Intl.Segmenter で和文の改行をいい感じにしてみる
tl;dr
ブラウザで文字列を表示する場合画面幅に応じて自動で改行されることがあります。英文などは分かち書きされているためブラウザは単語の区切りなどで改行することができますが、和文は文節が明確ではなく単語の途中で改行されてしまうことがあります。
この記事では、ECMA402 の Intl.Segmenter を用いて和文を分かち書きし、ブラウザに改行可能箇所を教えることでより読みやすいレイアウトを目指します。
(2023/04/14 追記) NPM package として公開しました 🚀
背景
ラテン文字を使用する多くの言語では語と語が空白で区切られていますが(以降分かち書き)、通常、日本語や中国語は分かち書きされていません。
一般的なブラウザでは表示領域(横幅)に対して表示させたい文字列が一行に収まらない場合自動で改行するような挙動になっています。英語のように既に分かち書きされた文の場合、ブラウザのデフォルトの挙動としては語と語の間で改行します[1]。
一方で日本語のように分かち書きされていない場合、句読点で区切ることはできますが語と語の区切りについては対応されておらず、結果として語の途中で改行が入ってしまうことがあります。
対処法
これらの問題は広く知られており、次の記事で説明されているように <wbr> で改行位置を指定する手法や <span> を用いて適切に語をまとめることで対処することができます。
しかしこれらを手動で行うのは骨が折れる作業であり、ミスも起きやすそうです。
上で紹介した記事でも紹介されていますが、Budoux という Google が開発したライブラリを使うことで和文の改行処理を自動で行うことができます。
Intl.Segmenter の紹介
この記事では外部のライブラリに依存しない方法として Intl.Segmenter を使う方法を紹介します。[2]
まず、Intl API というのは ECMA402 で定められている国際化 API の仕様で、言語ごとの数値・日付の書式化や複数形の言語規則を扱えるようにする API が提供されています。
Intl.Segmenter はその中でも新しい proposal で ES2022 で正式に取り入れられました。
Intl.Segmenter は、言語に応じた文の意味的分割を行うための API を提供しており、書記素・単語・文に分割することができます。
JavaScript で文字数をカウントする際に String.prototype.length を使うとサロゲートペアを考慮できずに意図した挙動にならないことが知られていますが[3]、Intl.Segmenter を用いて書記素で分割すると適切に文字数をカウントすることができます。
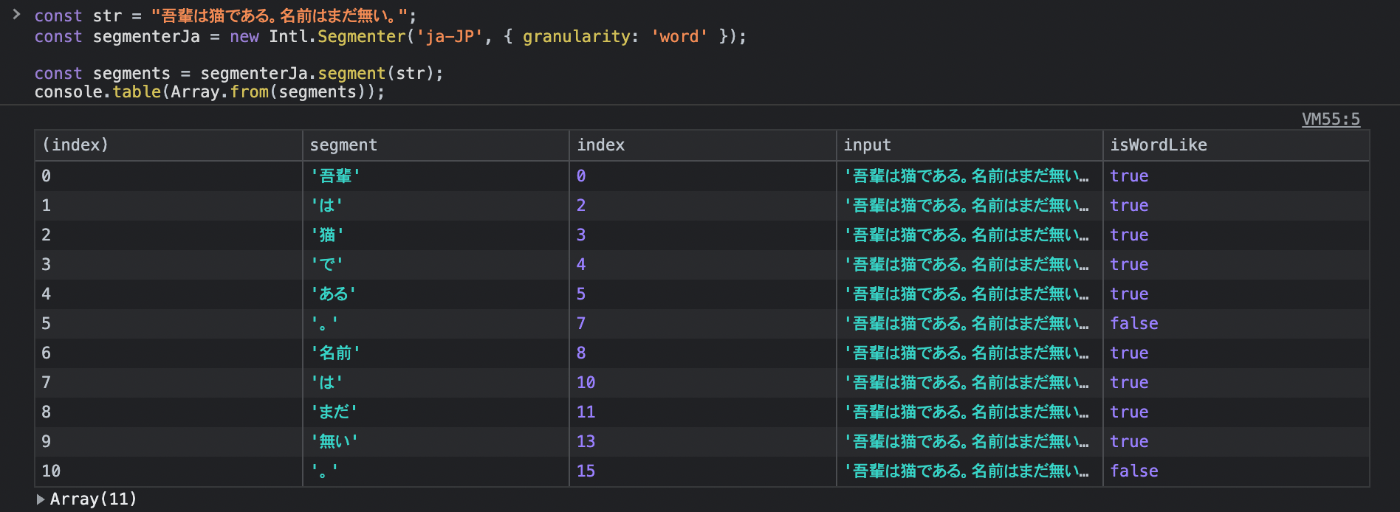
基本的な使い方は以下のようになっています。(Google Chrome v105 の Dev Console で実行)
サンプルコード
const str = "吾輩は猫である。名前はまだ無い。";
const segmenterJa = new Intl.Segmenter('ja-JP', { granularity: 'word' });
const segments = segmenterJa.segment(str);
console.table(Array.from(segments));
なお 2022/09 時点での各ブラウザのサポート状況は以下のようになっており、Firefox 以外の主要なブラウザでは利用できると考えて良さそうです。
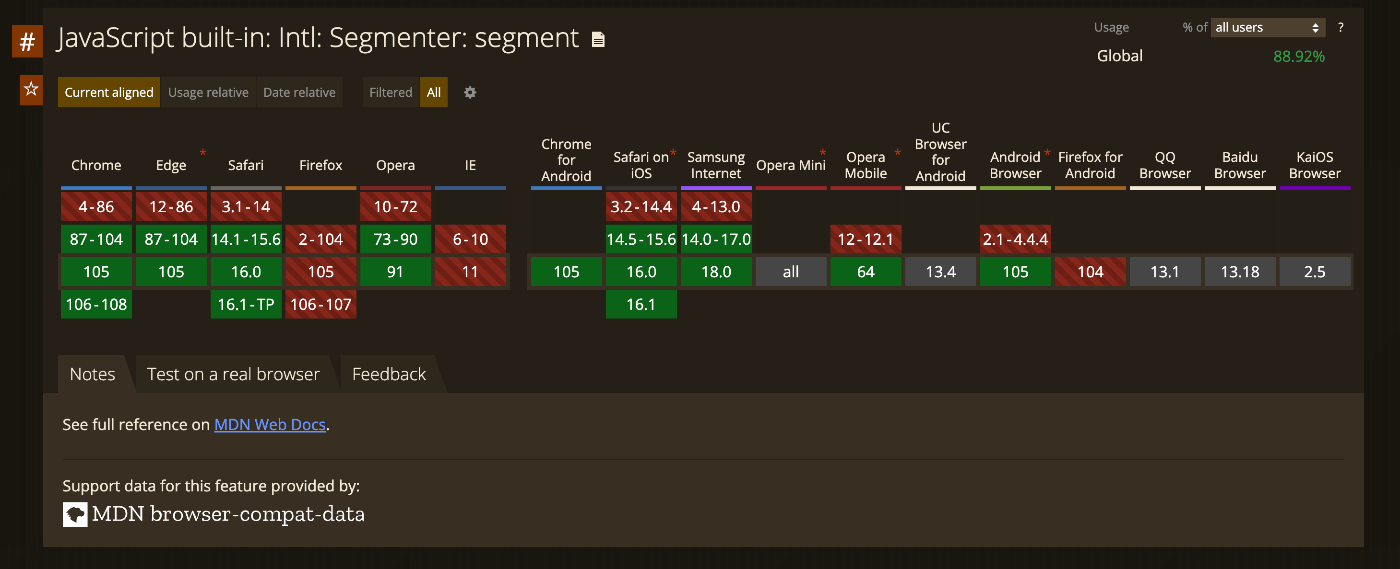
ref. https://caniuse.com/mdn-javascript_builtins_intl_segmenter_segment
ブラウザ以外のランタイムを見てみると Node.js では v16.0.0[4] から、Deno では v1.8 から利用できるようです。
Intl.Segmenter を用いた手法
Intl.Segmenter で分割された文字列に対して、上で紹介した記事にある手法を適用することで外部ライブラリに頼ることなく自動で改行位置を制御することができます。
今回は React.js を使って TextSegmenter コンポーネントとして実装しました。
CodeSandbox の例ではスライダーを動かすと表示幅が変わり改行されたときの挙動を確かめることができます。
我々のユースケースでは日本語と英語でしか使わないので locale を固定し、日本語だけ判定を行っています。英語の場合は CSS を変更してブラウザに任せてしまうのが良いと考えています。
実装面での懸念など
ここからは TextSegmenter を実装したときに当たった問題や実際に使う際に注意が必要なことについて説明していきます。
<wbr> とゼロ幅スペース
HTML で改行位置を指定する方法として以下の二種類が考えられます。
それぞれ説明を読む限りだとどちらを使っても今回の要件は満たしそうです。実際上記コードを書き換えて <wbr> の代わりに \u200b を挿入してみても見た目上はうまく改行されています。
なぜあえて見た目上はと強調したのかというと、表示された文字列をコピーしたときの挙動に差異があるためです。<wbr> を使った実装では文字列をコピーしてもタグが含まれることはありませんが[5]、ゼロ幅スペースを用いた実装ではコピーした際にゼロ幅スペースが残ってしまいます。
これは意図した挙動ではなくユーザー体験を損ないそうです。したがって今回は <wbr> を使っています。
SSR 時の hydration の考慮
上で紹介した TextSegmenter コンポーネントを SSR(Server Side Rendering) される場所で利用する場合は hydration 時の content mismatch に注意する必要があります。
SSR はその名の通りサーバーサイドで一度 React のアプリケーションを実行して DOM を構築し、HTML をブラウザに返します。ブラウザで React アプリケーションの JavaScript が読み込まれたらクライアントサイドで仮想 DOM を生成し、再度 DOM を構築、そしてイベントハンドラをアタッチしようとします。これを hydrate と呼びます。このとき、サーバー側で生成された DOM との差分がないかをチェックします。[6] ここで何も差分がなければ良いのですが、何らかの原因で差分が発生した場合 content mismatch が発生します。
React.js の hydrate API の実装を読み、hydration 時にエラーが発生する条件を確認してみます。hydrate API は ReactDOM に実装されており、今回特に関係がありそうな条件は次のコードに記載されています。
ここではサーバー側で生成された DOM の children とクライアントで生成された仮想 DOM の children を比較しています。仮想 DOM の children が string | number の場合、DOM の textContent と比較されます。同一の要素内では、仮想 DOM 側が foo でサーバー側で生成された DOM が f<span>oo</span> のようにマークアップされている場合は content mismatch エラーは発生しないようです。ちなみに開発環境ではもう少し厳しいルールが適用され、style などの属性に関してもチェックされます。
では次に、どのような場合にサーバーで生成した DOM とブラウザで生成した DOM に差分が発生するか考えてみます。
一番わかりやすい例は SSR サーバーでは Intl.Semgenter が利用できるがブラウザ側が対応していないというケースです。Intl.Segmenter の紹介で述べたとおり、現在 Firefox では Intl.Semgmenter が利用できません。他にもブラウザのバージョンが古くて対応していないケースなどがあります。
このようなケースでは、サーバーが生成した DOM は Intl.Segmenter によって一度分割され <wbr> が挿入されたノードになっていますが、ブラウザでは Intl.Segmenter が利用できず元の文字列がそのままノードになるため content mismatch が発生します。
実際、Next.js で SSR している箇所で TextSegmenter を用い、そのページを Firefox から見たところ次のようなエラーが表示されます(開発者モード)。
Warning: Expected server HTML to contain a matching text node for "今日は良い天気です" in <div>.
サーバーで生成された DOM とブラウザで生成された HTML は以下のようになっていました。
| サーバー | ブラウザ |
|---|---|
<span style="word-break:keep-all">今日<wbr/>は<wbr/>良い<wbr/>天気<wbr/>です<wbr/>ね</span> |
今日は良い天気です |
また、ECMAScript では仕様は定義されていても具体的な実装方法について言及されていないものがあります。つまり処理系によって微妙に異なる結果を出力する可能性があるということです。
今回利用した Intl.Segmenter についても同様で、文の分割に関して細かい実装方法や分割に利用する辞書については処理系任せになっています。
例えば、SSR に使うサーバーの実装が Node.js だっとすると JavaScript エンジンは V8 になります。一方で表示するブラウザが Safari の場合は JavaScript のエンジンは JavaScriptCore になります。
いくつか手元で試したところ次の文字列では異なる分割結果が得られました。[7]
| 対象文字列 | V8[8] | JavaScriptCore[9] |
|---|---|---|
| 五大湖 | "五大湖" | "五大", "湖" |
| E.T. | "E", ".", "T", "." | "E.T", "T" |
ここまで content mismatch が発生するようなケースについて考えてきましたが、次はどのように対応すればよいかについて考えてみたいと思います。
hydration 時の content mismatch に関して React.js の公式ドキュメントでは2つの対処法が提示されています。
- 要素に
suppressHydrationWarning={true}を追加する - 2 パスレンダーを使用する
それぞれ見ていきましょう。
要素に suppressHydrationWarning={true} を追加する
この方法は強制的にエラーを無視するというものです。ドキュメントにある通り1階層下のノードまでにしか適用されないため、深くネストされている場合はそれぞれのノードに suppressHydrationWarning={true} を付与する必要があります。この方法は意図しない不整合が残る懸念や、発見が遅れる懸念があるため今回は利用しませんでした。
2 パスレンダーを使用する
この方法はサーバーとクライアントで異なるものを表示したいケースで使います。一瞬だけサーバーと同じものを表示し、その後すぐに別のものを表示するというような手法です。この手法では2回描画処理が走るためパフォーマンス的な懸念が生じます。
今回のケースで考えてみると、サーバー側では Intl.Segmenter で処理を行わないというような実装を挟むことによって content mismatch を解消することができます。
具体的な実装は以下の部分です。
const [isClient, setIsClient] = useState(false);
useEffect(() => setIsClient(true), []);
if (!isClient) {
// two-pass rendering.
return <>{children}</>;
}
パフォーマンスの懸念に関しては TextSegmenter の中で使うノードはあくまで文字列を表示するためのものを想定しており、高コストのレンダリングが発生することはほとんど無いと考えています。
マークアップ済みのノードの考慮
例えば次の文を分割することを考えます。
メチルアルコールとエチルアルコールはいずれもアルコールの仲間です
この文を先程紹介した TextSegmenter に渡してあげると次のような結果になります。 (読みやすいように一部インデントを行ってます。)
<span style="word-break: keep-all;">
メチルアルコール<wbr>と<wbr>エチルアルコール<wbr>は<wbr>いずれ<wbr>も<wbr>アルコール<wbr>の<wbr>仲間<wbr>です<wbr>
</span>
これは概ね意図したような結果ではないでしょうか。
一方で、次のように一部をマークアップしたものを考えてみます。
メチルアルコールとエチルアルコールはいずれもアルコールの仲間です
<b>メチル</b>アルコールと<b>エチル</b>アルコールはいずれもアルコールの仲間です
TextSegmenter は children として渡した ReactNode を再帰的に探索し、文字列分割・改行の位置の挿入を行うように実装しているので上のコードを children として渡してみます。
実際に描画された HTML は次のようになりました。
<span style="word-break: keep-all;">
<b>メチル<wbr></b>アルコール<wbr>と<wbr><b>エチル<wbr></b>アルコール<wbr>は<wbr>いずれ<wbr>も<wbr>アルコール<wbr>の<wbr>仲間<wbr>です<wbr>
</span>
マークアップされた部分に <wbr> が挿入されてしまっています。これは再帰的にノードを処理していく際に親ノードと子ノードでそれぞれで別々に分割処理を行っているためです。
元の文を考えると次のような出力を期待したいところです。そのためには各ノードと対応する文字列を一度すべて抽出しテキスト全体に対して分割を行った上で Component Tree の再構築が必要ですが実装は難しそうです。
<span style="word-break: keep-all;">
<b>メチル</b>アルコール<wbr>と<wbr><b>エチル</b>アルコール<wbr>は<wbr>いずれ<wbr>も<wbr>アルコール<wbr>の<wbr>仲間<wbr>です<wbr>
</span>
今回は実装難易度が高いことと、そのようなマークアップを行うケースがなさそうだったため上記のようなナイーブな実装になっています。
まとめ
Intl.Segmenter API と和文に対して自動で改行位置を制御する方法について紹介しました。まだ比較的新しい API でどのように使えばよいか分からないという人も多いのではないかと思いますが、一つの使い方として参考になれば幸いです。
-
テキストの改行方法に関しては CSS の
word-break属性が適用されます。デフォルト値はnormalで既定の改行ルールが適用されます。 ↩︎ -
予め断っとくと Budoux は機械学習ベースで分割処理を行いますが、Intl.Segmenter の分割方法は実装依存になります。また Budoux はカスタムモデルが利用できるようですが、 Intl.Semgenter は辞書は指定できず proposal 段階です。 ↩︎
-
ブラウザの実装依存かもしれませんが、少なくとも自分の環境では問題ありませんでした。 ↩︎
-
Google Chrome 105.0.5195.125 で検証しました。 ↩︎
-
Safari 15.4 (17613.1.17.1.6) で検証しました。 ↩︎
-
https://github.com/v8/v8/blob/10.8.82/src/objects/js-segment-iterator.cc#L70-L106 ↩︎
-
https://github.com/WebKit/WebKit/blob/0ba0b3dac11c3a155c15feba08506fbc1088a822/Source/JavaScriptCore/runtime/IntlSegmentIterator.cpp#L74-L86 ↩︎
Discussion