageモデルで論文内ではunCLIPと呼ばれています。(以下unCLIPと呼称)
unCLIPは
- テキストからCLIPの画像埋め込みを得るprior
- CLIPの画像埋め込みとテキストから画像を生成するdecoder
の2つの要素からなります。上の図では上側がCLIPの学習プロセスを表し、下側がunCLIPの学習プロセスを表しています。
モデル
Decoder
埋め込み表現から画像を生成するDecoderは、35億パラメータGLIDEのテキスト埋め込みにCLIPの埋め込み表現を追加したモデルで、classifier-free guidanceというランダムに埋め込み表現をdropさせるテクニックを用いています。(GLIDEでも使われています)
また高解像度の画像を生成するために64px→256pxと256px→1024pxの2つのdiffusion upsampler modelが使われています。(GLIDEでは64px→256pxのみでした)
Prior
テキストから画像埋め込み表現を生成するPriorとしてはAutoregressive(AR) PriorとDiffusion Priorの2つが検討されており、Diffusion Priorの方が軽量で高品質な生成が可能であると述べられています。
Diffusion Priorはcausal attention maskを適用したDecoder-only Transformerが使われていて、テキスト/CLIPのテキスト埋め込み/diffusion timestepの埋め込み/ノイズが付与されたCLIPの画像埋め込みからノイズのないCLIPの画像埋め込みを予測します。
人手による評価
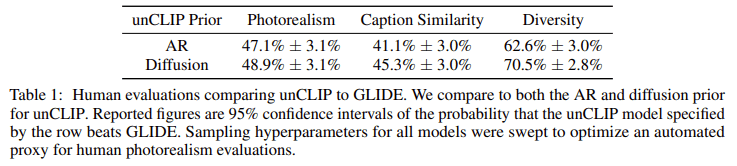
人手による評価で写実性・テキストとの適合度・多様性という観点でGLIDEとunCLIPを比較した結果です。写実性と適合度ではGLIDEに多少負けているものの多様性が大きく改善していることが分かります。
MS-COCOでの評価
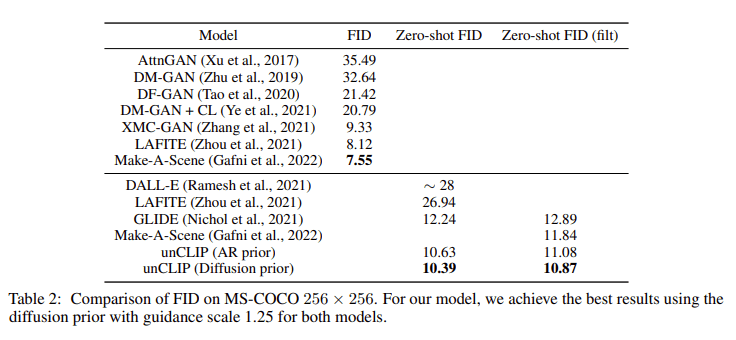
MS-COCOでの既存モデルとの比較では、unCLIPはCOCOで学習していないにも関わらずSOTAの性能を示しています。

審美性の評価
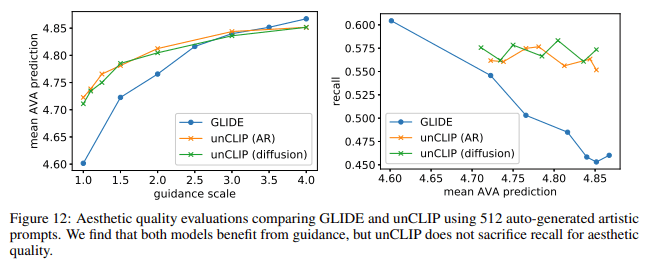
審美性評価の準備として、まずGPT-3で512個の"artistic"なキャプションを生成します。次に審美性を評価するAVA Datasetを用いて審美性スコア予測モデルを作成します。
これらを元にartisticなキャプションから画像を生成しそれらのスコアを予測して評価を行います。GLIDEに比べunCLIPはRecallを保ったまま審美性を高めることができています。
Limitations
unCLIPは多様性を改善した一方でいくつかの課題があります。

一つ目は要素や関係の紐づけがGLIDEに比べて弱いことです。上図の例では「青いキューブの上の赤いキューブ」というテキストに対して、unCLIPの生成例は色や位置関係がうまく反映されていません。(筆者注:こちらのCLIPを活用した論文では位置関係や物体の詳細についてはCLIP-ViTよりもCLIP-ResNetの方がよいという議論がありImage Encoderの観点で改善できるかもしれません)

二つ目は一貫した文字の生成ができないことです。上図の例では「Deep learningと書かれた看板」というテキストにたいして正しく文字が生成されていません。(筆者注:こちらのDiffusion Modelでは比較的上手く文字が生成出来ているため改善余地がありそうです)

三つ目は複雑なシーンの詳細を上手く生成できないことです。上図の例では「タイムズスクウェアの高品質な写真」というテキストに対して詳細な部分の生成に課題があり、これは64pxという低解像度からUpsampleを行っているためとしています。
感想
個人的にマルチモーダルな生成周りを追っていた中でこのクオリティが出るのはあと数年かかると思っていたので大変驚きました。Diffusionモデルは生成に時間がかかるなどの技術的な課題は残っている一方でそれらを改善する研究も現れていて(例1, 例2)、AIによる画像生成の実応用が近づいていると感じます。例えば論文中でも使われていたGPT-3によるテキスト生成→画像生成の仕組みで今後は人間が思いつかないようなユニークな画像が大量に作られるようになるかもしれません。AIによるクリエイティブの未来に期待しながら引き続き研究を追っていきたいと思います。
Discussion