Juliaでtidyverseを使う②~TidierData.jlによるデータ前処理:tidyr編~
本記事について
R言語で前処理や可視化などを効率的に行うことができるtidyverseパッケージ群をJuliaに移植した、Tidier.jlパッケージ群の解説記事シリーズ。
本記事では、Tidier.jlパッケージ群のうち、R言語のtidyr/dplyrパッケージに対応する、TidierData.jlを用いたデータ前処理について解説する。
公式にReferenceが提供されているので、ぜひそちらを直接参照していただきたい。本記事では一部の主要関数に限定して解説を行う。
TidierData.jlを使うモチベーション
別記事『Juliaでtidyverseを使う①~TidierData.jlによるデータ前処理:dplyr編~』を参照のこと。
TidierData.jlの関数・マクロたち
それでは以下に実例を示していく。まずはパッケージをインストールしよう。tidyverseパッケージ群のように、@Tidier.jlパッケージ群をインストールすることで、付属する種々のパッケージを一気にインストールできる。
ただしこれにはやや時間がかかるので、本記事を読むうえでは、TidierData.jlのみをインストールするのでもよい。
using Pkg
Pkg.add("TidierData")
using TidierData
なおRのtidyr/dplyrと同様に、TidierData.jlによる前処理も、原則的にパイプライン処理を利用した書き方をする。Juliaのパイプライン処理については他記事を参照のこと。
サンプルデータ
本記事ではRDatasets.jlの、mtcarsデータセットを利用する。これは32台の車両の性能(例:燃費、重量)を格納したデータセットである。
using RDatasets
@chain RDatasets.dataset("datasets", "mtcars") begin
first(_, 3) # 冒頭3行を表示
end
# TidierData.jlはChain.jlのラッパーなので、パイプライン処理ができる

説明の都合上、データセットの一部を抽出してデータサイズを小さくしておく(別記事『Juliaでtidyverseを使う①~TidierData.jlによるデータ前処理:dplyr編~』で解説した関数・マクロを使っている)。
df =
@chain RDatasets.dataset("datasets", "mtcars") begin
TidierData.@filter(Cyl == 6) # Cyl == 6の行のみ抽出
TidierData.@transmute(Model, # 車種名
MPG, # 燃費
WT, # 車体重量
AM = case_when(
AM == 0 => "Automatic", # オートマ車
AM == 1 => "Manual" # マニュアル車
)
) # 列を追加・上書きしながら、特定の列のみを選択
TidierData.@arrange(AM) # 列の水準を昇順に並び替え
end
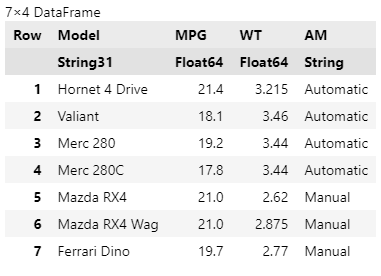
TidierData.@pivot_wider()による、long → wideデータへの変形
これはRのtidyr::pivot_wider()に対応する(なお後述するように、2023/12/22時点では全ての機能が移植されているわけではない)。
前述のようにサンプルデータフレームdfはtidy dataになっているので、すでにデータ分析において理想的な形式になっているのだが、用途に応じてwideデータに変形したいこともある。そのとき、TidierData.@pivot_wider()を用いる。
引数names_fromには、横方向に展開したい水準を持つ変数を指定する。引数values_fromには、wide展開したときに、それぞれの水準が新たな列となるので、その列にどの変数をデータとして格納するかを指定する。
以下のコードでは、変数AMの持つAutomaticやManualという水準がwide展開されて新たな列名となり、それぞれの列には変数MPGのデータが格納されている。例えば「Model名がMazda RX4の車両」はManual車なので、wide展開したときに、当然ながらAutomatic列のデータは欠測となる。そのため自動的にmissingと表示される。
df_wide =
@chain df begin
TidierData.@pivot_wider(names_from = AM, values_from = MPG)
end
println(df_wide)

もしmissing部分を一括で特定の値で埋めたければ、引数values_fillを用いる。
@chain df begin
TidierData.@pivot_wider(names_from = AM, values_from = MPG, values_fill = 100.0)
end

なお注意が必要なのは、longデータをwide展開する際に、各行を識別する変数が必要なことだ。今回は最初から、個別の車種名を持つ変数Modelがあるので、問題ない。しかしこの列を除外すると、上記のコードは動かない。
@chain df begin
TidierData.@select(!Model) # Model列を除外
TidierData.@pivot_wider(names_from = AM, values_from = MPG)
end
未実装機能
Rのtidyr::pivot_wider()には豊富な引数が用意されており、本来であればJulia移植後も以下のようなコードが実現されてほしい。この場合、Rであれば、wide展開後に作成される列はMPG.Automatic, MPG.Manual, WT.Automatic, WT.Manualの4列になる。が、2023/12/22時点では未実装なので、今後に期待。
@chain df begin
TidierData.@pivot_wider(names_from = AM, names_sep = ".", values_from = [MPG, WT])
end
ただ一応、色々工夫すれば、結果的には同じことは実現できる。ここは、前処理力が試されているということだろうか。
@chain df begin
TidierData.@mutate(AM = case_when(AM == "Automatic" => "MPG.Automatic",
AM == "Manual" => "MPG.Manual"),
AM2 = AM # AM列を複製
)
TidierData.@mutate(AM2 = case_when(AM2 == "Automatic" => "WT.Automatic",
AM2 == "Manual" => "WT.Manual")
)
TidierData.@pivot_wider(names_from = AM, values_from = MPG)
TidierData.@pivot_wider(names_from = AM2, values_from = WT)
end
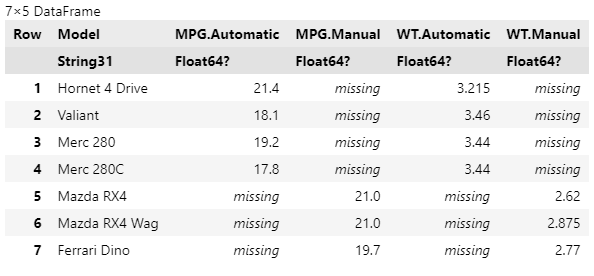
TidierData.@pivot_longer()による、wide → longデータへの変形
これはRのtidyr::pivot_longer()に対応する(やはり後述するように、2023/12/22時点では全ての機能が移植されているわけではない)。
wideデータを、機械処理しやすいようにlongデータに変形したいことはよくある。先に作成したwideデータのオブジェクトdf_wideをlongデータに戻してみよう。
TidierData.@pivot_longer()では、TidierData.@pivot_wider()と異なり、第2引数に処理対象の列を指定する。ここでの指定方法は、TidierData.select()のセマンティクスと同様なので、ヘルパ関数(TidierData.starts_with()など)を併用することもできる。
今回はAutomaticとManualという列名を、AMという新たに作成する列の水準にしたいので、names_toという引数に新たに作成する列名AMを指定する。
@chain df_wide begin
TidierData.@pivot_longer(Automatic:Manual, names_to = AM, values_to = MPG)
end

ここで、Model列に注目すると、同じ車種名が二度ずつ出現していることがわかる。もともとこのデータセットはlongデータであり、それをいったんwideデータにしたのち、longデータに戻しているのに、元通りになっていない。
今回は、もともと各車種のデータは1行ずつしかなかったので、MPGがmissingになっている行は、もともと存在しなかった行になる。よってこれらの行を削除すれば元通りになる。
@chain df_wide begin
TidierData.@pivot_longer(Automatic:Manual, names_to = AM, values_to = MPG)
TidierData.@drop_missing(MPG) # ある変数にmissingが含まれている場合はその行を削除
end
未実装機能(ついでにTidierData.@separate()/@unite()による水準の分離と結合)
Rのtidyr::pivot_longer()には豊富な引数が用意されており、やはりJulia移植後も同様の機能を使いたいが、2023/12/22時点では未実装なものも多い。
例えば以下のようなwideデータをTidierData.@pivot_longer()でlongデータに変形したとする。
using DataFrames # TidierData.jlはDataFrames.jlのラッパーなので、インストール済み
df_wide_2 = DataFrames.DataFrame(ID = [1, 2, 3],
control_A= [10.0, 10.5, 8.2],
control_B= [9.5, 10.2, 11.4],
experimental_A = [15.4, 14.1, 16.3],
experimental_B = [18.8, 17.6, 20.1]
)
@chain df_wide_2 begin
TidierData.@pivot_longer(contains("_"), names_to = condition, values_to = data)
end
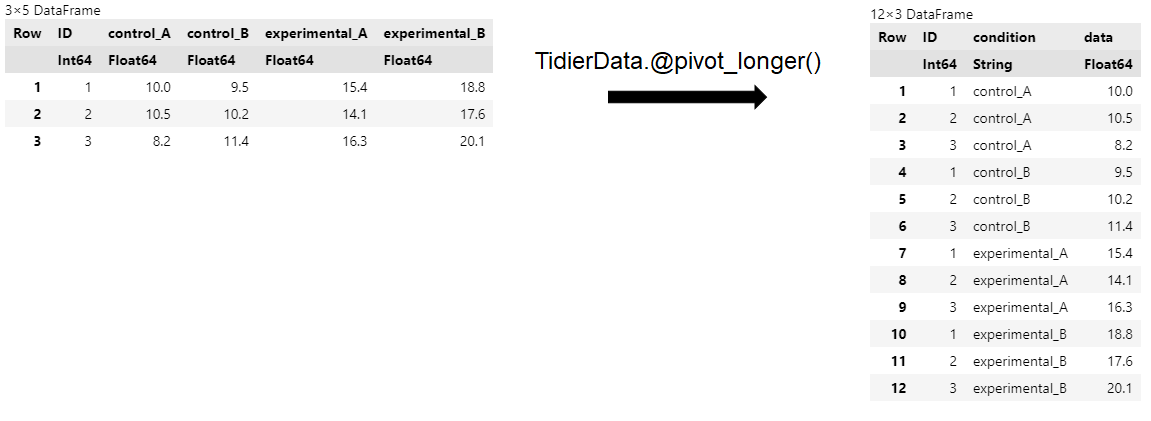
condition列には、control/experimentalの情報と、A/Bの情報が共存しているので、これらを識別する列(例えばcondition_CEとcondition_AB)を作ったほうがよい。
Rのtidyr::pivot_longer()なら、これを実現するための引数が用意されているのだが、2023/12/22時点で、TidierData.@pivot_longer()にはその機能はなく、恐らくTidierData.@separate()を併用して実現する必要がある。これはRのtidyr::separate()に対応する。
- 第2引数:分割する水準を持つ変数
- 第3引数:分割後のそれぞれの変数名
- 第4引数:分割する位置を示す文字列
df_sep =
@chain df_wide_2 begin
TidierData.@pivot_longer(contains("_"), names_to = condition, values_to = data)
TidierData.@separate(condition, [condition_CE, condition_AB], "_")
end
println(df_sep)

もし反対に、複数の変数に存在する水準を、行方向に結合した1つの変数を作成したければ、TidierData.@unite()を用いる。これはRのtidyr::unite()に対応する。
- 第2引数:結合に作成される新たな変数名
- 第3引数:結合対象の変数。
[]で配列にする - 第4引数:結合時に追加される文字列
@chain df_sep begin
TidierData.@unite(united_condition, [condition_CE, condition_AB], "+++")
end

欠測値処理
上で作成したdf_wideというデータフレームを利用しよう。一応、コードを再掲しておく。
df_wide =
@chain df begin
TidierData.@pivot_wider(names_from = AM, values_from = MPG)
end
TidierData.@drop_missing()による、特定の変数を基準としたリストワイズ削除
データフレームdf_wideにはAutomatic列とManual列に、異なる位置に欠測値missingが存在する。missingを含む行をリストワイズ削除したいとしよう。
DataFrames.jlのDataFrames.dropmissing()と同じはたらきを持つマクロがTidierData.@drop_missing()だ。
引数に何も書かなければ、1つでもmissingを含む行があれば全てリストワイズ削除される。もし引数に特定の変数を指定したら、その変数に関してのみmissingの有無が評価され、リストワイズ削除される。
@chain df_wide begin
TidierData.@drop_missing(Automatic) # Automatic列にmissingがあった場合のみリストワイズ削除
end
対象の列はTidierData.@select()のセマンティクスが使えるので、複数の列をカンマで区切って指定したり(例:TidierData.@drop_missing(Automatic, Manual) )、ヘルパ関数を用いて指定することもできる(例:TidierData.@drop_missing(starts_with("A")) )。
TidierData.@fill_missing()による、欠測値の補完
Rのtidyr::fill()に対応するマクロ。欠測値missingを、その変数に含まれる、missingの直前または直後の非欠測値で補完することができる。
データフレームdf_wideは、以下のパターンで欠測している。
-
Automatic列:missingより上に非欠測値がある -
Manual列:missingより下に非欠測値がある
欠測したい変数を列挙して、欠測を補完する方法を最後に指定する。
- 下から上方向に補完したいなら
"up" - 上から下方向に補完したいなら
"down"
以下のコードでは、上方向の補完を指定しているので、missingより下に非欠測値が存在するManual列は補完が成立しているが、Automatic列はmissingが最下部に固まっているので、補完できていない。
@chain df_wide begin
TidierData.@fill_missing(Automatic, Manual, "up")
end
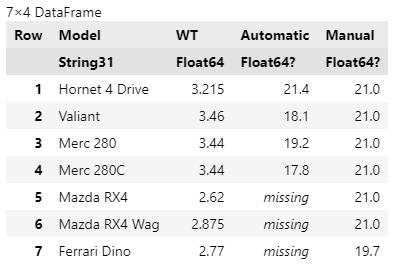
TidierData.@fill_missingは、TidierData.@group_by()などとも組み合わせられるので、グループごとにある方向で補完させる、ということもできる。
TidierData.replace_missing()による、欠測値の補完
Rのtidyr::replace_na()に対応。なお、TidierData.replace_missing()はマクロではなくメソッドなので、「@」は付けない。他の関数やマクロの中でのみ動作する。
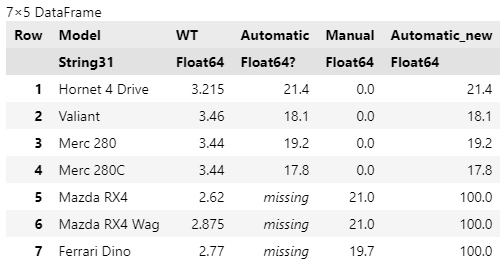
変数ごとに、その変数に含まれるmissingを、特定の値で置換できる。以下のコードでは、Automatic列の欠測を100.0で置換した新たな変数Automatic_newを作成している。また、既存のManual列の欠測を0.0で置換している。
@chain df_wide begin
TidierData.@mutate(Automatic_new = replace_missing(Automatic, 100.0),
Manual = replace_missing(Manual, 0.0)
)
end
TidierData.missing_if()による、欠測値の補完
欠測値補完とは逆に、特定の条件を満たすセルをmissingにする。やはりTidierData.missing_if()はマクロではなくメソッドなので、「@」は付けない。他の関数やマクロの中でのみ動作する。
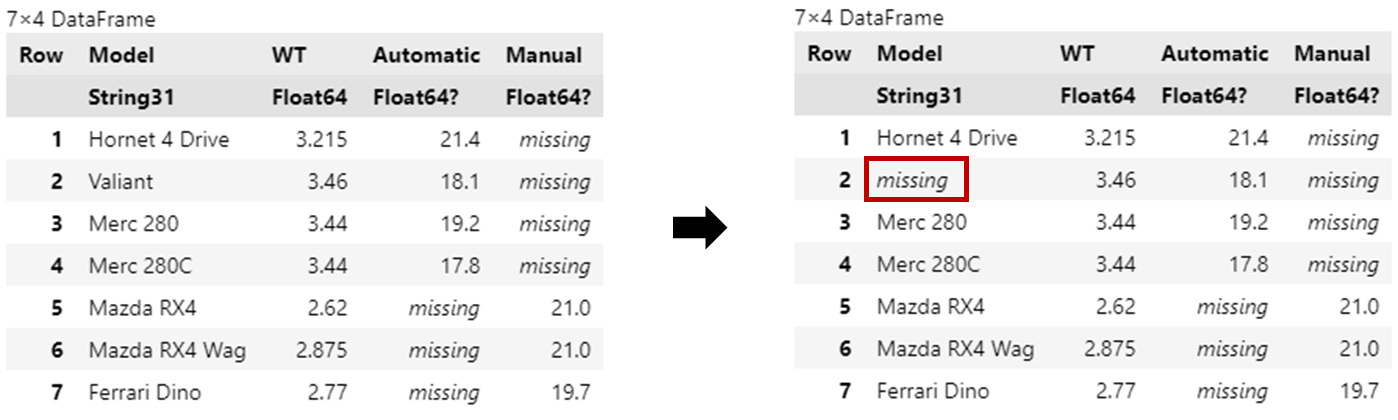
以下のコードでは、Model列に"Valiant"という車種が存在したらmissingにするよう指示している。
@chain df_wide begin
TidierData.@mutate(Model = missing_if(Model, "Valiant"))
end
関連記事
宣伝
R言語でtidyverseによる一連の分析フローをまとめた『改訂2版 Rユーザのための RStudio[実践]入門 〜tidyverseによるモダンな分析フローの世界』という書籍を執筆しています。R版の本書の内容は、第3章により詳しく書いてありますので、よければご参照ください。
Discussion