はじめに
最近、Techイベントやブログで「AIエージェント」という言葉を耳にする機会が増えています。
Snowflakeもこの流れに乗り、Cortex Agents(現在プレビュー機能) をリリースしています。
今回は、このCortex Agentsが現時点でどこまで賢く動けるのか、いくつかの質問シナリオを通じて検証してみたいと思います。
※本記事の内容は2025年8月4日時点のプレビュー版に基づく検証結果です。
注記
Cortex Agentsは現在プレビュー機能として提供されています。
プレビュー機能はSnowflakeに実装およびテストされていますが、完全なユーザビリティや特殊ケースへの対応は完了していない可能性があります。そのため、今後のバージョンで動作や仕様が変更される場合があります。
1.Cortex Agentsとは
Cortex Agentsは、Snowflakeが提供するAIエージェント機能で、構造化データ(テーブル)と非構造化データ(ドキュメントやチャットログなど)を横断的に扱えるのが特長です。
大規模言語モデル(LLM)を活用し、ユーザーの質問を理解して最適なツールを選択・実行し、回答を導きます。
まずは、Snowflake公式ブログに掲載されている図を見ながら、その全体像を整理してみましょう。
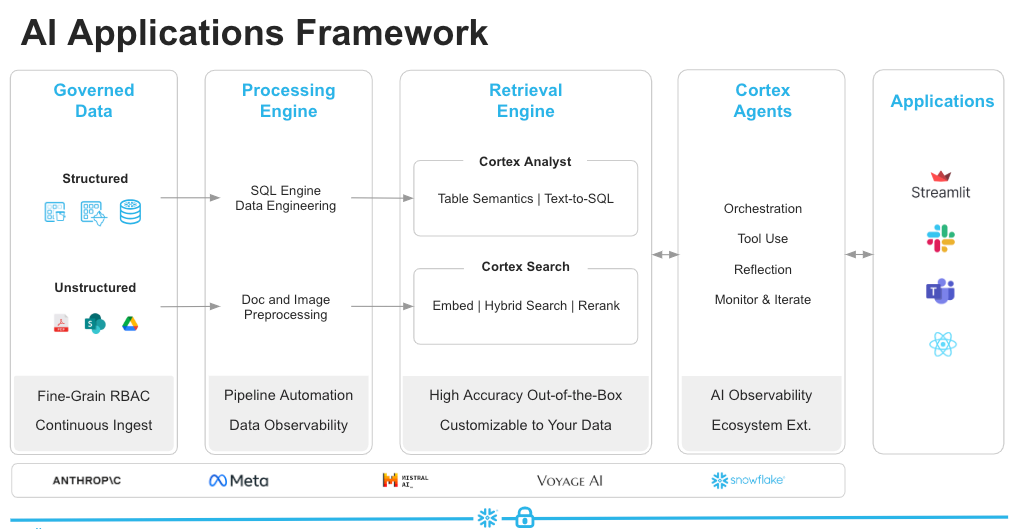
👉 公式ブログはこちら:エンタープライズデータに必要なのはエージェント
この図から読み取れるCortex Agentsの基本的なワークフローは、次のとおりです。
- 呼び出し:アプリケーションからREST API経由でCortex Agentsを呼び出す
- 計画:質問内容を理解し、「構造化か/非構造化か」を判断。必要に応じてタスクを分割
- ツール選択と実行:計画に基づき以下のツールを使い分け処理を実行
- Cortex Analyst:SQLを自動生成し構造化データをクエリ
- Cortex Search:PDFやチャットログなどの非構造データをベクトル検索
- 反映:得られた結果を評価し、必要であれば追質問や要約を行い最終回答を生成
このように、単なる「ツール呼び出し」ではなく、質問に応じて複数のステップを踏みながら動作するのが、Cortex Agentsの大きな特長です。
今回の記事では、このCortex Agentsがどこまで複雑な問い合わせに対応できるのか、実際のシナリオを通して検証していきます。
2.環境準備
今回の検証のために、以下4つのテーブルを準備しました。
| テーブル名 | 主なカラム例 | 用途(どのツールで使用するか) | データタイプ |
|---|---|---|---|
product_orders |
order_id, product_id,user_id,price, order_date | Cortex Analyst:売上集計など | 構造化データ |
customer_profiles |
age, region, gender | Cortex Analyst:属性条件に使用 | 構造化データ |
support_chat_logs |
user_id,message, timestamp | Cortex Search:顧客とのやり取り履歴 | 非構造化データ |
faq_articles |
question, answer | Cortex Search:ナレッジ検索 | 非構造化データ |
問い合わせインターフェースはStreamlitを使い、Cortex Agentsと連携する構成です。
Streamlit内でCortex Agentsに渡すRequest Bodyは以下のとおりです。
payload = {
"model": "claude-4-sonnet",
"response_instruction": "",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": query}
]
}
],
"tools": [
{"tool_spec": {"type": "cortex_analyst_text_to_sql", "name": "analyst1"}},
{"tool_spec": {"type": "cortex_analyst_text_to_sql", "name": "analyst2"}},
{"tool_spec": {"type": "cortex_search", "name": "search_chat"}},
{"tool_spec": {"type": "cortex_search", "name": "search_faq"}}
],
"tool_resources": {
"analyst1": {"semantic_model_file": CUSTOMER_PROFILES_SEMANTIC_MODELS},
"analyst2": {"semantic_model_file": PRODUCT_ORDERS_SEMANTIC_MODELS},
"search_chat": {
"name": CHAT_SEARCH_SERVICE,
"max_results": limit,
"id_column": "conversation_id"
},
"search_faq": {
"name": FAQ_SEARCH_SERVICE,
"max_results": limit,
"id_column": "faq_id"
}
},
"tool_choice": {"type": "auto"}
}
3.検証シナリオ
Cortex Agentsの出力精度やツール選択の挙動を確認するため、以下3つのシナリオを用意しました。
| 難易度 | 実行するクエリ | 期待されるツール選択 | 評価ポイント |
|---|---|---|---|
| Lv.1 単一ツール - 基礎 | ①「user_0の性別を教えて」 ②「返品手続きの方法を教えて」 |
1️⃣ Cortex Analyst(customer_profiles) 2️⃣ Cortex Search(faq_articles) |
ツール選択の正確性、生成SQLや検索結果の精度 |
| Lv.2 テーブルまたぎ(構造/非構造) | ①「user_0の性別と購入商品を教えて」 ②「パスワードを忘れた場合はどうすればいいですか?」 |
1️⃣ Cortex Analyst(product_orders, customer_profiles) 2️⃣ Cortex Search(search_chat, faq_articles) |
複数テーブルを統合した出力の可否 |
| Lv.3 複合ツール(構造+非構造) | 「product_0 を購入したユーザーと、そのユーザーの問い合わせ内容を一覧にしてください」 | 1️⃣ Cortex Analyst(product_orders)でproduct_0の購入ユーザを特定 2️⃣ Cortex Search(support_chat_logs)で購入ユーザの問い合わせを検索 3️⃣ LLMで要約 |
構造データ検索→非構造データ検索→要約の一連処理 |
それでは検証に入っていきましょう!
検証_Lv.1 単一ツール
💬 クエリ
- ①「user_0の性別を教えて」
- ②「返品手続きの方法を教えて」
✅ 結果
- ①
Cortex Analystが選択され、user_0の性別を回答できています。
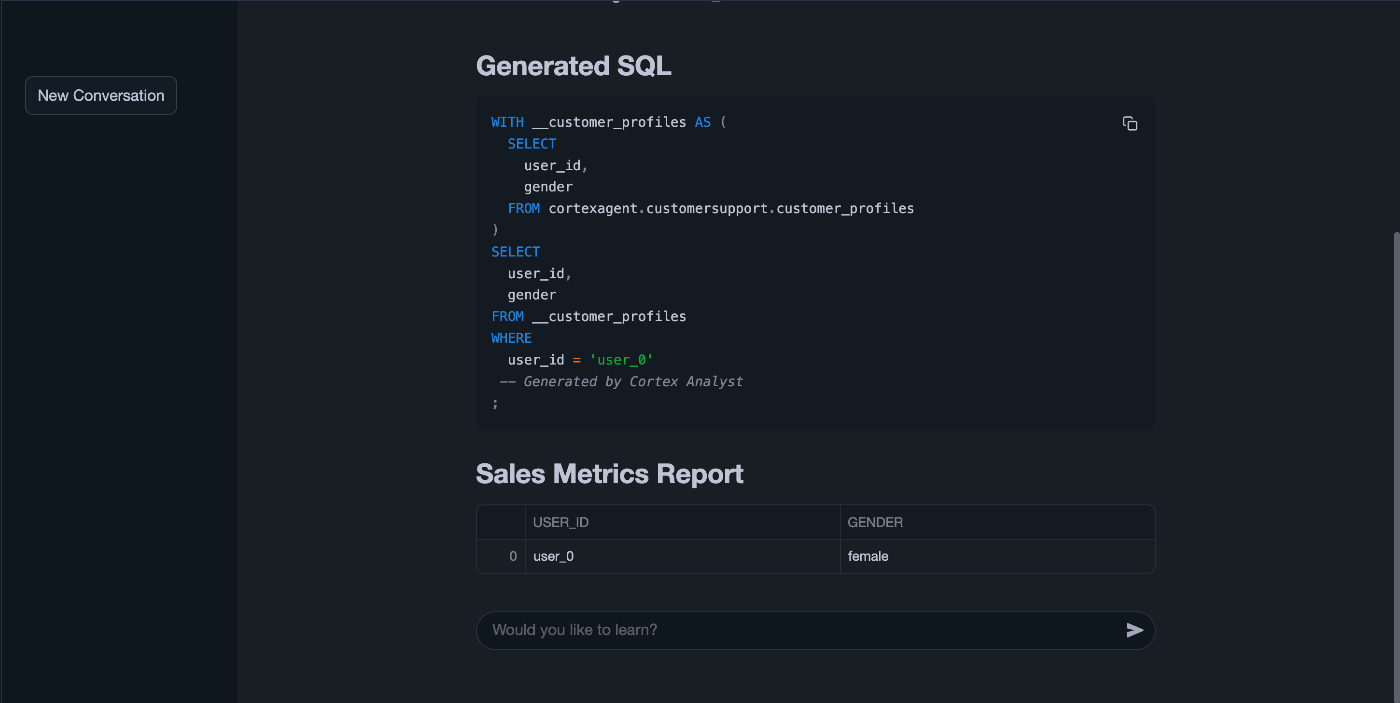
以下はレスポンスの一部で、定義したcortex_analyst_text_to_sql(analyst1)のToolが呼び出されていることが分かります。
{
"event": "message.delta",
"data": {
"delta": {
"content": [
{
"type": "tool_use",
"tool_use": {
"name": "analyst1",
"type": "cortex_analyst_text_to_sql",
"input": {
"query": "user_0の性別を教えて"
// 以下省略
}
}
},
// 以下省略(cortex_analyst_text_to_sql の結果(生成SQL・解釈内容など))
}
- ② Cortex Search を選択し、返品に関する FAQ が回答に引用されました。

以下はレスポンスの一部で、定義したsearch_chatなどのCortex SearchのToolが呼び出されていることが分かります。
{
"event": "message.delta",
"data": {
"delta": {
"content": [
{
"type": "tool_use",
"tool_use": {
"name": "cortex_search",
"type": "cortex_search",
"input": {
"query": "返品手続きの方法を教えて",
"indexName": "search_chat"
// 以下省略
}
}
},
{
"type": "tool_use",
"tool_use": {
"name": "cortex_search",
"type": "cortex_search",
"input": {
"query": "返品手続きの方法を教えて",
"indexName": "search_faq"
// 以下省略
}
}
},
{
"type": "tool_use",
"tool_use": {
"name": "cortex_search",
"type": "cortex_search",
"input": {
"query": "返品手続きの方法を教えて",
"indexName": "product_feedback"
// 以下省略
}
}
},
{
"type": "tool_results",
"tool_results": {
・・・省略
}
}
]
}
}
}
🧐 考察
- 質問内容に応じて構造化データ/非構造化データに最適なツールが選択されており、基本的なツール選択精度は高いと言えます。
- 特に非構造データの検索では、返品に関する質問に対して以下の3つの検索ツールを順に実行し、結果を統合して回答を生成していると考えられます。
- search_chat(チャットログ)
- search_faq(FAQ)
- product_feedback(レビュー・声)
検証_Lv.2 ツールはテーブルを跨げるか(構造-構造,非構造-非構造)
💬 クエリ例(構造化データのテーブルを跨いだ質問)
- 「user0の性別と購入商品を教えて」
※ user_0 の性別は customer_profiles、購入商品は product_orders に格納されている
✅ 結果
回答できない。
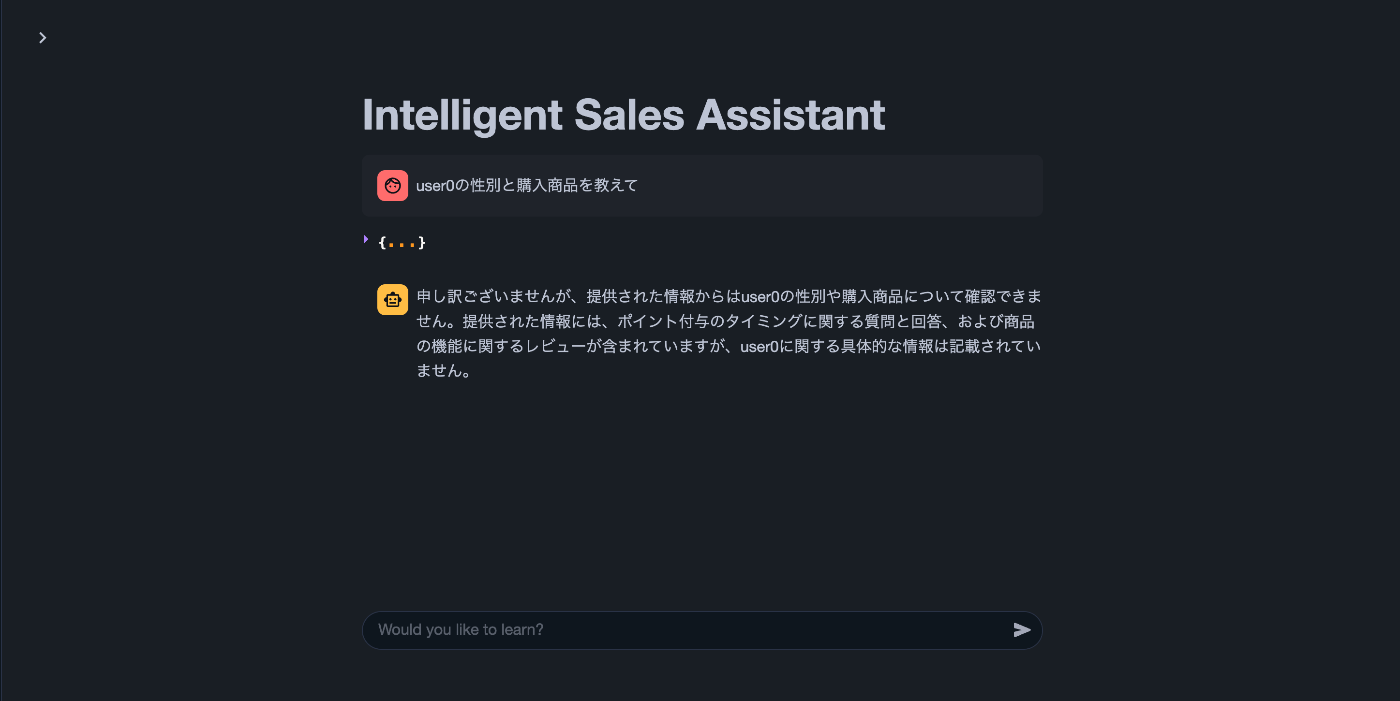
実際のレスポンスを確認すると、構造化データへの問い合わせであるにもかかわらず、Cortex Analystではなくcortex_search が選択されていました。
{
"status": 200,
"content": [
{
"event": "message.delta",
"data": {
"id": "msg_001",
"object": "message.delta",
"delta": {
"content": [
{
"index": 0,
"type": "tool_use",
"tool_use": {
"tool_use_id": "tooluse_c264753fbbc847b0a79bee",
"name": "cortex_search",
"type": "cortex_search",
"input": {
"columns": ["conversation_id"],
・・・・
対応1:指示プロンプトを変更
"response_instruction": """
ユーザー属性に関する質問は必ずanalyst1を使用し、
購入履歴に関する質問は必ずanalyst2を使用してください。
FAQ/チャット検索ではなく、まずSQLを用いた構造化データの取得を行い、
その結果をまとめて返答してください。
また、回答する際は、語尾に!をつけてください
"""
回答文の語尾に「!」が付いていたため、プロンプト自体は反映されていることが分かりました。しかし、テーブルを跨いだ検索そのものは依然として難しい結果となりました。
対応2:セマンティックモデルを1つに統合
これまではテーブルごとにセマンティックモデルを分割し、別々のツールとして渡していました。
- product_orders用のセマンティックモデル
- customer_profiles用のセマンティックモデル
これらを統合し、1つのsemantic_model.ymlとしてCortex Agentsに渡すよう変更しました。
name: "product_orders_and_profile"
tables:
# ── CUSTOMER_PROFILES ──
- name: CUSTOMER_PROFILES
base_table:
database: CORTEXAGENT
schema: CUSTOMERSUPPORT
table: CUSTOMER_PROFILES
dimensions:
・・・省略
# ── PRODUCT_ORDERS ──
- name: PRODUCT_ORDERS
base_table:
database: CORTEXAGENT
schema: CUSTOMERSUPPORT
table: PRODUCT_ORDERS
dimensions:
- name: ORDER_ID
expr: ORDER_ID
data_type: TEXT
is_primary_key: true
・・・省略
relationships:
- name: user_to_orders
left_table: CUSTOMER_PROFILES
right_table: PRODUCT_ORDERS
join_type: inner
relationship_type: one_to_many
relationship_columns:
- left_column: USER_ID
right_column: USER_ID
結果、テーブルを跨いだ問い合わせに対応可能となりました!
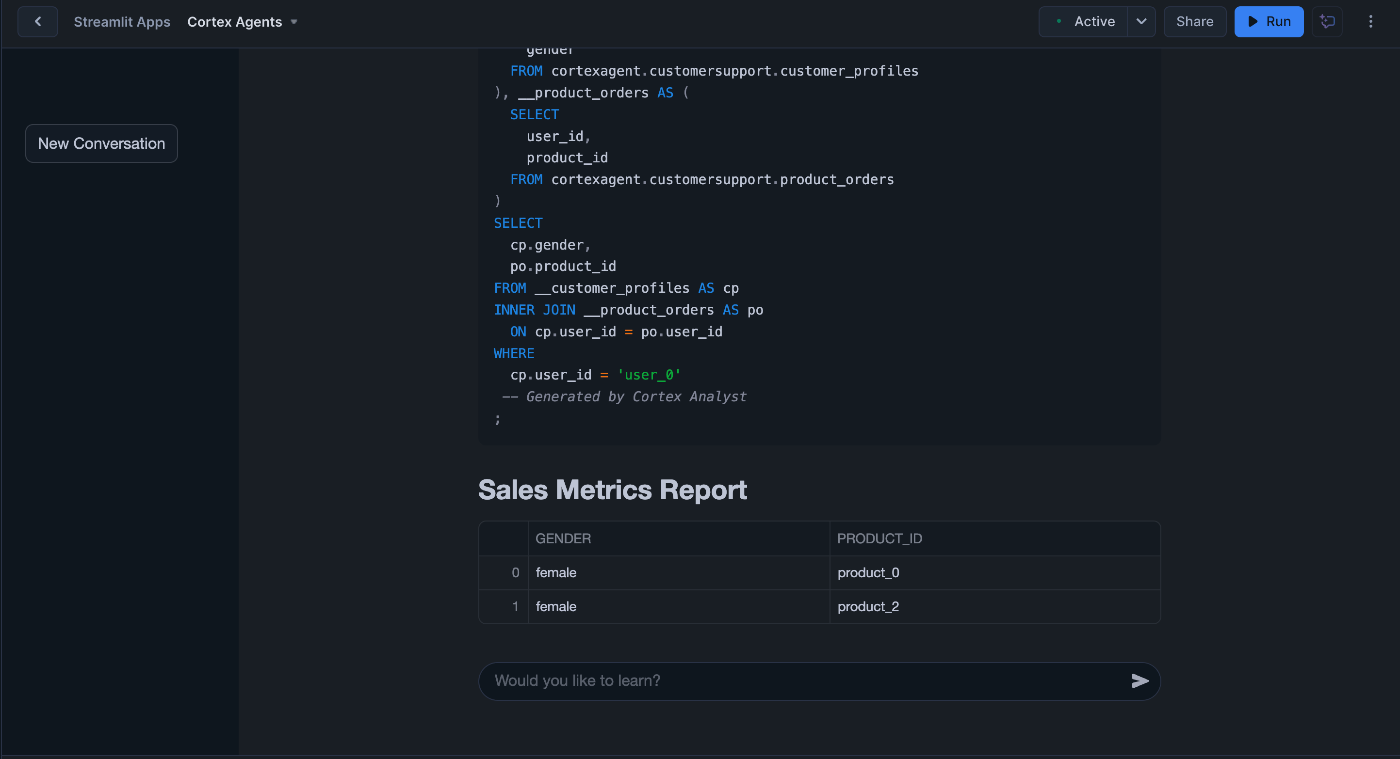
💬 クエリ例(非構造化データのテーブルを跨いだ質問)
「パスワードを忘れた場合はどうすればいいですか?」
関連レコードは以下2テーブルに分散しています
-
search_chat(チャットログ)
('conv_6', 'user_1', 'agent_0', CURRENT_TIMESTAMP,
'Q: アプリにログインできず、パスワードをリセットしても確認メールが届きません。どうすればいいですか?
A: 迷惑メールフォルダをご確認ください。届いていない場合は再送リクエストを行ってください。'), -
search_faq(FAQ)
('faq_4', 'アカウント',
'パスワードを忘れた場合はどうすればいいですか?',
'ログイン画面の「パスワードをお忘れですか?」リンクから登録メールアドレスを入力し、届いたメールの案内に従って再設定してください。'),
✅ 結果
2つのテーブルから関連情報を抽出し、正しく回答できました。

🧐 考察
- 構造化/非構造データを跨いだ検索は可能。
- ただし、テーブルごとにセマンティックモデルを分割すると、テーブル跨ぎの質問に対応できない場合がある。
検証_Lv.3 複合ツール(構造+非構造)
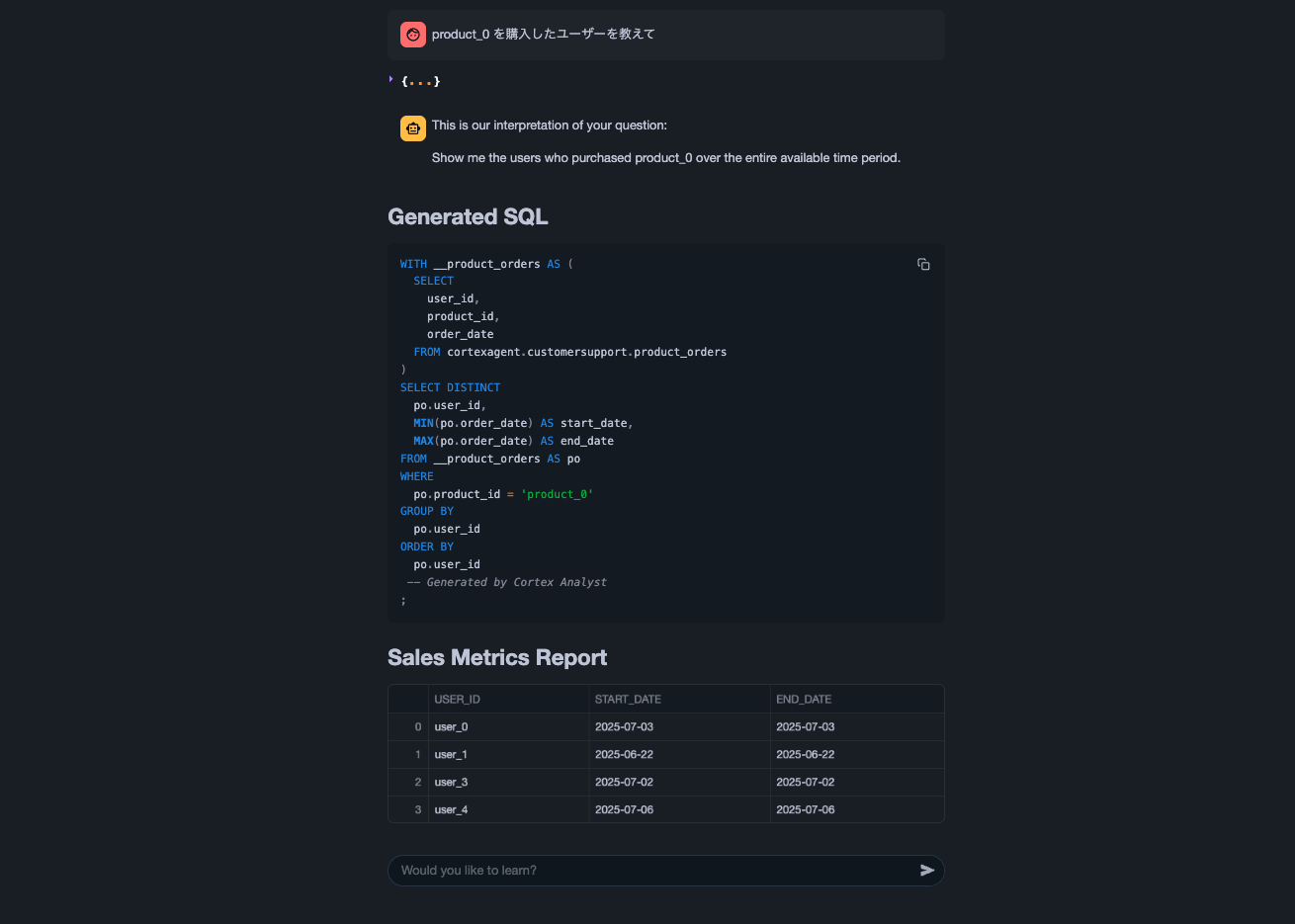
💬 クエリ例
「product_0 を購入したユーザーと、そのユーザーの問い合わせ内容を一覧してください」
この質問に答えるためには、構造化データ(購入履歴)と非構造化データ(問い合わせ内容)の両方を扱う必要があります。
-
product_orders
('order_0', 'user_0', 'product_0', 2, 45.20, '2025-07-03'),
('order_1', 'user_1', 'product_1', 1, 23.99, '2025-06-27'),
('order_2', 'user_2', 'product_2', 3, 88.50, '2025-07-01'),
('order_3', 'user_3', 'product_0', 1, 32.00, '2025-07-02'),
('order_4', 'user_4', 'product_1', 2, 60.00, '2025-06-30'),
('order_5', 'user_0', 'product_2', 1, 99.99, '2025-06-18'),
('order_6', 'user_1', 'product_0', 3, 75.40, '2025-06-22'),
('order_7', 'user_2', 'product_1', 1, 15.80, '2025-07-04'),
('order_8', 'user_3', 'product_2', 2, 66.66, '2025-07-05'),
('order_9', 'user_4', 'product_0', 1, 54.32, '2025-07-06');
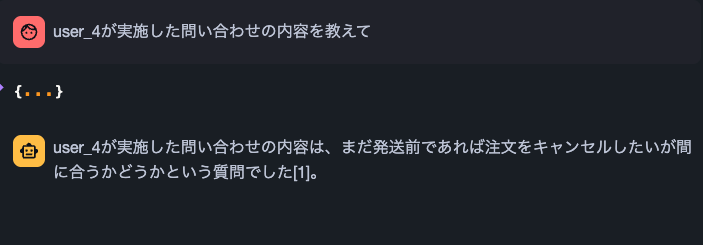
-
search_chat(チャットログ)
('conv_4', 'user_4', 'agent_1', CURRENT_TIMESTAMP,
'Q: user_4からの質問。まだ発送前であれば注文をキャンセルしたいのですが、間に合いますか?
A: 発送準備前であればキャンセル可能です。詳細はマイページからお手続きください。'),
期待する出力
product_0を購入したユーザは、user0,1,3,4です。
user4から「まだ発送前であれば注文をキャンセルしたいのですが、間に合いますか」という質問が来ています
✅ 結果
回答は得られませんでした。
Cortex AgentsがCortex Analystを使用せず、Cortex Searchだけを選択していることが確認できます。
{
"type": "tool_use",
"tool_use": {
"name": "cortex_search",
"type": "cortex_search",
"input": {
"columns": ["conversation_id"],
"indexName": "search_chat"
}
}
}
対応1:入力プロンプトを変更
質問を分割して明示的に流れを指示しました。
- 入力プロンプト1:
product_0 を購入したユーザを教えて。その後に、そのユーザーの問い合わせ内容を一覧してください
- 入力プロンプト2:
まずAnalystを使ってproduct_0購入ユーザーを取得し、次にSearch を使って問い合わせ内容を調べてください
- 入力プロンプト3:
明示的に、使用するツールを指定する
まずanalyst1ツールを使用してproduct_0を購入したユーザーを取得し、
次にsearch_chatツールを使用してそのユーザーの問い合わせ内容を調べてください。
✅ 結果
- 「Analyst ツールや Search ツールにアクセスできない」という趣旨の回答となり、期待する結果は得られませんでした。
- ログを見ると依然として Cortex Searchのみが選択されており、構造→非構造という多段階処理が実行されていません。
対応2:Request bodyのパラメータを変更してみる
Cortex Agentsに渡すRequest Bodyでは、モデルやツール選択に関わるパラメータtool_choiceを設定できます。これは "auto"(デフォルトで自動選択)、"required"(必ずいずれかのツールを利用)、"tool"(特定ツールを指定)の3種類があります。
今回はデフォルトの "auto" から "required" に変更し、必ずツールが利用されるようにした上で、対応1のプロンプトを再実行しました。
✅ 結果
期待する結果は得られず、ツール選択の挙動には変化がありませんでした。
参考: Cortex Agents REST API
対応3:Agentに渡す指示プロンプトを変更して試してみる
payload = {
"response_instruction": """
次のルールに従って必ず回答してください:
1. 購入履歴やユーザー属性に関する質問では、必ず Analyst ツール(analyst1)を最初に使用してSQLクエリを生成し、構造データを取得してください。
2. 次に、そのユーザーIDや購入履歴に紐づく問い合わせ内容・レビュー・チャットなどの非構造データを調べる場合は、Search ツール(search_chat, search_faq, product_feedback)を使用して取得してください。
3. 必ず **Analyst → Search → 結果統合** の順序で処理してください。
4. 回答は、取得したデータに基づいて統合的にまとめ、最後に必ず「!」をつけて終了してください。
### 例:
質問: 「product_0 を購入したユーザーと、そのユーザーの問い合わせ内容を教えて」
処理:
- Step1: analyst1 で product_0 の購入ユーザーを取得
- Step2: search_chat と search_faq でユーザーの問い合わせ内容を検索
- Step3: 両者を組み合わせて結果を要約
回答: 「product_0 購入者は user_4 です。そのユーザーの問い合わせ内容は〜です!」
"""
✅ 結果
しかし、期待する回答は得られませんでした。
回答文の語尾に「!」が付いていたことから、プロンプト自体は正しく読み込まれていましたが、Cortex Agents は Cortex Analystを使用せず、Cortex Searchのみを選択していたことがログから確認できました。
つまり、プロンプトで処理の流れを具体的に指示しても、構造データと非構造データを跨いだ検索を1回の質問で処理するのは難しいことが分かりました。
🧐 考察
- Cortex Analystと Cortex Searchの両方を組み合わせるような処理を、Agent が自動的に行うことは現時点では難しいと考えられます。
- ただし、実際の利用シナリオでは以下のように 複数のチャットに分けて質問する ケースも多いため、必ずしも 1 回の質問で統合的な回答を得る能力が必須とは言えないでしょう。
- ユーザ:product_0の購入者を教えて
- Cortex Agents:user_0が購入者です
- ユーザ:user_0の問い合わせ内容を教えて
まとめ
今回の検証では、Cortex Agentsが持つ「構造化データ×非構造化データ」を横断的に扱う能力を試しました。
- Lv.1 の基礎的な質問では、構造化データに対するSQL生成やFAQ検索を適切に選択し、意図を理解した回答を返せることを確認できました。
- Lv.2では、セマンティックモデルを統合することで、テーブルを跨いだ質問にも対応できることが分かりました。
- Lv.3のような構造・非構造を跨いだ複合質問は、現時点(プレビュー版)では1ターンでの処理が難しい結果となりましたが、Cortex Agentsには複数ステップ実行やツール連携の仕組みが備わっており、今後の進化に大いに期待できると感じています。
一方で、今回の検証を通じて実感したのは、「いくらagentとはいえ、データの構造や関係性を理解していなければ、適切な計画やツール選択は難しい」という点です。実際、構造化データをまたいだ質問に対応させるには、セマンティックモデルの整備やリレーションの定義が不可欠でした。
特にCortex Agentsは、現状こちらから明示的に制御できるパラメータが限られており、「賢さ」を引き出すには事前にどれだけデータを整備・設計できるかがカギとなると考えます。
総じて、Cortex Agentsは実用的に動作しており、今後のアップデートによってより柔軟で高度なエージェント挙動が可能になることを期待しています。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。