Goで開発して3年のプラクティスまとめ(2/4): cliアプリをつくれるところまで編
Goで開発して3年のプラクティスまとめ(2/4): cliアプリをつくれるところまで編
yet another入門記事です。
- part1 プロジェクトを始めるまで編
- part2 cliアプリをつくれるところまで編: これ
- part3 concurrent GO編
- part4 HTTP server/logger編
ご質問やご指摘がございましたらこの記事のコメントでお願いします。
(ほかの媒体やリンク先に書かれた場合、筆者は気付きません)
Overview
ほかのライブラリをインポートしてcliの呼び出し口を整えてツールを作れるところまでを目指します。
筆者がGoを書き始めて、A Tour of Goが終わった直後(つまりGoを初めて触りだしてから5時間あとあたりでしょうか)に社内というかチーム内でのみ使う小さなサーバープログラムをいきなり作り出したことがあるんですが、その時いろんなことがわからなくて困りました。
特に、
- エラーハンドリング周り
-
io.Reader/io.Writerを要求してくる関数群に対して何を渡したらいいのか -
jsonの読み書きのAPIのノリ -
cliフラグの取り方 - 環境変数とのインタラクション
エラーハンドリングを除くと、http serverを書くとき、というかcliツールを作るときに使う諸般のもろもろのツールの様式がわからなくて困りました。
ググって出てくるのもは古い内容のものも多かったりしたんですが、古いことに気付かず困りました。エラー周りはGo1.13、Go.1.20で結構変わったのでその辺も拾っておきます。
この辺のブロッカーを取り除けば心理的に楽にGoを書きだせるのではないかということで以下の順番で書いていきます。
- エラーハンドリング
- 慣習、
errors.Is/errors.As,panic-recoverについて
- 慣習、
- ファイル読み書き
- data marshaling(jsonとxml)
- html以外でxmlの読み書きは最近だと比較的少なくなってると思うからxmlは比較的力を入れずに
- cli flags
- stdのflag
- github.com/spf13/cobra
- environment variable
2種の想定読者
記事中では仮想的な「対象読者」と「ベテランとして取り扱われるその他の読者」が想定されています。
対象読者
記事中で「対象読者」と呼ばれる人々は以下のことを指します。
- 会社の同僚
- いままでGoを使ってこなかった人
- ある程度コンピュータとネットワークとプログラムを理解している人
- pythonとかNode.jsで開発したことある
- gitは使える。
- 高校生レベルの英語能力
- 作ってるところがアメリカ企業なので英語のリンクが全般的に多い
part1以降はA Tour of Goを完了していることと、
ポインター、メモリアロケーション、POSIX(もしくはLinux) syscallなどの基礎的概念がわかっていることが前提条件になっています。
そのほかの読者
特に断りがない時、他の読者も聴衆として想定されます。
- 筆者と同程度かそれ以上に
Goに長じており - POSIX APIや通信プロトコル、他のプログラミング言語でよくやられる方法を知っている
というベテラン的な人々です。
記事中に他にいい方法があったら教えてくださいとか書いてますが、大概はこのベテランな人たちに向けて書いているのであって、対象読者は当面気にしないでください(もちろんあったら教えてください)。
対象環境
- 下層の仕組みに言及するとき、特に述べない限り
linux/amd64を想定します。 -
OS/archに依存するコードは書きません。
version
検証はgo 1.22.0、リンクとして貼るドキュメントは1.22.3のものになります。
# go version
go version go1.22.0 linux/amd64
最近追加されたAPIをちょいちょい使うので1.22.0以降でないと動かないコードがたくさんあります。
直近の3~4 minor versionのみサポートするライブラリが多いとして、Go 1.18でできなくてそれ以降できるようになったことは、○○以降となるだけ書くようにします。
サンプルコードのrepository
サンプルコードの一部は下記にアップロードされます。
error-handling
Goにはtry-catchのような構文や、Result<T, E>のようなtagged union typeのようなものは現状存在しません。(sum typeのproposalは長く存在する)
代わりに、Goでは多値返却で、ソース順で最後の返り値の型をerrorとすることでエラーしうる処理を表現し、その値をチェックすることでエラーハンドリングを行います。
この節では、対象読者がまず気にするであろう、どうやってエラーをハンドルするかについて先に述べ、エラーの組み立て方、errors.Isやerrors.Asの内部的な挙動について述べます。その後、独自エラー型を定義するときの注意点やtry-catch的なpanicの使い方について述べます。
error != nilならほかの返り値は使わない
タイトルのような慣習(というべきなのかよくわかりませんが)があります。
-
err == nilならば、ほかの返り値は使ってもよい- interfaceはnon-nilだし、
- pointer type
*Tはnon-nilだし、 -
Tは(それがふさわしければ)non-zeroである - (ただしスライス
[]Tがnilなことは比較的普通かも・・・)
-
err != nilなら、ほかの返り値は基本使ってはいけない-
err != nilでも返り値を使ってよいとドキュメントされていることもある- e.g.
io.Readerがn > 0, io.EOFを返してくることがある
- e.g.
-
Goは多値返却で複数の値を返し、ソース順で最後の返り値の型がerrorであることで、エラーしうる処理を表現します。
func failableWork(...any) (ret1 io.Reader, ret2 *UltraBigBigData, err error)
func foo() error {
ret1, ret2, err := failableWork()
if err != nil {
// ret1, ret2は普通はzero value, この場合はnilなので、
// ret1.Readを呼ぶとnil pointer derefでパニックする
return err
}
// この時点ret1, ret2は普通はnon-nilな値であり、
// メソッドよんだり、pointer derefするなりしても安全。
// ret1, ret2を使って何かする
return nil
}
逆に言うと、あなたの書く関数もerr == nilの時にnil pointer derefが起きるような値を返してはいけません。
errorを判別する
err != nilでエラーなことはわかるけどどういうエラーなのかを判定したときは多くあります。
ファイルを開くのがエラーしたとき、ENOENTなのかEPERMなのかぐらいは最低でも知らないとハンドルできないですよね。
- エラーは基本的に、特定の値(pointerなど)で特定できるものと、型で特定できるものがある
- e.g. 値 => io.EOF, net.ErrClosed, (os/exec).ErrNotFoundなど
- 型 => *(encoding/json).SyntaxError, *(io/fs).PathError
- 取り合えずerrors.Is, errors.Asを使っておけばよい
err == target / err.(T)
ラップされていないエラーはerr == target(比較)やerr.(T)(type assertion)で判別可能です。
もしくはswitch x := err.(type) {}(type-switch)でも同様のことができます。
if err == io.EOF {
// EOF
}
syntaxErr, ok := err.(*json.SyntaxError)
if ok {
// syntaxErrorでエラー箇所のOffsetがわかるので、
// データソースのr io.Readerが、io.Seekerも実装しているとき
// seek backして前後をプリントしてみるとかできますね。
_, err := r.Seek(syntaxErr.Offset, io.SeekStart)
// ...
}
// type-switchでも可
switch x := err.(type) {
case nil:
fmt.Println("x is nil")
case *json.SyntaxError:
// このブランチではxは*json.SyntaxError型
_, err := r.Seek(x.Offset, io.SeekStart)
}
// 前述の例で行くと、Openのエラーの判定はこうなる。
_, err := os.Open("/nonexistent")
pathErr := err.(*os.PathError)
if pathErr.Err == syscall.ENOENT {
fmt.Printf("ENOENT: %#v\n", pathErr)
}
ただしエラーはほかのエラーにラップされることがよくあるため、この方法では判別できないことも多々あります。例外はio.EOFのようなsentinel valueとして使われるエラーのみです。
errors.Is / errors.As
Go 1.13(2019-09-03以降)から、stdの範疇でエラーのラッピング/アンラッピングの概念が追加されました。
- エラーがラップされている可能性がある場合は
-
err == target(比較)の代わりにerrors.Isを使います -
err.(T)(type assertion)の代わりにerrors.Asを使います
-
基本に常にerrors.(Is|As)を使っておけばよいです。
var (
err1 error
// Wrapping error so that you can't use comparison / type assertion.
err2 error = fmt.Errorf("decoding p1: %w", &json.SyntaxError{Offset: 19})
)
func init() {
_, err1 = os.Open("/nonexistent")
err1 = fmt.Errorf("opening config: %w", err1)
}
func main() {
// 実はerrors.Is(err, fs.ErrNotExist)でENOENTの判定になる。
if err1 != fs.ErrNotExist && errors.Is(err1, fs.ErrNotExist) {
fmt.Printf("err1 matched\n") // err1 matched
}
var syntaxErr *json.SyntaxError
_, ok := err2.(*json.SyntaxError) // ラップされているのでtype assertionはfalseを返す
if !ok && errors.As(err2, &syntaxErr) {
// errがある型Tであるかを判別したいとき、
// 呼び出し側で`var t T`で変数を定義し&TでAsに渡す
// AsはerrがTか、それをラップしたものであるならば、渡された変数にエラーを代入し
// trueを返す
fmt.Printf("err2 matched, err = %#v\n", syntaxErr) // err2 matched, err = &json.SyntaxError{msg:"", Offset:19}
}
}
エラーのラッピングとerrors.Is, errors.Asの内部挙動
-
Go 1.13より、エラーは情報を追加してしてラップできます
- もっとも簡単な方法は
fmt.Errorfで%wverbを使うことです。- e.g.
fmt.Errorf("creating table: want = %v, got = %v: %w", want, got, errMaybeIo)
- e.g.
- ラップされたエラーは
errors.Is(err, io.EOF),errors.As(err, &jsonSyntaxError)のような形で、比較されたり取り出されたりします。
- もっとも簡単な方法は
-
errors.Isとerrors.Asは- 単純に比較可能で同一(
Is)/代入可能(As)であれば、trueを返して終了する - 与えられた
errがそれぞれ以下を実装するとき、まずそれらのメソッドを呼び出してtrueを返すかチェックする-
Is:interface { Is(error) bool } -
As:interface { As(any) bool }
-
-
errがinterface { Unwrap() error }またはinterface { Unwrap() []error }(Go 1.20より)を実装していれば、Unwrapして深さ優先で探索。
- 単純に比較可能で同一(
fmt.Errorfを使うと手軽にエラーにメッセージを追加したり、複数のエラーをまとめることができます。
// ラッピング
return fmt.Errorf("making config: %w", err) // config 作成中にファイル読み込みとか書き込みが失敗したとかそういうエラーの場合
// 複数エラーをまとめることもある
return fmt.Errorf("%w: %w", ErrInvalidParam, err)
ラップされたエラーはerrors.Isなどがアンラップして判別に使うことができます。
if errors.Is(err, ErrInvalidParam) {
// err == wrapped ErrInvalidParam.
}
もちろん、ユーザーが直接interface { Unwrap() error }実装をチェックすることでアンラップすることもできます。
以下がerrors.Isとerrors.Asとfmt.Errorfのソースです。説明するより読んでもらったほうが早かったかもしれませんね。
(errors.Isはunwrapしてis関数を再帰的に呼び出している)
(errors.Asはunwrapしてas関数を再帰的に呼び出している)
fmt.Errrofは%wが使われているとUnwrapを実装したエラーでラップします。
見てのとおり%wが複数あればinterface { Unwrap() []error }を実装した型にラップします。
errorを組み立てる
逆に、パッケージとしてエラーを定義してexportする側の視点では、
- 単にエラーの種類がわかればよいだけの時は
errors.Newで値のエラーを作る-
fmt.Errorfでもよい
-
-
errorを実装する型を定義するのは以下のような時- シンプルなテキストじゃ足りない
- あとからエラー時のパラメータを取り出したい
-
errors.Isやerrors.Asで呼び出されるときの挙動をカスタマイズしたい - ほかのシステムからくる値だが、
errorとしてそのままマップできる- e.g. Errno
- その他そうするのが最も便利な方法なとき
- 他の関数の返り値のエラーを
fmt.Errorfでラップして、メッセージを追加して、人が読みやすくして返す。- ラップしないで返すこともある。ラップしたほうが丁寧。
- stacktraceがないので、ラップしないとどこで起きたエラーなのかよくわからなくなることはたびたびある(n敗)
- 渡す文字列の変更は破壊的変更とみなされることがある。
- 返されたエラーの
err.Error()を呼ぶとプリントされた文字列が観測できる - コードによってはこれによって、if文を分岐させていることがある。
-
dockerの内部コードを見るとwindowsが吐くエラーのerr.Error()をみてエラー文言を変えていたりする
-
-
errors.New()で作った値をラップしたエラーを返すほうがいいケースのほうが多い。-
Err...な値がexportされていないと、コードを読んでエラーメッセージを探してstrings.HasPrefix(err.Error(), "not found")みたいなコードを書くことになってつらい。
-
- 返されたエラーの
- ラップしないで返すこともある。ラップしたほうが丁寧。
// 値としてエラーをexportしておくと、パッケージ外から使用するコードは、
// errors.Is(err, ErrSomething)を利用して、エラーの判別が行える。
var (
ErrSomething = errors.New("something")
// effectively same
ErrOther = fmt.Errorf("other")
)
// パッケージ内でしか使わないときにexportしないことは普通にありうるだろう
var (
errNay = errors.New("nay")
)
var _ error = (*MyError)(nil)
type MyError struct {
Param1 string
Param2 int
Raw error
}
// Tがuncomparable、もしくはinterface valueを持つstructならば
// Errorメソッドは*Tが実装する。
//
// nil guardがないのでtyped-nilに対して`Error()`を呼ばれるとパニックするが
// 体感上困ることはほぼない。
func (e *MyError) Error() string {
return fmt.Sprintf(
"my error: param = %s, %d, raw = %v",
e.Param1, e.Param2, e.Raw,
)
}
func (e *MyError) Unwrap() error {
return e.Raw
}
_, err := funcProvidedByOtherPkg()
if err != nil {
return fmt.Errorf("doing some: %w", err) // ラップしておく
}
if someCond {
// errors.New()で作為性してexportした値を
// ラップして返すとerrors.Isで判定ができる
return fmt.Errorf("%w: describe sub cause", ErrSomething, values...)
}
interface { Is(error) bool }の実装例
errors.Isはerrがinterface { Is(error) bool }を実装していると、その実装を優先して使用します。
ではどういうときに実装すべきでしょうか?
例えば以下が考えられます
- 複数の値に対して
Is() == trueにしたい -
[]Tのようなcomparableではない値同士の比較 - (time.Time).Equalのように、値は一致しないけど意味的には一緒というのが表現したい
具体例として、前述したErrnoを示します。
osパッケージの各種関数が返すエラーでerrors.Is(err, fs.ErrNotExist)が機能するのはErrnoにIsが実装されているからです。
(unix版)
(windows版)
oserrorとは何でしょうか?
これらの値の参照をたどると以下で出てきます。
osパッケージで使うと書いているのはどういうことかというと
という感じでプラットフォーム間/API間でエラーを同一扱いするためにこういうことをしているようです。
interface { As(any) bool }の実装例
errors.Asはerrがinterface { As(target any) bool }を実装していると、その実装を優先して使用します。
As() == trueの時、targetにはerrが代入されていなければいけません。
AsのほうがIsに比べて複雑なので、実装する機会もさらに少ないかもしれません。
ではどういった時実装すべきでしょうか?
おそらくIsと同じく、
- 複数の型に対して変換をかけながら代入したい
- 内部的に意味のない値をドロップしたうえで代入したい
みたいな感じかと思います。
具体例を挙げます。std内では以下のhttp2StreamErrorが(おそらく)唯一の実装者です。
Asの実装は以下です。
reflectを使って、targetに自身が代入可能か判別し、代入可能であるときはtargetの各フィールドに代入を行っています。
対象読者的にはreflectが何かわからないと思います。Node.jsもといjavacsriptにもReflectがありますが、多分使うことは非常にまれなので使ったこと自体がないか存在すら知らなかったのではないかと思います。
reflectはGoコードを書いてできることのおおよそすべてをランタイムに動的に行うことができる機能群のことです。動的にstructの定義を行ったり、sliceのappendや複数のchannelをselectしたりできます。
struct tagなど通常のGoコードからはアクセスできない一部のメタデータへのアクセスもreflect経由で行います。
実際上記コードではtargetの型がhttp2StreamErrorの構造と一致するかテストしたうえで代入していますね。
中途状態が書き込まれてしまわないようにまずすべてのフィールドに代入可能なことをチェックしてから実際にSetで代入しています。
ConvertibleToを使っていることのポイントは、ほぼ同一構造で変換可能な型で構成されるstructに代入できるようにすることでしょう。
つまり、Asは以下のような別のstructに対してもtrueを返します。
(実際に代入可能であることはplaygroundで確認してください。)
type fakeHttp2Err struct {
StreamID int // `uint32`や`http2ErrCode`の代わりに`int`を使っていることがポイントです。
Code int
Cause error // optional additional detail
}
func (e fakeHttp2Err) Error() string {
return "fake"
}
ただfunc (e *fakeHttp2Err) Error() stringとしまうと、errors.Asには**fakeHttp2Errを渡すことになりますが、http2StreamErrorのAs実装はそのケースを無視しているので**fakeHttp2Errに対しては常にfalseを返してしまいますね。
*T, **T両方に対応するためには以下のように変更します。
func (e http2StreamError) As(target any) bool {
- dst := reflect.ValueOf(target).Elem()
+ dstOrig := reflect.ValueOf(target).Elem()
+ dst := dstOrig // T or *T
dstType := dst.Type()
+
+ needSet := false
+ if dstType.Kind() == reflect.Pointer {
+ // *T
+ dstType = dstType.Elem() // T
+ if dst.IsNil() {
+ needSet = true // needs allocation but deferred until needed.
+ } else {
+ dst = dst.Elem() // T, addressable
+ }
+ }
+
if dstType.Kind() != reflect.Struct {
return false
}
src := reflect.ValueOf(e)
srcType := src.Type()
numField := srcType.NumField()
if dstType.NumField() != numField {
return false
}
for i := 0; i < numField; i++ {
sf := srcType.Field(i)
df := dstType.Field(i)
if sf.Name != df.Name || !sf.Type.ConvertibleTo(df.Type) {
return false
}
}
+
+ if needSet {
+ // newly allocated value, mutating dst is not gonna propagate to `target`.
+ dst = reflect.New(dstType).Elem()
+ }
+
for i := 0; i < numField; i++ {
df := dst.Field(i)
df.Set(src.Field(i).Convert(df.Type()))
}
+ if needSet {
+ dstOrig.Set(dst.Addr())
+ }
return true
}
任意の同一構造のstructを受け付る気があるならこういう感じで*U/**U両対応が必要です。
対象読者がただちにこういった実装が必要になるかはわかりませんが、こういう気遣いがいるかもしれないことは覚えておくといいかもしれません。
errorはTか*Tのどちらが実装すべきか?
(comparableとは何ぞやというのは後述)
- 基本的には
*T。特に:- underlying typeがuncomparableなとき
- fieldにinterfaceを含むとき
-
Tのほうがいいかもしれないときもある:- underlying/base typeがcomparableな組み込み型
-
bool、int/uintvariants、float、complex、string、[n]T - e.g.
Errno
-
- underlying/base typeがcomparableな組み込み型
あるnon-pointer typeのTがレシーバのメソッドは*Tの場合でもinterfaceを満たす条件に使うことができます。
Tにerrorを実装してしまうと返ってくるエラーがT,*Tの両方がありえてしまいます。
そうなっているとerrors.Asでエラーを判別するときT, *T両方チェックが(理屈上)必要になるため困ってしまいます。
つまり以下のようなこと起こります
type nonPErr struct{}
func (e nonPErr) Error() string {
return ""
}
type pErr struct{}
func (e *pErr) Error() string {
return ""
}
var _ error = nonPErr{}
var _ error = (*nonPErr)(nil)
/*
./prog.go:18:15: cannot use pErr{} (value of type pErr) as error value in variable declaration: pErr does not implement error (method Error has pointer receiver)
*/
// var _ error = pErr{}
var _ error = (*pErr)(nil)
pErr型は*pErrでなければerror interfaceを満たしません。このエラーを取り出したいときはerrors.Asで*pErrだけをチェックすればよいことになります。
また、errorを実装する型がuncomparableである場合、以下のようにエラー同士を比較されてパニックすることがあり得ます。
package main
import (
"errors"
"fmt"
"io"
"strings"
)
type uoncomparableError []string
func (e uoncomparableError) Error() string {
return strings.Join(e, ", ")
}
func main() {
err1 := error(uoncomparableError([]string{"foo", "bar", "baz"}))
err2 := error(uoncomparableError([]string{"mah"}))
fmt.Println(err1) // foo, bar, baz
if err1 != io.EOF {
fmt.Println("this works fine")
}
if !errors.Is(err1, err2) {
fmt.Println("this works fine too but...")
}
if err1 != err2 {
// this panics
/*
panic: runtime error: comparing uncomparable type main.uoncomparableError
goroutine 1 [running]:
main.main()
/tmp/sandbox1037648224/prog.go:26 +0x1ad
*/
}
}
これはなぜかというと、Goのspecificationのcomparison operatorsの項目に説明される通りで
A comparison of two interface values with identical dynamic types causes a run-time panic if that type is not comparable.
だからなのです。
slice / map / function / uncomparableな型のフィールドを含むstructはuncomparable, それ以外はcomparableです。
uncomparableな型同士の比較(a == b)はコンパイルエラーなので、ランタイムでこの状況に陥ることはありません。
しかしinterfaceは中身はなんであるかruntimeまでわかりませんし、a == bはエラーする可能性を表現できませんので、比較できない場合パニックするよりほかありません。
一方で、io.EOFのような既知のcomparableな値との比較は安全です; io.EOFの中身はpointerなので比較可能な型です。
ただ、このように型が一致していてなおかつuncomparableであるというパターンは、例えばユーザーにとって中身のわからないエラー同士を比較するなどしない限りありえませんので、そう多く発生するケースではないと思われます。
ただ何かの理由でエラー同士の比較が行われないとは限らないので、避けておくに越したことはないでしょう。
以下のように変更すればパニックしません。
type uoncomparableError []string
-func (e uoncomparableError) Error() string {
+func (e *uoncomparableError) Error() string {
return strings.Join(e, ", ")
}
func main() {
- err1 := error(uoncomparableError([]string{"foo", "bar", "baz"}))
- err2 := error(uoncomparableError([]string{"mah"}))
+ e1 := uoncomparableError([]string{"foo", "bar", "baz"})
+ err1 := error(&e1)
+ e2 := uoncomparableError([]string{"mah"})
+ err2 := error(&e2)
fmt.Println(err1) // foo, bar, baz
if err1 != io.EOF {
fmt.Println("this works fine but...")
}
pointerはcomparableだからです。アドレス値同士の比較になります。
よくよく読み直してみるとA Tour of Goの中で、基本的にmethod receiverはTか*Tの片方にすべきという言及がありますね。
独自エラー型を返す時はtyped-nilに注意する
stdを含めて、多くのライブラリが自らが定義したエラー型を返り値の型に使うことはなく、error interfaceで返すことが多いです。
func failableWork() (any, *MyError) // ではなく
func failableWork() (any, error) // となっていることが多い。
// たとえ、実際には`&MyError{}`を返しているときでも。
それはなぜなのかというと
- error型に変換するときのtyped nilの可能性
-
func() (any, error)なinterfaceを満たせない - 後方互換性のために、その関数が返す型を追加したり変えたりできなくなる
後者二つはまあそのままなので分かると思います。
問題はtyped-nil、つまり以下のような現象が起きます。
func myTask() (someResult string, err *MyError) {
return "ok", nil
}
func someTask() (string, error) {
ret, err := myTask()
return ret, err
}
func main() {
ret, err := someTask()
if err == nil {
fmt.Println("success")
} else {
fmt.Println("failed") // failed
}
fmt.Printf("ret = %s, err = %#v\n", ret, err) // ret = ok, err = (*main.MyError)(nil)
}
この場合、以下のように変更すれば、nilがプリントされます。
func someTask() (string, error) {
ret, err := myTask()
+ if err != nil {
+ return ret, err
+ }
- return ret, err
+ return ret, nil
}
型のある値をinterfaceに代入すると結果は常にnon-nilになります。
つまり上記はこういう状態です。
var err error = (*MyError)(nil)
*MyErrorという型情報を持つ、具体的な値がnilのvar err errorということになります。
method receiverが*MyErrorなので、receiverにnilを渡して関数を呼び出しても普通に動作することがあり得ます(stdの中でもちょいちょいある)。
このためerrがnon-nilなのは妥当というか、non-nilでなければ困るということになります。
つまり、こうしてもいいわけじゃないですか
func (e *MyError) Error() string {
// describe root cause of an error.
+ if e == nil {
+ return "myerr"
+ }
return fmt.Sprintf("myerr: param1 = %q, param2 = %d", e.Param1, e.Param2)
}
むしろnilのようなリテラルが untyped だということは強調しておくべきでしょう。
typed nilはerrorに限らずinterfaceで型を指定した値に、具体的な型を代入するときは常に気を付ける必要があります。
このtyped-nilが起きるかもしれない危険性を不用意にパッケージ/モジュールの使用者に露出させる必要がない場面が多いため、基本的にerrorを返すのだと思われます。
特に(*MyError)(nil)が妥当なのかは関数シグネチャからはわからないと思いますので、ありえちゃだめならそもそも返ってこないのがよいのだと思います。
panic
組み込み関数のpanicを呼び出したり、sliceやarrayのout of index access, nil pointer derefなどが行われるとpanicが起きます。
quoted from https://go.dev/ref/spec#Run_time_panics
Execution errors such as attempting to index an array out of bounds trigger a run-time panic equivalent to a call of the built-in function panic with a value of the implementation-defined interface type runtime.Error.
quoted from https://go.dev/ref/spec#Handling_panics
Two built-in functions, panic and recover, assist in reporting and handling run-time panics and program-defined error conditions.
panicが起きるとその行から通常のプログラム実行が止まり、
スタックを巻き戻しながらdeferに登録された関数があれば登録されたのと逆順で実行していきます。
ある関数Fのなかでdeferされた関数がrecoverを呼ぶと、Fを呼び出すGから通常の関数実行の順序に戻ります。
func() {
defer func() {
if rec := recover(); rec != nil {
fmt.Printf("panicked = %#v\n", rec) // panicked = runtime.boundsError{x:6, y:4, signed:true, code:0x0}
}
}()
var a [4]int
var b []int = a[:]
_ = b[6] // index out of range!
fmt.Printf("this line can not be reached\n")
}()
fmt.Printf("back to normal execution order.\n")
recoverされずにpanicがgoroutineを終了させるとプロセス全体がエラー終了します。
// つまりこうすれば確実にプロセスを殺せます
go func() { panic("die!") }()
try-catch-finallyで例えると、deferがfinally、recoverがcatchだといえます。
と、こう書くとpanicは基本的にrecoverされない究極的なエラー終了手段かのように聞こえるかもしれません、実際上は*http.Serverがrecoverしてしまうので逆に基本的にrecoverされるものと思ったほうが良いです。もちろん100%挙動をコントロールできるシチュエーションでは別ですが、例えば*http.Serverを使わずにhttp serverを実装することは少ないと思いますし、Goを書いていてhttp serverを実装しないことも結構珍しいと思います。
https://pkg.go.dev/net/http@go1.22.3#Handler
If ServeHTTP panics, the server (the caller of ServeHTTP) assumes that the effect of the panic was isolated to the active request. It recovers the panic, logs a stack trace to the server error log...
panic時にプロセスが強制終了されてほしいとき、*http.Serverを使うプログラムの場合、ユーザーが自ら特別な措置を実装する必要があります。
つまりこころもちとしては
-
panicを意図的にする場合は- 意図的にrecoverし、意図しないpanicはre-panicする
- もしくは、プロセスは異常終了すべき
- 一方で
panicはコントロールしていないエリアで勝手に拾われるのは当然起こる
と思っているといいという感じです。
前述通り、そのgoroutineでpanicした時は通常の関数実行順序をやめ、deferに登録されている関数を登録の逆順で実行してきます。
つまりリソース解放処理は必ずdeferでしなければ、コントロールしていないコードによってrecoverされ、静かに不正状態に陥る可能性があります。
- リソース解放処理は必ず
deferで行おう-
sync.MutexのUnlock -
*os.FileのClose - 何かのカウントをincrementしたときのdecrement
-
sync.WaitGroupのDone
-
-
Goはすべてのgoroutineが眠りにつくとdeadlockであるとして、プロセスを終了してくれるガードが入っていますが、*http.Serverがコネクション待ちに入ってる状態はdeadlockに見えないはずなので、エラーしないのに動かない状態になるはずです。
もしくはrecoverされたくないならgo panic("panic cause")とわざとするとよいかもしれません。
ただし、panicがgoroutineを終了させたときの強制終了処理は他のgoroutineのdeferを呼び出しませんので、リソース解放処理をあてにしたプログラムが不正な中途状態を書き出すような場合は、それがプロセス終了後に観測されてしまいます。
できれば、あらゆるgoroutineで起きたpanicはrecoverで拾ってpanicしなおして、拾って・・・というのを繰り返してmain goroutineまで伝搬させたほうがいいでしょう。
main goroutineでpanic時のエラーログなどを書きだしてすべてのgoroutineを終了させるなどすると穏当にプロセスを終了させられます。
どのようにpanicを伝搬させるかはGoが勝手に判断できるタイプの仕事ではないのでユーザーが意図的に行う必要があります。
とはいえ、電源断(power outage / power failure, 停電など)の恐れがあるようなシステムではリソース解放が漏れなくても電断でおかしな状態になりうるので、
どちらにせよ回帰する方法がプロセス起動時に呼ばれなければなりません。
try-catch的に使われるpanic-recover
panicを使うとdeferされた関数以外を無視して一気に脱出ができるのでもちろんtry-catch的に使うこともできます。
Effective Goにtry-catch的panic-recoverの使い方が述べられています。
ポイントは以下になります
- 特定の値/型で
panicすることで処理をabortする - パッケージをまたいでpanicが伝搬しないように公開関数/メソッドでは必ずrecoverする
- 意図した型以外でのpanicははre-panicする
実際の*http.Serverはhttp.ErrAbortHandlerをsentinel valueとして、handlerをabortするためのpanicができるようになっています。
ちなみに筆者はtry-catch的panicを使ったことはありません。
std library内で使われるtry-catch的panic-recover
実際std内でも上記のようにpanicがthrow的に使われています。
encoding/json内では以下のようにpanicをthrow的に使っています。
少なくとも https://codereview.appspot.com/953041 のころからそうなので14年前(2024年現在)からずっとこんな感じでした
encoding/gob内でも同様の使い方がされています。
fmtやlog/slogはロジック中でpanicするわけにいかないのでrecoverしていますね
それ以外だとanyな値の比較のところでrecoverしていますね。
stacktraceはついてないのでほしいならライブラリを使う
Goのstd libraryはstacktraceの付いたエラーを返してくることがないため、慣習的にエラーにはstacktraceがついていないのが普通です。
stacktraceをつけたいなら以下のライブラリそのものを使うか、でなければ実装を参考に自分でエラー型を定義するとよいでしょう。
stdのエラーが全般的にstacktrace情報を含んでくれればと思うのですが、
- 現状のエラーがstacktraceを含まず、
-
strings.Contains(err.Error(), "...")でエラーの判別をするコードが存在し、 - 同様に
fmt.Sprintf("...", err)で文字列をくみ上げるコードも存在する
ので、暗黙的に既存コードから帰ってくるエラーにstacktraceを持たせる変更は破壊的変更となります。
io.EOFのようにsentinel valueとしてふるまうエラーが普通にあり得てしまうため、そういったものに勝手にstacktraceをつけてしまうとパフォーマンスに影響することも考えられます。
そのため、既存の挙動を全く破壊せずにstacktraceを取り出す方法が実装されない限り、入れる意味がないのでstdのコードがstacktraceを含むエラーを返してくることはないでしょう。
自分向けのざっくり作ったツールほどエラーのメッセージを丁寧にラップしないので、そういうときこそstacktraceが欲しいですね。
エラーメッセージをさぼって、後になってどこで起きたのかわからないエラーが吐かれて慌ててエラーのラップを整備しだすんですよね(n敗)。
おそらく近いうちにどうこうなる話題ではないので、必要であればエラーにstacktraceを追加するライブラリを使用するのがよろしいかと思います。
ファイルを開く、コピー
ファイルの読み書きはとりあえず必要なトピックになると思うので書きます。
簡単のためにサンプルコードのエラーハンドリングはすべてpanicになっています。
io APIの特徴
対象読者にとってファイルの読み書きと言えばと言えば
- Node.js: fs.promises.readFile / fs.promises.writeFile / fs.createReadStream / fs.createWriteStream
- python: openしてから
f.read()/f.write()
などだと思います。
この辺のAPIはエンコーディングを指定すると勝手に文字列に変換されたり、指定しないと適当なサイズのバッファがallocateされていたり、ファイルを全部読みこんでメモリに乗せてしまうのが普通だったりします。(pythonはシステムのロケールを使ってしまうので日本語のwindowsでひどい目にあったことがあります。)
これに対してGoは、io.Reader/io.Writerが中心的に取り扱われ、ファイル(*os.File)はそれらを実装します。
Goでstreamといえばio.Reader/io.Writerのことを指していることが多いと思います。
io.Reader/io.WriterはそれぞれPOSIX APIのread(2), write(2)をGo風に変えたもので、[]byteを介してやり取りします。
- バッファ(
[]byte)は呼び出すユーザーがサイズを決めてallocateします。 - 文字列への変換が自動的に起きることはありません。
- ファイルを全部読んで
[]byteにして扱うこともありますが、io.Reader/io.Writerを引数にとって渡す方が普通かと思います。 -
string([]byte(v))で文字列への変換ができますが、この変換は[]byteをutf-8として解釈しますので、ほかのエンコーディングで表現される文字列は意図的に変換する必要があります(e.g. EUC-JPなどを変換するときはgolang.org/x/text/encoding/japaneseを用いる、など)- 正しいutf8かはutf8.Valid([]byte(v))で別途チェックするか必要があります。
-
new TextDecoder().decode(new TextEncoder().encode(str))相当のこと(invalid runeをreplacement charに置き換え)をするにはstrings.ToValidUTF8(str, "\uFFFD")を呼びます。 - 1文字ずつ走査していく場合はfor-loopの中でutf8.DecodeRune呼び出して、RuneErrorが返ってきたとき書き換えるとかします。
Node.jsでもfs.FileHandleを使えばおおむね同じことができるんですが、それを引数に取るライブラリを見たことはないです。
開いて読み書きする
ファイルを開くためにはos.OpenFileを用います。
f, err := os.OpenFile("/path/to/file", os.O_RDWR|os.O_APPEND|os.O_CREATE|os.O_EXCL, fs.ModePerm)
if err != nil {
panic(err)
}
os.Openおよびos.Createはそれぞれ以下のショートハンドです
// os.Open
f, err := os.OpenFile("/path/to/file", os.O_RDONLY, 0)
// os.Create
f, err := os.OpenFile("/path/to/file", os.O_RDWR|os.O_CREATE|os.O_TRUNC, 0666)
返ってくる値は*os.Fileです。
*os.Fileはioで定義される大半のinterfaceを満たします。
var _ io.Reader = f
var _ io.Writer = f
var _ io.Closer = f
var _ io.Seeker = f
var _ io.ReaderAt = f
var _ io.WriterAt = f
io.Reader / io.Writerを満たすため、
const BUF_SIZE_YOU_WANT_READ = 8 * 1024 // whatever
bin := make([]byte, BUF_SIZE_YOU_WANT_READ)
n, err := f.Read(bin)
bin = bin[:n]
// bin is read content
...
// bin is []byte which contains whatever you want to write into f.
n, err := f.Write(bin)
POSIX APIのread(2) / write(2)をGo風にしたものになっており、
Readは渡されたスライスに読んだ内容をコピーしたうえで、読めたバイト数とエラー(あれば)を返します。
Writeは渡されたスライスの内容をすべて書き込み、書けたバイト数とエラー(あれば)を返します。
quoted from https://pkg.go.dev/io@go1.22.3#Reader
Even if Read returns n < len(p), it may use all of p as scratch space during the call.
上記よりRead後にしているbin = bin[:n]は必須です。
(たまに忘れてバグを生む)
さらに、
quoted from https://pkg.go.dev/io@go1.22.3#Writer
... Write must return a non-nil error if it returns n < len(p). ...
とある通り、Writeは渡された[]byteがすべて書き込めるまでブロックし、部分しか書けなかったらnon-nil errorが返されます。
閉じる
ファイルを閉じるためにはCloseを呼びます。
io.Closerの定義上、複数回Closeを呼び出したときの挙動は未定義なので、1度しか呼ばないように気を付けます。
色々さぼりたいときはonceを定義して、defer closeOnceとしておくことで、パニック時も含むエラー時にCloseできるようにしつつ、通常の系ではclose errorのハンドルもできるようにします。
// once wraps given fn to make sure it will be called only once.
// once is a poor and goroutine-unsafe equivalent to sync.OnceValue.
func once[T any](fn func() T) func() T {
var (
done bool
result T
)
return func() T {
if done {
return result
}
done = true
result = fn()
return result
}
}
// ...
f, err := os.OpenFile(...)
if err != nil {
return err
}
closeOnce := once(f.Close)
defer func() { _ = closeOnce() }()
// .. use of f may or may not fail ...
// in case it failed
if err != nil {
// deferred closeOnce is going to be called right before return
return err
}
if err := f.Sync(); err != nil { // if f has been written.
return err
}
if err := closeOnce(); err != nil {
// handle or ignore error
return err
}
...
読み込み専用のファイルの場合は(*os.File).Closeのエラーはおおむね無視してよいと思います。
書き込みしたファイルの場合は、とりわけunixにおいては(*os.File).Syncのエラーをハンドルして、Closeのエラーはおおむね無視すべきだと思います。
理由は↓のdetailsで説明しておきました。有名な話なのでGoをよく書く人はよく知ってると思いますが、対象読者に対しては急に詳細をドバっと出してしまう感じがしたので隠してあります。興味があったら読んでください。
Closeのエラーについて
ドキュメントを読む限り、Closeはエラーが帰ってこなさそうな雰囲気がありますが、ソースを読む限りclose(2)を呼ぶので各種エラーが帰ってきます。
ところで、Goはunixにおいてpreemptiveなスケジューリングを実現するためにsignal SIGURGを使います。
実装はGo1.14からです。
書いてある通り、WindowsではSuspendThread/SetThreadContext/ResumeThreadで実現されています。
unixではSIGURGを使ってpreemptionを実現しています
signalM自体は単なるtgkill(2)のラッパーで、特定のM(Machine = OS thread)にsignalを送っています。
その後、signal handlerに登録されているsigtrampから順繰りにsigtrampgo -> sighandler -> doSigPreemptという順番で実行、あとはWindowsの場合と同じ処理に合流してます。
このSIGURGは普通にsignal.Notifyで観測可能です。上記sighandlerが特にフィルターすることなくosパッケージが見える位置にsignalの通知をします。
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
go func() {
// このタイトループを消すとsigurgの発火がみえなくなる。
for range 1_000_000_000_000 {
// long tight loop
}
}()
c := make(chan os.Signal, 10)
signal.Notify(c)
for {
select {
case <-ctx.Done():
signal.Stop(c)
return
case sig := <-c:
/*
signal received: "urgent I/O condition"
signal received: "urgent I/O condition"
signal received: "urgent I/O condition"
signal received: "urgent I/O condition"
signal received: "urgent I/O condition"
*/
fmt.Printf("signal received: %q\n", sig)
}
}
これで何が困るかというと、一部のsyscallはこのSIGURGに割り込まれてEINTRを観測してしまうらしいっていうことなんですね。
そのため、すべてのsigactionにはSA_RESTARTがついています
signal(7)によると一部のsyscallはSA_RESTARTによってリスタートし、一部はリスタートぜずにEINTRを返すと述べています。
Goのstdでは、上記signal(7)中で言及のないsyscall呼び出し部分でも一部はEINTRを無視してリトライするようになっています。linux向け以外の実装のためにそうなっている面もありそうですが#40846を見る限り特殊な状況(この例ではFUSEに対するstat)を使えばドキュメントされてないsyscallもEINTRを返してくることがあるようです。
signal(7)にリストされていないにもかかわらず、close(2)はEINTRを返すとドキュメントされています。
しかも厄介なことに、linuxではclose(2)はEINTRが帰っても正常にfdは閉じられていると書かれているんですね。
つまり、EINTRだけど成功しているので、リトライしたら関係ないfdを閉じてしまうかもしれないということです。
そのため(*os.File).CloseのコードをたどってもcloseのEINTR時にそれを無視したりリトライするような処理はありません。
(*os.File).Syncを呼ぶとlinuxではfsync(2)が呼ばれます。こちらはEINTR時にリトライする処理が入っています。
https://man7.org/linux/man-pages/man2/close.2.html
A careful programmer who wants to know about I/O errors may
precede close() with a call to fsync(2).
とのことから、linuxではSyncを呼び出してSyncのエラーはハンドルし、Closeのエラーは無視したほうがよいのだと思います。
この辺の話、あくまでlinuxなら、という話であって別のunix系osだとまた違ったふるまいをするかもしれません。
SyncしてCloseのエラーを無視はおおむねどのosでも使えるはずですので、慣習的に行っても間違ってないはず・・・。
筆者はこの辺の挙動をwindowsであんまり試せてないので、windowsだとどうなんだかわからないのです。
ただし、*os.File以外のCloseは無視しちゃダメなときがあります。
例えば(*compress/gzip.Reader).CloseはCRC32チェックサムの照合を行いますので、ファイルが汚染されているなりするとエラーになります。全般的にio.ReadCloserをラップするio.ReadCloserがCloseを呼び出されたとき下層のio.ReadCloserのCloseを呼び出さないことのポイントはここにもあるのだと思います。もし対象読者がio.Readerを包むio.ReadCloserを作るときは同じくCloseのハンドルは呼び出し側にゆだねたほうがよいでしょうね。
全部読む
ファイルを全部読み込むためには
// https://pkg.go.dev/os@go1.22.3#ReadFile
bin, err := os.ReadFile("/path/to/file")
if err != nil {
panic(err)
}
// bin is content of `/path/to/file`
あるいは
// https://pkg.go.dev/os@go1.22.3#Open
f, err := os.Open("/path/to/file")
if err != nil {
panic(err)
}
defer func() { _ = f.Close() }()
// https://pkg.go.dev/io@go1.22.3#ReadAll
bin, err := io.ReadAll(f)
if err != nil {
panic(err)
}
// bin is content of `/path/to/file`
上記二つはほぼ一緒ですが、os.ReadFileは最適化されています; os.ReadFileはStat()によってファイルサイズを取得して、サイズ分のバッファーをあらかじめallocateしています。
一方でio.ReadAllはrのサイズを事前に知りませんので、512bytesから徐々にバッファを成長させながらio.EOFまでrを読み込みます。
Goを書いていると、io.Readerを受けとって中身を全部読むような関数はよく書くことになると思いますので、
read_all2.goの方法も知っておいたほうが良いでしょう。
全部書く
書き込む場合は
// https://pkg.go.dev/os@go1.22.3#WriteFile
err := os.WriteFile("/path/to/file", bin, fs.ModePerm)
if err != nil {
panic(err)
}
もしくは
f, err := os.Create("/path/to/file")
if err != nil {
panic(err)
}
_, err := f.Write(bin) // var bin []byte
closeErr := f.Close()
if err != nil {
panic(err)
}
if closeErr != nil {
panic(err)
}
です。
write_all1.goとwrite_all2.goはほぼ同じコードです。
コピー
対象読者はpythonやNode.jsでの開発経験があるため、ファイルのコピーと言えば以下を想像するかもしれません
- Node.js: fs.promises.copyFile
- python: (筆者は経験がなさ過ぎてよくわかりませんがおそらく) shutil.copy2
筆者の知り及ぶ限り、Goにおいてstdの範疇ではファイル名を二つ受け取ってコピーするような関数はありません。
代わりにio.Copyを使って、io.Readerをio.EOFまで読み込みながらio.Writerに逐次書き込みます。
これによって*os.Fileを*os.Fileへ頭から尻尾までコピーすればファイルのコピーとなります。
io.Copyを使ったファイルのコピーは以下のように行えます。
メタデータはコピーせず、単にファイルのコンテンツのみコピーします。
この処理の後で(*os.File).Chmodなどを使えばある程度プラットフォーム差をGoに吸収してもらいながらメタデータのコピーが行えます。
src, err := os.Open("/path/to/src/file")
if err != nil {
panic(err)
}
dst, err := os.Create("/path/to/dst/file")
if err != nil {
_ = src.Close()
panic(err)
}
// written is unused
written, err := io.Copy(dst, src) // https://pkg.go.dev/io@go1.22.3#Copy
if err != nil {
_ = src.Close()
_ = dst.Close()
// handle read/write error
// you might want to remove dst at this point
// _ = os.Remove("/path/to/dst/file")
panic(err)
}
err = dst.Sync()
if err != nil {
// handle sync error
_ = src.Close()
_ = dst.Close()
panic(err)
}
srcCloseErr := src.Close()
dstCloseErr := dst.Close()
if srcCloseErr != nil {
// handle or ignore close error
panic(err)
}
if dstCloseErr != nil {
// handle or ignore close error
panic(err)
}
ちなみにio.Copyは、
If src implements WriterTo, the copy is implemented by calling src.WriteTo(dst). Otherwise, if dst implements ReaderFrom, the copy is implemented by calling dst.ReadFrom(src).
とある通り、srcがio.WriterTo, あるいはdstがio.ReaderFromを実装する場合、それを呼び出して使います。そうでなければReadしてWriteするのをio.EOFまで繰り返します。
*os.Fileはio.WriterToとio.ReaderFromのどちらも実装し、実装の中で条件によってはsendfile(2)やcopy_file_range(2), splice(2)などを呼び出します。
このスニペットを筆者環境(linux/amd64)でデバッグ実行してみるとレギュラーファイル(*os.File)同士のコピーの場合copy_file_range(2)を使うのが見えます。sendfile(2)が使われるのはdstがstreaming socketでnetworkがtcp or unixの時だけのようです。
フォールバックの仕方とかが若干違うようですが、fs.promise.copyFileやshutil.copy2は実装の中で上記3つのsyscallのどれかを使うようになっているのでおおよそ同等な感じです。
データのシリアライズ/デシリアライズ
データのシリアライズ、デシリアライズは実用的なプログラムを作る時にほとんど避けられません。
stdにおける、データ構造とバイト列[]byteとの変換は全般的にencoding/*のパッケージで実装されています。
例えば、encoding/csvならばcsvとデータ構造との相互変換ができるなど、そういった感じです。
encoding/*パッケージ群はserialize/deserializeの代わりにMarshal/Unmarshalという語を使います。おそらく単なるデータとmap[string]any(のようなプログラム内の表現)との相互変換をするというよりは、structのようなmethodを持てるデータ構造とのマッピングだらかそういう言い回しなんだと思います(参考: stack overflow::What is the difference between Serialization and Marshaling?)
以降の節では、std libraryを使ったjsonとxmlの読み書きの基本を紹介します。
encoding/json
jsonの[]byteとデータ構造の相互変換はencoding/jsonで行います。
go.devのブログポスト: JSON and Go
json.(M|Unm)arshal
json.Marshalによってエンコード、json.Unmarshalによってデコードを行います。
基本的にはjsonのデータ構造に一致するstructを定義し、これに対してjson.Marshal / json.Unmarshalを呼び出します。
事前に構造を把握しないjsonの解析はstructを定義する代わりにmap[string]any(=JSON Objectを期待するとき) / []any(=JSON Arrayを期待するとき)もしくはany(=JSON Valueならなんでもいい時)を使います。
ただし、この場合型安全性を損なってしまいます。
場合によってはjsonのバイト列をGoのデータに変換せずに直接操作するようなライブラリを使うといいかもしれません。
package main
import (
"encoding/json"
"fmt"
)
type Sample struct {
// `json:"field_name"`で、marshal後のフィールド名を指定できる。
// ,omitemptyを付け足すと、zero valueの時Marshalがフィールドをスキップする
Foo string `json:"foo,omitempty"`
Bar Deeper // `json:"field_name"`がない場合、Go structのフィールド名がそのまま使われる("Bar":{}になる)。
// 実はjson.Unmarshal時のJSONフィールドとGoフィールドのマッチングはcase-insensitive
// json:"name"でフィールド名を付けるのは、
// json.Marshal時に
// 先頭小文字にしたいとかsnake_caseにしたいとかそういうとき
}
type Deeper struct {
Baz int
Qux MoreDeeper
}
type MoreDeeper struct {
Quux bool
}
func main() {
// []byte, errorを返す。
bin, err := json.Marshal(Sample{
Foo: "foo",
Bar: Deeper{
Baz: 123,
Qux: MoreDeeper{
Quux: true,
},
},
})
if err != nil {
panic(err)
}
fmt.Printf("%s\n", string(bin)) // {"foo":"foo","Bar":{"Baz":123,"Qux":{"Quux":true}}}
var s Sample
err = json.Unmarshal(bin, &s)
if err != nil {
panic(err)
}
fmt.Printf("%+v\n", s) // {Foo:foo Bar:{Baz:123 Qux:{Quux:true}}}
// case-insensitive
err = json.Unmarshal([]byte(`{"FOO":"boo","bAr":{"BaZ":455,"QUx":{"quux":false}}}`), &s)
if err != nil {
panic(err)
}
fmt.Printf("case-insensitive: %#v\n", s) // case-insensitive: main.Sample{Foo:"boo", Bar:main.Deeper{Baz:455, Qux:main.MoreDeeper{Quux:false}}}
}
-
json.Marshalには任意の型Tの変数を渡します。- struct tag
json:"name"でエンコード後のフィールド名を指定できます-
struct tagによって名前の被りが出るとそのフィールドが出力されなくなるとか独特な挙動をしますので、
snake_caseへの変換などのようなシンプルな名づけ以外はしない用がよいでしょう。
-
struct tagによって名前の被りが出るとそのフィールドが出力されなくなるとか独特な挙動をしますので、
- struct tag
json:",omitempty"でzero valueのフィールドをエンコード時にスキップできます。-
structはskipされることがないので、
time.Timeなどはこれの恩恵を受けられません。
-
structはskipされることがないので、
- struct tag
-
json.Unmarshalには、第二引数でデコード先データ構造のポインタを渡します。- struct tag
json:"name"でJSONフィールドとGoのstruct fieldの対応付けを決められます- case-insensitiveです。
-
C/C++ではポインタ/参照渡しした変数に書き込みをしてもらうことがよくあると思います。 -
C/C++のポインタ渡しは任意の型を渡すようなことはできない(void *をどう解釈するかは関数側ではわからない)はずですが、Goはreflectで型情報を取り出せるので、これによってanyが渡せるようになっています。 - non nilなポインタを渡せればokです。
(*T)(nil)を渡すとエラーになります。 - ちなみに
**Tを渡してもよいです。(var t *T; _ = json.Unmarshal(data, &t))-
**Tを渡した場合はnullリテラルを入力されたとき*Tがnilなのでわかるというメリットがあります。
-
- struct tag
Node.jsで、というかjavascriptでjsonを解析する場合はJSON.parseを使って解析結果のObjectを受け取りますよね。javascriptでは取り扱う変数は大部分がObjectであるのでこの決断には違和感がないかもしれません。
それに対してGoはデータ構造のサイズを既知とすることでスタックに置けるようにしたいわけですから、データ構造を先立たせるような考え方になるはずですね。
なので、map[string]anyへの変換よりは、任意の型を受けつられる関数の様式になります。
任意の型に対する演算を行うためには、Goではreflectを使います。
reflectはanyから型情報を得ることもできます。データをallocateするかどうかをユーザーに選択させながら任意の変数を受けるにはanyで任意の型Tの値のポインター*Tを受け付けるのが都合がいいということになります。
json.(M|Unm)arshaler
対象の type がjson.Marshaler, json.Unmarshalerを実装している場合、そちらが優先して使われます。
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
ポイントとして、
-
json.Marshalerは1つの有効なjson valueの[]byteを返す-
[]byte("null")でもよい
-
-
json.Unmarshalerは[]byteを解釈してメソッドレシーバに情報を代入する- なるだけ中途半端な結果を代入しないように、代入するのは処理最後まで遅延したほうが良い。
-
type T structに(M|Unm)arshalerを実装する際、-
type plain TとするとTのメソッドを引き継がないが内部のデータ構造が同じ構造体が定義できます- Unmarshalはデフォルトの動作そのままでいいけどその後validationを付け足したいとかそういうケースで非常に便利
- 例えばJSON Objectからversionだけ抜き出してそれをもとに後続のデコード処理を行いたいというときは、
type version struct {Version int}のような型を定義して、一旦json.Unmarshalします。 - 下記サンプルみたいにフィールドの一部を未解釈のバイト列のまま保持したい場合は
json.RawMessageを使います。
-
試しにtagged union的なものを実装してみます。
package main
import (
"encoding/json"
"fmt"
)
type data1 struct {
Foo string
}
type data2 struct {
Bar int
}
type data3 struct {
Baz bool
}
type Sample2 struct {
tag string
data any
}
func (s Sample2) MarshalJSON() ([]byte, error) {
m := map[string]any{}
switch s.data.(type) {
case data1:
m["tag"] = "data1"
case data2:
m["tag"] = "data2"
case data3:
m["tag"] = "data3"
default:
return nil, fmt.Errorf("unknown error type")
}
bin, _ := json.Marshal(s.data)
m["data"] = json.RawMessage(bin)
return json.Marshal(m)
}
func (s *Sample2) UnmarshalJSON(data []byte) error {
type T struct {
Tag string `json:"tag"`
Data json.RawMessage `json:"data"`
}
var t T
err := json.Unmarshal(data, &t)
if err != nil {
return err
}
var raw any
switch t.Tag {
case "data1":
var x data1
err = json.Unmarshal(t.Data, &x)
raw = x
case "data2":
var x data2
err = json.Unmarshal(t.Data, &x)
raw = x
case "data3":
var x data3
err = json.Unmarshal(t.Data, &x)
raw = x
default:
return fmt.Errorf("unknown tag")
}
if err != nil {
return err
}
s.tag = t.Tag
s.data = raw
return nil
}
func main() {
for _, d := range []Sample2{
{data: data1{Foo: "foo"}},
{data: data2{Bar: 5587}},
{data: data3{Baz: true}},
} {
bin, err := json.Marshal(d)
if err != nil {
panic(err)
}
fmt.Printf("marshaled = %s\n", bin)
var s Sample2
err = json.Unmarshal(bin, &s)
if err != nil {
panic(err)
}
fmt.Printf("unmarshaled = %#v\n", s)
/*
marshaled = {"data":{"Foo":"foo"},"tag":"data1"}
unmarshaled = main.Sample2{tag:"data1", data:main.data1{Foo:"foo"}}
marshaled = {"data":{"Bar":5587},"tag":"data2"}
unmarshaled = main.Sample2{tag:"data2", data:main.data2{Bar:5587}}
marshaled = {"data":{"Baz":true},"tag":"data3"}
unmarshaled = main.Sample2{tag:"data3", data:main.data3{Baz:true}}
*/
}
}
こんな感じでjson.Marshal/json.Unmarshalで呼び出されるときの挙動を差し替えることができます。荒はたくさんある気がしますが、読者がなんとなくインサイトを得られていればよいと思います。
map[string]any / []any / anyとの(M|Unm)arshal
事前にデータ構造を定義しない場合はmap[string]any, []any anyをエンコード元/デコード先に使うこともできます
package main
import (
"encoding/json"
"fmt"
)
func main() {
fmt.Printf("using map[string]any:\n")
for _, bin := range [][]byte{
[]byte(`{"foo":"bar", "baz":[1,2,3]}`),
[]byte(`{"foo":"bar", "baz":[1,2,3], "qux": {"nested":"nested", "null":null}}`),
} {
m := make(map[string]any)
err := json.Unmarshal(bin, &m)
if err != nil {
panic(err)
}
fmt.Printf(" %#v\n", m)
bin, err := json.Marshal(m)
if err != nil {
panic(err)
}
fmt.Printf(" %s\n", bin)
/*
map[string]interface {}{"baz":[]interface {}{1, 2, 3}, "foo":"bar"}
{"baz":[1,2,3],"foo":"bar"}
map[string]interface {}{"baz":[]interface {}{1, 2, 3}, "foo":"bar", "qux":map[string]interface {}{"nested":"nested", "null":interface {}(nil)}}
{"baz":[1,2,3],"foo":"bar","qux":{"nested":"nested","null":null}}
*/
}
fmt.Printf("using []any:\n")
for _, bin := range [][]byte{
[]byte(`[1,2,3]`),
[]byte(`[{"foo":"bar"}, [1,2,3]]`),
} {
var m []any
err := json.Unmarshal(bin, &m)
if err != nil {
panic(err)
}
fmt.Printf(" %#v\n", m)
bin, err := json.Marshal(m)
if err != nil {
panic(err)
}
fmt.Printf(" %s\n", bin)
/*
[]interface {}{1, 2, 3}
[1,2,3]
[]interface {}{map[string]interface {}{"foo":"bar"}, []interface {}{1, 2, 3}}
[{"foo":"bar"},[1,2,3]]
*/
}
fmt.Printf("using any:\n")
for _, litBin := range [][]byte{
[]byte(`123`),
[]byte(`0.4`),
[]byte(`true`),
[]byte(`null`),
[]byte(`["yay", 123]`),
[]byte(`{"object":"yes"}`),
[]byte(`"nay"`),
} {
var m any
err := json.Unmarshal(litBin, &m)
if err != nil {
panic(err)
}
fmt.Printf(" %#v\n", m)
bin, err := json.Marshal(m)
if err != nil {
panic(err)
}
fmt.Printf(" %s\n", bin)
/*
123
123
0.4
0.4
true
true
<nil>
null
[]interface {}{"yay", 123}
["yay",123]
map[string]interface {}{"object":"yes"}
{"object":"yes"}
"nay"
"nay"
*/
}
}
json.New(En|De)coder
json.(En|De)coderを使うことでstreamでJSONの処理が行えます。と言いつつ、以下のように
- decoderは1つのJSON value(つまりJSON Object全体)を読み終わるまでreaderを読んでから処理を始める
- encoderはエンコードを終えるまで
*bytes.Bufferに値をいったん全部書く
のでメモリ効率的にはjson.(M|Unm)arshalとほぼ変わらないと思います。
Decoderは1つのJSON valueを読んで動作します。その先にどういったデータがあるかは気にしませんので、例えばndjson(newline delimited JSON)などをうまいこと処理できます。
逆に言うと末尾にジャンクデータがあっても許容してしまうので、それが駄目な場合はdec.More()をチェックするなど追加の処理が必要です。
package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
)
type Sample struct {
Foo string
Bar int
}
func main() {
buf := new(bytes.Buffer)
encoder := json.NewEncoder(buf)
err := encoder.Encode(Sample{Foo: "foo", Bar: 123})
if err != nil {
panic(err)
}
fmt.Printf("%s", buf.String()) // {Foo:foo Bar:123}
decoder := json.NewDecoder(io.MultiReader(buf, bytes.NewReader([]byte(`foobarbaz`)))) // junk data at tail
var s Sample
err = decoder.Decode(&s)
if err != nil {
panic(err)
}
fmt.Printf("%+v\n", s) // {"Foo":"foo","Bar":123}
if decoder.More() {
bin, _ := io.ReadAll(decoder.Buffered())
fmt.Printf("junk data = %s\n", bin) // junk data = foobarbaz
}
}
json.(M|Unm)arshal | json.New(En|De)coderの使い分け方
json.NewEncoder / json.NewDecoderを利用するのは以下のような場合です
- 入力元 / 出力先が
io.Reader/io.Writerである - (デコード時のみ)トークンごとに処理したい
-
ndjson(newline delimited json)などを読み書きしたい - DisallowUnknownFieldsやSetEscapeHTMLのようなオプションを利用したい
- 入力の末尾にジャンクデータがあるのを許容したい
- JSON valueの開始オフセットはわかるけど終了オフセットはよくわかっていない
json.Marshal / json.Unmarshalを利用するのはそれ以外の時、という感じになると思います。
空の値のフィールドをスキップする(omitempty)
すで述べていますが、struct tagで,omitemptyを指定すると、フィールドがempty valueであるときにエンコード時にフィールドがスキップされます。
条件はここで網羅されている通り、ポインターでない限りstructはzero valueでもemptyになりません。
システム間でデータを相互交換するときにフィールドがないことが重要な場合があります。
Node.jsもといjavascriptでは自然とundefinedによってフィールドを消すことができます。Goではこのオプションを使うことでそれを実現できます。
package main
import (
"encoding/json"
"fmt"
)
type Sample struct {
Foo string `json:"foo,omitempty"`
Bar int `json:",omitempty"`
Baz string
Qux int
}
func main() {
bin, err := json.MarshalIndent(Sample{}, "", " ")
if err != nil {
panic(err)
}
fmt.Printf("%s\n", bin)
/*
{
"Baz": "",
"Qux": 0
}
*/
}
普通は存在しないフィールドの表現に*Tを用います。
なぜなら、json.Unmarshalの挙動が
- pointer type
*Tに対して、nullはnilを代入 - non-pointer type
Tに対して、nullは値を代入しない - struct fieldにマッチするJSON Object fieldがない場合、値を代入しない
であるので、
フィールドの型にintやstringを指定したとき、0や""が、JSONにフィールドがなかったということなのか、nullだったのか、その値が渡されたのか判別がつきません。
それらの判別が必要なケースではTに対して,omitemptyを使うことができないからです。
type Sample struct {
// pointerにしておくと、入力のJSON Objectにフィールドがなかった、もしくはnullだったとき、
// Unmarshal後にフィールドの値はnilになるので、それらがわかります。
Foo *string `json:"foo,omitempty"`
Bar *int `json:",omitempty"`
Baz string
Qux int
}
T | null | undefinedの表現の仕方
Node.jsを扱っていた対象読者はナチュラルにjsonのフィールドがT | null | undefinedを持てると思うかもしれませんが、普通にやるとそういうことはできません(以前の記事を参照)
ではどうやるのかというとフィールドにgithub.com/oapi-codegen/nullableで定義される型をjsog:",omitempty"付きで指定します。
type Sample struct {
Padding1 int
Opt nullable.Nullable[string] `json:"opt,omitempty"`
Padding2 int
}
上記playgroundで実際にスキップされるのを確認してください。
どうして普通にできないかとか
T | null | undefinedというのを表現しようとすると一つのデータ型で3つのステート(値がある、値がない(null)、フィールドがない(undefined))を表現する必要があります。
javascriptのObjectはGoで言えばmap[string]anyなので、フィールドがない|nil|値があるが表現できていたわけですね。
Go1.18以降、genericsが追加されたので3つのステートと任意の型Tのデータを持つ型というのが定義できるようになりました。
ただし前述通り、,omitemptyはstructには機能しないので、structでこういった型を定義できません。
そこで以下のいずれかの方法をとる必要があると思います
-
,omitemptyが機能する[]T,map[K]Vを利用する- 前述のgithub.com/oapi-codegen/nullableは
map[bool]Tを利用します。
- 前述のgithub.com/oapi-codegen/nullableは
-
以前の記事で述べた通り
-
[]byteやstructなどを一旦map[string]anyに変換し、これを介してフィールド存在チェック/削除をする -
IsZero() == trueの時、フィールドをスキップできるエンコーダーを用意して、3以上の状態を表現できる型を定義する- エンコーダーは以下などがある
- 3つの状態を表現できる型として
type option[T any] struct {valid bool; value T}を定義してtype undefined[T any] option[option[T]]を利用する
-
- 特に記事では述べてない記憶がありますが、コードジェネレーターで特定の値をスキップするような
MarshalJSONを生成しても当然達成可能です- embedされたフィールドの扱いが難しいですので対象読者に対してはお勧めできません。もしする場合は
encoding/json内部の挙動を読み込んだうえで行ってください。
- embedされたフィールドの扱いが難しいですので対象読者に対してはお勧めできません。もしする場合は
github.com/go-json-experiment/jsonはencoding/json/v2としてプロポーズしようとしているexperimental実装です。まだ破壊的変更を予定しているらしいですので本番で使うのはまだ怖いですね。
[]T版でT | null | undefinedを実装してみる
筆者はごく最近まで上記のnullableを知らなかったので、こういう方法があると思いついていませんでした。
以前の記事を書いた時点ではポインターを使わずにデータのあるなしを表現したい/Tがcomparableならundefined[T]もcomparableであってほしいというのが念頭にあったので、できるとわかっていてもこの方法をとらなかったもしれないですが。
リンク先の実装がmap[bool]Tを利用するので、[]Tバージョンだとどんな感じになるのか試しました
map[bool]T版とのパフォーマンス差を測るためにbenchも実装してみました
goos: linux
goarch: amd64
pkg: github.com/ngicks/und/v2/internal/bench
cpu: AMD Ryzen 9 7900X 12-Core Processor
BenchmarkSerdeMapV1-24 607209 1857 ns/op 1362 B/op 32 allocs/op
BenchmarkSerdeSliceV1-24 670332 1746 ns/op 1250 B/op 30 allocs/op
BenchmarkSerdeMapV2-24 716805 1563 ns/op 633 B/op 21 allocs/op
BenchmarkSerdeSliceV2-24 724090 1532 ns/op 665 B/op 22 allocs/op
PASS
ok github.com/ngicks/und/v2/internal/bench 4.606s
う~んslice版のほうが若干速いですね・・・!多分それなりにフェアな比較になっていると思います。
この結果を受けて筆者の自分向けライブラリではslice版を実装して使っていく決断を下しました。
struct tagの参照のしかた
上記でしれっとstruct tagを使用しています
type Sample struct {
Foo string `json:"foo"`
}
このタグによって、Foo string fieldは"foo"というJSON fieldとして読み書きされます。
(初学者だった時の私はこのメタデータってどうやってアクセスすんだよと気にしていました)
このタグはencoding/jsonから参照されるのでユーザーが直接気にする必要はありませんが、それはそれとしてアクセス方法を述べます。
struct tagはreflectパッケージを通じてアクセスします。
package main
import (
"fmt"
"reflect"
)
type Sample struct {
Foo string `json:"foo"`
}
func main() {
rt := reflect.TypeFor[Sample]()
for i := 0; i < rt.NumField(); i++ {
fty := rt.Field(i)
fmt.Printf("tag = %q, look up for json = %q\n", fty.Tag, fty.Tag.Get("json"))
}
/*
tag = "json:\"foo\"", look up for json = "foo"
*/
}
encoding/jsonのびっくりポイント
いくつかびっくりポイントが存在します。
- json.Unmarshal時、実はフィールドはcase-insensitiveに判定されます。
-
MarshalJSONのmethod receiverがpointer type*Tの場合、フィールドがadrresableでないとメソッドが呼ばれない
現在encoding/json/v2のプロポーザルを出そうという試みが存在し、Discussionでencoding/jsonのびっくりポイントが包括的に述べられています。大体の場合基本的な使い方の範疇で困らないと思いますけどたまにこのびっくりポイントに引っ掛かると思うので読んでおくと参考になるかも。
encoding/xml
xmlの[]byteとデータ構造の相互変換はencoding/xmlで行います。
xmlの使用頻度は高い人はすごく高いでしょうが、筆者の体感上htmlを除くと古いAPIとのやり取り以外で使う場面は少ないのでjsonに比べるとざっとしたことしか述べません。
xml.(M|Unm)arshal
jsonと同じく構造体を定義してxmlと相互にマッピングする方式です。
こちらはmap[string]anyやanyとの相互変換はサポートされているということは書かれていません。
xmlはJSONと違って<tag>に対して任意のattributeが<tag attr=value>のような形で追加していくことができますから、何かのデータフォーマットを定義せずに相互に変換することができないためだからでしょう。
package main
import (
"encoding/xml"
"fmt"
)
type Sample struct {
// XMLNameというフィールド名でxml struct tagが付いているとそれが
// outermost xml elementの名前になります。
// この場合フィールドの型その物はなんでもよいので、xml.Nameである必要はありません。
//
// https://pkg.go.dev/encoding/xml@go1.22.3#Marshal
// > the tag on the XMLName field, if the data is a struct
XMLName xml.Name `xml:"sample"`
Foo string `json:"foo" xml:"foo"`
Bar Deeper `xml:"bar"`
}
type Deeper struct {
Baz int `xml:"baz"`
Qux MoreDeeper `xml:"qux"`
}
type MoreDeeper struct {
Quux bool `xml:"quux"`
}
func main() {
// []byte, errorを返す。
bin, err := xml.Marshal(Sample{
Foo: "foo",
Bar: Deeper{
Baz: 123,
Qux: MoreDeeper{
Quux: true,
},
},
})
if err != nil {
panic(err)
}
fmt.Printf("%s\n", string(bin)) // <sample><foo>foo</foo><bar><baz>123</baz><qux><quux>true</quux></qux></bar></sample>
var s Sample
err = xml.Unmarshal(bin, &s)
if err != nil {
panic(err)
}
fmt.Printf("%+v\n", s) // {XMLName:{Space: Local:sample} Foo:foo Bar:{Baz:123 Qux:{Quux:true}}}
}
xml.(M|Unm)arshaler
xml.Marshaler, xml.Unmarshalerを通じて挙動を変更できるのはjsonと同様ですが、こちらはEncoder, Decoderを受けとるためjsonのそれとは様式が違います。
ポイントとしては
-
enc.EncodeElement(v, start)で1つの値をエンコードできる -
dec.Token()で返ってくる値はxml.CopyTokenを呼ばないと次のTokenコール時に上書きされることがある
ぐらいでしょうか。
Example: XMLEither
例として前作ったEither[T, U any]を載せます。
普通は数字だけど値が入っていないとfallback文字列が入っているというxmlで困ったので作ったものです。
package main
import (
"encoding/xml"
"errors"
"fmt"
"io"
"reflect"
)
type Either[T, U any] struct {
left T
right U
isLeft bool
}
func Left[T, U any](v T) Either[T, U] {
return Either[T, U]{
left: v,
isLeft: true,
}
}
func Right[T, U any](v U) Either[T, U] {
return Either[T, U]{
right: v,
isLeft: false,
}
}
func (e Either[T, U]) Left() (v T, ok bool) {
if e.isLeft {
return e.left, true
} else {
return v, false
}
}
func (e Either[T, U]) Right() (v U, ok bool) {
if !e.isLeft {
return e.right, true
} else {
return v, false
}
}
func (e Either[T, U]) MarshalXML(enc *xml.Encoder, start xml.StartElement) error {
if e.isLeft {
return enc.EncodeElement(e.left, start)
} else {
return enc.EncodeElement(e.right, start)
}
}
type EitherUnmarshalError struct {
LeftErr, RightErr error
LeftTy, RightTy reflect.Type
}
func (e *EitherUnmarshalError) Error() string {
return fmt.Sprintf(
"EitherUnmarshalError: left type = %s, right type = %s. left err = %s, right err = %s",
e.LeftTy, e.RightTy, e.LeftErr, e.RightErr,
)
}
type replayReader struct {
tokens []xml.Token
idx int
}
func (r *replayReader) Token() (xml.Token, error) {
if r.idx >= len(r.tokens) {
return nil, io.EOF
}
next := r.tokens[r.idx]
r.idx++
return next, nil
}
func (e *Either[T, U]) UnmarshalXML(d *xml.Decoder, start xml.StartElement) error {
var (
err, leftErr, rightErr error
l T
r U
)
tokens := []xml.Token{start}
for {
token, err := d.Token()
if err != nil && !errors.Is(err, io.EOF) {
return err
}
if token == nil {
break
}
token = xml.CopyToken(token)
tokens = append(tokens, token)
}
err = xml.
NewTokenDecoder(&replayReader{tokens: tokens}).
DecodeElement(&l, nil)
if err == nil {
e.left = l
e.isLeft = true
return nil
} else {
leftErr = err
}
err = xml.
NewTokenDecoder(&replayReader{tokens: tokens}).
DecodeElement(&r, nil)
if err == nil {
e.right = r
e.isLeft = false
return nil
} else {
rightErr = err
}
return &EitherUnmarshalError{
LeftErr: leftErr,
RightErr: rightErr,
LeftTy: reflect.TypeOf(l),
RightTy: reflect.TypeOf(r),
}
}
func main() {
type either struct {
XMLName xml.Name `xml:"either"`
A Either[int, string] `xml:"a"`
}
for _, e := range []either{
{A: Left[int, string](123)},
{A: Right[int, string]("foobar")},
} {
bin, err := xml.Marshal(e)
if err != nil {
panic(err)
}
fmt.Printf("marshaled = %s\n", bin)
var u either
err = xml.Unmarshal(bin, &u)
if err != nil {
panic(err)
}
fmt.Printf("unmarshaled = %#v\n", u)
/*
marshaled = <either><a>123</a></either>
unmarshaled = main.either{XMLName:xml.Name{Space:"", Local:"either"}, A:main.Either[int,string]{left:123, right:"", isLeft:true}}
marshaled = <either><a>foobar</a></either>
unmarshaled = main.either{XMLName:xml.Name{Space:"", Local:"either"}, A:main.Either[int,string]{left:0, right:"foobar", isLeft:false}}
*/
}
}
go generate
Goにtask runnerはない
Node.jsで開発経験のある対象読者はnpm run <<script-name>>などで動作するスクリプトの代わりになるものがGoでは何になるか疑問に思うかもしれません。
Goにはタスクランナーのようなものはコード生成以外に関してはありません。
一応pythonのみしか開発経験がない対象読者のために説明すると、
npm run <<script-name>>でpackage.jsonの"scripts"以下に書かれたスクリプトを実行できるもののことです。
scriptsはJSON Objectで定義でき、<<script-name>>の部分がJSON Field、実際のスクリプト内容はvalueで記述されます。
スクリプトは{"package":{"dependencies":{...}}}でインストールされた実行ファイルもPATHに加えて実行するので十分クロスプラットフォームになれるということらしいです。
例えばnode-canvasはネイティブモジュールを使うため、install時にnode-gypというNode.js向けのビルドシステムを動作させます。
// https://github.com/Automattic/node-canvas/blob/2de0f8b36dbb271c9dc1bdb211812c5dabca5129/package.json#L35
"scripts": {
// ...
"install": "prebuild-install -r napi || node-gyp rebuild",
// ...
},
最近はWASM/WASI(preview2)があるのでinstall時にそのシステムでビルドする仕組みを見る機会は徐々に減っていくかもしれません。
これ以上の詳細はnpm公式を参照してください:npm Docs: scripts
これに代わるものはGoのstdのツールチェーンでは多分ありません。自分でMakefileをメンテしているプロジェクトをちょいちょい見るのでそれがよい方法かもしれないです。(とはいえMakefileのクロスプラットフォーム化はなかなか落とし穴があるみたいです(参考))。(筆者はMakefileよくわかんないのでなんとも言えないですが。)
ただし、
-
go run path/to/module/path/to/main/pkg@versionがリモートモジュールを実行できること- 常に最新がいいなら
@latestとします
- 常に最新がいいなら
-
cgo(C言語で書かれたコードをGoから呼び出す)を使う際は(pkg-configの設定を要求してくるライブラリがあることはあるにしろ)基本的にgo buildですむので別コマンドは不要。- ただしcross-compilationが大変になります。
-
//go:generate [options] <<command>>でソースが置かれたパッケージのディレクトリをcwdにして任意のコマンドが実行できること -
dockerでマルチプラットフォームビルドが行えること- koもいいとよく聞くが筆者は試したことがない
が組み合わさると、task runner的な物の欲求は薄いと思われます。
Denoをインストールしてdeno.jsonにtasksを書くとdeno task ...で実行できるのでどうしても欲しいならそういう方法になるかと思います。ただ不用意に依存要素を増やしてあれとこれとあれをインストールして・・・というと色々キツいことがあって、手順書の負荷が上がったり、使用者の環境でうまいことDenoが動かなかったりでサポートコストが増大したり(1敗)、gitlab-ciのイメージが大きくなってしまったりするんですね・・・。
GoのプロジェクトがGoだけで完結できるといいというのは一般論だと思います。
github.com/go-task/taskなど、Goで作られたタスクランナーを用いるというのもありかもしれません。筆者は使ったことがないのでお勧めする立場ではありませんが、golang/goのwikiで紹介されているので認知度が高くて十分叩かれてると予測しています。
結論としては
- タスクランナーは使わない
- 複雑なビルドフラグやテストマッチャーがなくて、
-
code generatorの呼び出し口はgo:generateで全部網羅でき、 -
Dockerfile1つ、もしくはbake.hclでビルドが事足りるか- もしくは
github actionsやgitlab-ciにすべて任せる
- もしくは
- 時にはタスクランナーなしでもいけますねおそらく
- Deno, github.com/go-task/task(筆者は使ったことがない)などのクロスプラットフォームタスクランナーを用いる
-
Makefileでクロスプラットームを頑張るか、unix系OSオンリーだと割り切る - スクリプト的な作業もすべて
Goで書く
のいずれかという感じでしょうか。ケースバイケースな色が強いのでこの方法でよいです!と言えるものはないですね(この一連の記事に書かれていることはすべてそうなんですが)
Goをスクリプト的に使うのはいつか
ソフトウェアを作っていればcliアプリケーションを作ることがなかったとしても、作業用のスクリプトを組みたくなる場面はたくさんあると思います。
上記の通りgo:generateでコード生成はまかなうことができているんですが、例えばjsonschemaを解析してコード生成を行うライブラリが吐いた後のgoコードをさらにテキスト置換するとかそういう必要があることが時たまあります。
いちばん手軽ですぐ思いつくいのはshell scriptやbatch file/PowerShell scriptを書くことでしょうか?ただこれらは落とし穴が多かったり、プラットフォーム依存なので複数プラットフォームで動いてほしい時に再実装や多バージョンメンテがいるのが困りますよね。クロスプラットフォーム問題は開発環境でも頻繁に起きます。「事務機がwindowsでiphone/android両対応アプリをmacで開発していてサーバーはlinux」な開発環境自体はそこそこ一般的に思います。
クロスプラットフォームで動作するスクリプト環境としてpython、Deno+dax, Bun(Bun Shell)(さらにここにあなたの得意なスクリプト言語を加える)などが考えられます。
これらはクロスプラットフォームなだけでなく、「データを加工してJSONに変換する」とか、「複雑なif-else/switch-caseで処理分岐させる」であるといった複雑な処理を実装しやすいです。
処理が多くなって来た時にソースを分割しやすいのも利点ですね。
筆者はDeno+daxでスクリプトを開発したことがありましたが、0.38.0以前であったのでredirectサポートがなく、結構苦しくてコードベースが大きくなるのに伴って結局素のDenoに戻してしまいました。最終的に既存コードをimportしまくるGoのcliアプリを再実装しました。
ただスクリプト環境の導入は前述通り、手順書のコストやサポートのコストが増大するので、GoのプロジェクトはなるだけGoで完結してほしいですよね。
なのでGoをスクリプト的に書く場面はそれなりにあると思われます。
特に以下のケースの時、shell scriptに打ち勝ちうるかもしれません。
- そこそこサイズの大きな処理になる
- 複雑な処理を伴う
- 既存のコードを活用できる
-
dockerとかだと直接github.com/moby/mobyをインポートしてdockerdが使うstructや定数をそのまま使えるので場合によっては便利です。 - 既にやりたい処理のライブラリを作成済み/知っている。
-
個人的にはちょっと文字列を書き換えるような処理でもGoで書いてしまいます。そのくらいのことはGoでもとっても簡単にできるからです。
既存の資産のでかさで何使うのかを決めたらいいともいえるかもしれませんね。
Goをスクリプト的に置く場合、ディレクトリを切ってmainパッケージでソースを置きます。
配置としては./cmd以下にディレクトリを切ってもいいと思いますし、配布するつもりないよっていうのを強調するために./scriptにサブディレクトリを切ってそこをmain packageとしてもいいかもしれません。
internal/script以下にサブディレクトリを切るとよそに公開するつもりがない雰囲気が伝わっていいかもです。
Goのruntimeの中だとsrc/runtimeの中にmain packageを含む.goファイルがpackage runtimeなほかのソースと一緒にドカっと置かれていて、それを使ってコード生成を行っていました。そういう方法もあり見たいです。
go:generate
上記のgo command documentによれば、
//go:generate command argument...
というgenerate directive commentを書いておき、
go generate [-run regexp] [-n] [-v] [-x] [build flags] [file.go... | packages]
で、ファイルかパッケージを指定してコマンドを実行することができます。
go:generateは上記ドキュメントによればコード生成を主眼としていますが、実際上はコマンドはおおよそ何でも実行できます。
コマンドのcwdはデフォルトではgo:generateが書かれたファイルのパッケージのディレクトリになるので、相対パスはそのファイルからの相対パスになります。
//go:generate go run -mod=mod entgo.io/ent/cmd/ent@v0.12.3 generate --target ./gen ./schema
のようにすれば、entのジェネレーターを使用してコード生成が行えます。
もちろんローカルで作ったmain packageも実行可能です
//go:generate go run ./split-server-interface/ -i ../somewhere/server-interface.go -o ./server_interface.generated.go
なので、go generateでコード生成を行うプロジェクトは変更する度にgo.modと同階層で
go generate ./...
としておけばすべてのgo:generateを実行できるので、generateの実行忘れを防ぐことができます。
cli flag
cli flagの解析はstd範疇で取り扱われています。ちょっとしたcode generatorもフラグなしでは柔軟性に欠けるため、これを簡単にさせてくれるのがすごく便利です。
- シンプルなフラグ解析はstdの
flagが強力です - サブコマンドの分割を行ったり、long flag/short flagのサポートをえたい場合はgithub.com/spf13/cobra + github.com/spf13/pflagがよいかも
- 単に
--xというフラグの指定がしたいだけならflagでokです。
- 単に
flag
flagパッケージを使うとアプリ実行時に渡したフラグを解析できます。
ドキュメントされている通り、cliからフラグの指定は以下のいずれでもよいです。逆に-xのみとか、--xのみとかという設定はできません。
-flag
--flag // double dashes are also permitted
-flag=x
-flag x // non-boolean flags only
double dashが使用できるようになったのはGo1.19より。
Release Noteにはdouble-dashのことは載ってないですけどgo docの差分を見ると1.19からドキュメントに追加されています。
# 同じ
go run ./main.go -f1=foo
go run ./main.go --f1 foo
フラグのバインディングをflagパッケージで定義してからflag.Parseでフラグのパーズを行います。
シンプルなフラグの設定はflag.Tで行います。(Tは任意の組み込み型 e.g. string, bool, int)
import "flag"
var (
flag1 = flag.String("f1", "default value", "flag usage description")
)
func main() {
fmt.Printf("flag1 = %s\n", flag1) // flag1 =
flag.Parse() // Parse cli arguments and set parsed result.
// flags are parsed and flag1 is set.
fmt.Printf("flag1 = %s\n", flag1) // flag1 = foo
}
// go run ./main.go -f1 foo
すでに定義した変数にフラグをバインドするにはflag.TVarを使います。(Tは任意の組み込み型 e.g. string, bool, int)
import "flag"
var (
flagMultiple string
)
// 複数フラグを一つにバインドするのもできます
func init() {
flag.StringVar(&flagMultiple, "fm1", "1", "flag multiple 1")
flag.StringVar(&flagMultiple, "fm2", "2", "flag multiple 2")
flag.StringVar(&flagMultiple, "fm3", "3", "flag multiple 3")
}
// go run ./main.go -fm3 bar -fm1 foo -fm2 baz
// 最後に設定された値がバインドされてます
// flagMultiple = baz
フラグテキストの任意なパージングにはFuncあるいはBoolFunc(Go1.21.0より)を使います
import (
"flag"
"log/slog"
"time"
)
var (
t1 time.Time
logLevel slog.Level = 99999
)
func init() {
flag.Func("t1", "time to start", func(s string) error {
var err error
t1, err = time.Parse(time.RFC3339, s)
return err
})
flag.BoolFunc("log", "bool func", func(s string) error {
switch s {
case "true":
logLevel = slog.LevelInfo
case "":
default:
return logLevel.UnmarshalText([]byte(s))
}
return nil
})
}
// go run ./main.go -t1 2023-04-04T09:00:00+09:00
// t1 = 2023-04-04 09:00:00 +0900 +0900
//
// go run ./main.go -log
// log = INFO
//
// go run ./main.go -log=DEBUG
// log = DEBUG
encoding.TextMarshaler / encoding.TextUnmarshalerを実装した型についてはflag.TextVarが使えます(Go1.19より)
var (
t2 time.Time
)
func init() {
flag.TextVar(&t2, "t2", time.Now(), "time to end")
}
// go run ./main.go
// t2 = 2024-05-27 15:28:18.550790779 +0000 UTC m=+0.000017945
positonal argを取り出すにはflag.Argもしくはflag.Argsを使います。
for i := range 3 {
positionalArg := flag.Arg(i)
fmt.Printf("position %d = %s\n", i, positionalArg)
}
fmt.Printf("args = %#v\n", flag.Args())
// go run ./main.go foo bar baz qux
/*
position 0 = foo
position 1 = bar
position 2 = baz
args = []string{"foo", "bar", "baz", "qux"}
*/
実はこれらのtop-level functionはflag.CommandLineへの同名メソッドへのエイリアスです。
なので実は任意の[]stringをパーズしたり、フラグセットを分割してサブコマンドを実現したりできます。
package main
import (
"flag"
"fmt"
"os"
)
func main() {
sub1 := flag.NewFlagSet("sub1", flag.PanicOnError)
sub2 := flag.NewFlagSet("sub2", flag.PanicOnError)
foo := sub1.String("foo", "", "foo")
bar := sub2.Int("bar", 0, "bar")
if len(os.Args) < 2 {
panic("too short")
}
switch os.Args[1] {
case "sub1":
sub1.Parse(os.Args[2:])
fmt.Printf("foo = %s\n", *foo)
case "sub2":
sub2.Parse(os.Args[2:])
fmt.Printf("bar = %d\n", *bar)
}
}
// go run ./main2.go sub1 --foo=yayyay
// foo = yayyay
// go run ./main2.go sub2 --bar=23
// bar = 23
実際にサブコマンドを実現しようとするとまだやらないといけないことがたくさんあります。github.com/spf13/cobraなどのライブラリを使ったほうがよいでしょう。
github.com/spf13/cobra
などが利用しているcliフレームワークです。使用者リストもメンテされています。
この手のサブコマンドを実装できるライブラリとしてはgithub.com/urfave/cliかこれかをとりあえず使っておけばよい、という感じです。
利用法は簡単で
go run github.com/spf13/cobra-cli@latest init
go run github.com/spf13/cobra-cli@latest add <<sub-command>>
でひな形が作成されるため、これに沿ってアプリを実装していくのみです。
# go run .
A longer description that spans multiple lines and likely contains
examples and usage of using your application. For example:
Cobra is a CLI library for Go that empowers applications.
This application is a tool to generate the needed files
to quickly create a Cobra application.
Usage:
cobra-subcommand [command]
Available Commands:
completion Generate the autocompletion script for the specified shell
help Help about any command
sub1 A brief description of your command
sub2 A brief description of your command
Flags:
-h, --help help for cobra-subcommand
-t, --toggle Help message for toggle
Use "cobra-subcommand [command] --help" for more information about a command.
簡単すぎてちょっとびっくりしちゃいますね。
ドキュメントを見て詳細なつくり込みを行ってください。サブコマンドの実現までなら見てのとおり、ほとんどのボイラープレートはこなしてくれます。
内部的にgithub.com/spf13/pflagというライブラリに依存し、POSIX風な-f or --flagというショートフラグに対応しています。
非常に便利ですが、これはstdのflagをフォークしてつくられているので、API/内部の作りはそっくりですが、flagの進歩をそのまま取り込めるということでもない、というのがネックとなります。
例えばGo1.19以降のflagに追加されたBoolFuncやTextVarがありません。ただそれらは(*flag.FlagSet).Varのラッパーとして実装されているので、pflagのVarを使えば大体同じことがでおそらくできます。
environment variable
プログラムを書いていくうえで環境変数とのインタクラクションはほとんど必須のものと言っていいでしょう。
W. Richard Stevens. (2013). Advanced Programming in the Unix Environment 7.6によると、unixにおける典型的なメモリ配置ではプロセスに与えられるhigh addressからcommand-line argumentとenvironment variablesが配置され、その後からstackが徐々にlow addressに向けて伸びていきます。
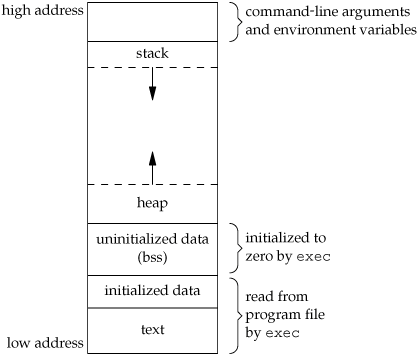
W. Richard Stevens. (2013). Advanced Programming in the Unix Environment section 7.6 より引用
Goも読む限り別に例外でないらしく、argvのすぐ後にenvironment variableを示すポインタが並んでいるのは変わらないようです。memmoveでコピーしているのでこのポインターにアクセスするのは1度きりのようですが。(memmoveの実装のしかたも面白いので、興味がある方はこちらの素晴らしい記事を参照ください: Go の copy はいかにして実装されるか)
ちなみにwindowsではsyscallで取得しているので、ちょっと話が違いますね
Goはruntime起動時にこのargvとenvioronment variableをコピーしてしまい、ユーザーはコピーにしかアクセスしないのでこういったレイアウトであること(=argvのバウンドチェックがおかしくて環境変数やスタックがぶっ壊れるみたいな)をユーザーコードが意識することはないはずですが、ここで重要なのはプロセスから見えるメモリ領域にこれらの変数を引き渡す方法が広く存在しており、プログラム自身が自発的に設定したり外部環境から読み込まなくても勝手に置かれるということです。これは設定ファイルを、例えばdockerなどのcontainerに引き渡すのに比べてはるかに簡単です(fork(2)してexecve(2)する前にfdを閉じなければプログラムに自発的に動作させることなくファイルも引き渡すことができるんですがここではそれは置いときます)。
環境変数はファイルを受け渡すよりもより自然にプロセス間で受け渡すことができるため、これによって設定値を引き渡す決断を下すことも多いでしょう。
つまり、環境変数を簡単に取得できるようにしておくことは非常に重要です。
os.Getenv / os.LookupEnv
環境変数の取得はos.Getenv, os.LookupEnvで行います。
fmt.Printf("$GOPATH = %q\n", os.Getenv("GOPATH"))
v, ok := os.LookupEnv("NONEXISTENT")
fmt.Printf("$NONEXISTENT = %q, found = %t\n", v, ok)
/*
$GOPATH = "/go"
$NONEXISTENT = "", found = false
*/
Goにはzero valueの概念があるため、未初期化で中身が不定な変数というのは存在しません。
そのためos.Getenvが""を返す時、環境変数が設定されていなかったのか、それとも空(export GOPATH=)が設定されていたのかわかりません。
設定されていたかまで判定したい場合はos.LookupEnvを使用します。第二返り値がtrueであるとき環境変数が設定されています。
os.Setenv / os.Unsetenv
環境変数をset/unsetするにはos.Setenv / os.Unsetenvを呼びます。
os.Setenv("SERVER_URL", "https://exmaple.com")
ただしunixにおいてはSetもUnsetも前述のコピーされたenvironを書き換えるので、プログラム起動時のenvironはそのままメモリ領域に残っています。
SetやUnsetをした後でも/proc/$pid/environの内容は変わらないことからこのことがわかります。
github.com/caarlos0/env
環境変数をstructにバインドしたい場合、筆者はgithub.com/caarlos0/envを使います。
使い勝手がよくてすごいライブラリなんですが機能追加が破壊的とみなされていて毎リリースのレベルでメジャーバージョンが上がります。
環境変数の解析はプログラムのエントリポイント近くで行うのでメジャーバージョンが上がっても困りにくいので大丈夫ですかね?
詳細はモジュール自身のREADME.mdに譲るとして、コード例を以下にしまします。
package main
import (
"fmt"
"net/url"
"os"
"time"
"github.com/caarlos0/env/v11"
)
type config struct {
GOPATH string `env:"GOPATH"`
SERVER_URL *url.URL `env:"SERVER_URL,notEmpty"`
T1 time.Time `env:"T1"`
List []string `env:"LIST" envSeparator:":"`
}
func main() {
os.Setenv("SERVER_URL", "https://exmaple.com")
os.Setenv("T1", "2022-03-06T12:23:54+09:00")
os.Setenv("LIST", "foo:bar:baz")
var c config
err := env.Parse(&c)
if err != nil {
panic(err)
}
fmt.Printf("GOPATH = %s\n", c.GOPATH)
fmt.Printf("SERVER_URL = %s\n", c.SERVER_URL)
fmt.Printf("T1 = %#v\n", c.T1)
fmt.Printf("LIST = %#v\n", c.List)
/*
GOPATH = /go
SERVER_URL = https://exmaple.com
T1 = time.Date(2022, time.March, 6, 12, 23, 54, 0, time.Location(""))
LIST = []string{"foo", "bar", "baz"}
*/
// (time.Parse()は$TZや`/etc/localtime`などの時間に関する環境の影響を受ける。
// この環境はどちらも設定されていないのでtime.Location("")となる。
// この辺の挙動はけっこうややこしいので
// 対象読者も早いうちにtimeのクセに引っ掛かってしまうかも)
}
そのほかの方法
詳細な説明は省きますが、ほかのライブラリを利用してももちろん良いです。
-
github.com/spf13/viperの
BindEnv/AutomaticEnv機能を用いる- すでに読み込まれたconfigと同名の環境変数をcase-insensitiveで読み込む機能があります。超便利です。
環境変数に設定すべきでないものは何か
環境変数は通常であればchild processにすべて引き渡されるのでセキュリティー的に敏感な情報は設定しないほうがいいかもしれません。
前述通り、unix系の環境ではunsetしても環境変数はメモリの先頭に残り続けるので、短命であるべき情報は特に環境変数として引き渡してきてはいけないことになります。
セキュリティー関連の記事を見ると、パスワードなどのcred情報はファイルやsecret storeから読み取り、使い終わったらメモリから即座に消すべき、というのをたびたび目にします。
現実的にメモリを読まれる状況まで行けば何でもされてしまうと思うので問題になりにくいかもしれないですが、アドバイスとして述べておく価値はあるでしょう。
おわりに
筆者は実際にGoを書きだす前に最も気にしていたエラーハンドリング周りを説明し、ファイルの読み書き、jsonとデータ構造の相互変換、go:generateによるコード生成の整備、cliフラグの解析方法と環境変数の読み込み方について書きました。
特にエラーハンドリング周りはアップデートが何度が起きており、Effective Goはerrors.Is / errors.Asに触れませんし、当然Go 1.20より interface { Unwrap() []error }がerrorsパッケージに認識されるようになったことでエラーチェインが木構造をもてるようになったことも述べられません。
特にos.IsNotExistの代わりにerrors.Is(err, fs.ErrNotExist)を使うべき、などは(はっきりドキュメントされているが)ちょっと気付きにくいので強調しておきました。
これで既存コードやライブラリをインポートして呼び出し口を整えてツールを作りだすことはできるはずです。
- part1 プロジェクトを始めるまで編
- part2 cliアプリをつくれるところまで編: これ
- part3 concurrent GO編
- part4 HTTP server/logger編
Discussion