Google Cloud Managed Service for PrometheusでPrismaのコネクション数をチューニングする




業務で Google Cloud Managed Service for Prometheus を使って Cloud Run で動作するアプリケーションの Prisma のコネクション数をチューニングする機会があったので、備忘録もかねて手順を共有します。
少しでも同じような状況の方の参考になれば幸いです。
環境情報
- Prisma: v5.10.2
- NestJS: v10.3.8
- TypeScript: v5.1.6
- Node.js: v20.12.2
- GoogleCloudPlatform/run-gmp-sidecar: v1.1.1
Prisma のコネクションについて
作業に入る前に、前提知識として Prisma のコネクションと Google Cloud Managed Service for Prometheus について解説します。
まずは、Prisma のコネクションについてです。
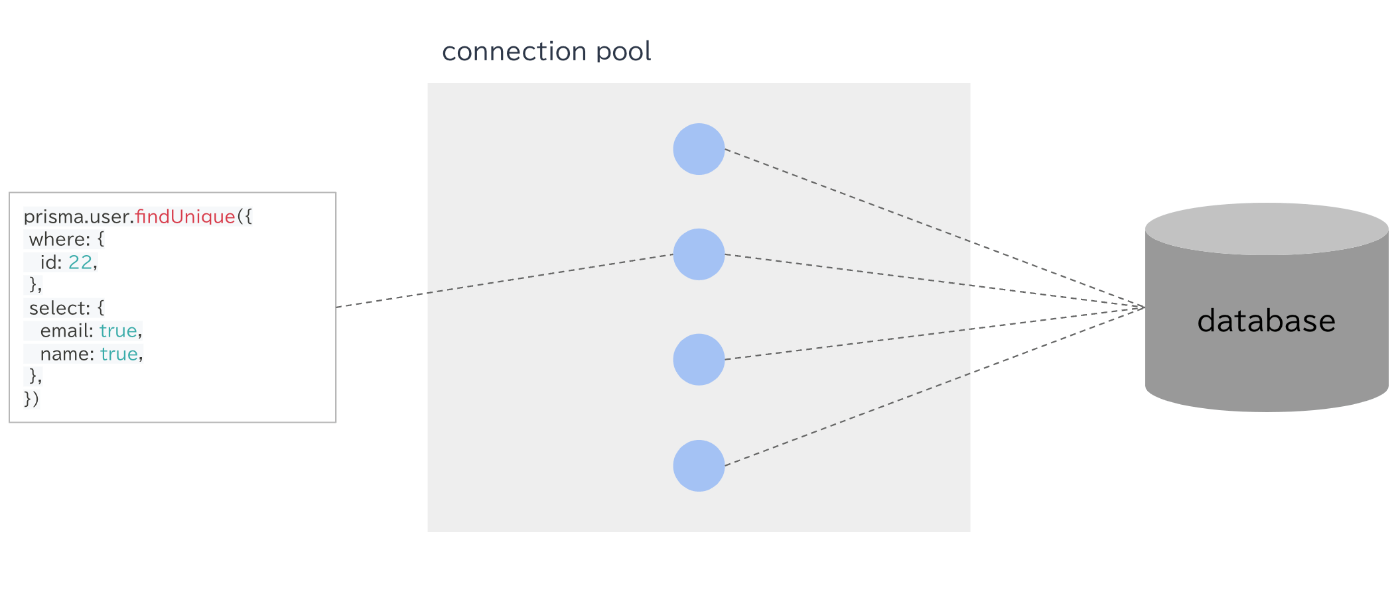
Prisma はコネクション・プールの仕組みを持っています。
コネクション・プールとは、DB との接続(コネクション)を保存して使い回す仕組みです。
クエリを実行する度に DB とのコネクションを確立する必要がなくなるので、うまく使えばレイテンシの改善が期待できます。
Prisma のコネクション数を指定する方法
Prisma は 1 PrismaClient インスタンスが 1 つのコネクション・プールを持っており、コネクション・プールが保持できるコネクション数は、データベース URL のconnection_limitパラメータで指定できます。
例えば、以下の場合、コネクション・プールは 4 つのコネクションを保持できます。
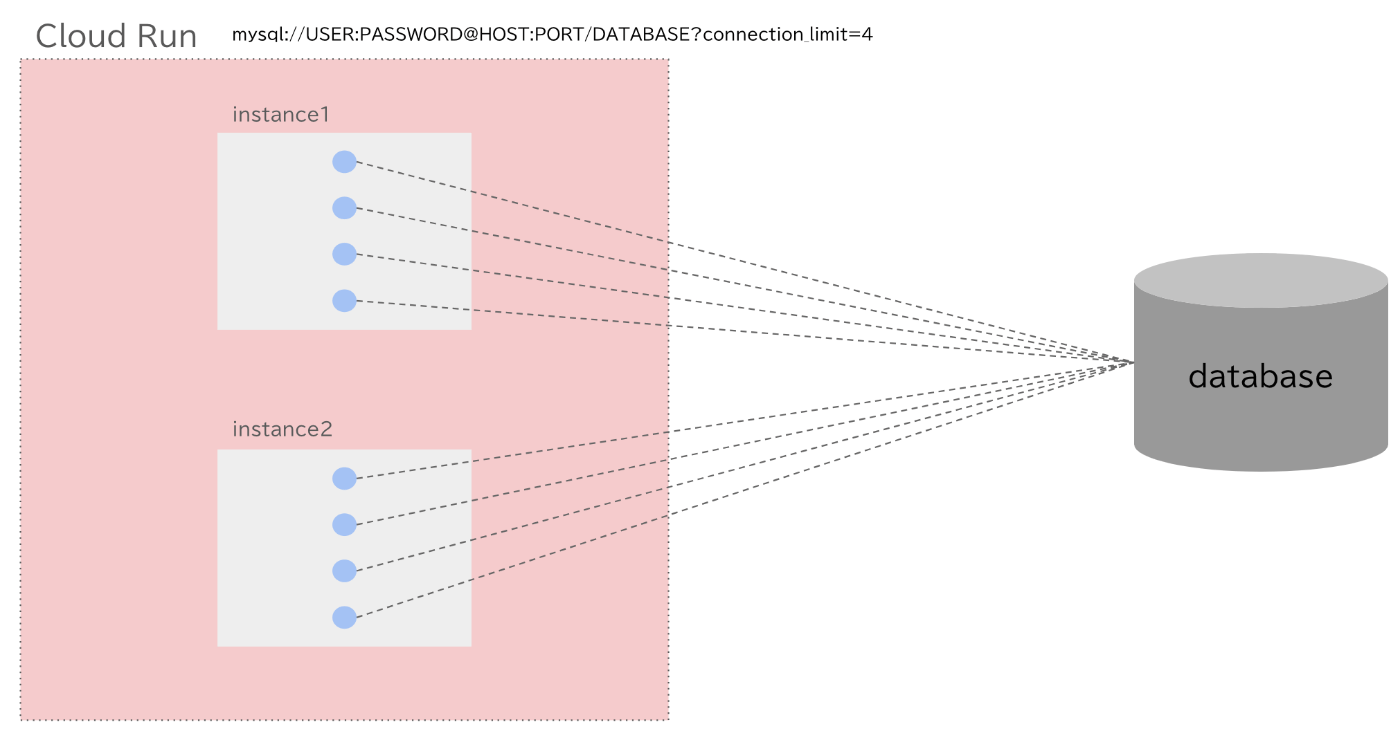
mysql://USER:PASSWORD@HOST:PORT/DATABASE?connection_limit=4
推奨される設定にしたがって、アプリケーション内で 1 つの PrismaClient インスタンスが作成されるようになっている場合、アプリケーションは最大 4 つのコネクションを保持できるということです。
Cloud Run の場合、1 インスタンス=1 アプリと考えることができるので、1 インスタンスで 4 つのコネクションを保持できます。
Prisma におけるコネクションチューニングの考え方
Prisma でコネクションをチューニングする上で最も重要なのは、いかにコネクションを効率よく使い回すかを考えることです。
Prisma のクエリとコネクションは以下の関係性を持っています。
- コネクション・プールに利用可能なアイドル状態のコネクションがない場合、クエリエンジンは、コネクションの数が
connection_limitで定義された上限に達するまで、追加のコネクションをオープンし、コネクション・プールに追加する - クエリエンジンが コネクション・プール からコネクションを予約できない場合、クエリーはメモリ内の
FIFO(First In First Out)キューに追加される。FIFO とは、クエリがキューに入った順に処理されることを意味する - クエリエンジンは、キュー内のクエリーを制限時間内に処理できない場合、そのクエリーに対してエラー・コード
P2024の例外をスローし、キュー内の次のクエリーに移る
つまり、クエリの数に対してコネクションの数が少ない場合、一部のクエリは「待ち状態」になります。
待ち状態になると、その分クエリが処理されるまでに時間がかかってしまいます。

そのため、いかに全てのクエリにコネクションを適切に振り分けて、クエリの待ち時間を短くするかがチューニングの鍵となるのです。
Google Cloud Managed Service for Prometheus について
Prisma のコネクション数をチューニングするためには、コネクション数などのメトリクスを可視化する必要があります。
そして、Cloud Run 上で動作するアプリケーションのメトリクスを可視化するために使用できるのが、Google Cloud Managed Service for Prometheus です。
Google Cloud Managed Service for Prometheus は、Google Cloud 上のアプリケーションから送信した Prometheus 指標(メトリクス)を可視化するためのツールです。
Prisma では メトリクス を Prometheus のフォーマットで送信することができるので、Google Cloud Managed Service for Prometheus と組み合わせることで、容易にメトリクスを可視化することができます。
Google Cloud Managed Service for Prometheus で Prisma のコネクション数をチューニングする手順
前提知識が揃ったところで、実際にチューニングの手順を見ていきます。
- アプリケーション側で Prometheus フォーマットのメトリクスを返すエンドポイントを作成する
- Cloud Run のサイドカーとして Managed Service for Prometheus を動作させる
- Cloud Monitoring の Metrics Explorer で Prisma のメトリクスを表示する
- Prisma のコネクション数をチューニングする
1. アプリケーション側で Prometheus フォーマットのメトリクスを返すエンドポイントを作成する
まずは、Prisma の設定ファイル(schema.prisma)で previewFeatures に metrics を設定します。
generator client {
provider = "prisma-client-js"
previewFeatures = ["metrics"]
}
次に、Prisma の Prometheus フォーマットのメトリクスを返すエンドポイントを作成します。
NestJS の場合は以下のようになります。
import { Controller, Get } from "@nestjs/common";
import { PrismaService } from "../prisma/prisma.service";
@Controller("metrics")
export class MetricsController {
#prisma: PrismaService;
constructor(prisma: PrismaService) {
this.#prisma = prisma;
}
@Get()
async get(): Promise<string> {
const prometheusMetrics = await this.#prisma.$metrics.prometheus();
return prometheusMetrics;
}
}
参考: Prisma Metrics
2. Cloud Run のサイドカーとして Managed Service for Prometheus を動作させる
次に、Cloud Run のサイドカーとして Managed Service for Prometheus を動作させます。
このサイドカーから先ほど作成したエンドポイントを定期的に叩くことで、メトリクスの時間変化を可視化することができます。
サイドカーは、デフォルト構成とカスタム構成を選択できます。
参考: サイドカーを構成して Cloud Run サービスに追加する
デフォルトだと、以下の設定でサイドカーが実行されますが、今回は port や interval を変更したいので、カスタム構成で設定します。
apiVersion: monitoring.googleapis.com/v1beta
kind: RunMonitoring
metadata:
name: run-gmp-sidecar
spec:
endpoints:
- port: 8080
path: /metrics
interval: 30s
まずは、以下のように Managed Service for Prometheus のサイドカーを設定します。
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: sample-app
spec:
template:
metadata:
annotations:
run.googleapis.com/container-dependencies: '{"prometheus-collector":["sample-app"]}'
spec:
serviceAccountName: sample-app@example.iam.gserviceaccount.com
volumes:
- name: PROMETHEUS_COLLECTOR_CONFIG
secret:
secretName: PROMETHEUS_COLLECTOR_CONFIG
items:
- key: "1"
path: config.yaml
containers:
- name: prometheus-collector
image: "us-docker.pkg.dev/cloud-ops-agents-artifacts/cloud-run-gmp-sidecar/cloud-run-gmp-sidecar:1.1.1"
volumeMounts:
- mountPath: /etc/rungmp/
name: PROMETHEUS_COLLECTOR_CONFIG
- name: sample-app
image: sample-app:xxxxx
command:
- /nodejs/bin/node
ports:
- name: http1
containerPort: 7000
resources:
limits:
cpu: 1000m
memory: 512Mi
Managed Service for Prometheus のカスタム設定(PROMETHEUS_COLLECTOR_CONFIG)は Secret Manager で設定します。
以下の値を Secret Manager に登録しましょう。(portやintervalなどは任意の設定に書き換えてください)
apiVersion: monitoring.googleapis.com/v1beta
kind: RunMonitoring
metadata:
name: run-gmp-sidecar
spec:
endpoints:
- port: 7000
path: /metrics
interval: 10s
この設定では、7000 ポートの/metrics エンドポイントに対して、10 秒ごとにリクエストを送り、メトリクスを収集します。
その他の詳細はこちらを参考にしてください。
3. Cloud Monitoring の Metrics Explorer で Prisma のメトリクスを表示する
以上により、Cloud Monitoring の Metrics Explorer で Prisma のメトリクスを表示できるようになっているはずです。
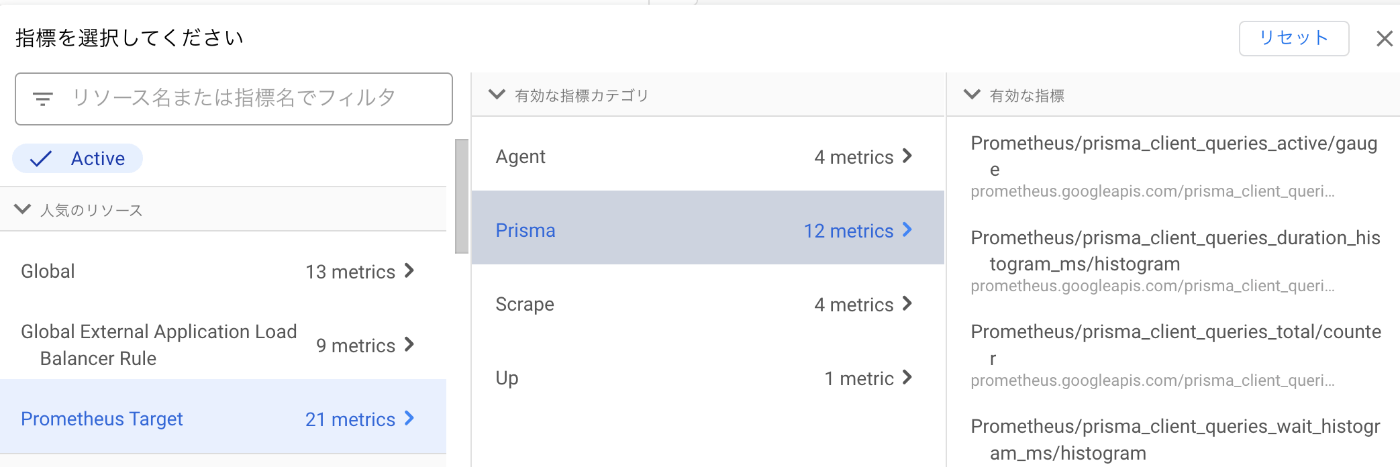
クエリを追加でPrismaのメトリクスを選択します。
対象のCloud Runのリビジョンやインスタンスで絞ることで、以下のようにメトリクスの時間変化を可視化することができるでしょう。
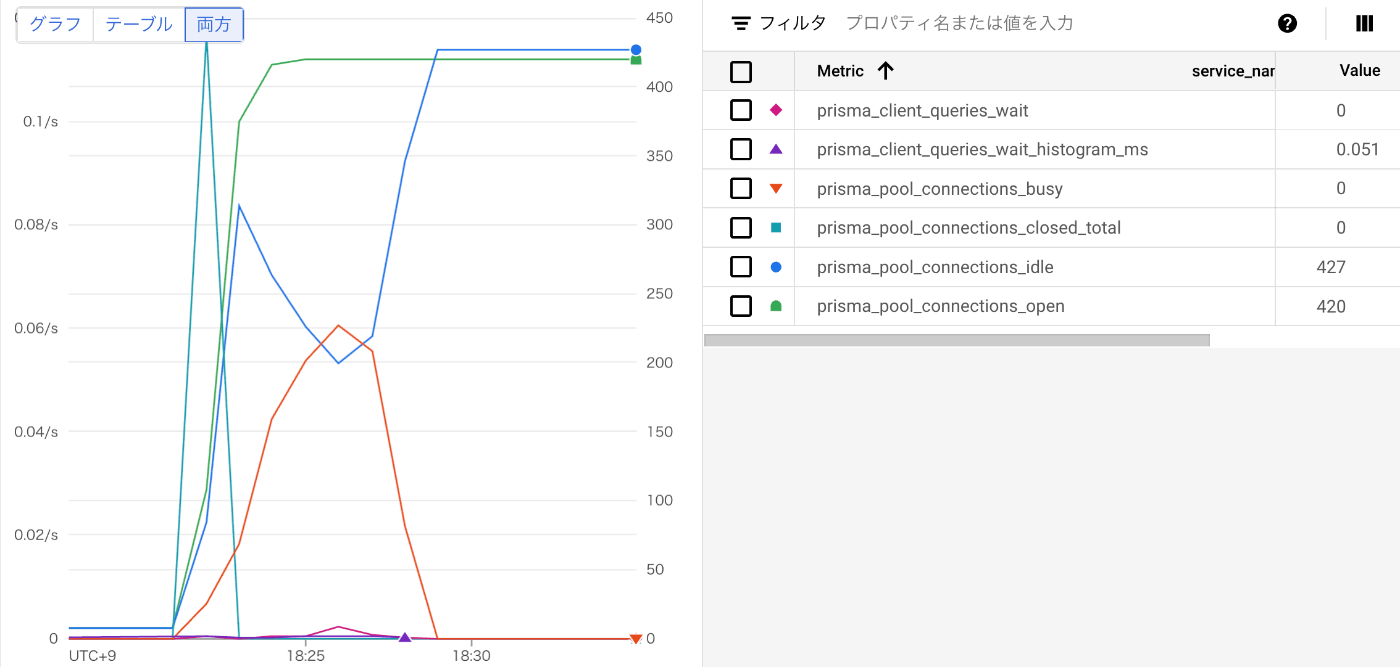
4. Prisma のコネクション数をチューニングする
Prisma では、コネクション数の調整に役立つメトリクスを提供しています。
中でも個人的に便利と感じているのは、prisma_client_queries_waitです。
これは、コネクションが空くのを待っているクエリの数を表示するメトリクスです。
つまり、この数が少なければ少ないほど、コネクションを効率よく各クエリに割り当てられているということになります。
クエリの待ち時間が短くなるので、レイテンシも改善するでしょう。
例えば、以下のグラフの場合、prisma_client_queries_waitの数が多いので、クエリを効率よく捌けていないということになります。
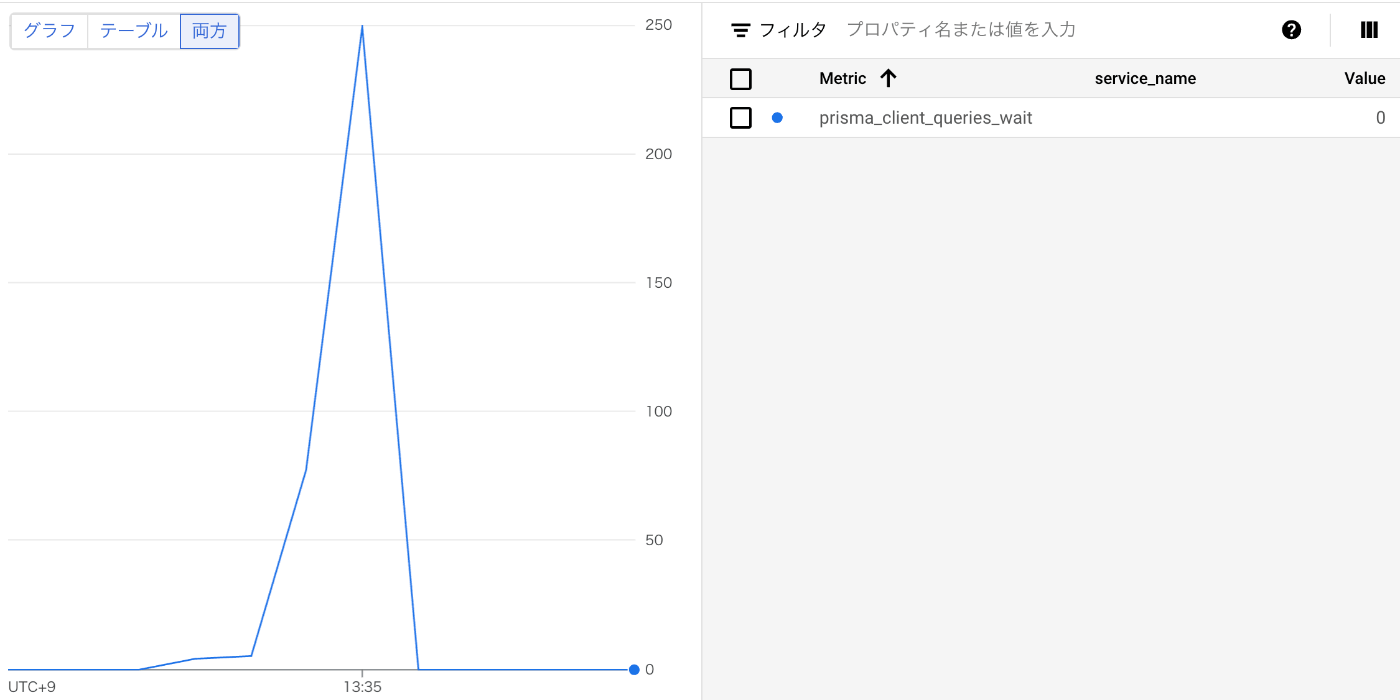
そこで、connection_limit の値を増やします。
すると、コネクションが適切にクエリに割り当てられるようになるので、prisma_client_queries_wait の数も減ります。
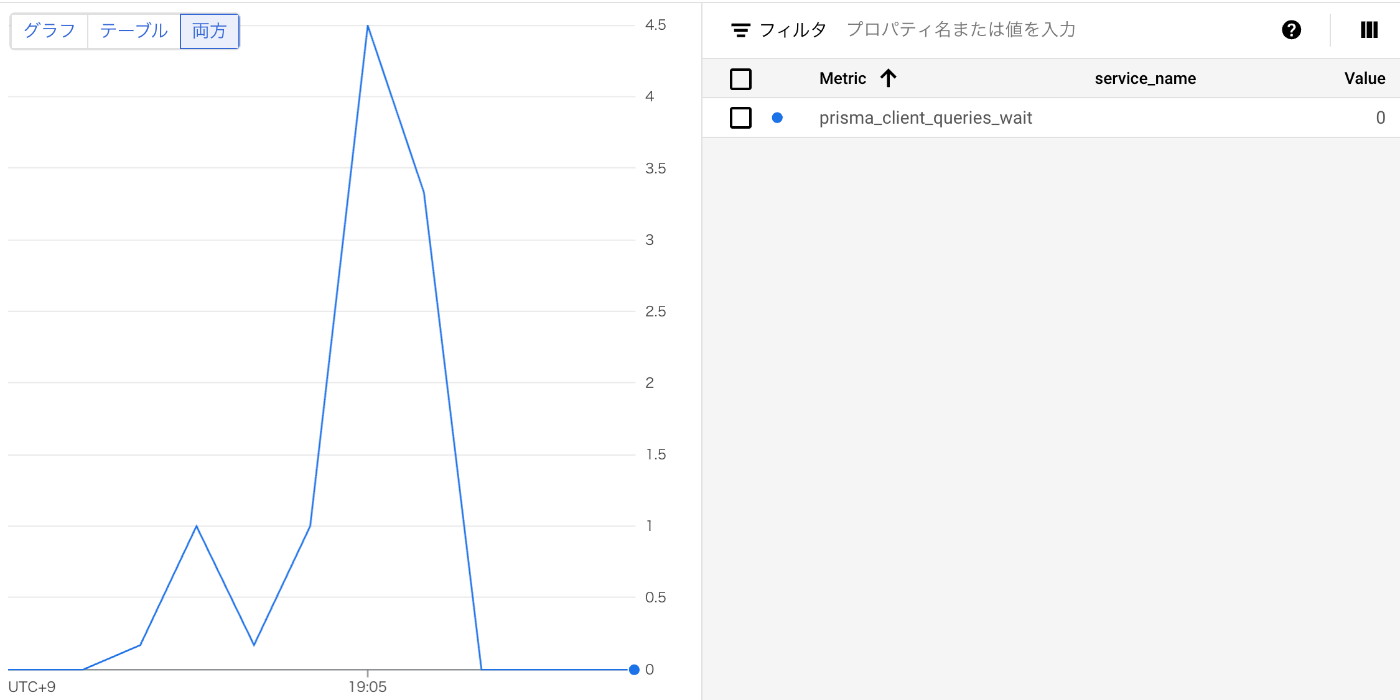
クエリの待ち時間が減るので、その分レイテンシの改善も期待できるでしょう。
実際我々のアプリでは、この設定を見直しだけで、1 秒近くレイテンシが改善しました。
Prisma はこれ以外にもコネクション数に関するメトリクスを数多く提供しています。うまく活用してパフォーマンスの改善に役立てましょう。
おわりに
今回は Prisma のコネクションの設定にフォーカスしました。
しかし、Prisma のパフォーマンスはその他の様々な要因にも影響を受けます。
例えば、以下のような項目です。
- Prisma が発行するクエリのパフォーマンス(大量に SELECT されるなど)
- N+1 問題
- DB のスペック(e.g. CPU, メモリ, 最大コネクション数)
そのため、実際のチューニングでは、複合的な視点を持ってチューニングをすることが重要です。
とはいえ、Prisma のコネクションが、アプリケーションのパフォーマンスを向上させる上で重要な項目であることは間違いありません。
この記事が、Prismaのコネクションをチューニングする上で少しでも参考になっていれば幸いです。
Discussion