Go の copy はいかにして実装されるか
Go で slice から別の slice に要素をコピーする際にはたいてい builtin 関数の copy を使用しますが、中身がどのように実装されているかは普段あまり意識しないと思います。そこで中身を深ぼっていったところいろいろと面白い発見があったので共有したいと思います。
本記事では次のことが学べます。長い記事となっていますので、ぜひお時間のある時にお読みいただければなと思います。
- builtin 関数の読み解き方
- Go アセンブリの読み書き方
- Go と Plan 9 の間にある、とある OS の話
- SIMD 最適化の手法
- アクセシビリティに配慮した作図
まずはとっかかりとして builtin 関数の実装の起点を探します。少し調べてみると、builtin 関数の使い方は GoDoc があるのでそれを読めば良さそうです。ただ実装自体はこのドキュメントからは明示的に辿れません。実は builtin 関数は、実装がそのままどこかにあるわけではありません。引数に取れる型を柔軟にするために、字句解析、構文解析、抽象構文木(AST)生成までは builtin 関数を1つのシンボル(ノード)のように扱い、AST から SSA(Static Single Assignment form)、延いては Go アセンブリを生成する際に builtin 関数の引数に対応した Go アセンブリを自動生成するようになっています。
ではその自動生成しているコードはどこを読めばよいかというと、builtin 関数の AST におけるノード表現が src/cmd/compile/internal/ir/node.go に定数で宣言されているので、これを元に検索すれば良さそうです。特に builtin 関数の copy は ir.OCOPY に対応しているので、これ元に検索します。
するとエスケープ解析したり、引数の型チェックをしたりしている箇所もありますが、メインの処理を呼んでいるのはここ、もとい workCopy であることが分かります。
workCopy の説明を読むと、Go のコードを
copy(a, b)
としたときに、生成される Go アセンブリは疑似コードで
init {
n := len(a)
if n > len(b) { n = len(b) }
if a.ptr != b.ptr { memmove(a.ptr, b.ptr, n*sizeof(elem(a))) }
}
n;
となっているので、つまるところコピーを行っている実態は runtime.memmove [1]になります。
次に memmove がどこで実装されているか検索する必要がありますが、typecheck.LookupRuntime("memmove") とある通り runtime パッケージにその実態があるか確認しているコードがあるので、目で追う際もコードと同じく runtime パッケージを探せば良さそうです。すると ここ に function body なしで宣言されていることが見て取れます。ご存知の方も多いかと思いますが、Go Spec にも載っているとおり、Go のコードの時点では function body を書かずに、アセンブリなど Go の外側で function body の中身を書くことができます。
A function declaration without type parameters may omit the body. Such a declaration provides the signature for a function implemented outside Go, such as an assembly routine.
function body なしの宣言と function body の中身のつなぎ合わせは、コンパイル後のリンクの過程でお互いのシンボルを照合して行います。
ここまでの処理は go build を行うことで自動的に行われるので、ユーザー視点では特に runtime の中身やコンパイル過程、リンカについて意識する必要はありません。
それではアセンブリで記述される runtime.memmove の中身を深ぼっていきます。
runtime.memmove の実態はアセンブリで記述されていることからも分かるとおり、各アーキテクチャ毎(と一部 OS 毎)に別々に実装されています。
それぞれの実装を見ていっても、それはそれで楽しかったり、新しい発見がありそうですが、本記事では筆者が個人的に一番面白いと思った amd64 の実装を見ていきます。なお Go のバージョンは明記しない限り 1.18 とします。
コードを読み始めて一番最初に目につくのは、ヘッダコメントにある Inferno と bitbucket への URL ではないでしょうか。
// Derived from Inferno's libkern/memmove-386.s (adapted for amd64)
// https://bitbucket.org/inferno-os/inferno-os/src/master/libkern/memmove-386.s
実は各アーキテクチャ向けの memmove の実装のほとんどは Inferno と呼ばれる OS のカーネルライブラリに含まれるコードがベースとなっています。
ここで Inferno について少し解説します。1995年ごろに AT&T ベル研究所より開発がスタートした Inferno は、同じくベル研で研究開発が進められていた Plan 9 で培った成果を元に、より幅広いデバイスやネットワーク、アーキテクチャに対応した分散 OS です。Plan 9 の開発には Go の生みの親である Rob Pike が関わっていたのですが、Inferno にも Rob Pike が関わっています。現在では開発自体はほぼストップしているのですが、2005年初めにフリーライセンスのもとOSS化、2021年3月にMITライセンスで再ライセンスされていることから、メンテナンスはされているのかなと思われます。
Inferno のカーネル部には、幅広い環境ごとの差異を吸収して Write once, run anywhere(WORA) でプログラムを動作させるため、Dis と呼ばれる仮想マシンが実装され、Inferno 上で動作するアプリケーションは Dis バイトコードに変換されて実行されます。また、アプリケーション開発用言語として Limbo が開発され、これが Inferno 上でアプリケーション開発を行うための、事実上の標準言語となっています。
Inferno は動作タイプとして主に CPU 上で直接動作する組込タイプと、既存 OS 上で動作する仮想環境タイプの2種類があり、前者のタイプに対応している CPU には x86, ARM, PowerPC, MIPS, SPARC などがあり、後者には Window NT, Windows 95, Unix, Plan 9 などがあります。その移植性の高さから、有志で Nintendo DS で動作させる猛者もいるほどです[2]。
こう聞くと、Inferno は OS というより Java に近い仮想マシンなのかなという印象を抱くと思います。それもそのはず1996から1997年にかけてすでにシェアを伸ばし始めていた Java の競合相手して公開されているのです。Java もInferno(Limbo) も WORA でそれぞれ JVM、Dis といった仮想マシン用バイトコードを生成して実行する点においては共通しているのですが、大きな違いとして、JVM はスタックマシン、Dis はレジスタマシンで設計思想が違います。一般的に、スタックマシンはレジスタマシンに比べ実装が容易なのに対し、プロセッサのアーキテクチャに則っていないため JIT コンパイルや複数コアでの並列実行がしにくいという欠点があります(スタックマシンに対するレジスタマシンのメリデメはこの逆です)。ちなみに Android の VM であった Dalvik も Java から変換されたバイトコードを実行しますが、レジスタマシンで実装されています。
閑話休題。
結局のところ Inferno のカーネルライブラリをベースに Go の runtime.memmove が実装された歴史的背景については分からなかったのですが、Inferno の歴史や設計思想から、Go の生みの親である Rob Pike が Inferno に精通していたこと、Inferno が Go と同じくクロスプラットフォームで動作すること、組込で動作するレジスタマシンであったことがベースになった理由なのではないかと考えられます。
さて、Inferno について話が逸れましたが、いよいよ runtime.memmove の処理手順を追っていきます。上記で述べた通り、数ある中で amd64 の実装を見ていきます。細かい注意点ですが、コード自体は amd64 アセンブリで記述されているわけではなく、amd64 アセンブリへ変換しやすい形式で記述された Go アセンブリです。Go アセンブリの読み書きについては本記事の趣旨ではないので以下の2つの記事をご参照ください。
まずは runtime.memmove のエントリーポイントから引数を受け取るところまで(L35-L41) を読みます。
Go1.16 あたりから関数呼び出しを高速化・最適化するためレジスタベースの呼出規約がサポートされました。runtime に実装される builtin 関数などの低レイヤ関数は引数をスタックからレジスタで渡すように変更されてきましたが、呼出規約が変わると後方互換性がなくなるので、移行中または移行済の関数には <ABIInternal> が付いています。
どのレジスタを使うかは以下のプロポーザルにまとまっています。
runtime.memmove は呼出前に、slice をコピーする際に必要となる情報を引数で渡すために、その情報をあらかじめレジスタに格納しておきます。渡す引数は「コピー先の slice」「コピー元の slice」「コピーするサイズ」の3つであるため、呼出側からアクセスできるようにポインタに変換した後 AX, BX, CX レジスタに格納します。そして呼出側の runtime.memmove 冒頭では、それらを使って計算するためにそれぞれ DI, SI, BX レジスタに移しています。
コピーに必要な情報がレジスタにそろった後は、いよいよコピー処理が始まります。runtime.memomove の処理はコピーするデータサイズや実行するプロセッサが対応している命令セットから大きく次の3つのタイプに分かれます。これらは完全に独立しているわけではなく、組み合わせて用いられます。
- ループアンローリングタイプ
- ループタイプ
- AVX タイプ
ループアンローリングタイプ
slice のコピー操作の基本形はループタイプなのですが、処理の順番通りに話を進めるため、ループアンローリングタイプから見ていきます。
ループアンローリングタイプはその名の通りループを展開して直接処理手順を書き下すタイプです。なぜ展開するかというと理由は主に2つあって、1つはコピーするデータが比較的小さい場合、ループをするためにループカウンタを保持・計算するコストが高くつくケースを回避するためで、もう1つは全て書き下すことで複数のデータに対する命令をまとめて行ういわゆる SIMD 命令を有効に扱うためです。これらによりループを行うよりはるかに少ない命令数でコピー操作が行え、高速化が見込めます。
どのようにアンローリングを行うかはコピーするデータサイズごとに変わり、実際に先ほどのレジスタ初期化後の L54-L73 で分岐しています。
TESTQ BX, BX
JEQ move_0
CMPQ BX, $2
JBE move_1or2
CMPQ BX, $4
JB move_3
JBE move_4
CMPQ BX, $8
JB move_5through7
JE move_8
CMPQ BX, $16
JBE move_9through16
CMPQ BX, $32
JBE move_17through32
CMPQ BX, $64
JBE move_33through64
CMPQ BX, $128
JBE move_65through128
CMPQ BX, $256
JBE move_129through256
コピーするサイズが比較的小さい場合、具体的には 0 から 16 バイトまでは MOVB, MOVL, MOVQ を使ってそのままコピーを行います。
move_9through16:
MOVQ (SI), AX
MOVQ -8(SI)(BX*1), CX
MOVQ AX, (DI)
MOVQ CX, -8(DI)(BX*1)
RE
17 から 256 バイトまでは MOVOU を使って SIMD 演算を行っています。ちなみに MOVOU は Go アセンブリ独自の命令で、amd64 では MOVDQU、つまり 128 ビット整数演算を行う SSE が呼ばれます。さらに言うと X0 から X15 は SIMD 演算に使われるレジスタです。
move_65through128:
MOVOU (SI), X0
MOVOU 16(SI), X1
MOVOU 32(SI), X2
MOVOU 48(SI), X3
MOVOU -64(SI)(BX*1), X4
MOVOU -48(SI)(BX*1), X5
MOVOU -32(SI)(BX*1), X6
MOVOU -16(SI)(BX*1), X7
MOVOU X0, (DI)
MOVOU X1, 16(DI)
MOVOU X2, 32(DI)
MOVOU X3, 48(DI)
MOVOU X4, -64(DI)(BX*1)
MOVOU X5, -48(DI)(BX*1)
MOVOU X6, -32(DI)(BX*1)
MOVOU X7, -16(DI)(BX*1)
RET
Go アセンブリと amd64(x86_64) の命令セットの対応表は以下の CSV や Go のコードからご覧になれます。
ここで例に挙げた move_65through128 のコピー方法が一見何をしているのか分かりにくいなと思ったので、一つ一つ嚙み砕いて見ていきましょう。
コードの読み方は、MOVOU (SI), X0 は「SI レジスタのアドレスが指すメモリの値を X0 レジスタにコピーする」、逆に MOVOU X0, (DI) は「X0 レジスタの値を DI レジスタのアドレスが指すメモリにコピー」というのは他の AT&A 形式のアセンブリ言語と同様なのですぐにわかると思います。また、MOVOU 16(SI), X1 は「SI レジスタから +16 バイトオフセットしたアドレスが指すメモリの値を X0 レジスタにコピーする」というのも同様です。
一方で MOVOU -64(SI)(BX*1), X4 のようなアドレスの後ろにさらに括弧がある形式はあまり見かけない形式だと思いますがどう読めば良いでしょうか?これは「SI レジスタから -64 バイトオフセットして、さらに BX*1 バイトだけオフセットしたアドレスが指すメモリの値を X0 レジスタにコピーする」と読みます。
この2回オフセットする形式を実際にコードが実行される場合に当てはめて読んでみると、BX==65 の場合は、「SI レジスタから -64+65*1=+1 バイトオフセットしたアドレスが指すメモリの値を X0 レジスタにコピーする」となり、BX==128 の場合は、「SI レジスタから -64+128*1=+64 バイトオフセットしたアドレスが指すメモリの値を X0 レジスタにコピーする」となります。
文字だけではあまりピンとこないと思うので、図に書き下してみました。

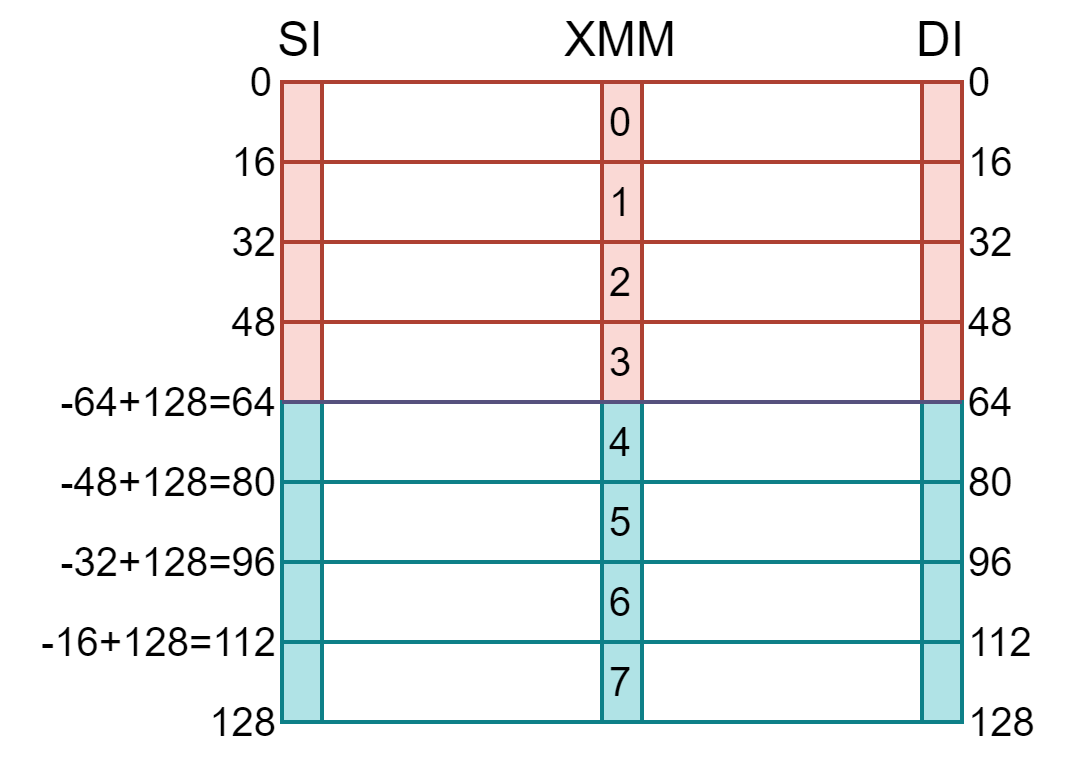
1つ目の図が BX==65 の場合、2つ目の図が BX==128 の場合です。図の見方を簡単に説明します。まず SI および DI の列はメモリを表し、左右の数字はそれぞれのレジスタからのオフセット位置を表しています。次に X の列は、X1 から X8 までのレジスタを表しています。そしてそれらを繋ぐ線は、例えば SI のアドレスを起点として 0 から 15 バイトまでのメモリの値を X0 レジスタにコピーし、X0 レジスタの値を DI のアドレスを起点として 0 から 15 バイトまでのメモリにコピーすることを表します。
図の配色についても補足します。コピーする領域の前半を赤、コピーする領域の後半を青で表現しています。ただ BX==128 の場合は、コピーする領域の前半・後半で重複していないのですが、BX==65 の場合は重複しているため、重複する領域は紫で表しています[3]。
ところで分岐先には 256 から 2048 までに対応したループアンローリングされたコードがあるのですが、L54-L73 の分岐で使用されていないことに気付いたと思います。実はここのコードは、コピー領域を 256 バイトずつに分けてコピー&自前でループし、端数分は tail に戻ってコピーしているので、ループタイプの一種として考えることができます。
また、コピーするデータサイズが 2048 バイト以上の場合の分岐はないのかと思うかもしれませんが、実はコピーするサイズが 2048 を超えるとアンローリングせずにループを回したほうがベンチマークをとった結果早かったので、分岐がないそうです。
ループタイプ
2つ目はループタイプについて見ていきましょう。
ループアンローリングタイプと AVX タイプはループタイプをより効率的に実行するために考案された手法で、ループタイプが基本形となります。ループタイプはコードのヘッダコメントにあった通り Inferno のカーネル部のコードがベースになっています。
実際にアセンブリを見ていく前に、Inferno に C 言語実装もあるので、まずはそちらを見てからループタイプのイメージを掴みましょう。
void*
memmove(void *a1, void *a2, ulong n)
{
int m = (int)n;
uchar *s, *d;
d = a1;
s = a2;
if(d > s){
s += m;
d += m;
while(--m >= 0)
*--d = *--s;
}
else{
while(--m >= 0)
*d++ = *s++;
}
return a1;
}
細かい型の説明や初期化処理はさておき、処理の流れを追っていきます。といっても読み解くのはそこまで難しくはありません。if文の前半は、コピー元・コピー先の位置から +m だけオフセットし、つまりコピー領域の末尾に移動し、コピー領域の先頭に向かって順番にコピーしています。一方でif文の後半は、コピー領域の先頭から末尾に向かって順番にコピーしています。
単純にコピーするだけなら後半の方法だけでコピーできると思うかもしれません。実際のところコピー元とコピー先の領域がかぶっていなければ後半の方法だけで十分です(もちろん前半だけでも十分です)。しかし、コピー先の先頭位置がコピー元の先頭位置より前にあり、かつ領域がかぶっている場合、後半の方法でコピーをしてしまうと、かぶっている領域をコピーする際にコピー元のデータはすでにコピー先のデータに置き換わっているので、そのままコピーをしてしまうとコピー先からコピー先にコピーをするというよくわからない現象が起きてしまいます。
ちなみに Go アセンブリではif文の前半・後半の処理の名前をコピー走査の向きからそれぞれ back/forward と呼んでいます。
ではその back/forward 処理を見ていきましょう。
処理は Go アセンブリのコードの L81 から始まります。
/*
* check and set for backwards
*/
CMPQ SI, DI
JLS back
L81 は先ほどの C 言語のコードの if 文にあたります。CMPC で SI と DI を比較する、言い換えるとコピー元の先頭位置がコピー先より小さいまたは同じ場合は[4]、JLS[5] によって L114 の back 処理にジャンプし、そうでない場合はそのまま L87 の forward 処理に入ります。
まずは back 処理を見ていきます。
/*
* check overlap
*/
MOVQ SI, CX
ADDQ BX, CX
CMPQ CX, DI
JLS forward
最初の check overlap ではコピー元・コピー先の領域がかぶっているかどうか確認しています。そしてかぶっていない場合は、forward にジャンプします。前述したとおり領域がかぶっていなければ forward/back どちらの処理でコピーを行っても構わないので、そのまま back の処理を続ければよいと思うかもしれません。ただそれは C 言語での話で、Go アセンブリの forward は back に比べいくつか最適化が施されているので、できる限り forward で処理を行います。その最適化については forward の処理を見ていく際に説明します。
続きを見ていきます。L126-L127 ではコピーを末尾から先頭に向かってコピーしていくためにオフセットしているのは、C 言語のコードで見てきた通りです。
L128 からはいよいよ back の処理を行っていきます。リンク先のコードを見て、「あれ?コピーって L133 から行うんじゃないの?」と思うかもしれませんが、L128 の STD の時点からコピーを繰り返し行うための準備が始まっています。
STD
/*
* copy
*/
MOVQ BX, CX
SHRQ $3, CX
ANDQ $7, BX
SUBQ $8, DI
SUBQ $8, SI
REP; MOVSQ
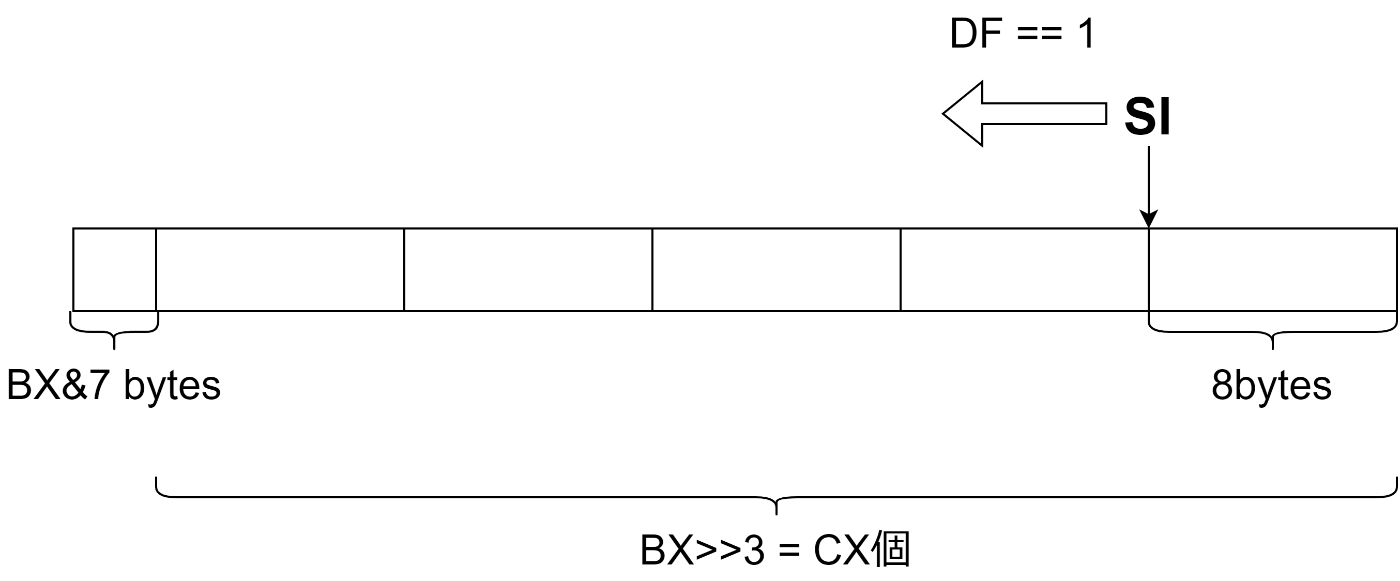
実際にコピーを行うのは REP; MOVSQ 、すなわち REP(繰り返し) MOVSQ (8 バイトコピー)ですが、仕様が「CX 回 DF が立っているときは SI, DI をデクリメントしながら、立っていないときはインクリメントしながら SI が指す位置から DI が指す位置に MOVSQ で値をコピーする」となっているので、CX を準備したり、8 バイトずつコピーしていくので SI, DI の指す位置オフセットしたり、STD で DF レジスタを立てたりして繰り返しコピーの前処理をしています。
コピーは 8 バイトずつ行うため、当然そのままでは数バイト分(正確には BX&7 バイト)コピーできないので、tail に戻って残りの数バイト分をコピーします。
CLD
ADDQ $8, DI
ADDQ $8, SI
SUBQ BX, DI
SUBQ BX, SI
JMP tail
コピーの流れを図に表すと次のようになります。DI の動きは SI とほぼ同じなので省略しています。
これで back 処理は完了です。次に forward 処理を見ていきましょう。
forward 処理は上述した通り、いくつかの最適化を行っており、さっそく L88-L89 では、コピーするサイズが 2048 バイト以下の場合はループアンローリングしたほうが処理速度が速いため move_256through2048 にジャンプしています。
2048 バイトより大きい場合は、ループアンローリングをすると遅くなる傾向にあるため[6]、そのままループしてコピーします。
// If REP MOVSB isn't fast, don't use it
CMPB internal∕cpu·X86+const_offsetX86HasERMS(SB), $1 // enhanced REP MOVSB/STOSB
JNE fwdBy8
// Check alignment
MOVL SI, AX
ORL DI, AX
TESTL $7, AX
JEQ fwdBy8
// Do 1 byte at a time
MOVQ BX, CX
REP; MOVSB
RET
それではどのようにループ&コピーをしているかというと、ここでも細かく3つの分岐があります。
1目は L92-L93 で、コードを実行している CPU に ERMSB すなわち enhanced REP MOVSB/STOSB が実装されていなければ fwdBy8 にジャンプします。
ERMSB は Ivy Bridge[7] から導入された機能で、導入以前は REP MOVSB/STOSB つまり 1 バイトずつループ&コピーをする処理はスループットが低く忌避されていたのですが、導入後はいくらか高速にコピーできるようになったため、ERMSB が有効になっている場合に限り使用されることもあるみたいです[8]。
fwdBy8 は 8 バイトずつコピーして端数は tail に戻って処理を行うのですが、back で見てきた内容とほぼ同じなので、ここでは詳細の説明は省略します。
ERMSB が実装されている場合は、2つ目の分岐 L96-99 に入っていきます。ここでは SI と DI のアドレスの下位 3 ビットが 0 の場合 fwdBy8 にジャンプし、どちらか一方でも 0 でない場合(unalignment と言います)はジャンプせずに3つ目の分岐に入っていきます。
その3つ目の分岐は L102-104 で、1 バイトずつコピーしていきます。
ここの3つの分岐は少し複雑で分かりにくかったと思うのでまとめると、
- ERMSB が有効でかつ unalignment の場合、
REP; MOVSBで 1 バイトずつコピーする - そうでない場合、
fwdBy8で 8 バイトずつコピーする
となります。
余談ですが、ここの分岐は、実質的な処理の変更日が2016年(Go1.7)頃とだいぶ前なので[9]、現在生産・使用されている CPU や、CPU の使用用途に合わせてもう少し細かくベンチマークを取ることで、チューンナップできる余地がありそうだなと筆者は感じました。
AVX タイプ
いよいよ最後のタイプ、AVX タイプの説明をしていきます。さっそくコードを深ぼっていきましょう、と言いたいところですが、実はコードの流れを読み解くための知識は前2つのタイプを組み合わせれば充足することができます。なのでここでは前2つのタイプでは足りない知識を箇条書きで補足するのに留めます。
- 分岐の開始位置は L75-L76で、
runtime·useAVXmemmoveが有効かどうかでジャンプするかを決めます。 -
PREFETCHNTAはキャッシュを効かせるために事前にメモリからデータをロードする手法で、Intel® の最適化マニュアルにも経験的に有効であることが示されていますが、なぜこれらの数値が選択されたかは分かりませんでした(過去の glibc には似たようなコード片がありました。ただそこでもなぜそうしているかの理由は記載されていませんでした)。 -
CMPは演算結果を捨てたSUBと同じ命令とみなすことができるので、SUBをした演算結果の状態によって分岐したい場合は、再度CMPを呼ぶ必要はありません。 -
R11 = ((DI & -32) + 32) - DIはコピー開始アドレスを切り良くするための演算で、DIが32 の倍数になる次の整数を計算しています(ただしDIがすでに 32 の倍数の場合DI + 1となります)。 - AVX タイプのコピーは、コピー領域を3つの領域 Head, Body, Tail に分割して行います。
- Body はコピー領域の先頭と末尾のアドレスが切り良くかつ最大になるように取られた領域で、AVX 命令を使って高速にループ&コピーします。
- Head はコピー領域の先頭から Body の先頭までの領域で、端数処理を行います。
- Tail は Head の末尾からコピー領域の末尾までの領域で、端数処理を行います。
-
VZEROUPPERはYMMレジスタの上位ビットを 0 にする命令です。AVX 命令と SSE 命令はベクトル演算器を共有していて、SIMD 演算中は CPU 内のベクトル演算モードが AVX モードと SSE モードに自動的に切り替わるようになっているのですが、一連の AVX 命令を実行し終えた後にVZEROUPPERをし忘れていると、その後の SSE 命令実行中に AVX 命令を実行していないにも関わらず不意に AVX モードに移行して、パフォーマンスが落ちてしまいます。このパフォーマンス劣化は AVX-SSE Transition Penalties と呼ばれていて、公式資料にもVZEROUPPERを挿入することで回避できる旨が記載されています。 -
SFENCEは、アウトオブオーダやライトコンバインが効いていてもSFENCEより前の store 系命令が確実に実行され完了していることを保証するメモリバリアを行うための命令です。 - 通常 store 系命令はメモリに書き込む際にキャッシュにも書き込むのですが、
VMOVNTDQはキャッシュに書き込まずにメモリに書き込む命令です。巨大なデータをシーケンシャルにコピーするときなど、キャッシュをほぼ再利用しないと分かっているときにこの命令を利用すると書き込み速度が上がります。このキャッシュせずにメモリに store する命令は Non-Temporal(NT) stores と呼ばれています。ただし一連の NT stores 命令を実行後はまだ完全にメモリにデータが書き込み出来ていない場合があるので、SFENCEを呼んで書き込みが完了するのを待ちます。
AVX タイプのコードは非常に巧妙に実装されているのですが、一方で以下の改善点も見つかりました。
-
gobble_128_loopでのAXは定数として扱われているので、即値でも良さそう。 - AVX-512 を使った高速化が見込めそう。
本記事では builtin 関数の copy がどのように実装されているか、copy の宣言から Go アセンブリレベルまで細かく見ていきました。ご覧いただいた通り文章にすると結構な量になりましたが、やってることとしてはシンプルだったと思います。また今回は copy を見てきましたが、それだけでなく、他の builtin 関数を読み解く際や SIMD 最適な Go アセンブリを書く時など、Go における低レイヤに足を踏み入れたい方の参考になれば幸いです。
-
コードをよく読むと、何らかの計測時(race detector が有効になっている、など)には
runtime.slicecopyが呼ばれますが、この関数の前半で計測用のコードを実行しているだけで、結局大抵の場合runtime.memmoveが呼ばれます。 ↩︎ -
Inferno DS https://www.gamebrew.org/wiki/Inferno_DS ↩︎
-
アクセシビリティに配慮した配色にするのはなかなか難しい。
 ↩︎
↩︎ -
先頭位置がコピー先・元で同じ場合の条件分岐の扱いが C 言語の時と逆なことに注意が必要ですが、どのみちどちらに分岐しても処理結果は変わりません。 ↩︎
-
JLEとほぼ同じ意味です。 ↩︎ -
move_256through2048が実装されたのが2014年なので、もしかすると 2048 バイト以上でもループアンローリングしたほうが処理速度が速いかもしれません。ちなみにmove_256through2048を実装したのは rui314 さんです。 ↩︎ -
インテル® Core™ プロセッサー 第3世代 ↩︎
-
https://stackoverflow.com/questions/43343231/enhanced-rep-movsb-for-memcpy ↩︎
Discussion