はじめに
本日、Snowflake Intelligence がついに GAとなりました。
これを記念して、改めてこの新機能の魅力を皆さんにご紹介したいと思います。
Snowflake Intelligenceはプレビュー期間中からすでに多くの注目を集めており、ブログ記事やお客様からのお問い合わせを通じて、その関心と期待の大きさを強く感じています。
私自身もこれまでに、Snowflakeの新機能をいくつか検証してきましたが、その中でも印象に残っているのがCortex Agentsの検証です。Cortex AnalystやSearchをAgentsのREST API経由で呼び出すことで、より精度の高い分析ができることを体感しました。
あれから月日が経ち、Cortex Agents自体も進化を遂げています。
そして何より、より簡単にCortex Agentsを活用するためには、Snowflake Intelligence(Agents をラップするUI層)の存在が欠かせないと感じています。
そこで今回は、Snowflake Intelligenceを用いたユースケースを実際に検証することで、その魅力とポテンシャルをお伝えしていこうと思います。
1. Snowflake Intelligenceとは
Snowflake Intelligence が登場した当初、
Cortex Agents と何が違うの?」
と混乱した方も多いのではないでしょうか。私もその一人でした。
そんな中で、以下の図を見たときに「あ、なるほど」と腑に落ちた記憶があります。
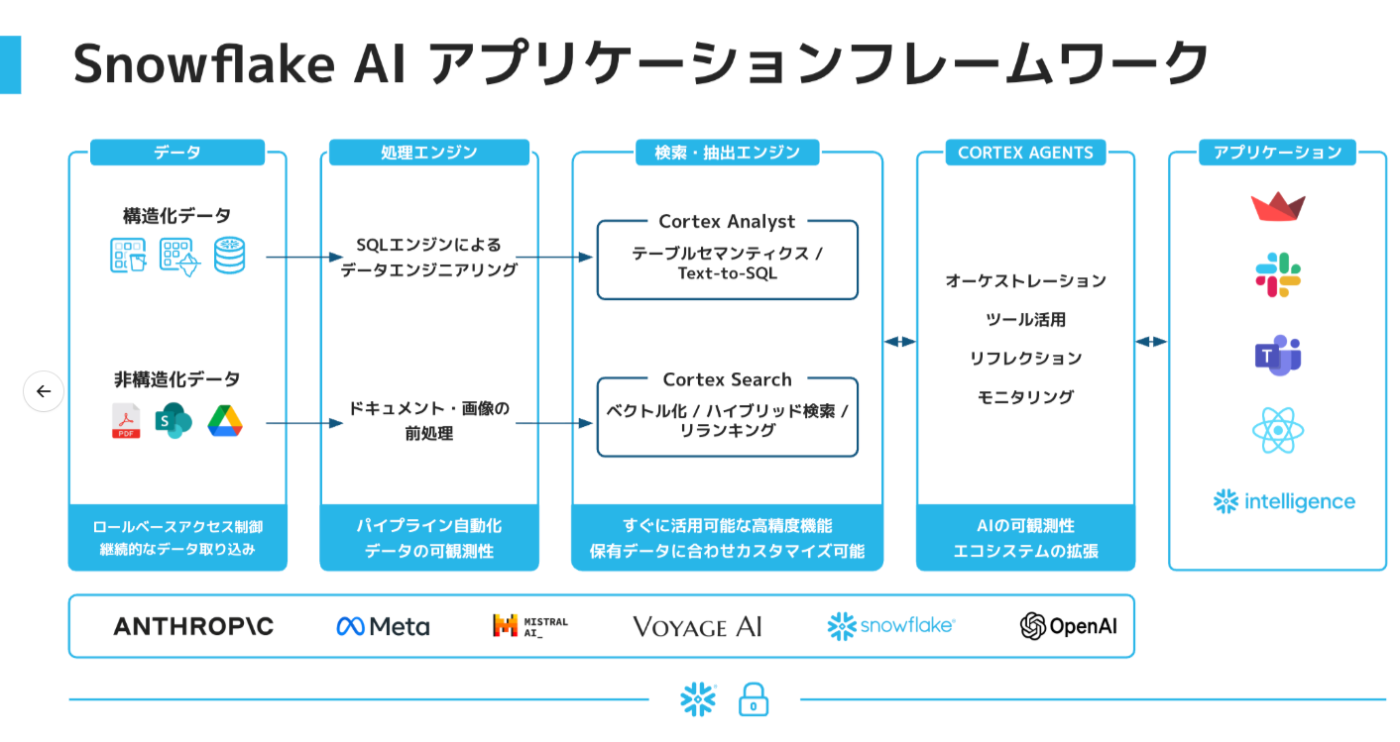
画像引用:Snowflake World Tour Tokyo 2025 - BS - 104 Cortex AIとデータエージェントによる正確な対話型アプリケーションの展開
図の右端にある枠を見ると、Snowflake Intelligence は 「UI層」 に位置づけられています。
つまり、ユーザーが質問を入力するのはこのレイヤです。
この図をもとに、やり取りの流れをステップで整理すると以下のようになります。
- ユーザーが質問を入力
Streamlit や Slack といった UI 層(=Snowflake Intelligence)で質問を受け付けます。 - Intelligence → Agents へのリクエスト送信
Intelligence は質問を Cortex Agents に渡します。 - Agents がツールを選択して処理
Agents は質問内容に応じて、利用可能なツール(例:Cortex Analyst、Cortex Search、Custom Tool)を選び、実行計画を立てて回答を生成します。 - 結果を Intelligence(UI層) に返す
生成された回答が Intelligence に戻され、ユーザーに結果が表示されます。
このように整理すると、
- Intelligence = ユーザーの窓口(UI)
- Agents = 実際に動く頭脳(ロジック層)
という関係で捉えるとわかりやすいです。
2. 検証シナリオ
Snowflakeを使っていると、組織全体のコスト(Consumption)を分析したい場面ってよくありますよね。特に大規模な環境では、複数アカウントにまたがる利用状況を追うのが意外と手間だったりします。
例えば、社内で開発・検証・本番の各環境を別アカウントで運用していたり、
グループ会社や事業部単位で Snowflake アカウントを持っているようなケースです。
そんなときに気になるのが、こんな疑問ではないでしょうか。
「10月のクレジット消費量が多いアカウントTop5は?」
「SERVICE_TYPE ごとの利用量の推移はどのくらいか?」
これらを確認するには、通常 SNOWFLAKE.ORGANIZATION_USAGEの各種ビューを使ってSQLを実行します。ただ、毎回SQLを書いて集計するのは、正直かなり面倒ですし、一定のSQLのスキルも必要になります。
そこで今回は、Snowflake Intelligence にこのコスト分析を任せてみることにしました。
Intelligenceに対して自然言語で質問を投げると、自動的にORGANIZATION_USAGEを参照して結果を返してくれるような仕組みを目指します。
もう一つ試してみたのが、Cortex Searchを活用したSnowflakeのドキュメント検索です。
たとえば、Intelligenceで
「Auto Clustering のコストが増えている」
とわかったときに、すぐそのままこう聞けたら便利ですよね。
「Auto Clustering の課金体系を教えて」
こうした原因分析をSnowflakeのドキュメントを参照しながら行う──そんな構成を検証してみました。
3. 環境準備
まずは必要な設定を実施します。
Snowflake Intelligenceに必要な設定
-- Snowflake Intelligence関連オブジェクトを格納するDBを作成
CREATE DATABASE IF NOT EXISTS snowflake_intelligence;
GRANT USAGE ON DATABASE snowflake_intelligence TO ROLE PUBLIC;
-- エージェントを格納するスキーマを作成
CREATE SCHEMA IF NOT EXISTS snowflake_intelligence.agents;
GRANT USAGE ON SCHEMA snowflake_intelligence.agents TO ROLE PUBLIC;
Cortex Agentsで使用するツールの準備
今回は、Cortex Agents内で以下の2つのツールを利用します。
- Cortex Analyst — コスト分析用(ORGANIZATION_USAGE.METERING_DAILY_HISTORY を参照)
- Cortex Search — Cortex Knowledge Extensionsで取得したSnowflakeドキュメントをRAG検索する
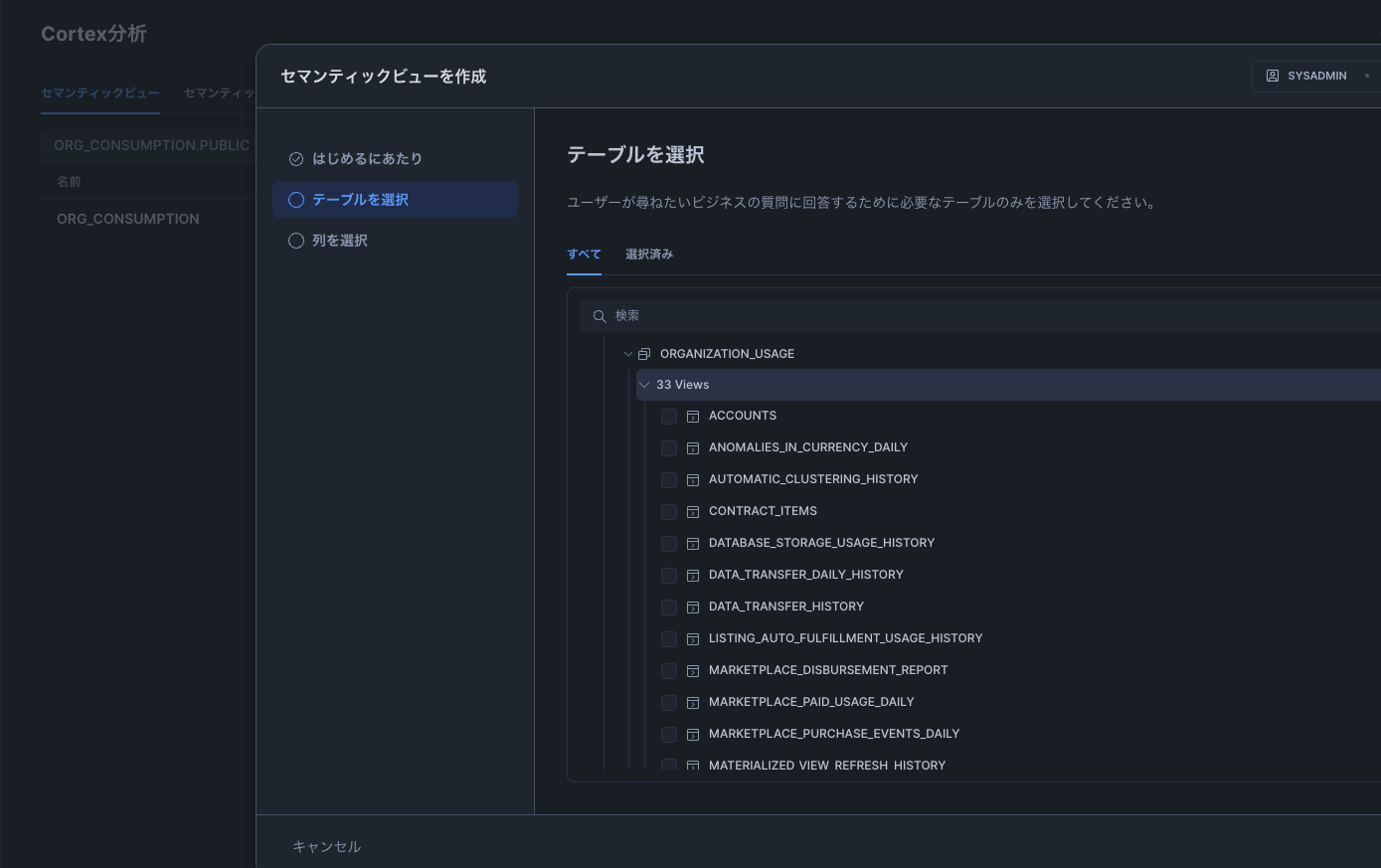
- Cortex Analystの設定
まず、Cortex Analyst で参照するセマンティックビューを作成します。
対象は ORGANIZATION_USAGE.METERING_DAILY_HISTORY の全カラムです。
- Cortex Searchの設定
Knowledge Extensionsを活用したCortex Searchの設定手順については、以下の記事が参考になります👇
Snowflake公式ドキュメントのExtensionsを取得しIntelligenceから問い合わせをしてみた
ここでSNOWFLAKE_DOCUMENTATION.SHAREDスキーマを選択し、Snowflake Documentationを検索対象に指定します。
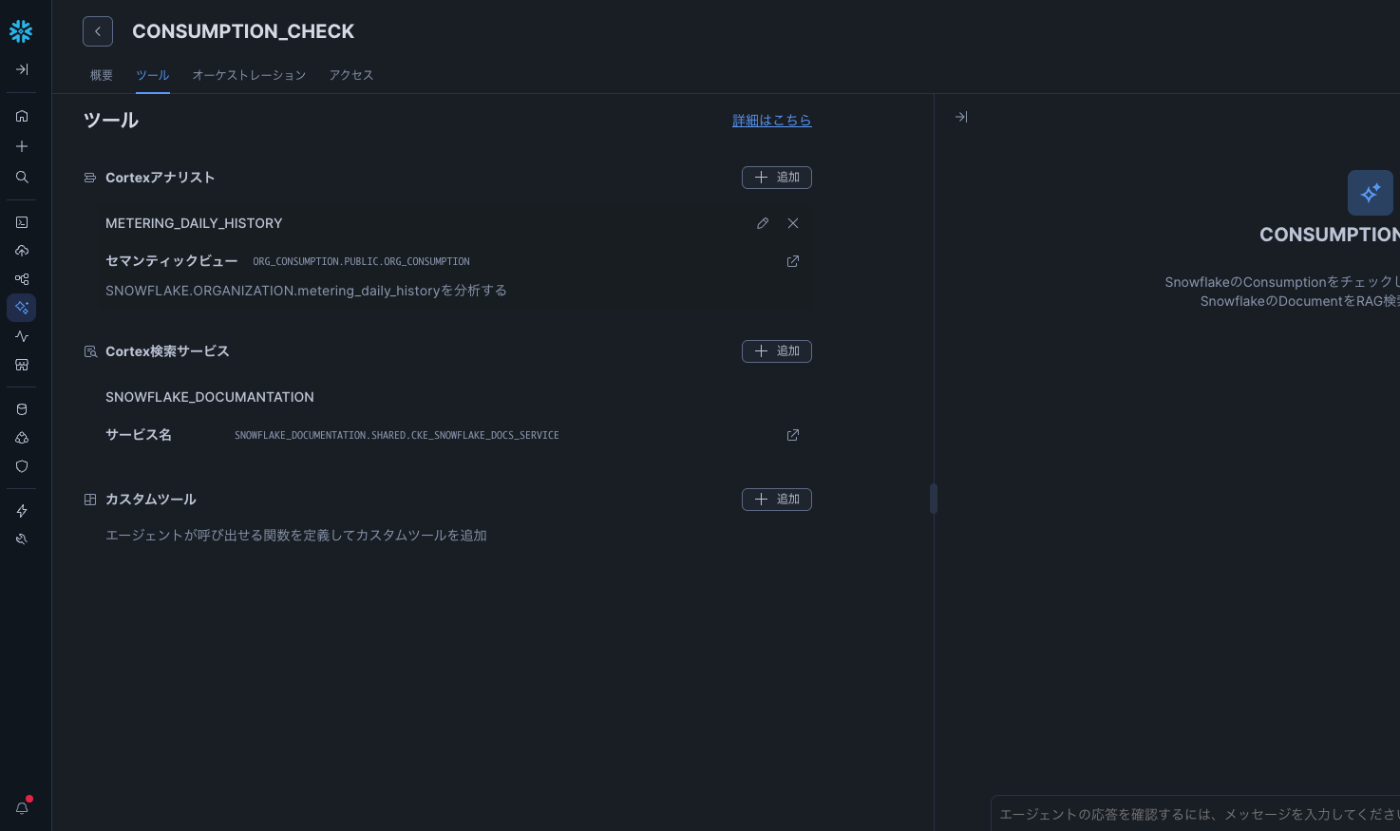
Cortex Agentsへのツール登録
ツールの準備ができたら、Cortex Agents に登録していきます。
以下のように、先ほど作成した Cortex Analyst と Cortex Search(Knowledge Extensions) をツールとして設定します。
Cortex Agentsの設定タブについて
Cortex Agents の設定画面では、以下の 4つのタブ が用意されています。
それぞれの役割と設定内容を整理してみましょう。

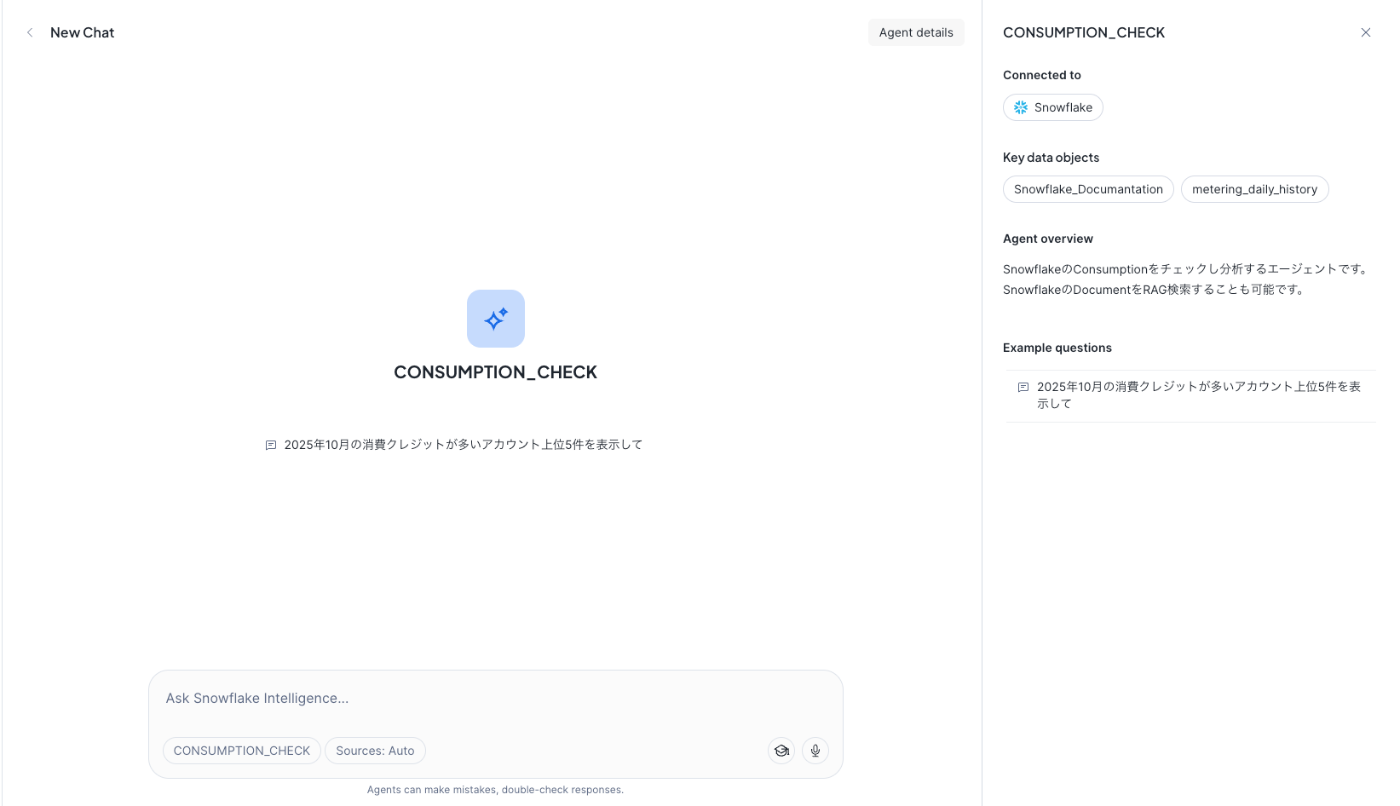
- 概要タブ
このタブでは、エージェントの説明や質問例を設定します。
Intelligenceから利用するユーザーに「どんなエージェントなのか」を伝えるための情報です。
たとえば、以下のように設定します👇- Agent overview:エージェントの用途や目的を記載
- Example questions:ユーザーが投げる想定質問をサンプル表示
こうして設定した概要や質問例は、以下の画像のようにIntelligence上に表示されます。
-
ツールタブ
ここでは、エージェントが利用できるツールを設定します。

-
オーケストレーション
このタブでは、タスクの計画・応答方法をカスタマイズできます。特に設定しない場合はモデルが自動選択されますが、ドロップダウンから手動でモデルを指定することも可能です。

最新のClaude4.5 シリーズやGPT5なども選択できるようになっています。
また、以下の2項目を使ってエージェントの動作をより柔軟に制御できます。項目 役割 例 Orchestration instructions タスク計画の方針を指定 「まずツールAを優先的に使用し、該当しなければツールBを使う」など Response instructions 応答の形式やトーンを定義 「表形式で回答する」「技術者向けの文体で返す」など -
アクセス
最後に、エージェントへアクセスできるロールを設定します。
これにより、特定のユーザーグループにのみ利用を許可することが可能です。
設定が完了したので、次章ではシナリオに沿って実際の検証を進めていきます。
4. 検証
それでは、Snowflake Intelligenceを使って実際に分析していきます
1-1. 「10月のクレジット消費量が多いアカウント Top5 は?」
まずはシンプルに、10月のクレジット消費量が多いアカウントを確認してみます。
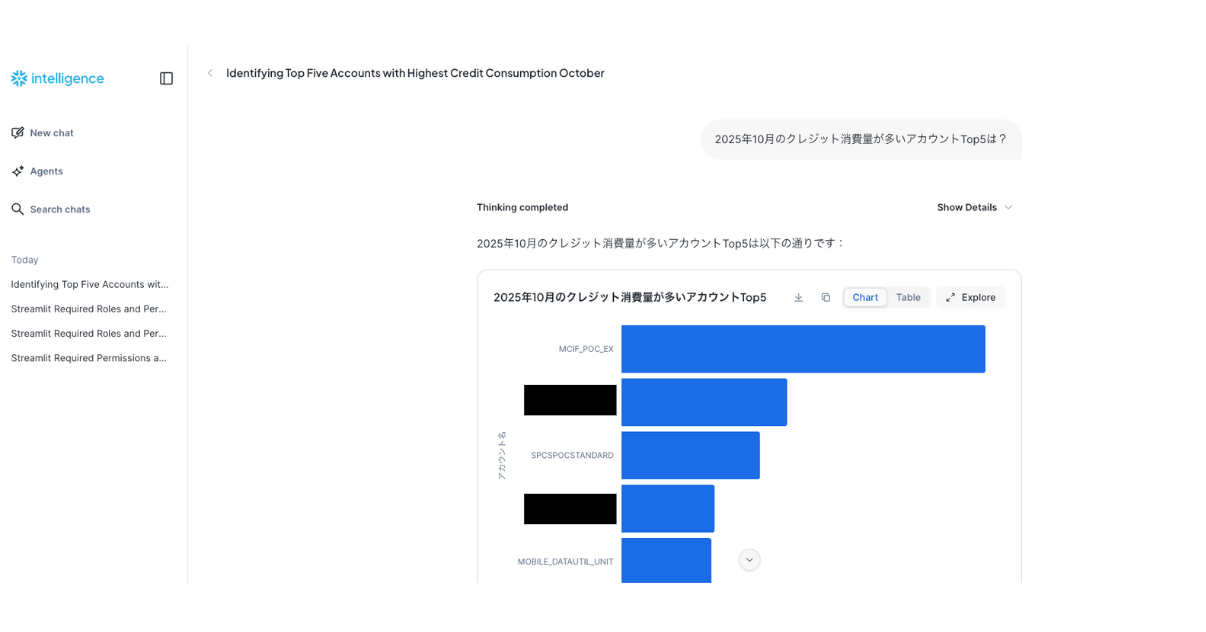
手元で確認した結果とも一致しており、正しく集計できました。
1-2. 「10月の利用クレジットが一番多かったアカウント」について詳細分析
次に、1-1で最もクレジットを消費していたアカウントについて、SERVICE_TYPE 別の利用クレジットをまとめてみます。
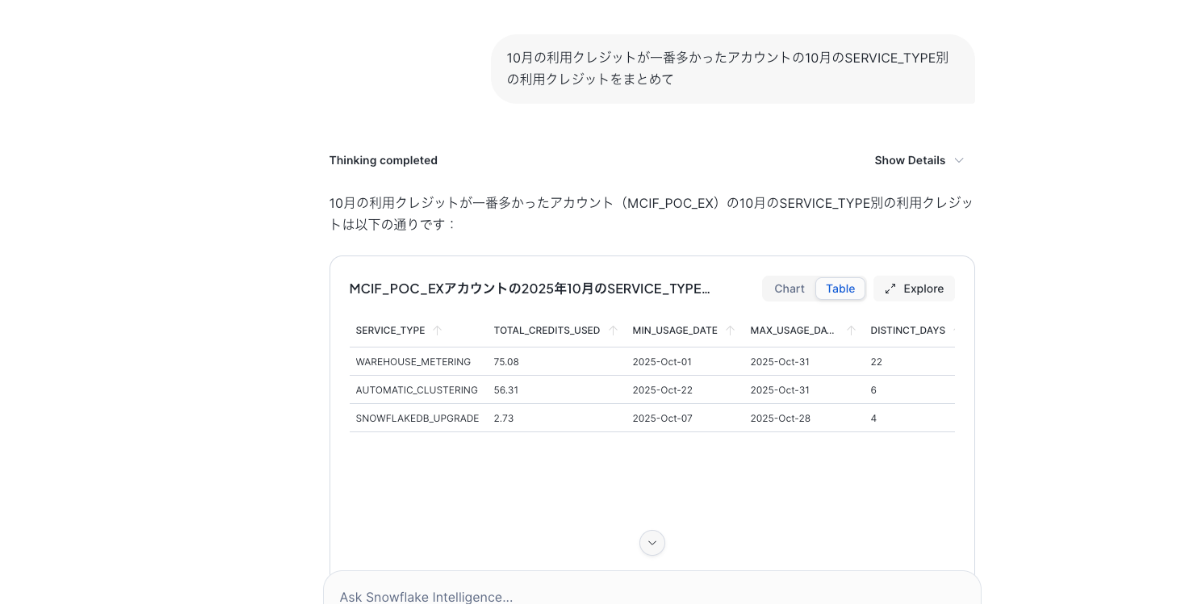
結果を見ても、分類・集計ともに妥当な内容であることが確認できました。
2-1. 「SERVICE_TYPEごとの利用推移(2025年4月〜10月)」
次に、期間を広げて SERVICE_TYPE ごとの利用量の推移 を確認してみます。
- 集計対象は2025年4月~10月
- SERVICE_TYPEごとの利用料金の推移を出してほしい
- 列に月を(4,5,6,7)、行にSERVICE_TYPEという形で集計して

月別に利用傾向を可視化できており、直感的に増減がつかめます。
2-2. 「SERVICE_TYPEごとの月次増減率」
次に、各SERVICE_TYPEの月ごとの増減率を計算してみます。
- 集計対象は2025年4月~10月
- SERVICE_TYPEごとの増減率を出す。4月のクレジットを1として、以降の月をこの基準月に対してどれくらいの割合増減があったか。を計算する
- 列に月を(4,5,6,7)、行にSERVICE_TYPEという形で集計して

この結果を見ると、TRUST_CENTERの増加率が高いことがわかります。
2-3. 「Trust Centerのコスト体系を調べる」
最後に、コストが増加傾向にある Trust Center について、
そのコスト体系と原因をIntelligenceに尋ねてみます。

Intelligenceが、Snowflake DocumentationをRAG検索し、Trust Centerのコスト体系とコスト増加の原因を推測し自然言語で回答してくれました。
わざわざブラウザを開いてドキュメントを探さなくても、
Intelligence 上で直接ドキュメント情報と推測原因を得られるので非常に便利なAgentになっているなという感想です。
5. まとめ
今回の検証を通じて、Snowflake Intelligenceのポテンシャルを強く実感しました。
特に印象的だったのは、分析と調査がシームレスにつながる体験です。これまで ORGANIZATION_USAGE の分析は SQL を書いて行うのが一般的でしたが、Intelligence では自然言語で質問するだけで、Cortex Analyst が自動的に SQL を生成し、即座に結果を返してくれます。
さらに Cortex Search(Knowledge Extensions) を組み合わせることで、分析結果の背景をそのまま Snowflake Documentation から参照することができました。これまでエンジニア頼みだった分析や調査の工程が、ビジネスユーザー自身の言葉で完結できる──そんな新しい可能性を感じました。
また、ユーザーのフィードバックを受け取る仕組み(👍/👎ボタン)が標準で備わっており、AI_OBSERVABILITY_EVENTS テーブルを通じてその内容を集計・分析できる点も見逃せません。ユーザーの反応を反映しながらエージェントを継続的に改善できるため、「作って終わり」ではなく、共に育てていく仕組みとして設計されている点は大きな魅力です。ユーザーからのフィードバックを積極的に取り入れる文化の醸成も、今後の運用において鍵となるでしょう。
加えて、生成された回答に対して「なぜその答えに至ったのか?」を可視化できる「Show details」の存在も非常に重要です。どのツールを選び、どのような手順で思考が進んだのかが視覚的に確認できるため、生成AIに対する信頼性を高める手助けとなります。
欲を言えば、複数の Agents をまたいだ連携(例:分析結果 → ドキュメント検索)ができるようになると、さらに使いやすくなると感じます。今回のケースでいえば、Snowflake Documentationは汎用性の高いToolとなるため、毎回個別のAgentに組み込むのではなく、独立した Agentとして共通利用できる構成が理想的かもしれません。
ほとんどの設定が GUI ベースで完結しますので、ぜひ皆さんも一度触ってみて、この自然言語でデータと対話する体験を実感してみてください。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。