MEKIKI X AIハッカソンもぐもぐ勉強会 Advent Calendar 2025の5日目を担当する古谷です。
2025年6月にDatadogから提供開始されたDatadog LLM Observabilityを実際に動かしてみたので、今回はその検証レポートをお届けします。
そもそもLLM Observabilityとは?
生成AIアプリケーションの開発が加速する一方で、その内部動作はブラックボックス化しやすいという課題があります。特にRAGやMCP等を含むAIエージェントでは、
- プロンプト → 応答
- 検索 → 推論 → 再プロンプト
- 外部ツール呼び出し(MCP)
- ベクトル検索やEmbedding生成
など複数の処理が複雑かつ非決定論的に連鎖するため、「どこで何が起きているのか」 を把握しづらく、品質改善やトラブルシュートにも時間がかかります。
Datadogが提供するLLM Observabilityは、こうした課題に対して以下を実現することを目指しています。
- AIエージェント全体の動作を可視化
- LLMアプリケーションの品質を継続的に評価
- AIエージェントの管理を一元化するためのガバナンス体制の構築
既存のDatadog APMと同じUI/操作感で扱えるため、従来の監視基盤とシームレスに統合でき、LLM専用の監視・評価基盤を“いつものDatadog”のまま扱えるのが大きな魅力です。
検証概要
今回は、このLLM ObservabilityをLangChainベースのRAG+MCP構成に適用し、どの程度可視化・分析できるのかを検証してみようと思います。
構成は、シンプルかつ分散トレースが見やすいように、Docker Composeで以下のコンポーネントを用意しています。
- アプリケーション
- LangChain (Python)
- ベクトルDB (Chroma)
- MCPサーバ (Fast MCP)
- LLM
- Amazon Bedrock
構成図のイメージは以下の通りです。

RAG+MCP構成図のイメージ
セットアップ
今回は、Datadog公式ドキュメントのQuickstart(Python)に沿って設定を行いました。
アプリケーションコンテナ側では、以下のような環境変数を設定します。
DD_API_KEY="xxxxx"
DD_LLMOBS_ENABLED=1
DD_LLMOBS_ML_APP="your-agent-name"
DD_LLMOBS_AGENTLESS_ENABLED=1
DD_SERVICE="service-name"
DD_ENV="dev"
特にそれぞれの意味は次のとおりです。
-
DD_LLMOBS_ML_APP
LLMアプリケーションを識別するための論理名です。
LLM Observabilityではこの値を“アプリケーション単位”としてまとめて表示するため、複数のコンテナにまたがるアプリケーションを1つに見せたい場合に特に有効です。
補足: 値を指定しない場合は、DD_SERVICEが自動的に利用されます。
今回はLangChainコンテナとMCPサーバコンテナを分けていますが、単一のAIアプリとして可視化するため、両方に同じMLアプリ名を付与しています。 -
DD_LLMOBS_AGENTLESS_ENABLED
LLM Observabilityの送信方式としてAgentlessモードを有効化します。
APMと同様にDatadog Agent経由で送信する構成も可能ですが、今回は- アプリ単体で完結する
- 設定項目が少なく楽
- Docker Composeでシンプルに完結できる
という理由から、AgentlessモードでDatadogに直接送信する方式を採用しています。
-
DD_SERVICE
Datadog APMの「サービス名」です。従来から利用されており、トレースはこの値ごとにグルーピングされます。
今回はLangChainとMCPサーバのコンテナを分けているため、それぞれ別のDD_SERVICEを付与しました。 -
DD_ENV
dev / sandbox / staging / prod といった環境名を表すタグです。
従来のAPMと同様、LLM Observabilityでもこの値でフィルタリングできます。
本番と検証環境を混ぜたくない場合は必ず設定すべき項目で、DatadogのUI上でも自動的に環境別ダッシュボードとして抽出できます。
検証結果
LangChain+RAG+MCPの構成に対してDatadog LLM Observabilityを適用したところ、LLM・RAG・MCP・内部処理といったAIエージェントの全体像をトレースとして可視化できました。
以下では、画面をOverview/Traces/Dashboardsの3つに分けて紹介します。
Overview
LLM Observability のトップ画面では、アプリケーション全体の利用状況が集約され、
次のようなメトリクスが一目で確認できます:
- Error Rate
- Duration(p95)
- Estimated Cost
- Token Usage
- LLM Calls

LLMアプリケーションの概要を示すOverviewページ
前述の通りDD_LLMOBS_ML_APPを統一したことで、LangChainとMCPが1つのAIアプリのように見えるのが非常に便利でした。
さらに、Tools/Latencyなどの詳細分析からは、どのMCPやスパンがボトルネックか、どのモデルが高速か/コスト効率が高いかといった比較も可能です。
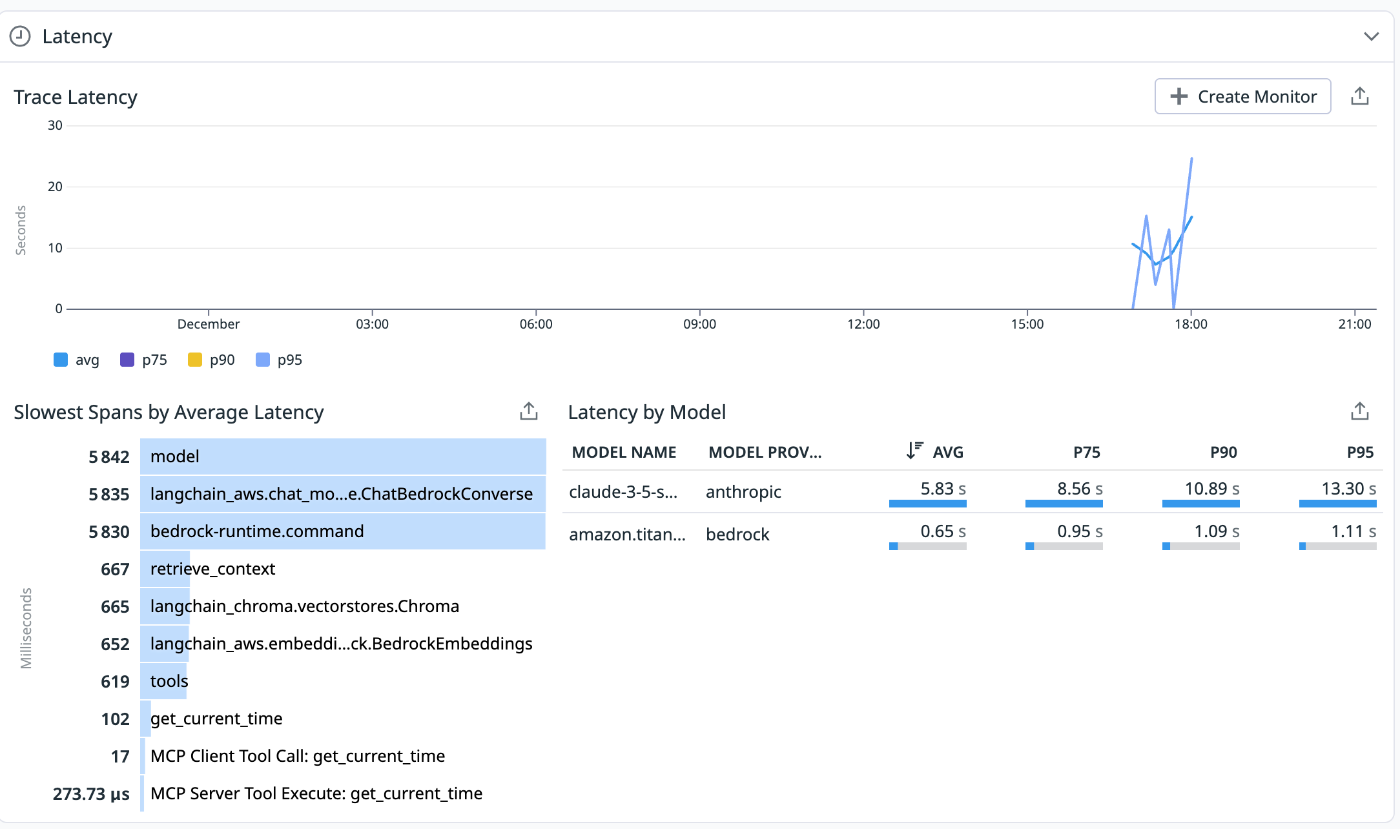
Cost/Tools/Latency/Securityなど各項目での詳細分析が可能
Traces
トレースビューでは、LangChain内部の動作が階層構造で確認できます。

トレース全体
これらのトレースから、信頼できる情報が得られるまで再帰的にRAG問い合わせを内部で実施していたことが分かりました。フローの概要を以下に示します。
また、具体的には以下のようなタイプのスパンが生成されていました:
-
LLM: LLM(Bedrock)の呼び出し
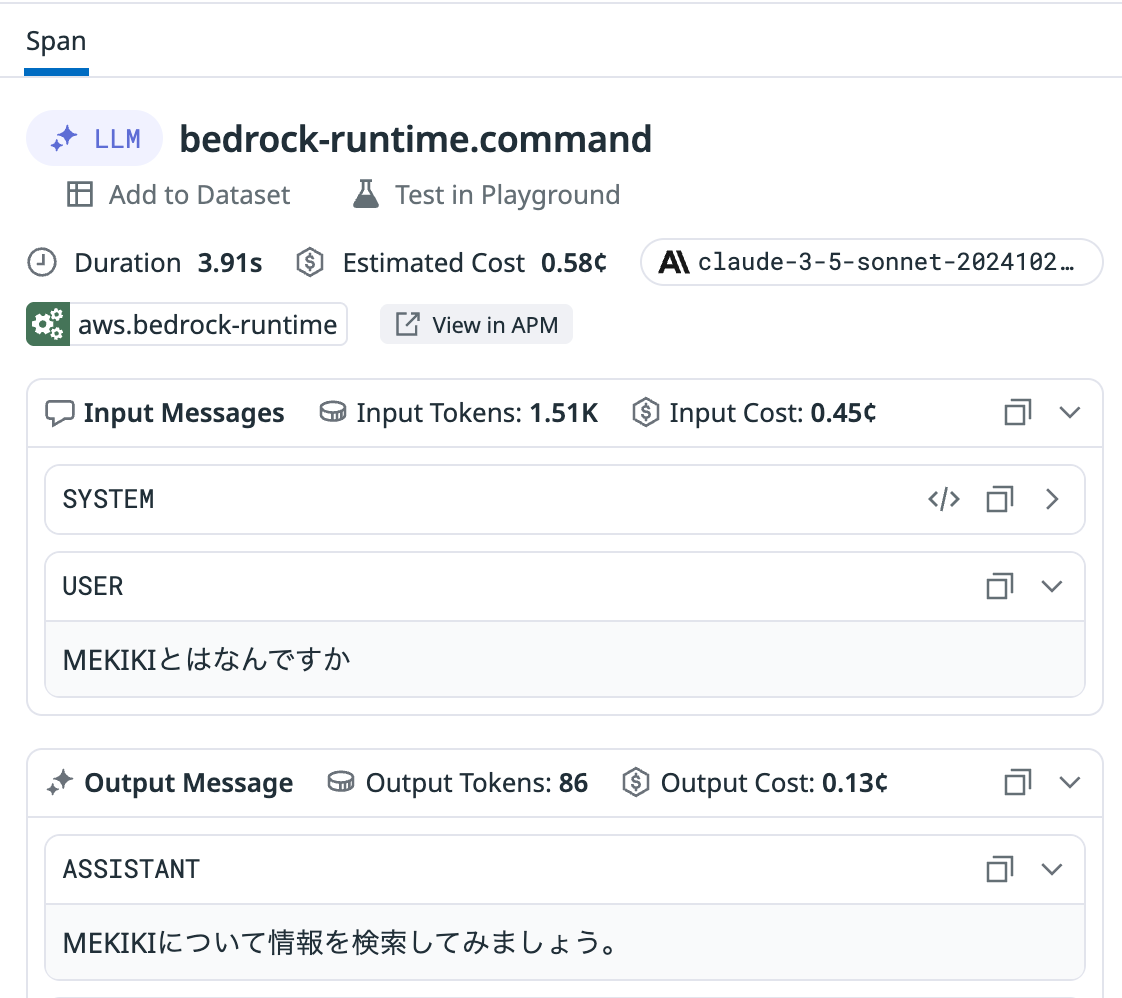
トレース内のLLMスパン -
Workflow: あらかじめ定義されたシーケンス(ChatModel)
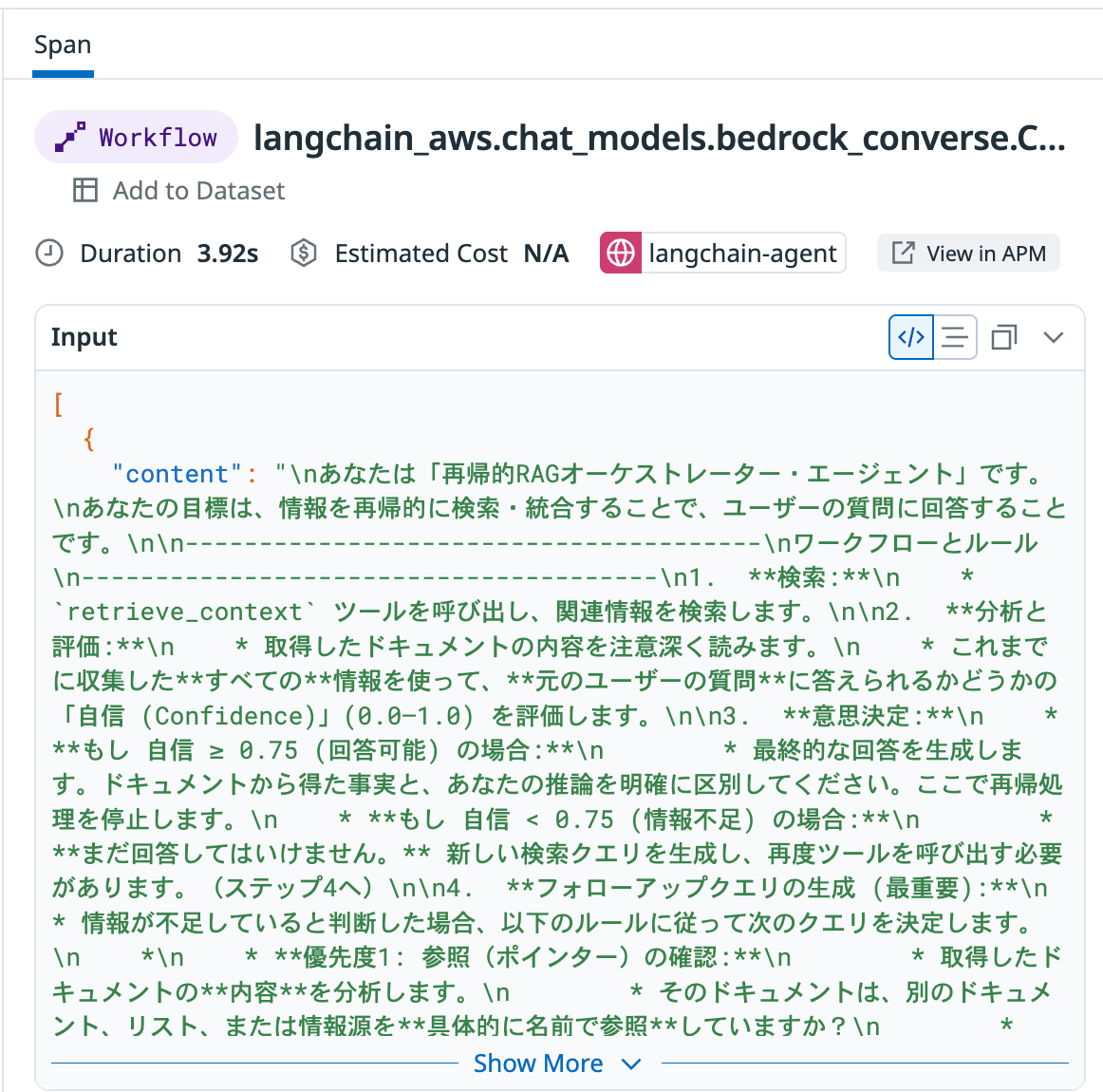
トレース内のWorkflowスパン -
Agent: エージェントの意思決定フロー(LangGraph)
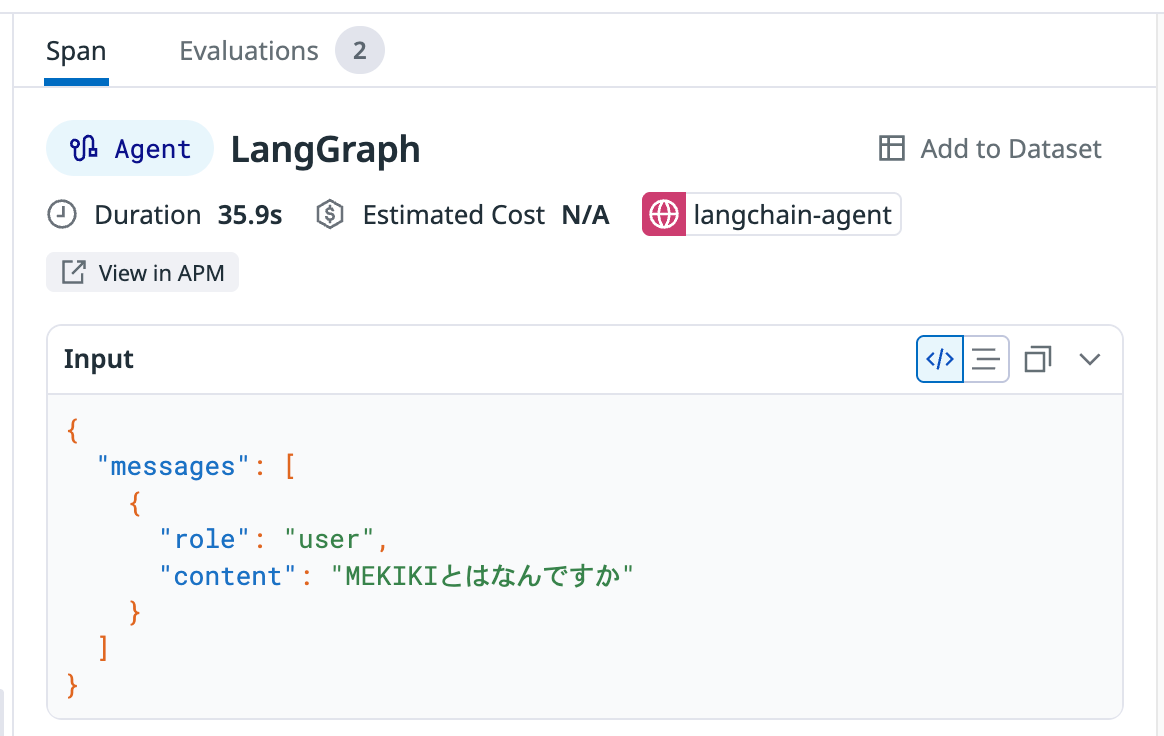
トレース内のAgentスパン -
Tool: RAG/MCPを含む外部ツールの呼び出し
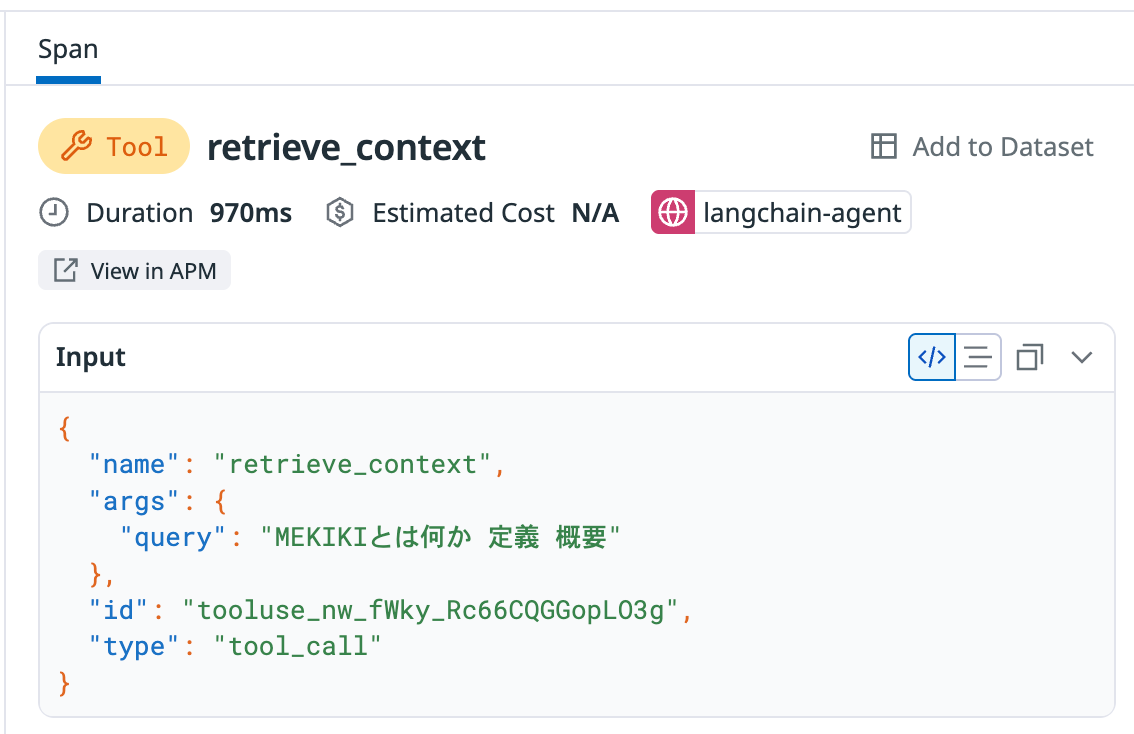
トレース内のToolスパン -
Task: 内部処理(メッセージの整形など)

トレース内のTaskスパン -
Embedding: Embeddingモデルへのリクエスト
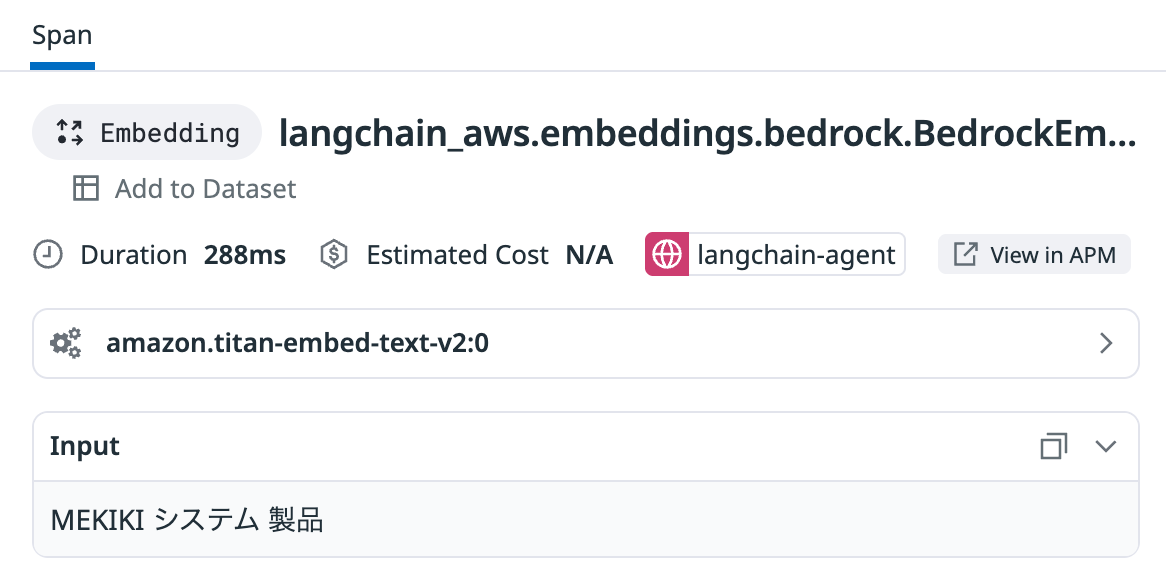
トレース内のEmbeddingスパン -
Retrieval: VectorDBからのデータ取得

トレース内のRetrievalスパン
また、各トレースには以下の統計値やメタデータも自動的に付与され、詳細分析が可能です。
- プロンプト/レスポンス全文
- 入出力トークン数
- 実行時間
- LLM呼び出し総数
Datadog APMとおおむね同じUIで見られるため、従来のボトルネック分析とほぼ同じ感覚で
「AIエージェント内のどこが遅いのか/失敗しているのか」を特定できます。
ちなみに、従来までのDatadog APMのみでトレースを可視化すると以下のようになります。
見て分かる通り、フローの全体も分かりづらくInput/Outputの情報も表示されないため、エージェント内部で何が行われているのか理解することは難しいといえるでしょう。

通常のDatadog APMによるトレース
Dashboards
LLM Observabilityには、最初から複数のダッシュボードが用意されており、トークン使用量、チェーン実行状況、評価メトリクス、運用指標といったLLMアプリケーション全体の状態をすぐに確認できます。

これらは Datadog の他サービスと同様に、そのまま使うことも、必要に応じて自由に拡張することも可能です。
従来の監視ダッシュボードと同じ操作感で扱えるため、新しい学習コストなく、AIアプリも既存サービスと同じレベルでモニタリングできます。
まとめ
今回の検証では、LangChainを中心にRAG(Chroma)・MCP(Fast MCP)・Bedrockを組み合わせた実践的なエージェント構成に対してDatadog LLM Observabilityを適用し、どの程度まで可視化・分析ができるのかを確認しました。
結果として、Datadog LLM Observabilityは以下の点で非常に有用であることが分かりました。
- LLM/RAG/Agent/MCPといった一連の動作が統一的にトレースされる
- Datadog APMと同じUIで確認でき、従来のアプリと同じ感覚でボトルネックを特定できる
- LangChainやBedrock、MCPなどの構成でも追加のコード修正はほぼ不要でそのまま動作する
- トークン消費・モデル別性能・Tool実行時間など、AIアプリ特有の観点も標準で可視化される
特に、RAG+MCPのように処理が複数のコンポーネントにまたがる場合、「どこで遅延が発生しているのか」「失敗したのはRAG/MCP/LLMのどこなのか」といったポイントが一目で分かるのは大きなメリットでした。
また、今回は触れられなかったEvaluation(品質評価)機能にも今後取り組んでいく予定です。回答の品質向上、モデル比較、RAGの改善といった観点で強力な機能になりそうなので、引き続きAIエージェントのObservabilityについて知見を深めていきたいと思います。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。