Juliaでtidyverseを使う①~TidierData.jlによるデータ前処理:dplyr編~
本記事について
R言語で前処理や可視化などを効率的に行うことができるtidyverseパッケージ群をJuliaに移植した、Tidier.jlパッケージ群の解説記事シリーズ。
本記事では、Tidier.jlパッケージ群のうち、R言語のtidyr/dplyrに対応する、TidierData.jlを用いたデータ前処理について解説する。
公式にReferenceが提供されているので、ぜひそちらを直接参照していただきたい。本記事では一部の主要関数に限定して解説を行う。
TidierData.jlを使うモチベーション
Juliaでは、DataFrames.jlやDataFramesMeta.jlの関数・マクロによって前処理を行うことが多いと思われる。これらに習熟しているユーザは、あえてTidierData.jlを使うべき理由はないかもしれない。
筆者はある程度Rに習熟しているが、Julia自体は初学者であり、RからJuliaに移行する際の学習コストを最小にしたかった。
その際、習熟しているtidyr/dplyrパッケージによるデータ前処理とほとんど同じ記法が使えるTidierData.jlの存在は大いなる助けとなった。
2023/12/21時点では、完璧な移植が行われているわけではないが、実用的には十分なレベルで移植が完了している(筆者にとっては、だが)。
TidierData.jlの関数・マクロたち
それでは以下に実例を示していく。まずはパッケージをインストールしよう。tidyverseパッケージ群のように、@Tidier.jlパッケージ群をインストールすることで、付属する種々のパッケージを一気にインストールできる。
ただしこれにはやや時間がかかるので、本記事を読むうえでは、TidierData.jlのみをインストールするのでもよい。
using Pkg
Pkg.add("TidierData")
using TidierData
なおRのtidyr/dplyrと同様に、TidierData.jlによる前処理も、原則的にパイプライン処理を利用した書き方をする。Juliaのパイプライン処理については他記事を参照のこと。
サンプルデータ
本記事ではRDatasets.jlの、mtcarsデータセットを利用する。これは32台の車両の性能(例:燃費、重量)を格納したデータセットである。
using RDatasets
df = RDatasets.dataset("datasets", "mtcars") # mtcarsデータセットを、dfというオブジェクトに格納
first(df, 3) # 冒頭3行を表示

TidierData.@filter()による行の抽出
Rのdplyr::filter()とほとんど同じ。「『燃費が15.0以下(MPG ≤ 15.0)、オートマ車(AM == 0)』または『燃費が30.0より大きい(MPG > 30.0)、マニュアル車(AM == 1)』」行のみを抽出してみよう。
ANDやORは、演算子&&や||で表す。
@chain df begin
TidierData.@filter((MPG <=15.0 && AM == 0) || (MPG > 30.0 && AM == 1))
end
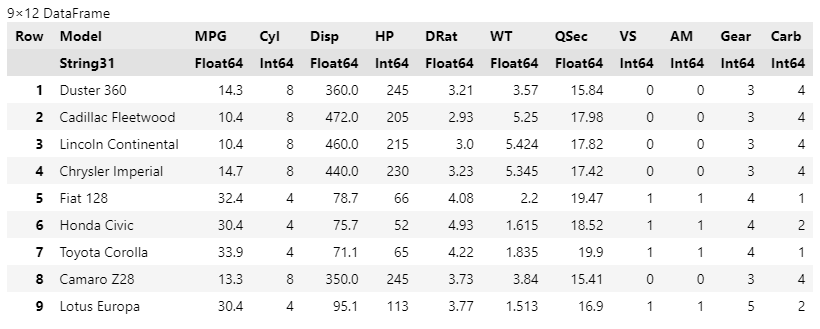
dplyrと同様に、条件の否定は!で表す。
@chain df begin
TidierData.@filter(!(MPG <= 20 || AM == 1))
end

抽出する条件を配列で与えて、その配列に含まれる行を抽出することもできる。これはRでは%in%演算子を用いて実現するが、Juliaではin演算子を使う。
@chain df begin
TidierData.@filter(Model in ["Mazda RX4", "Toyota Corona", "Volvo 142E"])
end
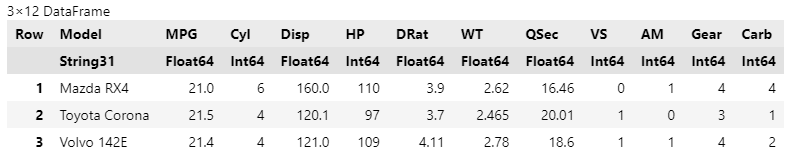
より発展的な書き方として、後述するように正規表現を用いて、特定の文字列を含む行を抽出することもできる。また、別記事で解説するTidierStrings.jlパッケージを併用することでさらに効率的になる。
TidierData.@select()による列の抽出
やはりRのdplyr::select()と同様に利用できる。抽出対象の列名をカンマで区切って併記するが、連続した列は始点:終点という書き方で一括して指定できる。また、除外する列は!で指定する。
列を選択すると同時に、列名を変更することもできる(DISP = Disp)。
@chain df begin
TidierData.@filter(MPG > 30.0)
TidierData.@select(MPG, DISP = Disp, WT:Gear)
TidierData.@select(!(QSec:VS))
end

ヘルパ関数を利用した列選択
dplyrと同様に、種々のヘルパ関数を利用して、特定の文字(列)を含む列だけを抽出することができる。
-
starts_with(): 特定の文字(列)から始まる列を選択 -
contains(): 特定の文字(列)を含む列を選択 -
ends_with(): 特定の文字(列)で終わる列を選択
注意が必要なのは、大文字と小文字は区別されることだ。以下のコードでは、"p"で終わる列を選択しているので、Disp列は抽出されているが、HP列は抽出されていない。
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(starts_with("C"), contains("G"), ends_with("p"))
end

正規表現を用いた柔軟な列名選択を行うためには、matches()が重宝する。例えば正規表現では^は、「その文字から始まる」ということを意味する。よって以下のコードでは、"a"から始まる列名が選択される。
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(matches("^a", "i"))
end

おや?大文字と小文字は区別されるはずでは?
これは第2引数"i"が、大文字と小文字の区別をしない(Do case-insensitive pattern matching)ことを指示しているためだ(詳しくはマニュアル参照)。
正規表現さえ使いこなせれば、starts_with(), contains(), ends_with()は全て、matches()1つで同等の処理ができる。
最後に、列の順番を入れ替えたいとき(例えば、後半の列を前半にごっそり移動したいとき)、everything()を利用した書き方はよく使う。

TidierData.@mutate()による列の追加・上書き
Rのdplyr::mutate()と同じはたらき。新たに列を追加することも、既存の列を上書きすることもできる。
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(matches("p\$", "i")) # "p"または"P"で終わる列を選択。$の前にエスケープシーケンスが必要
TidierData.@mutate(new = (Disp - 100.0) * 5.0,
HP = HP / 100.0
)
end
ヘルパ関数を用いた高度な列の追加・上書き
Rのdplyrとほぼ同様のヘルパ関数を利用できる。if_else()やcase_when()は条件分岐に役立つ。
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(matches("M")) # "M"を含む列を選択
TidierData.@mutate(AM2 = if_else(AM == 0, "Automatic", "Manual"))
TidierData.@mutate(AM3 = case_when(AM2 == "Automatic" => "AUTOMATIC",
AM2 == "Manual" => "MANUAL",
true => "ELSE" # 上記の条件以外は全て
)
)
end

ここで、Rのtidyverseに慣れた人なら、「あれ、以下のように書けるはずでは?」と思うだろう。どうやらTidierData.jlでは2023/12/21時点で、Rのtibble::tibble()が持つような「同じ関数の中で先に作成した変数を継承する」という機能は実装されていないようだ。そのため以下のコードは実行できない(1つの@mutate()のなかでAM2を継承しようとしていることに注目)。
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(matches("M")) # "M"を含む列を選択
TidierData.@mutate(AM2 = if_else(AM == 0, "Automatic", "Manual"),
AM3 = case_when(AM2 == "Automatic" => "AUTOMATIC",
AM2 == "Manual" => "MANUAL",
true => "ELSE"
)
)
end
Rのdplyrバージョン1.0.0で実装されたヘルパ関数across()も利用できる。これは、複数の列すべてに一括して同じ関数を適用するときに利用できる。後述するTidierData.@summarize()でも重宝する。
# 入力値を10倍する関数を定義 -------
function mpl_10(x)
x * 10.0
end
@chain df begin
TidierData.@slice(1:5) # 1~5行目だけを選択
TidierData.@select(MPG:Disp)
TidierData.@mutate(across(MPG:Disp, mpl_10))
TidierData.@rename(MPG_times_10 = MPG_mpl_10) # 列名を変更するマクロ
end

TidierData.@group_by()によるグループごとの処理
これもRのdplyr::group_by()とほぼ同じ。ある変数の水準ごとにサブグループを作り、それぞれに同じ処理を施すことができる。例えば以下のコードでは、オートマ車とマニュアル車それぞれのなかで、シリンダー数が6の行を抽出している。
@chain df begin
TidierData.@group_by(AM)
TidierData.@filter(Cyl == 6)
end

出力を見ると明らかなように、グループが識別されている。もしこのグループを解除したいなら、TidierData.@ungroup()を使う。
@chain df begin
TidierData.@group_by(AM)
TidierData.@filter(Cyl == 6)
TidierData.@ungroup()
end

TidierData.@summarize()によるグループごとの処理
Rのdplyr::summarize()とほぼ同じ。なおTidierData.@summarise()と書いてもよい。基本的にTidierData.@group_by()とセットで使い、グループごとにデータを要約する。
using Statistics
@chain df begin
TidierData.@group_by(AM)
TidierData.@summarize(mean_MPG = Statistics.mean(MPG),
n = n() # 各グループのデータ数を数えるヘルパ関数
)
TidierData.@arrange(AM) # 昇順に並び替えるマクロ
end
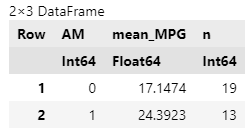
グループは複数指定することもできる。
using Statistics
@chain df begin
TidierData.@group_by(AM, Cyl)
TidierData.@summarize(mean_MPG = Statistics.mean(MPG),
n = n() # 各グループのデータ数を数えるヘルパ関数
)
TidierData.@arrange(AM, desc(Cyl)) # AMは昇順に、ヘルパ関数を用いてCylは降順に並び替えている
end

ここで、出力にグループが残っていることに注目してほしい。特に、指定したグループはAMとCylの2つだったのに、AMに関してのみグループが残っていることが重要だ。
これはRのdplyrと同様で、TidierData.@summarize()を実行すると、自動的にグループが1つ解除される。もし明示的にグループを解除したければ、やはりTidierData.@ungroup()を適用されたい。
TidierData.@pull()によるベクトル化
TidierData.jlはデータフレームを操作するパッケージなので、パイプライン処理の結果はやはりデータフレームになる。
そのデータフレームに含まれる特定の変数(列)を取り出して、特定の処理をしたいとき、Rのdplyr::pull()と同様に、TidierData.@pull()を用いる。取り出された変数はベクトルとなる。
@chain df begin
TidierData.@pull(MPG)
typeof() # 型を調べる
end
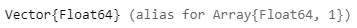
よって、例えばある変数の平均を求めたいとき、パイプライン処理の中にStatistics.mean()を入れればよい。
using Statistics
@chain df begin
TidierData.@pull(MPG)
Statistics.mean() # 算術平均を返す
end
TidierData.@***_join()によるデータフレームの結合
これもRのdplyr::***_join()系関数と同様。複数のデータフレームを、任意の方法で結合できる。
まずは以下2つのサンプルデータを作る。
df_A =
@chain df begin
TidierData.@filter(AM == 0 && Cyl != 4)
TidierData.@distinct(Cyl) # 重複する行を削除するマクロ
TidierData.@select(Cyl, WT)
end
df_M =
@chain df begin
TidierData.@filter(AM == 1 && Cyl != 6)
TidierData.@distinct(Cyl) # 重複する行を削除するマクロ
TidierData.@select(Cyl, QSec)
end
println(df_A)
println(df_M)

TidierData.@left_join()
第1引数のデータフレームが主役。パイプライン処理で書く場合は、@chainの後に書くデータフレームということになる。
これに対して、第2引数のデータフレームを結合する。このとき、結合の基準となる変数を第3引数に指定する(ただし指定しなければ、勝手に重複している列名を検出してくれる)。
@chain df_A begin
TidierData.@left_join(df_M, Cyl) # df_Aに対して、変数Cylを基準にdf_Mを結合する
end
データフレームdf_Aには、df_Mだけが持つQsecという変数は存在しないので、この足りない変数が結合される。そのとき、両方のデータフレームにCyl == 8が共通しているので、この部分は数値が補完される。一方、主役たるdf_Aが持つCyl == 6は、df_Mには無いので、その部分を補完することができずmissingになる。

TidierData.@right_join()
第2引数のデータフレームが主役。そのためTidierData@left_join()とは逆に、df_Mが持たない変数WTが結合される。このとき、df_Mだけが持つCyl == 4は補完できずmissingとなる。
@chain df_A begin
TidierData.@right_join(df_M, Cyl)
end

TidierData.@inner_join()
第1引数のデータフレームに共通する基準変数のみ結合される。
@chain df_A begin
TidierData.@inner_join(df_M, Cyl)
end

TidierData.@anti_join()
第1引数のデータフレームだけが持つ基準変数のみ結合される。
@chain df_A begin
TidierData.@anti_join(df_M, Cyl)
end

TidierData.@anti_join()
第1引数、第2引数のデータフレームを、全ての基準変数について結合する。
@chain df_A begin
TidierData.@full_join(df_M, Cyl)
end

TidierData.@bind_***()によるデータフレームの結合
Rのrbind()やcbind()に相当。つまりデータフレームを、行方向または列方向にそのまま結合する。
TidierData.@bind_rows()による行方向の結合
df_A =
@chain df begin
TidierData.@filter(AM == 0 && Cyl != 4)
TidierData.@distinct(Cyl) # 重複する行を削除するマクロ
TidierData.@select(Cyl, WT)
TidierData.@mutate(row_num = row_number()) # 1スタートの連番の整数を付与
end
df_M =
@chain df begin
TidierData.@filter(AM == 1 && Cyl != 6)
TidierData.@distinct(Cyl) # 重複する行を削除するマクロ
TidierData.@select(Cyl, QSec)
TidierData.@mutate(row_num = row_number() + 2) # 1 + 2 = 3スタートの連番の整数を付与
end
@chain df_A begin
TidierData.@bind_rows(df_M) # 行方向に(つまり縦方向に)結合
end

TidierData.@bind_cols()による列方向の結合
@chain df_A begin
TidierData.@bind_cols(df_M) # 列方向に(つまり横方向に)結合
end

関連記事
宣伝
R言語でtidyverseによる一連の分析フローをまとめた『改訂2版 Rユーザのための RStudio[実践]入門 〜tidyverseによるモダンな分析フローの世界』という書籍を執筆しています。R版の本書の内容は、第3章により詳しく書いてありますので、よければご参照ください。
Discussion