初めての負荷試験で学んだこと
最近、仕事で初めて負荷試験を実施する機会がありました。
今回は、備忘録も兼ねてそのときに実施した負荷試験の手順と学びをまとめます。
少しでもこれから初めて負荷試験を実施する方の参考になれば幸いです。
前提: アプリの構成について
今回テストしたアプリの技術スタックは以下の通りです。
- TypeScript
- NestJS
- Prisma
- GraphQL
- Cloud Run
- Cloud SQL
Cloud Run上で動作していて、データ取得はCloud SQLからPrisma経由で行っています。
PHPで動作していた既存アプリからのリプレイスを行いました。
負荷試験の手順
負荷試験は以下の手順で実施しました。
- 負荷試験を実施するかどうかを決める
- 既存のリクエスト状況を再現する方法を決める
- シナリオを決める
- 負荷試験の合格基準を決める
- 負荷試験環境の構成を決める
- 負荷試験のシナリオを作成する(K6)
- 負荷試験を実施する
- チューニングを実施する
- 負荷試験の結果を反映させる
それぞれについて、具体的な作業内容をまとめていきます。
1. 負荷試験を実施するかどうかを決める
そもそも最初に、負荷試験を実施するかどうかを決める必要があります。
判断材料として、まず最初に現状のリクエスト状況を調査しました。
調査の結果、対象のアプリには秒間数十程度のリクエストが来ていることが判明し、大きな負荷がかかることが想定されたため負荷試験を実施することになりました。
2. 既存のリクエスト状況を再現する方法を決める
次に、負荷試験でどのように既存のリクエストを再現するかを考えました。
候補に挙がったのは以下の二つです。
① 本番環境のリクエストをLBでミラーリングして負荷試験環境(ステージング環境)に流す
② エンドポイント毎のリクエストの割合からリクエストを再現する
①は確実にPROとリクエスト状況を近付けることはできるのですが、LBのモードを新しいバージョン(グローバル外部アプリケーション ロードバランサ)に差し替える必要があったため、検証のコストが高いのと、差し替えによるサービスへの影響も大きいと判断して断念しました。
そのため、今回は②の「エンドポイント毎のリクエストの割合からリクエストを再現する」方式で進めることになりました。
3. シナリオを決める
アプリケーションに対するリクエストは、常に一定であることはほとんどありません。
今回の場合は、任意のタイミングでスパイクする可能性があると考えられたため、以下のシナリオでテストをすることにしました。
- 一定のリクエストが継続するパターン
- リクエストがスパイクするパターン
また、どの程度のリクエストに耐えられるかを把握しておくため、徐々にリクエスト数を増やしていく「限界値テスト」も実施しました。
4. 負荷試験の合格基準を決める
当たり前ですが、合格基準がないと負荷試験をクリアしたかどうかが分からないので、合格基準は定めておく必要があります。
今回は、レイテンシ・エラー率・インフラリソースのメトリクス(CPU・メモリ)の増加率を合格基準の項目に定めました。
e.g. 負荷試験の目標
- レイテンシが1s以内
- キャッシュなしで ◯◯req/sec を裁き切れる
- エラー率◯◯%以下
- Cloud Run, DBのCPU・メモリ使用量に大幅な増加がないこと
- CPU+◯◯%以内
- メモリ+◯GiB以内
この目標値は外部要因(e.g. ステークホルダーからの指定)などによっても変動するので、アプリ毎に適切な値を設定するようにしましょう。
5. 負荷試験環境の構成を決める
次に、負荷試験を実施する環境を決定します。
ここで考えないといけないのは、いかに本番環境と同じ状態に近付けるかです。
なぜなら、実際にサービスとして提供するのは、あくまで本番環境だからです。
いくらステージング環境で負荷試験をクリアしたとしても、ステージング環境のスペックが本番環境とかけ離れていたら、本番環境でも同じように動作する保証にはなりません。
今回は、なるべく本番環境と近づけるため、各インフラリソースのスペックや設定を本番環境と揃えました。
また、データーベースはデータ量や内容が異なるとクエリの負荷が変わってくるため、本番環境からデータをコピーして利用しました。
6. 負荷試験のシナリオを作成する(K6)
次に負荷試験のシナリオをK6で実装しました。
実装のポイントは以下の二つです。
- エンドポイント毎にメトリクスを取得する
- URLのパターンをなるべく増やす
エンドポイント毎にメトリクスを取得する
今回は複数のエンドポイントに対してリクエストを投げる要件がありました。
しかし、デフォルトだとK6はエンドポイント毎の細かいメトリクスは出してくれません。
そのため、Trendメトリックなどを使って、エンドポイント毎にメトリクスを出す設定を追加しました。
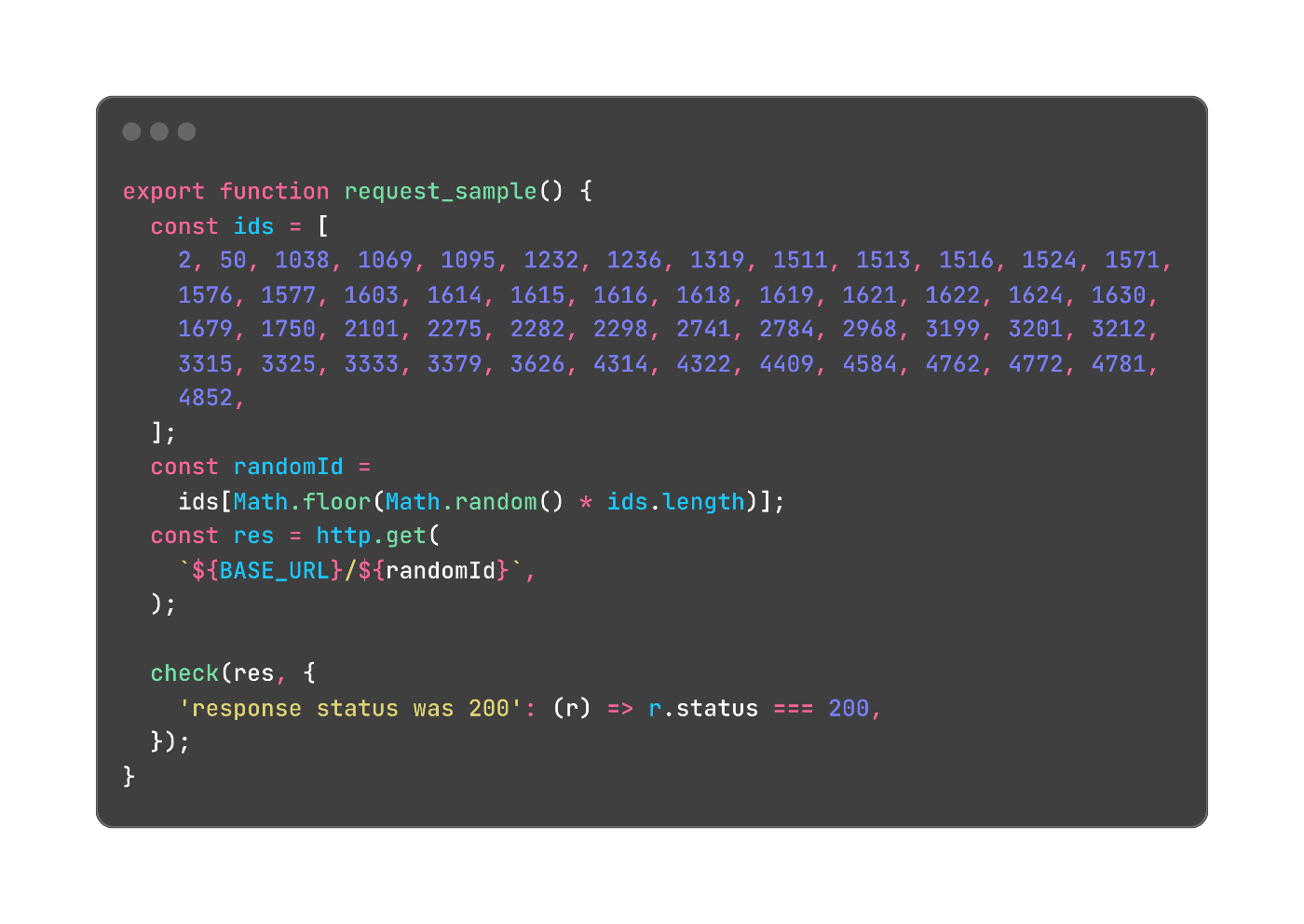
URLのパターンをなるべく増やす
実際の本番環境では、同じURLだけ叩かれることはありません。数多くのパターンのURLがランダムに叩かれます。
そのため、今回は以下のようにURLのIDを複数用意してランダムに叩かせることで、なるべく本番環境と同じ状況を再現しようと試みました。
同じURLだけを叩くと、キャッシュ(e.g. クエリキャッシュ)などにより正しくテストができない可能性もあるので、なるべく多様なパターンを用意する方がよいでしょう。
7. 負荷試験を実施する
6.で作成したK6のコードをVMインスタンスから実行することで、負荷試験を実施しました。(ローカルからだとPCが耐えられないと想定されたので、VM上にK6の環境を構築しました)
8. チューニングを実施する
K6の実行結果やGoogle Cloudのメトリクスを元にボトルネックを特定し、以下の流れでチューニングを行いました。
- クエリチューニング
- Prismaのコネクションの調整
1.については、Query InsightsやGoogle Cloudのメトリクスダッシュボードを使ってボトルネックを特定し、ひたすらクエリを直していきました。
具体的には、以下の対応を行いました。
- Prismaのクエリを生クエリに差し替え
- PrismaはJOINなどをした場合に複数のクエリが発行されるため実行速度が遅くなる場合がある
- やはり生クエリは速い..!
- GraphQLのN+1問題解消のため、DataLoaderを用いた実装に差し替え
2.についてはGoogle Cloud Managed Service for Prometheusを使ってPrismaのメトリクスを可視化した上で、Prismaのconnection_limitの調整を行いました。
こちらについては、Zennにも知見を共有してあります。
最終的にはこのconnection_limitの調整を行ったことで、パフォーマンスが劇的に改善し、負荷試験の目標値をクリアすることができました。
DBのCPUやメモリの状態に問題が無いにも関わらずアプリ側のレイテンシが改善しない場合は、アプリ側のコネクション数の設定を見直してみるのがおすすめです。
9. 負荷試験の結果を反映させる
負荷試験の結果をもとに各リソース(e.g. Cloud Run, Cloud SQL)のスペックを決定し、本番環境に反映させました。
その他負荷試験を実施する上での注意点
最後に負荷試験における注意点をまとめておきます。
インフラコストに気を配る
負荷試験もGoogle Cloud上で実行する以上、少なからずインフラコストはかかります。
実際のテスト時は仕方ないにしても、それ以外の時間はなるべくコストがかからないようにしましょう。
具体的には、以下の項目は最低限確認しておくとよいでしょう。
- K6を実行するVMインスタンスは負荷試験が終わったら停止する
- Cloud RunのAlways on CPUは負荷試験が終わったら無効(
run.googleapis.com/cpu-throttling: "true")にしておく - Cloud Runの最小インスタンス数は負荷試験が終わったら0(
autoscaling.knative.dev/minScale: "0")にしておく
負荷試験の結果を信頼し過ぎない
負荷試験の結果はもちろん参考にはなりますが、絶対的なものではありません。
例えば今回の場合は、負荷試験ではDBのCPUが上昇しメモリはほとんど変わりませんでしたが、実際のPRO環境に適用すると、逆にCPUはほとんど変わりませんでしたが、メモリは上昇しました。
そのため、負荷試験の結果を盲信するのではなく、疑ってかかった上で、メトリクスを一気に上げるのではなく少しずつ上げていくなどの緩和策を講じた方が安全だと思います。
おわりに
今回、個人的に負荷試験を実施する上で重要だと感じたのは、負荷試験環境をなるべく本番環境に近付けることと、なるべく多くのメトリクスを可視化することです。
前者は負荷試験結果の信頼性を上げるために重要で、後者はチューニングを効率よく行うために重要です。
方法や環境自体は全く同じ状況は訪れないとは思いますが、これらの考え方だけは今後も負荷試験をする上で持ち続けておきたいと考えています。
今回は以上です。
この記事が負荷試験を実施する上で少しでも参考になっていれば幸いです。
Discussion